八. 实战:CUDA-BEVFusion部署分析-环境搭建
目录
-
- 前言
- 0. 简述
- 1. CUDA-BEVFusion浅析
- 2. CUDA-BEVFusion环境配置
-
- 2.1 简述
- 2.2 源码下载
- 2.3 模型数据下载
- 2.4 基础软件安装
- 2.5 protobuf安装
-
- 2.5.1 apt 方式安装
- 2.5.2 源码方式安装
- 2.6 编译运行
-
- 2.6.1 配置 environment.sh
- 2.6.2 利用TensorRT构建模型
- 2.6.3 编译运行程序
- 2.7 拓展-Python接口
- 2.8 拓展-Debug调试配置
- 3. 推理结果浅析
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第八章——实战:CUDA-BEVFusion部署分析,一起去分析 CUDA-BEVFusion 的优化策略与环境搭建和测试
Note:CUDA-BEVFusion 是多模态 BEV 感知算法 BEVFusion 的部署框架,需要大家对 BEV 感知算法和 BEVFusion 有一定的了解,这样可能对课程内容的理解更加深刻,如果大家想了解 BEV 感知算法的可以看看 一. BEV感知算法介绍,想了解 BEVFusion 多模态感知算法的可以看看 三. LiDAR和Camera融合的BEV感知算法-BEVFusion
课程大纲可以看下面的思维导图
0. 简述
从这节开始我们进行第八章 CUDA-BEVFusion 部署分析,这一章节也是这个课程的最后一个章节,那关于 BEVFusion 的部署相信大家从开始就一直期待,为什么呢,是因为 BEVFusion 其实涉及到的东西非常多,不仅仅是一个 classifier 或者 detection 那么简单,它里面涉及到的内容其实就是我们前面第一章到第七章的一个大汇总。我们前面讲过的东西在这里或多或少都会有所涉及,所以作为一个比较大也是比较难的项目,我们一起去学习一下它,看看它的开源代码是怎么做的
那这个章节会讲得比较细,主要分为以下九个部分:
- 1. 分析 CUDA-BEVFusion 的优化策略与环境搭建和测试
- 2. 学习 spconv 的原理
- 3. 学习导出带有 spconv 的 SCN 网络的 onnx
- 4. 学习 spconv 的优化方案(Explicit GEMM conv)
- 5. 学习 spconv 的优化方案(Implicit GEMM conv)
- 6. 学习 BEVPool 的优化方案
- 7. 分析 BEVFusion 中各个 onnx
- 8. 学习 CUDA-BEVFusion 推理框架设计模式
- 9. CUDA-BEVFusion 代码分析
我们逐个看一下,首先第 1 小节是分析 CUDA-BEVFusion 的优化策略以及环境搭建的一个测试,这个小节是作为第八章的引言部分会去跟大家介绍一下 BEVFusion 是什么,它各个层都是负责干什么的,以及 CUDA-BEVFusion 它作为 BEVFusion 的一个推理框架,它主要是对哪些部分做了优化,这些内容讲完之后我们会去带着大家把环境搭建一下,跟着 NVIDIA 官方提供的 README 文档搭建环境并测试跑通,这是我们第一小节要做的事情
后面的 2、3、4、5 四个小节主要是围绕 spconv 展开的,spconv 是我们说的 3D Sparse Convolution 的一个简称,稀疏卷积,它主要是针对 3D 的稀疏点云进行特征提取的一个小模块,这个小模块其实就是能够比较高效的处理带有稀疏性质的 3D 点云。我们都知道点云在整个 3D 场景中其实是比较稀疏的,一个场景中真正有意义的点只占少部分,针对这样一个稀疏化的数据我们怎么高效的去做一个卷积,这是 spconv 需要做的事情。我们如果想要去搞定它就得需要先学习一下 spconv,所以我们在第 2 小节会带大家学习一下 spconv 的工作原理,里面的算法是什么样子,里面的 Rulebook 和 hash table 是用来干什么的,atomic operator 原子操作是干什么的等等,这些都是我们在第 2 小节中要掌握的。
我们学习完了 spconv 的原理之后很自然的会想到带有 spconv 的网络模型例如 SCN 该怎么导出其对应的 ONNX 呢,带有 spconv 模型的 onnx 导出其实和我们之前所讲的 onnx 导出方式有所不同,这是因为之前的 onnx 模型的输入都是图片,图片输入到网络的分辨率大小都是固定的比如说 640x640,它不会说因为场景变化而变化,但对于点云输入来说,它的数量其实是不固定的,它是随着场景的变化而变化的,比如我们当前场景比较空旷那点云的数量就比较少只有 1000 个点,另一个场景行人车辆比较多那点云的数量就比较多有 10000 个点,所以每次输入到网络中的点云的数量都是不一样的,这意味着每次通过 spconv 稀疏卷积的输入输出形状可能会不一样,那针对这种输入输出不固定的情况 tensorRT 是不支持的,tensorRT 虽然可以支持动态 shape,比如说输入的 BCHW 维度的 shape 可以修改,但是对于稀疏卷积这种输入大小不固定的情况 tensorRT 本身还是不支持的,既然 tensorRT 不支持稀疏卷积模块,那我们如何使用带有 spconv 的网络比如 SCN 进行推理呢,那这个我们会在第三小节中给大家讲解,这部分其实也是跟着 NVIDIA 官方提供的一个方案看看他是怎么调用 spconv 这个库的,虽然 NVIDIA 设计了 spconv 库的一个加速方案,但它目前并没有开源,所以本质上它就是一个黑盒子,我们并不知道它内部是怎么做加速的,但它提供了一些接口,我们只能利用它提供的接口去做一个前向推理
那第 3 小节之后我们会自然的去想既然 NVIDIA 没有开源 spconv 加速的话,如果我们自己去做 spconv 加速有哪些方案呢,那这里其实有两个思路,一个是 Explicit GEMM conv 也就是显性的方式,那显性 GEMM conv 是什么呢,其实就是一个矩阵乘法,全称是 GEneral Matrix Multiplication,也就是说把卷积计算转换成矩阵乘法计算,我们如果写过 CUDA 都知道 NVIDIA 里面的 CUDA 和 cuDNN 库其实对矩阵乘法做了非常多的优化,比如 cuBLAS 它里面就是有很多针对矩阵乘法的一个加速效果,所以把 Conv 转换成矩阵乘法来做加速的话其实是比较有效的方式,那这个方式它跟 spconv 的一个兼容性,spconv 怎么利用它去做加速的呢,这是我们第 4 小节要去考虑的
那我们学完了 Explicit GEMM conv 加速方案之后,可以剧透下这种方式会有一点劣势,有一些额外的开销,那针对这个额外的开销这些多余的计算我们怎么去弥补它呢,怎么去进一步的加速呢,所以也就引入了第 5 小节的 Implicit GEMM conv 隐式的 GEMM conv,那隐式的 GEMM conv 是什么呢,它与显式的有什么区别呢,它对 spconv 是怎么加速的呢,这个是我们在第 5 小节要去讲解的内容
那我们也能看到我们大概会花 4 个小节的内容给大家去讲解 spconv,说明它的地位是非常重要的,那这里我们虽然是围绕这 spconv 去讲解的,但它里面的很多核心还是偏底层的,比如说矩阵乘法、im2col 等等,所以这里也会去围绕 spconv 稍微展开讲一下
我们学完 spconv 之后 BEVFusion 第二个比较重要的部分就是 BEVPool,我们要去看 BEVPool 它是怎么优化的,我们如果读过 BEVFusion 或者 LSS 的文章,我们就知道 2D Camera Feature 转到 BEV Feature 这个过程其实计算量非常大,时间也比较长,那针对 BEVPool 计算量大时间长的问题,NVIDAI 是怎么做加速的呢,这个我们会在第 6 小节给大家讲解
OK,那学习完 BEVPool 的优化之后我们第 7 小节会针对 BEVFusion 中的各个模块去分析它的 onnx,主要包括以下五个 onnx:
- camera.backbone.onnx:相机主干网络的 onnx
- camera.vtransform.onnx:相机视角转换的 onnx
- lidar.backbone.xyz.onnx:点云主干网络的 onnx
- fuser.onnx:融合模块的 onnx
- head.bbox.onnx:检测头的 onnx
我们会分析下这几个 onnx 的输入输出是什么样子的,以及这些 onnx 之间的一个关联性是什么样子的,这样我们就比较好理解 BEVFusion 以及 CUDA-BEVFusion 是按照什么样的方式来做推理的
经过从第 1 小节到第 7 小节的铺垫后,我们再看第 8 小节和第 9 小节就会容易很多了,那在第 8 小节中我们会去学习 CUDA-BEVFusion 推理框架的设计模式,设计模式其实就是讲 C++ 的一个写法,我们会去看 CUDA-BEVFusion 它各个模块,各个类,命名空间,它们是怎样的一个层级关系,哪个类调用哪个类,哪个类属于哪个命名空间,这是我们必须在学习代码之前必须要掌握的东西,我们要学习一个大项目如果不知道这一块的话,不知道它的设计框架是按照什么样的方式去设计的话,那其实会很影响我们看代码的效率
那我们第 8 小节讲完之后在最后的第 9 小节中我们会跟大家一起过一下代码,把几个比较核心的地方给大家看一看,整个代码其实给大家做了很多注释,在读代码的时候可以跟着注释,以第 8 小节的设计模式为指南去读这个代码,这个代码写得还是挺不错的
OK,以上就是第八章的全部内容,那我们先进入第 1 小节,分析 CUDA-BEVFusion 的优化策略和环境搭建测试
1. CUDA-BEVFusion浅析
本小节的目标:CUDA-BEVFusion介绍,以及搭建部署推理环境跑通程序
我们先看 CUDA-BEVFusion,那 CUDA-BEVFusion 其实是 NVIDIA 开源的一个叫 LiDAR_AI_Solution 项目下面的一个小项目,它针对 MIT 的 BEVFusion 进行了 CUDA 和 TensorRT 的加速,达到较高的推理速度。Github 地址是:https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution
那大家感兴趣的可以看一下这个项目,它参考价值还是比较高的,它的整个项目其实是围绕 3D Sparse Convolution 去展开的,也就是以它为核心去做优化的,比如 CUDA-CenterPoint、CUDA-BEVFusion、它其实都是针对点云和多模态融合做的一个优化,大家可以自己阅读下它对应的 README 文档

