Bruteforc_Test靶场使用Burpsuite爆破教程
前言:
该文章仅用于信息网络安全防御技术学习,请勿用于其他用途!
该文章为纯技术分享,严禁利用本文章所提到的技术进行非法攻击!

目录
前言:
第一题:
第二题:
第三题:
第四题:
第五题:
第六题:
总结:
第一题:
第一步:
搭建小皮面板,创建一个网站
打开BP尝试抓包
抓取到包之后,尝试爆破第一个level
抓取到包之后,把请求发送到intruder


第二步:
尝试以下4种攻击模式(sniper、battering ram、pitchfork、cluster bomb)
Sniper:(单击模式)
比如在知道用户名是admin的情况下,那么可以只针对密码的爆破,选择对密码部分加一个变量,然后点击payloads ,在payloads页面,可以选择添加单个或者多个密码(1、add),也可以选择load(2、load)添加已经准备好的密码字典,添加完成之后,点击 start attack 发起爆破

我这边加了5个密码的情况下,显示了6个请求,因为第一个是默认的基线请求,
查看下面手动添加的密码,可以看到密码部分显示的是手动添加的密码,
再看response,很明显,密码错误,说明字典不够强大,关闭此窗口,
选择添加已经准备好的密码字典,点击start attack 发起爆破


爆破完成之后,可以对此次的爆破结果做一个简单的筛选,点击length,
可以筛选出长度不一样的返回值,这一次爆破也失败,说明字典还是不够强大
尝试新的字典,完成攻击后,点击length可以查看长度不一样的返回值
点击response查看返回的状态码,提示登录成功!
第二种攻击模式:
battering ram (一个payload尝试所有的点)
抓取请求包,选择攻击模式,点击右上角start,它会用同一个payload去尝试所有的点
更换密码比较多的字典尝试,它会先从position 1进行尝试,然后再尝试 position 2
尝试position 2 的时候,有一条密码是正确的,所以response返回登录成功


第三种攻击模式:
Pitchfork (每一个位置都可以单独创建一个payload)
选择Pitchfork 模式,payload set选择第 1 个位置,添加用户名的top500字典
payload set选择第 2个位置,添加密码的top1000字典
payload set选择第 3个位置,添加test的top500字典
运行完成后,可以看到每条线使用的是字典中的第一条数据,以此类推
如果设置两个payload,各设置一个字典进行爆破也会爆破出来




第四种攻击模式:
cluster bomb (排列组合出所有payload的可能性,字典小一点,要不然会很慢)
每条payload加10条数据
可以注意到,cluster bomb模式是先尝试payload 1的第一条去组合payload 2的所有数据,然后使用第二条再去组合payload 2的所有数据进行爆破,所以这个模式如果字典太大的话,爆破时间会非常的慢



第二题:
验证码复用
抓取请求包,发送到repeater,前端控制住不要让页面刷新,也就是验证码刷新,
在repeater页面点击send,查看response返回是否可以复用
确定验证码可以复用后,发送到intruder,选择sniper攻击模式,加载payload,
点击start attack开始攻击,当字典里面有正确的密码时,查看response返回值,显示登录成功


第三题:
把验证码请求发送到repeater,通过修改code值来控制验证码下次刷新的值,这里改成1111,
再发送一次登录的请求包,把验证码改成1111,点击send,会发现返回的是登录失败,
这说明它的请求走了刚才的验证码响应
然后,把这两个请求串联起来,再去做爆破,达到一个验证码复用的效果

在串联之前呢,先把登录的请求发送到intruder,把payload加上,然后要想在这个登录请求之前先发验证码的请求怎么做呢
在project option页面中最下面的macros模块,点击Add,添加之前验证码的请求,添加完成之后,可以对这个请求进行修改,也就是修改验证码的参数(这里注意,不止是修改验证码的参数,其他的也可以)
点击 configure item,进入面板里面修改验证码的参数,点击右下角的OK
注意在设置完参数后,一定要点击test macro测试一下这个宏,确定已经成功




