MySQL第五章:汇总数据
**内容来自: **
1、b站mosh老师的SQL课程(第五章) 【中字】SQL进阶教程 | 史上最易懂SQL教程!10小时零基础成长SQL大师!!_哔哩哔哩_bilibili www.bilibili.com/video/BV1UE41147KC/?p=17&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=171e84ea90c06aa5a434d7fa2502e75c
2、https://zhuanlan.zhihu.com/p/222865842(非常感谢这位知乎大佬,笔记、课件写的很详细)
《SQL必知必会(第五版)》这部分内容这个月后期会统一更新
3、https://zhuanlan.zhihu.com/p/206699786
各数据库字段之间的关联
聚合函数
作用:取字段值并聚合他们**(不包括空值)**,输出一个单一值
实例
题目:从发票记录表里筛选出 2019年下半年以后的记录,并汇总2019年下半年交易日期的最大值,汇总2019年下半年交易总额最小值和平均值,计算2019年下半年交易总额1.1倍、记录总数(两种方法实现),汇总支付账单的记录总数、顾客数(包括未付款的)。
解释invoices表中字段invoice_total和payment_total之间的关系:
invoice_total是账单消费的价格总额,只要invoice_date不是null,invoice_total是就会有值;而payment_total是账单消费生成后顾客付款的金额,是和payment_date捆绑在一起,只要payment_date是null,则payment_total为0.
USE sql_invoicing;
SELECT
MAX(invoice_date) AS latest_date,
-- SELECT选择的不仅可以是列,也可以是数字、列间表达式、列的聚合函数
MIN(invoice_total) AS lowest,
AVG(invoice_total) AS average,
SUM(invoice_total * 1.1) AS total, -- 先检索出invoice_total字段,再乘1.1,然后求和并命名为total
COUNT(*) AS total_records,
COUNT(invoice_total) AS number_of_invoices,
-- 和上一个相等
COUNT(payment_date) AS number_of_payments,
-- 【聚合函数会忽略空值】,得到的支付数少于发票数
COUNT(DISTINCT client_id) AS number_of_distinct_clients
-- DISTINCT client_id 筛掉了该列的重复值,再COUNT计数,会得到不同顾客数
FROM invoices
WHERE invoice_date > '2019-07-01' -- 想只统计下半年的结果
注意:
函数后面都要加上括号。
练习
题目:计算下表中空缺的数据,并让最后筛选出的表格格式与下面一样。
date_range total_sales total_payments what_we_expect (the difference) 1st_half_of_2019 2nd_half_of_2019 Total
USE sql_invoicing;
SELECT
'1st_half_of_2019' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
-- 或者(sum(invoice_total) -sum(payment_total)) as what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-01-01' AND '2019-06-30'
UNION
SELECT
'2st_half_of_2019' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-07-01' AND '2019-12-31'
UNION
SELECT
'Total' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-01-01' AND '2019-12-31'\
GROUP BY子句
按一列或多列分组,注意语句的位置。
案列1:按一个字段分组
题目:在发票记录表中按不同顾客分组统计下半年总销售额并降序排列
USE sql_invoicing;
SELECT
client_id,