那我们从上图可以看到 CUDA-BEVFusion 它是一个多传感器融合的 BEV 感知算法,有图像输入和点云输入,图像是多视角图像,图像支路和点云支路分别做特征提取后再融合,得到一个融合后的 BEV Feature 特征,然后再接上一个 Detection Head 和 Segmentation Head 去做预测
值得注意的是 BEVFusion 其实是有两篇文章的:
- 北大&阿里推出的 BEVFusion
- BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework,
- NeuIPS 2022 accepted
- GitHub 地址:https://github.com/mit-han-lab/bevfusion
- MIT&上海交大推出的 BEVFusion(CUDA-BEVFusion 选用)
- BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
- ICRA 2023 accepted
- GitHub 地址:https://github.com/ADLab-AutoDrive/BEVFusion
那这两个 BEVFusion 有什么不同呢,我们可以对比看看它们的网络结构,如下所示:


那这两篇工作属于同时期的工作,我们来看看这两篇文章的思路有什么异同点,那首先输入输出都区别吗,两篇文章的输入同样是多视角图像还有点云数据,那输出有一点点区别,除了 3D 检测任务之外,MIT 这篇工作中还引入了分割任务,那任务其实无关紧要,它只是一个额外连接的检测头罢了,任务预测基于的特征是一致的,叫做 Fused BEV Features,融合的 BEV 特征。
那其实这两份工作思路是一致的,它都是通过分开提取特征再融合的方式得到融合后的 BEV 特征,其中 Camera Stream 和 LiDAR Stream 的处理都是一致的,从思路上从框图上讲是完全一样的,有一点点区别的地方在于融合任务,MIT 额外引入了一个分割任务,另外希望大家注意到 BEVFusion-MIT 这篇文章中对单一模态没有特定的检测支路的,那到底需不需要这个额外的模块呢,那这是一个仁者见仁智者见智的事情,大家感兴趣的话也可以在 MIT 的工作基础上添加额外的检测头,看看结果会不会有什么变化
另外想说的是 MIT 的工作其实更偏工程性一点,一些优化的讨论是更丰富的,此外 mit-han-lab 这里面有非常多非常好的代码,大家如果想要做高效部署的,一定要看这个 repository。这里面除了 BEVFusion 之外,它还有很多比较出色的项目,那他们很多项目其实都是有在关注模型的一个效率问题,这个是 mit-han-lab 它比较特殊的地方,也是比较强势的地方,希望大家可以抽时间看一看
我们重点来看下 BEVFusion-MIT 的模型,它包括以下几个部分:
- Camera Encoder
- 可以选择 Swin Transformer 也可以选择 ResNet
- LiDAR Encoder
- 选用的是 CenterPoint 中的 SCN(Sparse Convolution Network)
- Camera-to-BEV
- 预测每个像素的深度分布之后使用 BEVPool 转换到 BEV 空间
- LiDAR-to-BEV
- 提取特征后沿 Z 方向进行 Flatten 转换到 BEV 空间
- BEV Encoder
- 将 BEV 空间下的 Camera Feature 和 LiDAR Feature 融合在一起,通过几个 Conv 关联起来
- Head
- 3D Detection(x,y,z,w,h,vx,vy,sin,cos,score)
- Segmentation(CUDA-BEVFusion 中暂时没有实现)
可以看到 BEVFusion-MIT 总共有六个部分,我们先看 Camera Encoder,这个是 Camera 特征提取器,我们看 BEVFusion 的多视角图像输入是有 6 张图片(nuScenes 数据集为例),6 张图片放在一个 batch 里面给 Camera Encoder 做推理,那这个 Encoder 可以是 Swin Transformer 也可以是 ResNet。Swin Transformer 是基于 transformer 的网络,它里面会有一些额外的不参加计算的操作,比如 reshape、shifted window 等等,那这种操作其实会影响计算密度和计算效率的,所以普遍上 Swin Transformer 它的一个计算密度其实没有 Resnet 高,那为什么这里还是会选择 Swin Transformer 呢,因为 Swin Transformer 是基于 transformer 的网络,那 transformer 有什么好处呢
这里稍微回顾一下,transformer 相比于 CNN 而言它具有很强的一个全局性,那 CNN 卷积神经网络它比较关注图片的局部性,而 Swin Transformer 更关注的是全局性,那全局性在这里有什么好处呢,我们看到这里是 6 个多视角的图像,那我们要做全局性的一个 attention 的话其实是比较适合这个任务的,因为我们可能会需要 6 个视角的图像不同位置的不同信息,我们只要通过 attention 就能够知道它们的之间的关联性,这是选取 Swin Transformer 的一个好处,那当然要考虑效率的话其实 ResNet 也是没有问题的
OK,这个地方其实需要讲的东西不多,这是 Camera 的一个编码器
我们再来看 LiDAR 的编码器,LiDAR 编码器在这里选的是 SCN(Sparse Convolution Network)它是在 CenterPoint 中的一个模块,那这里 BEVFusion 其实是直接拿这个现有的模块做 LiDAR 的特征提取的
特征提取完之后,下一步我们需要把 LiDAR 和 Camera 两个特征给它投影到 BEV 空间上,LiDAR 的投影相对来说比较简单,因为点云本身就是 3D 的,我们只需要沿着高度维度进行拍扁就行;Camera 的投影相对来说比较复杂,因为 Camera 图像本身是 2D 的,那 2D 投影到 3D 的 BEV 空间上的话这里面就会涉及到传感器的内外参,我们需要根据内外参数得到映射关系就可以把 Camera Feature 投影到 BEV 上,之后再通过 BEVPool 把 BEV Grid 上的点做一个累加,最后得到 BEV 上的一个特征图,维度是 360x360x80 的大小,360x360 是 BEV Grid 的大小,80 是通道数,这里给大家稍微提一下,后面会具体展开讲。那这个 BEVPool 其实是比较重要的,因为我们都知道 BEVPool 计算比较耗时,我们需要去学习一下 CUDA-BEVFusion 是怎么去优化这个 BEVPool 的
OK,我们把 Camera 给投影映射到 BEV 之后,我们还要把 LiDAR 的信息给映射到 BEV,这个就比较简单了,因为 LiDAR 本身就是 3D 的,我们直接在 z 方向上做一个 Flatten 就 OK 了,所以这个地方其实可以忽视掉