创建宏之后,把这个宏添加到会话里面,让它自己去执行
点击session handling rules-----Add,添加一个rule,可以起中文名称,
下面选择之前创建好的宏,点击右下角的OK,选择完宏之后,想控制这个宏在哪些范围生效的话,可以点击scope
默认的是自定义网站的范围,现在就可以添加爆破的网站了,添加完成之后,去到intruder模块尝试爆破


爆破后查看请求会发现,有好几个响应码都不一样,有的是登录失败,有的是验证码错误,为什么有的走了登录逻辑,有的没有走呢
这个和设置的并发量有关,在intruder---resource pool默认资源池里面的值改一下,也可以新创建一个,我这里创建了10个并发,跑完发现还是有一定的几率会出现验证码错误,下面改一下并发的间隔时间,改成10毫秒,跑完之后发现,还是有个提示验证码失败的请求,这里的几率很难把握,个人觉得并发量不要太高,也不要太低,看自己物理机的CPU强不强了
个人建议并发量设置小一点,间隔时间就别设置了,一是效率不高,二是没啥用





第四题:
F12抓取登录的请求包,查看前端加密的信息,选中login,查看监听器里面绑定的的click或者其他submit事件,点击看它干了啥事,如果是from_login,可以直接在这个代码页面进行搜索,如果不确定是不是当前的这个,可以打个断点尝试以下,打了断点之后确定是登录的信息,可以尝试解读一下这串代码做了什么,
然后使用在线解密网站尝试能不能解密或者加密1、首先,通过 document.getElementById() 获取到表单中的用户名和密码输入框的值,并将其分别赋给变量 username 和 password。
2、然后,使用这些获取到的用户名和密码,构造一个 JSON 格式的字符串 pwd_key,其中包含了键名为 "username" 和 "password" 的对应值。
3、使用 alert() 函数输出 pwd_key 的值,以便在浏览器中显示弹窗,展示构造好的 JSON 字符串。
4、接下来,使用 encryptByDES() 函数将构造好的 pwd_key 进行加密。加密的密钥是 '232cb851727762bbf7dd097da3bcd354'。
5、再次使用 alert() 函数输出 post_key 的值,以便在浏览器中显示弹窗,展示加密后的结果。
6、最后,调用 post() 函数,将加密后的密钥发送给服务器进行登录验证




找一个在线DES加密网站,我这里就直接使用老师用的网站http://tool.chacuo.net/cryptdes
那根据代码里面提供的加密信息,复制到在线加密网站输入框里面尝试加密
(加密模式:DES,填充:CryptoJS.pad.Pkcs7,密码:232cb851727762bbf7dd097da3bcd354,
待加密、解密的文本:{"username":"admin","password":"12345"})
可以看到网站加密后的结果和网页里面加密后的结果是一样的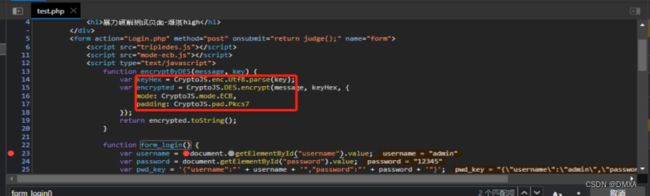


上面我们知道了网站也是可以进行DES加密并且和登录的加密结果一样,那么打开BP抓取登录的请求包
然后选择Extender(插件)-----BAppstore(Burp Suite 的插件市场)这里要找的是BurpCrypto,点击install,安装后右上角会多一个标签


添加完成之后,先去设置payload,选择custom iteator(自定义的迭代器),然后在下面拼接JSON,第二部分选择字典





Payload添加完成之后
点击BurpCrypto标签,选择加密方式,添加秘钥,点击创建设置名称:避免使用中文(test1),
然后回到payload,在payload processing添加刚才创建好的规则,点击start attack,查看结果,response显示破解成功