SUM(invoice_total) AS total_sales
FROM invoices
WHERE invoice_date >= '2019-07-01' -- 筛选,过滤器
GROUP BY client_id -- 分组
ORDER BY total_total DESC
-- 或者ORDER BY SUM(invoice_total) DESC
只有聚合函数是按 client_id 分组时,这里选择 client_id 列才有意义(分组统计语句里SELECT通常都是选择分组依据列+目标统计列的聚合函数,选别的列没意义)
注意:
- 若未分组,会报错,因为使用聚合函数(如
SUM(),COUNT(),AVG()等)对某些列进行操作时,需要用GROUP BY子句来指定基于哪些非聚合列进行分组;从逻辑上来说,不使用GROUP BY而直接使用聚合函数会导致 SQL 对整个结果集应用该聚合函数,而不是对每个客户单独应用,不符合需求;- 语句顺序很重要 FROM—WHERE—GROUP BY(永远在from和where的后面)----ORDER BY,分组语句在排序语句之前,调换顺序会报错。
案例2:按多个字段分组
题目:计算各州各城市的总销售额,并按各州名称升序排列。

提示:
sql_invoicing表中一个城市只能属于一个州中,所有归根结底还是算的各城市的销售额
USE sql_invoicing;
SELECT
state,
city,
SUM(invoice_total) AS total_sales
FROM invoices
JOIN clients USING (client_id)
-- 别忘了USING之后是括号,太容易忘了
GROUP BY state, city
-- 逗号分隔就行
-- 这个例子里 GROUP BY 里去掉 state 结果一样(建议不要省略)
ORDER BY state
练习
题目:在 payments 表中,按日期和支付方式(不能是数字编码)分组统计总付款额,并按照日期升序排列

USE sql_invoicing;
SELECT
date,
pm.name AS payment_method,
SUM(amount) AS total_payments
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY date, payment_method
-- 用的是 SELECT 里的列别名
ORDER BY date
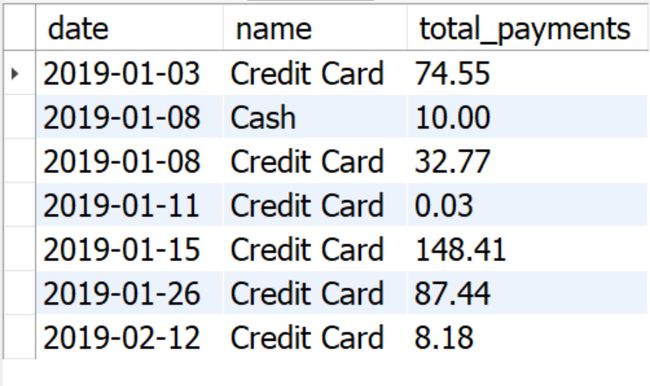
结果解读:
每一条记录显示一个日期和支付方式的独立组合,可以看到某特定日期和特定支付方式条件筛选出的总付款额。这个例子里每一种支付方式可以在不同日子里出现,每一天也可以出现多种支付方式,这种情况,才叫真·多字段分组。不过上一个例子里那种(每个州只有一个城市,一个city对应一个state)为假·多字段分组。
总结
解答复杂问题时,学会先分解拆分为简单的小问题或小步骤逐个击破。合理运用分解组合和IPO(input-process-output 输入-过程-输出)思想。
HAVING
HAVING 和 WHERE 都是是条件筛选语句,条件的写法相通,数学、比较(包括特殊比较)、逻辑运算都可以用(如 AND、REGEXP 等等)
两者本质区别:
- WHERE 是对 FROM JOIN 里原表中的列进行 事前筛选,所以WHERE可以对没选择的列进行筛选,但必须用原表列名而不能用SELECT中确定的列别名;
- HAVING …… 对 SELECT …… 查询后(通常是分组并聚合查询后)的结果列进行事后筛选,若SELECT里起了别名的字段则可以用别名进行筛选,也可以用聚合函数(原名),且不能对SELECT里未选择的字段进行筛选。唯一特殊情况是,当HAVING筛选的是聚合函数时,该聚合函数可以不在SELECT里显性出现。
案列
题目:
筛选出总发票金额大于500且总发票数量大于5的顾客
USE sql_invoicing;
SELECT
client_id,
SUM(invoice_total) AS total_sales,
COUNT(*/invoice_total/invoice_date) AS number_of_invoices
FROM invoices
GROUP BY client_id
HAVING total_sales > 500 AND number_of_invoices > 5
-- 均为 SELECT 里的列别名
为什么不能在
from invoices后面用where total_sales > 500 and number_of_invoices > 5?
