详解维吉尼亚密码(附四种攻击策略)
目录
一. 介绍
二. 破解维吉尼亚密码
2.1 频率统计
2.2 提高型频率统计法
2.3 Kasiski攻击法
2.4 重合指数攻击法(index of coincidence method)
三. 小结
一. 介绍
我们知道英语字母的出现频率是有规律的,比如像下表:
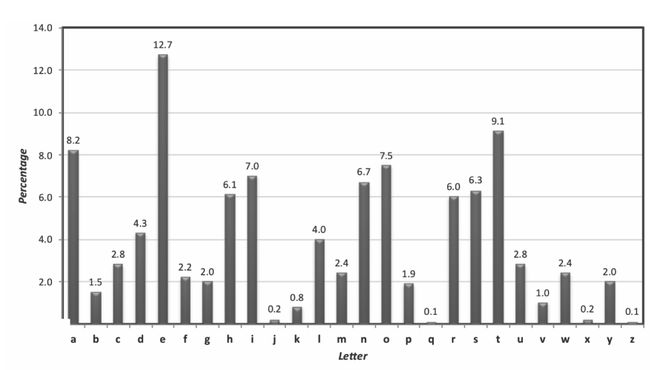
掌握了这些规律后,像凯撒密码等单表置换密码就不安全了。因为固定的密文字母一定对应着同样的明文字母。这个时候就出现了,略微高级的维吉尼亚密码。
维吉尼亚密码(Vigenere cipher)又叫做多表置换密码(poly-alphabetic shift cipher)。举个例子,明文字母为ab,可能对应密文DZ;明文字母是ac,可能对应密文TY。我们发现同一个明文字母a,在密文中有的时候是D,有的时候是T
首先说明下,这些密码都是把字母a~z对应0~25,密钥字母相加对应数字相加,必要时需要模26。举个例子,比如密钥是cafe,加密过程如下表:
| 明文 | tellhimaboutme |
| 密钥 | cafecafecafeca |
| 密文 | VEQPJIREDOZXOE |
需要注意的是密钥cafe是会被重复利用的,以4为循环。也就是说加密第一个字母,加密第五个字母,加密第9个字母使用的同一个密钥c;以此类推。
观察下密文,我们发现密文E有的时候对应明文e,有的时候对应明文a,看起来似乎毫无规律。另外,当密钥足够长时,破解起来就更加难了。
维吉尼亚密码是在16世纪提出了,直到过了200多年,人们才陆续发现了破解的方法。
二. 破解维吉尼亚密码
2.1 频率统计
假定密钥长度为t,也就是密钥k包含t个字母,可以写做:
![]()
借此,我们把密文可以分成t组。比如把第一个密文,第t+1个密文,第2t+1个密文放一起,等等。这些密文所使用的密钥是一样的,如下:
![]()
这些密文都使用同一个私钥 。密码学中很喜欢把一组叫做一流(stream),第j组,也就是第j流。
。密码学中很喜欢把一组叫做一流(stream),第j组,也就是第j流。
首先,最傻的穷搜攻击(brute-force search),一共有t组,每一组的密钥都有26种可能性(26个英文字母),如果直接穷搜的话,也就是![]() ,这显然是不可行的。
,这显然是不可行的。
那应该怎么做?
我们可以统计每一组密文字母的频率,比如我们发现在某一组密文中P出现的频率最高,那么它对应的明文大概率是e(看上面英文字母频率统计表)。由此就可以推导出这一组的密钥,这样其它的字母也就可以解决了。这种攻击方法的时间复杂度为26t。
2.2 提高型频率统计法
以上统计字母概率的方法误差太大了,比如如果你发现两个字母频率一样,咋办?
所以,实际利用的时候大都采用频率平方和的数字分析方法。还是一样,把英文字母a~z跟整数0~25对应起来。令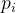 代表第i个字母的概率,注意是概率。根据字母表,我们发现:
代表第i个字母的概率,注意是概率。根据字母表,我们发现:
![]()
在同一组密文中,使用的密钥是相同的。也就是对于密文来讲,令 代表第i个字母的频率,假定该组的密钥为k,那么明文应该与
代表第i个字母的频率,假定该组的密钥为k,那么明文应该与![]() 相对应,由此计算:
相对应,由此计算:
![]()
密钥有26种可能性,只需要最多计算26次,当发现这个计算结果也接近0.065时,这个密钥就是正确的。
这个在现代密码学中可以被看成密钥恢复攻击(key recovery attack)。
2.3 Kasiski攻击法
Kasiski算法最早于19世纪中期被提出,该方法可以用来猜测密钥具体长度。我们知道英语中会经常出现“the”这个单词,加密形成密文后,很有可能对应相同的密文字母。
假如某维吉尼亚密码的密钥是beads,我们来看一个例子:

密文中重复出现了LII,它们都对应着明文the,说明这两个明文使用的是同一个密钥字母。我们把密钥的长度看成周期,两个LII之间的距离为30,说明30是密钥周期的倍数。
2.4 重合指数攻击法(index of coincidence method)
这种方法主要也是用来猜测密钥长度的,比上一个方法更加准确,利用代码也更容易实现。
假定密钥长度为t,在给定密文的情况下,我们希望通过重合指数攻击法,导出t的具体值。
按照之前分组的思想,第一组(stream)密文使用同一个密钥,如下:
![]()
同一个密钥代表同一种移位的加密方式。
令代表第i个明文字母的频率,假设此组密文的移位为j,也就可以得到:
![]()
其中代表明文第i个字母的概率。也就是![]() 就是把
就是把![]() 移位j得到的,这种移位其实很类似于抽象代数中循环群。比如假设明文a的概率为0.01,那么移3位的话,密文中C的频率应该接近0.01。考虑一个字母的话,误差太大。
移位j得到的,这种移位其实很类似于抽象代数中循环群。比如假设明文a的概率为0.01,那么移3位的话,密文中C的频率应该接近0.01。考虑一个字母的话,误差太大。
所以:
![]()
由此便可以大致确定移位的多少。假定候选的密钥长度![]() ,攻击的步骤如下:
,攻击的步骤如下:
- 抽取第一组密文
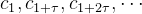
- 形成直方图,统计每个字母的频率
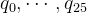
- 接着计算:
![]()
如果此时的 恰好为密钥长度t时,最终
恰好为密钥长度t时,最终![]() 的计算结果必定接近0.065.
的计算结果必定接近0.065.
如果密钥长度分析不对的话,每个字母出现的频率会均匀相等。因为是乱码,相当于均匀随机取,所以![]() ,也就可以得到:
,也就可以得到:
![]()
总结下就是,当密钥正确时,计算出的结果接近0.065;当密钥不对时,计算出的结果接近0.038.
也可以拿第二组密文来验证此时的密钥长度分析是否正确。
三. 小结
维吉尼亚密码的攻击算法需要密文的长度足够长,因为只有这样才能利用频率来代替概率。
可以想到如果密钥长度足够长,这个密码方案可以实现香农意义上的完美安全。