如果请求很多的话,长度比较长的话,可以进行规则筛选,在 Grep Match 中,添加一个新的筛选项,这个筛选项可以在hex里通过关键字进行加密后,进行比对是否和现在的hex一致,如果一致的话,可以添加在筛选项里
得到请重新登录加密后的hex和返回的hex一致,那么就可以加到 Grep Match中
添加完成之后,再次start attack,结果显示,带有请重新登陆hex编码的请求都显示为1,破解成功的没有显示,这样的话点击length,就可以快速的筛选出来




第五题:
在之前首先要明白后面的原理以及步骤:
1、BP向服务器请求验证码图片 (BP-----Server)
2、服务器响应验证码给到BP
3、BP把验证码发给AI图像识别 (一个web服务)
4、AI识别出来后再响应给BP (也就是0527)
5、BP组装最后的登录报文 (user、pass、0527)
6、BP发送请求的报文给到服务器
7、服务器再把响应登录请求单的结果返回给BP下面开始一步一步实操:
1、先找在github上找OCR资源
2、https://github.com/sml2h3/ddddocr
3、https://github.com/f0ng/captcha-killer-modified
4、把地址资源下载到本地,进行编辑使用


1、保存验证码图片到本地,后面可以进行调用
2、代码中的图片名称要和文件夹里面的一致
3、代码是使用 ddddocr 模块进行验证码识别的示例

1、然后在AIocr.py所在的目录下,打开cmd,运行这个py文件
2、运行后提示找不到名为 'ddddocr' 的模块
3、然后可以在这个窗口中进行安装ddddocr模块,(pip install ddddocr)
4、安装的时候老是提示超时

1、安装ddddocr的时候遇到了一些错误,首先是源不对,直接使用pip install ddddocr会很慢
2、在网上找了一些文章,用了其他的源地址,还升级了一下pip以及清除了pip的缓存


- 这里的报错是我的疏忽,没有好好审查代码,Ddddocr的o应该是大写的O
- 还有就是调用 OCR 实例的方法应该是 classification(),而不是 classinfication()

1、前面已经下载过captcha,注意要使用符合自己jdk版本的就可以
2、选择add进行添加,next,正常添加完成的情况下,在output窗口会有成功的代码提示
3、如果报错的话,会在error窗口里面提示
4、如果你用的是python相关的插件,需要下载一个jython的jar包,直接在官网下载即可
5、下载完成之后,在option页面选择python evnironment 下的jython选择添加即可




1、勾选上之后,上面会多一个这个插件的标签
2、开启python服务,在captcha的路径里输入CMD,然后输入python codereg.py 启动
3、抓取请求发送到intruder,添加密码和验证码变量后,选择攻击模式为pitchfork
4、然后在payload里面添加字典和验证码插件服务,第二个payload选择exstension-generated
5、线程池尽量调小一点






1、设置完成后,就可以点击右上角的start运行起来
2、可以看到intruder页面有很多0识别成了o
3、下面修改代码,在处理验证码的这一行后面加上.replace("o","0")
4、return web.Response(text=ocr.classification(img_bytes)[0:4].replace("o","0"))
5、重新start运行起来

1、改了代码之后,可以看到运行结果没有把0识别成o了
2、大量的字典进行爆破的时候,效率低时间长,可以把登陆失败的密码筛选出来,做进一步的效率提升

登录成功
第六题:
2、启动BP,抓取登录请求发送到repeater,手动发送测试确定是否token有变化
3、添加宏:设置configure item-----add(定义自定义参数配置),定义表达式开始(选择下面的token)
4、点击OK,配置宏项(响应中的自定义参数位置会有一个刚才添加的配置)





(这里的参数名称尽量统一,防止记不住)
1、在repeater页面测试添加后的宏是否生效(发送之前在proxy页面重新发送一次到repeater,要不然会没有反应)
2、宏设置完成之后,设置intruder,添加password变量(这里的token就不需要添加变量了,因为在发送请求后,只要相应里包含token,token就会自动刷新)
3、设置可以自己把握



(登陆成功!)
总结:
每次拿到的token都是从服务器下发的最新的token,就是服务器返回的token作为下一次请求的参数