- WHERE子句的顺序不能在GROUP BY的后面;
- 此时挑选出来的记录不是以顾客id为第一筛选条件,此时的筛选条件是发票金额大于500且发票数量大于5,对题目来说是无效的;(where可以使用任何字段,无论在不在select的语句里)
- 当select中存在未使用聚合函数作用的字段时,需要用group by来深明DBMS基于哪些非聚合字段进行分组。
练习
题目:
在 sql_store 数据库(有顾客表、订单表、订单项目表等)中,找出在 ‘VA’ 州且消费总额超过100美元的顾客(两种方法实现)
思路:
- 需要的信息在顾客表、订单表、订单项目表三张表中,先将三张表合并;
- WHERE 事前筛选 ‘VA’ 州的;
- 按顾客分组,并选取所需的列并聚合得到每位顾客的付款总额;
- HAVING 事后筛选超过 100美元 的。
-- 法一
USE sql_store;
SELECT
c.customer_id,
c.first_name,
c.last_name,
SUM(oi.quantity * oi.unit_price) AS total_sales
FROM customers c
JOIN orders o USING (customer_id) -- 别忘了括号,特容易忘
JOIN order_items oi USING (order_id)
WHERE state = 'VA'
GROUP BY
c.customer_id,
c.first_name,
c.last_name
HAVING total_sales > 100
-- 法二
USE sql_store;
SELECT
c.customer_id,
c.first_name,
c.last_name,
SUM(oi.quantity * oi.unit_price) AS total_sales
FROM orders o
JOIN customers c USING (customer_id) -- 别忘了括号,特容易忘
JOIN order_items oi USING (order_id)
WHERE state = 'VA'
GROUP BY
c.customer_id,
c.first_name,
c.last_name -- 只用id进行分组就行(id与名字和姓氏是一一对应的)
HAVING total_sales > 100
MySQL中多表连接的顺序
在MySQL中,对于多表关联的顺序有两种准则:
FROM一个核心表A(与BCD三个表都有关系),用多个JOIN …… ON ……分别通过不同的链接关系链接不同的表B、C、D……,通常是让表B、C、D……为表A提供更详细的信息从而得到一张合并了BCD……等表详细信息的合并版A表(只有表里有相同的列才能连接)。同时也允许各表之间随便排列,只要保证表与表之间的关联条件正确且能把几个表连在一起即可。
注意:
SQL 语言的核心是对表的引用,最终都是在联合表上进行字段筛选和数据加工。
补充
题目:
用两种写法都能筛选出总点数大于3k的州
-- 法一
SELECT state, SUM(points)
FROM customers
GROUP BY state
HAVING SUM(points) > 3000
-- 法二(除非要求不要求显示总积分数)
SELECT state
FROM customers
GROUP BY state
HAVING SUM(points) > 3000
注意:
当 HAVING 筛选的是聚合函数时,该聚合函数可以不在SELECT里显性出现
ROLLUP
GROUP BY …… WITH ROLL UP 自动汇总型分组,若是多字段分组group by column1, column2, column3 with roll up的话汇总则是按照【column1, column2, column3】、【column1, column2】,【column1】进行分组统计,同时还会去掉所有分组字段进行一次统计,因此会有n+1次分组。
注意:这是MySQL扩展语法,不是SQL标准语法,仅仅在MySQL中才有
案例1(单字段分组)
题目:分组查询各客户的发票总额以及所有人的总发票额
USE sql_invoicing;
SELECT
client_id,
SUM(invoice_total)
FROM invoices
GROUP BY client_id WITH ROLLUP
输出结果:
结果解读:
最后一行是所有人的总发票额。
案例2(多字段分组)
题目:
分组查询各州、市的总销售额(发票总额);
分组查询州层次的总销售额(发票总额);
分组查询全国层次的总销售额(发票总额);
SELECT
state,
city,
SUM(invoice_total) AS total_sales
FROM invoices
JOIN clients USING (client_id)
GROUP BY state, city WITH ROLLUP
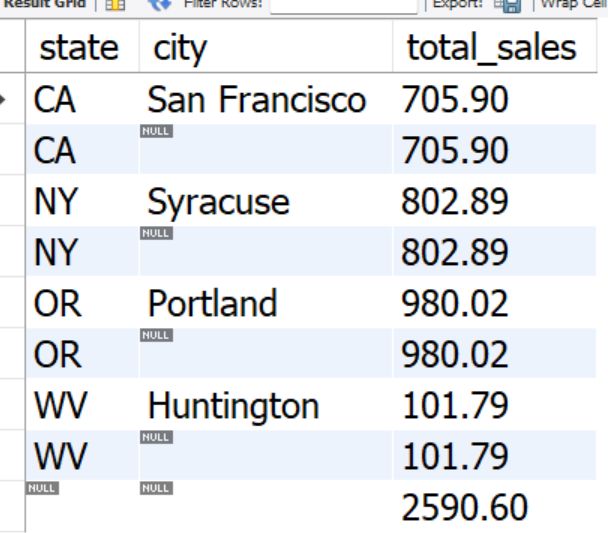
案例3(多字段分组)
题目:
分组查询特定日期特定付款方式的总支付额以及单日汇总和整体汇总
USE sql_invoicing;
SELECT
date,
pm.name AS payment_method,
SUM(amount) AS total_payments
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY date, pm.name WITH ROLLUP
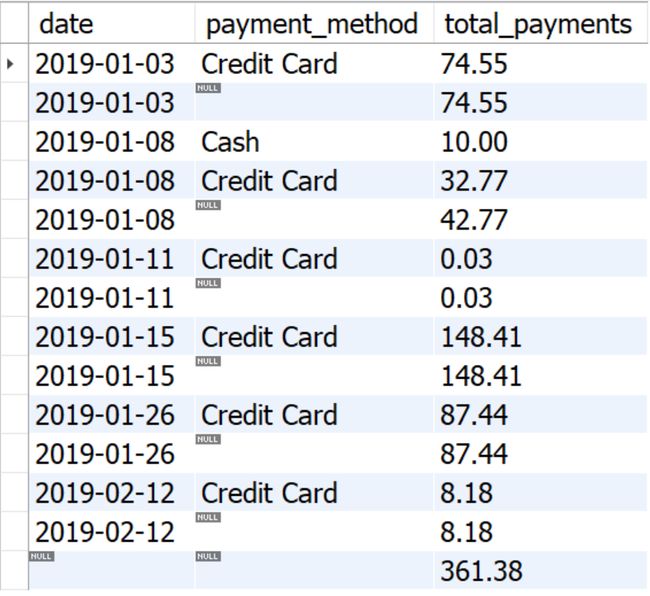
注意:
groupby不能不使用在 select 中设定别名,因为select 是在 from 和 group by 之后执行的.
练习
题目:分组计算各个付款方式的总付款 并汇总
SELECT
pm.name AS payment_method,
SUM(amount) AS total
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY pm.name WITH ROLLUP
补充(多字段查询)
题目:
分组查询特定日期特定付款方式和顾客id的总支付额以及单日汇总、单日特定付款方式汇和整体汇总
USE sql_invoicing;
SELECT
date,
pm.name AS payment_method,
client_id,
SUM(amount) AS total_payments
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY date, pm.name, client_id WITH ROLLUP

验证:
group by column1, column2, column3 with roll up的话汇总则是按照【字段1,字段2,字段3】、【字段1,字段2】,【字段1】进行分组统计,同时还会去掉所有分组字段进行一次统计,因此会有n+1次分组。
总结
MySQL的语句顺序select...distinct...from...join...on...where......group by...having...union...order by...limit...,在SQL的执行顺序:from...join...on...where......group by...having...select..distinct....union...order by...limit...,MySQL的处理顺序:from...join...on...where......group by...select..distinct....having...union...order by...limit...
注意:
SQL 的处理顺序遵循一个特定的逻辑顺序,但这不一定反映了数据库管理系统内部的实际操作顺序,DBMS的处理顺序中select在having之前(mysql的处理方式是中间生成虚拟表或者叫临时表,而这个虚拟表的生成的列靠的就是select,所以having之后的操作,其实内部已经根据select生成了虚拟表,列自然也是as后的);
FROM 才是 SQL 语句执行的第一步,并非 SELECT 。数据库在执行 SQL 语句的第一步是将数据从硬盘加载到数据缓冲区中,以便对这些数据进行操作;
SELECT 是在 FROM 和 GROUP BY 之后执行的,因此不能在 WHERE 和GROUP BY中使用在 SELECT 中设定别名;
尽量使用 JOIN 进行表的连接,永远不要在 FROM 后面使用逗号连接表;
如果有 GROUP BY 语句,SELECT语句中只能够使用 GROUP BY 语句后面的字段或者聚合函数;
不能在一个没有 GROUP BY 的 SELECT 语句中同时使用普通函数和聚合函数。因为在既有聚合函数又有普通函数的 SQL 语句中,如果没有 GROUP BY 进行分组,SQL 语句默认视整张表为一个分组,当聚合函数对某一字段进行聚合统计的时候,引用的表中的每一条 record 就失去了意义,此时表中全部的数据都最后都会被筛选为一个统计值,你此时对每一条 record 使用其它函数是没有意义的;
集合运算: DISTINCT 和 UNION ;
排序运算:ORDER BY,OFFSET。
注意:
排序运算不仅在 SQL 语句的最后,而且在 SQL 语句运行的过程中也是最后执行的。