那经过上面的步骤之后我们现在有什么,有 Camera BEV Feature 还有 LiDAR BEV Feature,下一步我们该做什么呢,该做融合,什么下的融合呢,BEV 下的融合。我们把图中黄色的 Camera BEV Feature 和蓝色的 LiDAR BEV Feature 放在一起后做融合,通过一个 BEV Encoder,那这个 Encoder 也是比较重要的,它其实就是个传感器融合。通过几个 Conv 把 Camera BEV Feature 和 LiDAR BEV Feature 之间的关联性给学习出来,最终可以得到一个比较好的 BEV Feature,那我们认为这个 BEV Feature 融合了相机的几何信息以及 LiDAR 的深度信息,更适合用来做预测,因此在这之后可以接一个检测头或者分割头用来做预测
我们需要重点关注的有以下三个部分:
- Camera Encoder 的 INT8 量化学习
- SCN 的实现
- BEVPool 的实现
- 这在之后的几个小节会进行详细的描述
CUDA-BEVFusion 作为 BEVFusion 的 TRT 推理框架,我们需要先理解它在哪些部分做了优化,这个是我们在阅读代码前需要掌握的,在量化方面上 CUDA-BEVFusion 整体上是 FP16 精度推理的,对于某些部分可以 INT8 推理,下面我们具体来看一下每个部分的优化方向:
-
Camera Encoder
- 一系列前处理(Normalized,Resize 等),使用 CUDA 加速
- 可支持 INT8 量化(这里的推理时间占比最大),使用 TensorRT 加速
-
LiDAR Encoder
- 设计 voxelization 的 CUDA Kernel,加速 points 到 voxel 的转换,使用 CUDA 加速
- 自定义 spconv 的实现,做 SCN 的前向推理(这里估计没有走 TensorRT,而是使用 CUDA 加速)
-
Camera-to-BEV
- 自定义 BEVPool 的 CUDA Kernel,加速 Camera Feature -> BEV Feature 的转换,使用 CUDA 加速
- BEVPool 后的 BEV Feature 再通过几个 conv 进行特征提取,使用 TensorRT 加速
-
LiDAR-to-BEV
- SCN 之后的 Feature 就是 BEV 级别的 Feature 了,所以这里属于 LiDAR Encoder 的一部分
-
BEV Encoder
- 通过 Fusion 的部分,这里可支持 INT8 量化
- 通过几个 conv 进行融合后的特征提取,使用 TensorRT 加速
-
Head
- 将 BEV Feature 转换到 output 能够用的 Feature,使用 TensorRT 加速
- 将拿到的 output 进行 decode 与绘图,使用 CUDA 加速
上面的六个部分也是我们学习 CUDA-BEVFusion 这个项目的一个方向,我们稍微展开以下,那 Camera Encoder 在 CUDA-BEVFusion 中的优化方向主要是前处理部分,那前处理部分我们很熟悉了,输入图像在进入到网络之前需要经过一系列的预处理,比如 resize、normalization 等等,那这部分和我们之前讲的其实差不多,可以利用 CUDA 核函数做加速,把前处理做完之后,将处理完的数据送入网络中进行 forward 前向推理,那这部分我们不用考虑,它其实是使用 TensorRT 去做加速的
我们再来看 LiDAR Encoder,点云在送入网络之前也需要做一个前处理,那这里的前处理使用的是 Voxelization 体素化,那体素化的话其实也有一个 CUDA Kernel 可以加速点云到 Voxel 的一个转换,之后把预处理好的数据送入到 SCN 网络中进行 forward 前向推理,那这个地方虽然是导出有 ONNX 模型的但它并没有跑 TensorRT 的,那为什么没有跑呢,其实之前也有提到过因为 SCN 中包含有稀疏卷积,而稀疏卷积的输入输出大小是不固定的,没有办法走 TensorRT 推理,所以这里是通过 3DSparseConvolution 和 CUDA 进行的加速
OK,我们再来看 Camera-to-BEV 的一个映射,那在这里使用 BEVPool,那 BEVPool 的话它里面也是有 CUDA 加速的,利用 CUDA 多线程去处理各个 Grid 上的一个累加操作,投影到 BEV 之后我们需要再通过几个 Conv 做一个特征提取,那这个使用 TensorRT 做加速的
那 LiDAR-to-BEV 这个地方之前也说过,LiDAR 本身就是 3D 的,所以这个地方其实可以跳过,我们不用关注
那么我们继续看一下 BEV Encoder 编码器,那这个编码器其实就是很多个 conv 的组合,是可以做 INT8 量化的,它本质上也是一个 DNN,所以我们可以把它取出来给 TensorRT 加速,这是没问题的
那么最终通过 BEV 的编码器得到最终的 BEV Feature 之后传给 head 做预测,这里的 head 包括两部分,一个是通过 Detection Head 得到检测输出的结果,那这个地方它是跑了 TensorRT 加速的。拿到 output 结果之后,我们需要做个 decode 得到 3D 点的信息,那得到 3D 点信息之后还需要绘制到图像上,那绘图这部分使用的是 cuOSD 同样是 CUDA 加速的
OK,所以说我们看到 CUDA-BEVFusion 它每一个模块其实都会涉及到 CUDA 加速,对于大部分 CNN 它其实都是使用的 TensorRT 的加速,所以说这意味着我们在看代码的时候,我们其实感兴趣的可以看他的 CUDA 加速核函数是怎么写的,那以上就是学习 CUDA-BEVFusion 的一个方向
下面我们来看看 CUDA-BEVFusion 的环境配置
2. CUDA-BEVFusion环境配置
之前博主有分享过 LIDAR_AI_Solution 的环境配置,这次在其基础上再重新过一遍 CUDA-BEVFusion 的环境配置,感兴趣的可以看看:LiDAR_AI_Solution环境配置
2.1 简述
CUDA-BEVFusion 环境的配置需要一些前置条件,可以从 README 中获取到,我们一起来看下:
- CUDA >= 11.0
- CUDNN >= 8.2
- TensorRT >= 8.5.0
- libprotobuf-dev == 3.6.1
- Compute Capability >= sm_80
- Python >= 3.6
其中有两个点值得我们注意,一个是 Compute Capability >= sm_80,这其实是一个硬性条件,大家可以点开对应的链接查看自己的显卡符不符合要求,博主这里截取了两张图,一个是主机的算力图,一个是 Jetson 的算力图,如下所示:


在主机的算力图中右边是笔记本的显卡算力图,左边则是正常的显卡算力图,从图中我们也能看出只有 30 系和 40 系的显卡算力才满足 sm >= 80 的要求,10 系和 20 系都是不支持的,另外 Jetson 嵌入式系列只有 Jetson AGX Orin、Jetson Orin NX 以及 Jetson Orin Nano 三款产品满足要求,因此大家可以对比自己手里的设备,如果算力不满足要求则需要考虑在其它高算力的设备上去配置环境了,因为这是硬性要求。
除了显卡算力的硬性要求外还有一个点值得大家注意,那就是 libprotobuf-dev == 3.6.1,protobuf 软件的版本是指定了的,要求 3.6.1,博主之前在 LiDAR_AI_Solution环境配置 的博文中是通过以下指令来安装的:
sudo apt install libprotobuf-dev=3.6.1*
通过如下指令可以卸载:
sudo apt remove libprotobuf-dev
在 Issues#60 中也有人提到源码编译 protobuf,其指令如下:
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git checkout v3.6.1
git submodule update --init --recursive
bash autogen.sh
./configure
make -j$(nproc)
make -j$(nproc) check
sudo make install
因此本次环境配置博主会提供 apt 方式和源码编译两种方式安装 protobuf=3.6.1,这些在后续具体的环境配置中会提到
这次博主将再次完整的走一遍流程,本次流程和上次 LiDAR_AI_Solution环境配置 没有什么本质性的区别,都大差不差,只是 protobuf 的安装提供源码编译的方式,另外把上次 Python 接口编译问题给解决
博主本次配置 CUDA-BEVFusion 使用的设备依旧是自己的电脑主机,环境如下:Ubuntu20.04、RTX3060、Driver-510.108.03、CUDA-11.6、cuDNN-8.4.0、TensorRT-8.6.1.6
大家如果使用 Jetson 嵌入式的话则需要保证 JetPack >= 5.1.1
OK,下面我们正式开始 CUDA-BEVFusion 的环境配置
2.2 源码下载
大家确保自己的设备算力满足要求后就可以来开始安装环境了,首先需要把整个项目完整的拉取下来,这个是非常非常重要的,大多数问题都是由于没有完整拉取整个项目而导致的,由于整个项目非常大所以在拉取时最好是开代理,不然容易断开导致 clone 得不完整,而博主只有在 Windows 下才有代理 Linux 上没有,因此考虑从 Windows 下拉取整个项目,大家如果在 Linux 下有代理的可以直接从 Linux 上拉取省掉不必要的麻烦
首先你需要在 Windows 下面安装 Git,这个比较简单大家可以参考下面的文章自行安装:
- Git 安装:Windows系统Git安装教程
- Git 下载地址:https://git-scm.com/downloads
- 也可点击 here【pwd:cuda】 下载博主准备好的 Git 软件包
将 Git 安装完成后就可以在 cmd 窗口正常执行 git 指令了,项目克隆指令如下:(PS:一定记得开代理)
git clone --recursive https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution
–recursive 是一定要加上的,它会去循环克隆子项目,完整的项目拉取过程如下图所示:
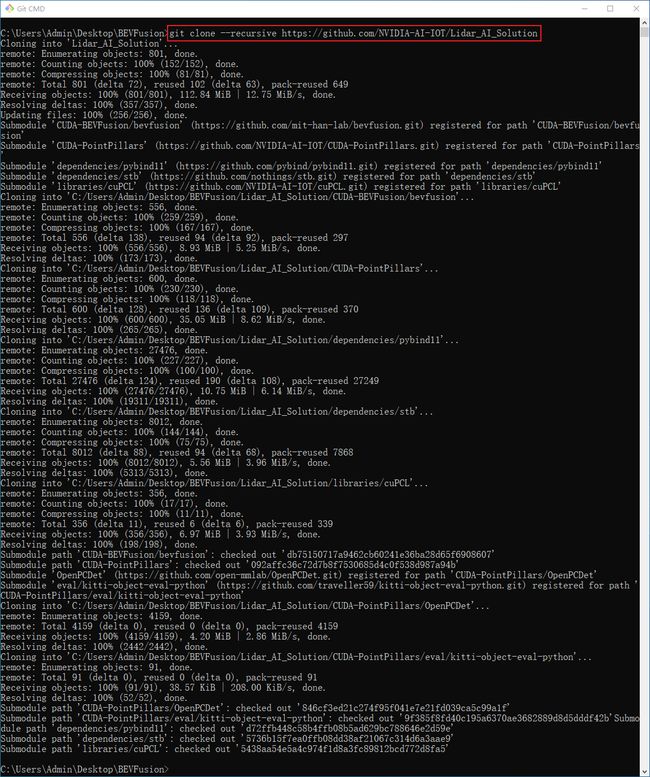
下载完成以后把整个项目拷贝到 Linux 进行后续操作就行,值得注意的是,从 Windows 拉取的代码放在 Linux 上会有一个小小的 bug,这个我们之后会提到
这里也提供博主拉取的整个 repo,感兴趣的可以自行下载,下载链接:Baidu Drive【pwd:cuda】(注意该代码下载于 2023/12/27 日,若有改动请参考最新)
至此,整个项目文件就准备好了,在 Windows 下整个项目大概有 568MB 的大小,此外 LiDAR_AI_Solution 项目下面存在多个子任务,由于我们只关注 CUDA—BEVFusion 因此只看 CUDA-BEVFusion 的 README 文档即可
2.3 模型数据下载
整个项目准备好后接下来我们就需要下载模型和测试的数据了
所有的模型都可以从 Baidu Drive 下载,model.zip 它包含如下内容:
- swin-tiny onnx models
- resnet50 onnx 和 pytorch models
- resnet50 int8 onnx 和 PTQ models
nuScenes 的样例数据可以从 Baidu Drive 下载,nuScenes-example-data.zip 它包含如下内容:
- 6 视角的相机图像
- camera/lidar/ego 的转换矩阵
- 用于 example-data.pth 的 bevfusion-pytorch 数据,只允许导出 onnx,而无需依赖完整数据集
下载完成后需要把对应的 model.zip 和 nuScenes-example-data.zip 放到 CUDA-BEVFusion 文件夹下进行解压,完整指令如下:
# 下载模型和数据到 CUDA-BEVFusion 文件夹
cd CUDA-BEVFusion
# 解压模型和数据压缩文件
unzip model.zip
unzip nuScenes-example-data.zip
# 下面是解压后整个文件夹的结构
CUDA-BEVFusion
|-- example-data
|-- 0-FRONT.jpg
|-- 1-FRONT_RIGHT.jpg
|-- ...
|-- camera_intrinsics.tensor
|-- ...
|-- example-data.pth
`-- points.tensor
|-- src
|-- qat
|-- model
|-- resnet50int8
| |-- bevfusion_ptq.pth
| |-- camera.backbone.onnx
| |-- camera.vtransform.onnx
| |-- default.yaml
| |-- fuser.onnx
| |-- head.bbox.onnx
| `-- lidar.backbone.xyz.onnx
|-- resnet50
`-- swint
|-- bevfusion
`-- tool
至此,CUDA-BEVFusion 需要的模型和数据也准备好了
2.4 基础软件安装
基础软件包括 CUDA、cuDNN、TensorRT 的安装,各个软件版本要求如下:
- CUDA >= 11.0
- cuDNN >= 8.2
- TensorRT >= 8.5.0
基础软件的安装可以参考 Ubunt20.04软件安装大全,这边不再赘述
2.5 protobuf安装
2.5.1 apt 方式安装
apt 方式安装指令如下:
sudo apt install libprotobuf-dev=3.6.1*
安装过程如下图所示:

安装完成后,其库文件在 /usr/lib/x86_64_linux-gnu 文件夹下,可以看到多了 libprotobuf.so 等库,头文件在 /usr/include/google/protobuf 文件夹下,大家可以自行检查下
此外如果大家想要卸载它则可以执行如下指令:
sudo apt remove libprotobuf-dev
这时候再去查看 /usr/lib/x86_64_linux-gnu 和 /usr/local 文件夹可以发现关于 protobuf 的头文件和库文件都被卸载了
这就是通过 apt 方式安装 protobuf 的流程,相对来说还是比较简单的
2.5.2 源码方式安装
之前我们是通过 apt 指令安装的,我们下面尝试从源码编译 protobuf
首先我们需要看下自己电脑上是否存在其它的 protobuf 版本,指令如下:
whereis protoc
输出如下:

可以看到 protoc 存在两个路径,一个是 conda 下面的,这个是 python 环境下面的,另一个是博主之前安装的 3.11.4 版本的 protobuf
如果系统中存在 protobuf,我们可以输入如下指令看看当前系统默认的 protobuf 的版本:
protoc --version

可以看到此时博主的 protobuf 的版本是 3.20.3,显然是不满足 3.6.1 的,因此我们需要重新编译一个 3.6.1 版本的 protobuf,首先我们需要把 3.6.1 版本的 protobuf 源码给克隆下来,指令如下:
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git checkout v3.6.1
git submodule update --init --recursive
由于整个项目也比较大,拉取非常耗时,这边大家可以直接下载博主准备好的源码,不需要自己去拉取下载了,下载链接:Baidu Drive【pwd:cuda】
下载完成后我们就可以进行编译了,进入 protobuf 文件夹,执行如下指令:
cd protobuf
bash autogen.sh
./configure
make -j$(nproc)
make -j$(nproc) check
sudo make install
在执行 make -j$(nproc) check 你可能会遇到如下问题:

这主要是权限问题,解决办法参考自 here,终端输入如下指令赋权限即可:
chmod 777 src/google/protobuf/compiler/zip_output_unittest.sh
chmod 777 src/google/protobuf/io/gzip_stream_unittest.sh
再重新执行:
make -j$(nproc) check
此时可以看到正常输出了,如下图所示:

之后再执行如下指令即可完成安装
sudo make install
如果想要卸载的话可执行如下指令
cd protobuf
sudo make uninstall
安装完成后在对应的路径可以看到 protobuf 的 bin、include 和 lib 三个文件夹,并且 protoc 输出的版本也是 3.6.1,如下图所示:
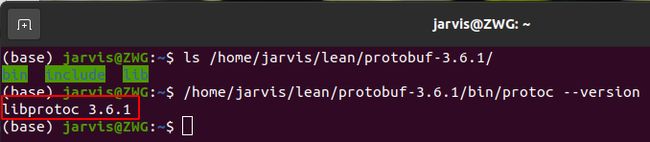
值得注意的是上述 protobuf 编译安装后默认安装在系统的标准目录 /usr/local 下,如果想要安装在指定位置,可以执行 ./configure --prefix=/home/jarvis/lean/protobuf-3.6.1 安装在自己指定的路径,不过这种情况下可能需要手动设置环境变量,在配置文件 ~/.bashrc 中添加如下内容即可:
export PATH="home/jarvis/lean/protobuf-3.6.1/bin:$PATH"
export LD_LIBRARY_PATH="home/jarvis/lean/protobuf-3.6.1/lib:$LD_LIBRARY_PATH"
博主这边选择的是安装到自己指定的目录,大家可以根据实际情况自行选择
OK,以上就是从源码编译 Protobuf 的整体流程了,其实也比较简单,安装过程没有什么出现奇怪的问题,唯一比较难的点可能在于 Protobuf 项目的完整拉取,毕竟有 100 多 M,需要开代理
2.6 编译运行
OK,项目、模型、数据文件准备好了,必要的软件也已经安装了,下面我们开始 CUDA-BEVFusion 的编译运行
在开始编译运行之前我们需要解决一个小 bug,也就是之前提到的在 Windows 下面拉取代码放到 Linux 上面时执行 shell 脚本文件时报错,如下图所示:

报错的原因是 Windows 和 Linux 的 .sh 脚本文件的编码不同,Windows 下的换行符是 \r\n 而 Linux 下的换行符是 \n,没有识别 \r
解决办法是将从 Windows 下载的所有文件格式转换为 Linux 的格式,指令如下:
sudo apt get install dos2unix
cd LiDAR_AI_Solution
find . -type f -print0 | xargs -0 dos2unix
这条 Linux 指令是用来将当前目录(及其子目录)下的所有文件从 DOS/Windows 格式转换为 Unix/Linux 格式,参考自:here
值得注意的是博主在网盘中提供的 LiDAR_AI_Soulution 和 Protobuf 的源码中的编码格式问题都已经修改好了,大家可以直接使用,无需修改
由于在 Windows 下拉取的代码放到 Linux 上存在编码问题,每次都要去修改也不太方便,因此你也可以在 Windows 下面装个 Linux 的虚拟机,通过 NAT 模式让虚拟机可以访问外网,这样就可以直接在虚拟机的 Linux 上拉取代码了,也不用担心编码的问题了,当然如果你在 Linux 上面有个好的代理当我没说
OK,解决掉编码问题后我们接着往下走
2.6.1 配置 environment.sh
修改 tool/environment.sh 文件中 TensorRT/CUDA/CUDNN/BEVFusion 变量值
# 修改为你当前使用的路径
export TensorRT_Lib=/path/to/TensorRT/lib
export TensorRT_Inc=/path/to/TensorRT/include
export TensorRT_Bin=/path/to/TensorRT/bin
export CUDA_Lib=/path/to/cuda/lib64
export CUDA_Inc=/path/to/cuda/include
export CUDA_Bin=/path/to/cuda/bin
export CUDA_HOME=/path/to/cuda
export CUDNN_Lib=/path/to/cudnn/lib
# resnet50/resnet50int8/swint
export DEBUG_MODEL=resnet50int8
# fp16/int8
export DEBUG_PRECISION=int8
export DEBUG_DATA=example-data
export USE_Python=OFF
博主修改后如下所示:
export TensorRT_Lib=/home/jarvis/lean/TensorRT-8.6.1.6/lib
export TensorRT_Inc=/home/jarvis/lean/TensorRT-8.6.1.6/include
export TensorRT_Bin=/home/jarvis/lean/TensorRT-8.6.1.6/bin
export CUDA_Lib=/usr/local/cuda-11.6/lib64
export CUDA_Inc=/usr/local/cuda-11.6/include
export CUDA_Bin=/usr/local/cuda-11.6/bin
export CUDA_HOME=/usr/local/cuda-11.6/
export CUDNN_Lib=/usr/local/cuda-11.6/lib64
# resnet50/resnet50int8/swint
export DEBUG_MODEL=resnet50int8
# fp16/int8
export DEBUG_PRECISION=int8
export DEBUG_DATA=example-data
export USE_Python=OFF
修改完成后在终端执行 environment.sh 文件,指令如下:
cd CUDA-BEVFusion
bash tool/environment.sh
博主执行完之后如下图所示:

从输出信息可以看到配置的环境的一些信息,包括使用的模型、软件环境路径等等,大家可以对照下看是否符合自己的预期
2.6.2 利用TensorRT构建模型
环境配置好后需要利用 TensorRT 的 trtexec 将 ONNX 模型构建成对应的 engine 引擎文件,指令如下:
bash tool/build_trt_engine.sh
博主执行完之后如下图所示:
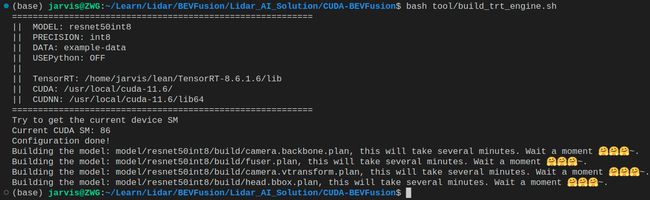
大家从输出信息也能看到 TensorRT 构建的模型主要包含以下四个模块:
- camera.backbone.plan:相机主干网络模块
- camera.vtransform.plan:相机视角转换模块
- fuser.plan:融合模块
- head.bbox.plan:检测头模块
那这里大家可能会有疑惑 lidar.backbone.xyz.onnx 点云主干网络模块为什么没有通过 TensorRT 构建 engine 呢,那这点其实我们前面也提到过,因为稀疏卷积,稀疏卷积输出维度只有通过卷积后才能确定的特性导致无法通过 TensorRT 来推理,因此只能另辟蹊径,具体是怎么做的呢,博主认为应该是通过 3DSparseConvolution 这个库利用 onnx-parser 解析器自己解析 ONNX 文件从而完成 LiDAR 主干网络的前向推理过程,NVIDIA 也提供了 spconv 编译好的动态库和对应的接口文件,由于未开源因此内部具体的加速实现我们也无从得知
执行成功后生成的 engine 保存在 model/resnet50int8/build 文件夹下,此外还有对应 engine 的 .log 日志文件以及 .json 文件,JSON 文件保存着各个 engine 的各个 layer 详细的信息,如下图所示:
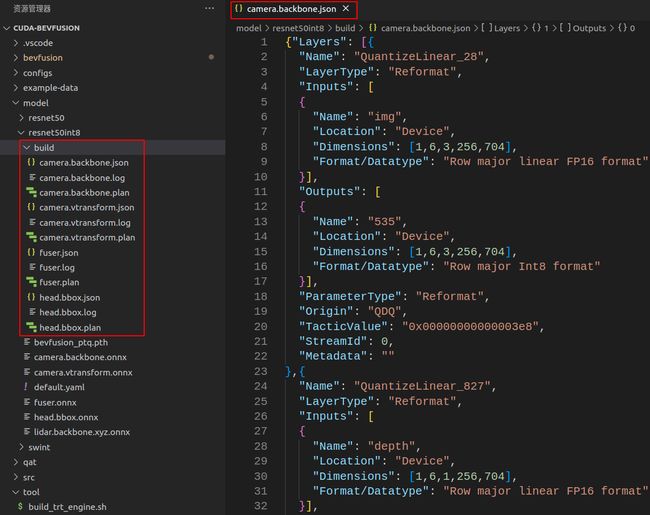
这里还需要注意几个点:
- Note 1:这里面对于 camera backbone 以及 fuser 模块的 onnx 是可以 fp16 或者 int8 的,但相反 camera vtransform 以及 head 是固定在 fp16 的。这可能是因为 head 靠近输出属于敏感层,tensor 里面的信息很重要需要高精度保留更多的信息
- Note 2:lidar backbone 的 onnx 并没有通过 trtexec 创建推理引擎,那具体是如何完成推理的,详细可以在 bevfusion 的 c++ 实现中找答案
- Note 3:这里 int8 量化的时候并没有进行 calibration 校准,是因为我们在进行 int8 推理的时候读取的 onnx 是带有 QDQ 节点的,里面存储了 calibration 的量化信息。而 TRT8 版本之后是能够直接加载带有 QDQ 节点的 ONNX 模型的,TensorRT 在创建模型的时候会根据 QDQ 节点的 scale 值进行层融合等优化。相反吗,如果 onnx 模型中没有 QDQ 节点的话,使用 int8 推理需要在 trtexec 创建模型的时候进行 calibration 来计算各个层的量化 scale
2.6.3 编译运行程序
OK,环境配置好了,模型也准备好了,下面我们可以编译运行了,指令如下:
bash tool/run.sh
博主执行后如下图所示:



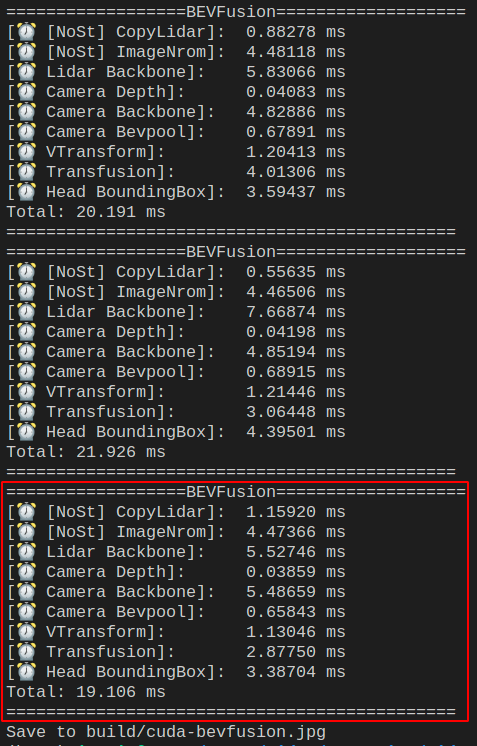
保存的推理图片如下所示:

至此,CUDA-BEVFusion 的环境配置以及推理运行到这里就结束了,下面我们再来看看 Python 接口的推理
2.7 拓展-Python接口
主要包含以下几点:
- 1. 启用 environment.sh 文件中的 python 编译
USE_Python=ON - 2. 执行
bash tool/run.sh构建 libpybev.so - 3. 执行
python tool/pybev.py测试 python 接口
下面我们过一遍整体流程,首先我们需要去 environment.sh 中打开 USE_Python,如下所示:
export TensorRT_Lib=/home/jarvis/lean/TensorRT-8.6.1.6/lib
export TensorRT_Inc=/home/jarvis/lean/TensorRT-8.6.1.6/include
export TensorRT_Bin=/home/jarvis/lean/TensorRT-8.6.1.6/bin
export CUDA_Lib=/usr/local/cuda-11.6/lib64
export CUDA_Inc=/usr/local/cuda-11.6/include
export CUDA_Bin=/usr/local/cuda-11.6/bin
export CUDA_HOME=/usr/local/cuda-11.6/
export CUDNN_Lib=/usr/local/cuda-11.6/lib64
# resnet50/resnet50int8/swint
export DEBUG_MODEL=resnet50int8
# fp16/int8
export DEBUG_PRECISION=int8
export DEBUG_DATA=example-data
export USE_Python=ON # 打开 Python 接口
然后我们再执行如下指令:
bash tool/enviroment.sh
输出如下:
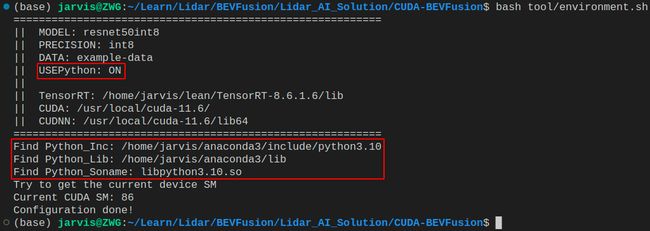
可以看到 Python 接口被打开了,并找到了关于 Python 的一些头文件和库文件
接着我们再执行运行指令构建 libpybev.so,指令如下所示:
bash tool/run.sh
你可能会看到如下错误:


我们从输出信息可以看到 CMake 在找 Protobuf 时存在一些警告导致最终程序崩溃,这个问题是因为 CMake 在寻找库时遵循的路径优先级导致的,在当前博主的软件环境下 CMake 优先选择了 Anaconda 环境中的 Protobuf 库而不是系统级别的库。
博主认为是 CMake 找库的优先级导致的,因此博主在 CMakeLists.txt 强制设置了 Protobuf 的搜索路径,如下所示:
# CMakeLists.txt 第 31 行
# find_package(Protobuf REQUIRED)
# 修改为你自己安装的 Protobuf 路径
# apt 安装在 /usr 下,源码安装默认也是在 /usr
set(Protobuf_ROOT "/usr")
find_package(Protobuf 3.6.1 REQUIRED)
这会告诉 CMake 在 /usr 目录下寻找 Protobuf 3.6.1 版本的库,而不是默认查找 Anaconda 环境下的库,但是修改后测试时问题依旧存在,最终博主是通过更换 conda 虚拟环境解决了这个问题
博主当前的虚拟环境是 conda 默认的 base 虚拟环境,因此博主更换了另一个虚拟环境,并重新执行了上述指令,如下所示:
# 激活你自己的虚拟环境
conda activate yolov8
bash tool/environment.sh
bash tool/run.sh
输出如下:
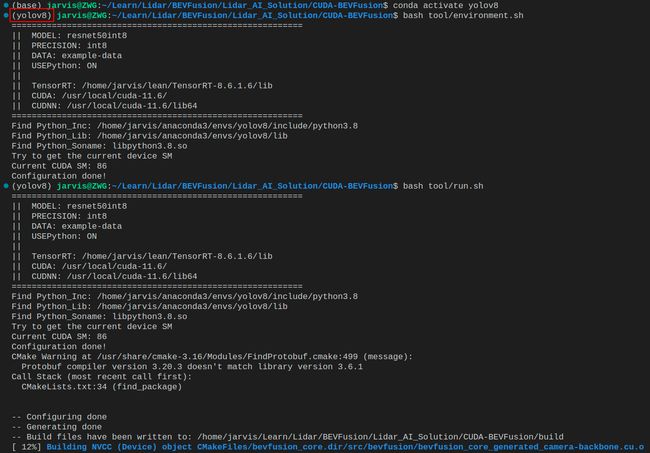
可以看到 Python 的头文件和库文件的搜索路径发现了变换,是从虚拟环境 yolov8 去找的,另外 CMake 也没有 Protobuf 库的警告了,直接运行通过了
libpybev.so 通过上述方式生成了,接着我们就需要来测试 Python 接口了,如下所示:
python tool/pybev.py
执行后你可能会遇到如下的问题:

从错误信息可以看出问题在于环境变量 DEBUG_MODEL 没有在执行 Python 脚本时被正确设置,而 DEBUG_MODEL 变量是在 environment.sh 脚本文件中设置的,如果在运行 environment.sh 后在同一个 shell 中没有直接运行 Python 脚本,那么 Python 脚本将不会继承这些环境变量,导致出错
因此在执行 Python 脚本文件之前我们需要使用 source 命令来执行 environment.sh 脚本,这样会将 environment.sh 中定义的环境变量加载到当前的 shell 会话中,然后在同一个 shell 会话中直接运行 Python 脚本,指令如下:
source tool/environment.sh
python tool/pybev.py
输出如下:

可以看到正常执行了,至此,Python 接口的使用到这里就结束了
2.8 拓展-Debug调试配置
后续我们在学习 CUDA-BEVFusion 的代码时,肯定是需要进行一步步调试分析的,因此我们来配置下调试
其实也比较简单,我们在 CMakeLists.txt 中将 26 行的 Release 注释,将 27 行的 Debug 打开即可,如下所示:
# CMakeLists.txt 26 行
# set(CMAKE_BUILD_TYPE "Release")
set(CMAKE_BUILD_TYPE "Debug")
接着再执行 bash tool/run.sh 完成 Debug 模式的编译工作,然后在 main.cpp 中打一个断点,在 vscode 中按 F5 即可开始调试,如下图示所示:

可以看到正常进入调试模式了,接着大家可以愉快的调试了
OK,以上就是整个 CUDA-BEVFusion 的环境配置过程了,其实也不是很难,大家遇到问题可以多查阅下相关资料,多看看 issue
3. 推理结果浅析
我们最后再看一下推理时间,推理环境如下:
-
CPU
- Intel i5-12400F @ 2.50GHz
- 64 bit
- 6 core
-
GPU
- NVIDIA RTX 3060
-
model
- ResNet50int8
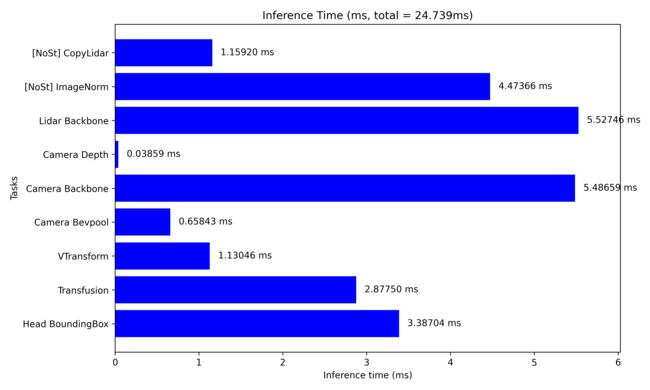
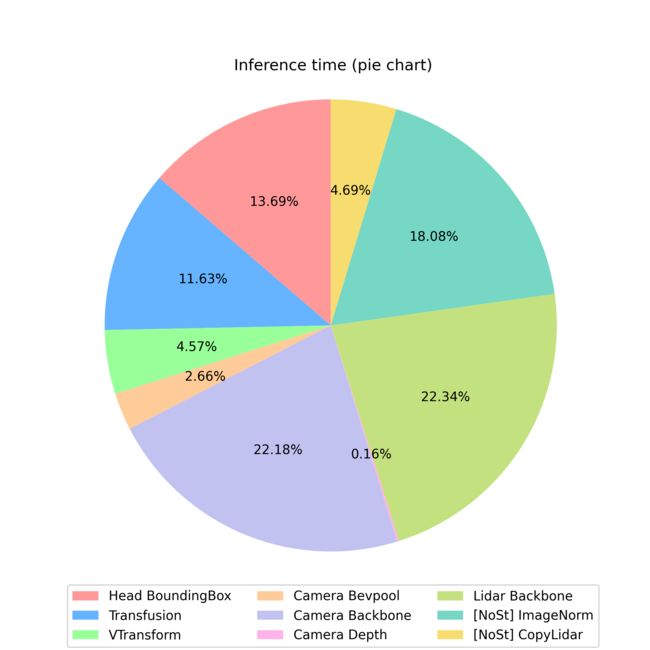
那上面是博主绘制的 CUDA-BEVFusion 的推理速度表格和饼状图,看起来比较直观,整体而言 head 部分还是较重,因为这里面会有一些 cpu 的操作,其次针对 LiDAR backbone 和 Camera 的 ResNet 的 backbone 也很重,然而 camera 的分辨率还只是 256x704,工业化需要的分辨率会远大于这个,所以实际落地使用的话需要的推理时间会更长
自动驾驶场景中我们往往需要关注百米远的物体比如红绿灯或者指示牌,这是因为后期我们做 planing 规划和决策时需要提早知道红绿灯或者指示牌给的一些信息,这样才方便我们后期决策,所以远方小物体的检测是自动驾驶中的一个难题,而 256x704 分辨率的图像是远远不够的,我们一般需要 1080p 甚至 2K 的图像才能检测到那么远的小物体
另外 BEV Grid 的大小是 360x360,每个 Grid 如果代表 0.4m 的话,那车辆所能探测的最远距离是 180x0.4=72m(以车辆为中心),这也意味着 BEVFusion 做工业部署还是有很强的可扩展性,需要去进一步优化,那如果我们想要探测百米开外的小物体则需要扩大 BEV Grid 的大小,那 Grid 的增大随之带来的是计算量以及推理时间的增加
还有这是 RTX3060 的数据,如果是部署的话考虑的还是边缘设备比如 Jetson AGX Orin 等等,其实推理时间还是比较长的。另外 CUDA-BEVFusion 项目中也提到 camera backbone 是比较耗时的,看有没有一些其他的办法进行优化,lidar backbone 可以考虑 cuPCL 的优化做进一步的加速,也是有可发展空间的
那以上就是第 1 小节的全部内容了,我们理解了 CUDA-BEVFusion 后我们从下一个小节开始会去跟大家去讲 spconv
总结
这节课我们学习了 CUDA-BEVFusion 的一些基础知识以及环境搭建,CUDA-BEVFusion 是 BEVFusion 多模态融合感知算法的部署框架,由 NVIDIA 开源在 LiDAR_AI_Solution 项目下,它对 Sparse Convlution、BEVPool 等都实现了加速非常值得大家学习。此外我们还跟随其 README 文档一起搭建了基本的环境,其难点在于整个项目的完整下载以及 protobuf 特定版本的安装,最后我们还分析了 CUDA-BEVFusion 的推理时间以及其存在局限性,离真正的工业化使用还是有一点的距离,有进一步的扩展和优化空间。
OK,以上就是第 1 小节的全部内容了,下节我们将去学习 spconv 的原理,敬请期待
这是博主 2023 年度的最后一篇文章了,感谢大家长期以来的关注,我们 2024 年见,最后提前祝大家新年快乐
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
- 代码和安装包下载链接【提取码:cuda】
参考
- LiDAR_AI_Solution环境配置
- 一. BEV感知算法介绍
- 三. LiDAR和Camera融合的BEV感知算法-BEVFusion
- https://github.com/mit-han-lab/bevfusion
- https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution/CUDA-BEVFusion
- BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
- BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation