Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]
目录
1.文章要解决的问题:长期时间序列预测(值得研究的方向)
2.解决方法(贡献,创新点):
深度分解架构(Deep Decomposition Architecture)
原文部分
自相关机制(Auto-correlation mechanism)
这里傅里叶相关的知识大家自己 去网上看吧,挺多的,FFT应用领域很广泛比如还有CV的图像压缩。
3.具体实验
数据集概括:
完成细节:参数配置与显卡环境
其他Baseline
实验主要的结果//这段官方分析讲的很好,好好看
消融实验
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
1.文章要解决的问题:长期时间序列预测(值得研究的方向)
长期时间序列预测问题:待预测的序列长度远远大于输入长度,即基于有限的信息预测更长远的未来。上述需求使得此预测问题极具挑战性,对于模型的预测能力及计算效率有着很强的要求。
以前的方法有什么问题?
之前基于Transformer的时间序列预测模型,通过自注意力机制(self-attention)来捕捉时刻间的依赖,在时序预测上取得了一些进展。但是在长期序列预测中,仍存在不足:
-
长序列中的复杂时间模式使得注意力机制难以发现可靠的时序依赖。
-
基于Transformer的模型不得不使用稀疏形式的注意力机制来应对二次复杂度的问题,但造成了信息利用的瓶颈。//logsparse attention工作
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第1张图片](http://img.e-com-net.com/image/info8/e23bf1cd8fbe42938e1d26e5476bc6bb.jpg)
2.解决方法(贡献,创新点):
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第2张图片](http://img.e-com-net.com/image/info8/b090c7ce229c4b8cb9e6ef14136e141c.jpg)
为突破上述问题,THUML(清华大学软件学院机器学习组)全面革新了Transformer,并提出了名为Autoformer的模型,主要包含以下创新:
-
突破将序列分解作为预处理的传统方法,提出深度分解架构(Decomposition Architecture),能够从复杂时间模式中分解出可预测性更强的组分//针对之前注意力机制工作不能发现可靠的时序依赖
-
基于随机过程理论,提出自相关机制(Auto-Correlation Mechanism),代替点向连接的注意力机制,实现序列级(series-wise)连接和O(LlogL)复杂度,打破信息利用瓶颈//针对二次复杂度与信息利用的瓶颈不能兼而有之的问题
在长期预测问题中,Autoformer在能源、交通、经济、气象、疾病五大时序领域大幅超越之前SOTA,实现38% 的相对效果提升。//果真吗?
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第3张图片](http://img.e-com-net.com/image/info8/dd4b448e4dc24670b71647a9eaf83388.jpg)
深度分解架构(Deep Decomposition Architecture)
时间序列分解是指将时间序列分解为几个组分,每个组分表示一类潜在的时间模式,如周期项(seasonal),趋势项(trend-cyclical)。由于预测问题中未来的不可知性,通常先对过去序列进行分解,再分别预测。但这会造成预测结果受限于分解效果,并且忽视了未来各个组分之间的相互作用。
我们提出深度分解架构,将序列分解作为Autoformer的一个内部单元,嵌入到编-解码器中。在预测过程中,模型交替进行预测结果优化和序列分解,即从隐变量中逐步分离趋势项与周期项,实现渐进式分解。
原文部分
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第4张图片](http://img.e-com-net.com/image/info8/228d05b05bd9495e9f17926ce19c2969.jpg)
模型输入:使用encoder输入的后一半作为输入来提供最近的信息,所以是![]()
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第5张图片](http://img.e-com-net.com/image/info8/7b92d0863e2343b48504f5b6f4e67d91.jpg)
Encoder
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第6张图片](http://img.e-com-net.com/image/info8/e9af7b19833642e699d5534f4d5120d6.jpg)
首先![]() 信号作为输入,把自相关之前与之后的结果相加再进入序列分解模块(Auto-Correlation到后文详解),Autoformer的Encoder部分更加关注Seasonal部分,去掉了trend part(“_”代表去掉了趋势项), 所以Encoder想把季节变换(周期变换)学的更加好一些,然后在Feed Forward源码里面是conv->relu->dropout->conv->dropout,其实就是一个编码过程,把编码前的结果与编码后的结果做一个相加,再经历一个序列分解
信号作为输入,把自相关之前与之后的结果相加再进入序列分解模块(Auto-Correlation到后文详解),Autoformer的Encoder部分更加关注Seasonal部分,去掉了trend part(“_”代表去掉了趋势项), 所以Encoder想把季节变换(周期变换)学的更加好一些,然后在Feed Forward源码里面是conv->relu->dropout->conv->dropout,其实就是一个编码过程,把编码前的结果与编码后的结果做一个相加,再经历一个序列分解
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第7张图片](http://img.e-com-net.com/image/info8/55c10ad9fc2548d4b1038faf6e370f8c.jpg)
Decoder
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第8张图片](http://img.e-com-net.com/image/info8/6dd61f103e894b45960f929728b864ad.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第9张图片](http://img.e-com-net.com/image/info8/1bb4934e94bb467b8aa44a07325de085.jpg)
Encoder主要关注Seasonal分支,所以在decoder这里接受encoder的输出,下方图中decoder中红框部分是Decoder处理Seansonal分支,下面这条线用于refine(提炼)trend分支,可通过上方公式简单理解。
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第10张图片](http://img.e-com-net.com/image/info8/d32c869b370244d6beca5a4d0cb2cd24.jpg)
自相关机制(Auto-correlation mechanism)
什么是自相关呢?
自相关是指信号在1个时刻的瞬时值与另1个时刻的瞬时值之间的依赖关系,是对1个随机信号的时域描述。
自相关(Autocorrelation),也叫序列相关,是一个信号与其自身在不同时间点的互相关。非正式地来说,自相关是对同一信号在不同时间的两次观察,通过对比来评判两者的相似程度。自相关函数就是信号x(t)和它的时移信号x(t-τ)的乘积平均值。它是时移变量τ的函数。
这个文章讲的很不错,推荐看看
自相关与互相关 - 知乎
![]()
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第11张图片](http://img.e-com-net.com/image/info8/92c56b34fb4b4f108c4200d32e0847fa.jpg)
 代表了延迟多少的意思,=1,代表lag1(滞后1) ,这里的Rxx(τ)自相关函数是为了找那些历史子序列与当前序列相似,这个函数可以作为metric去指导这件事情。
代表了延迟多少的意思,=1,代表lag1(滞后1) ,这里的Rxx(τ)自相关函数是为了找那些历史子序列与当前序列相似,这个函数可以作为metric去指导这件事情。
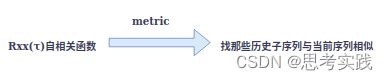
如果两段序列不是很对应的话,Rxx(τ)会变小,如1为当前序列,子序列2与1更相似,3与1不是那么相似。
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第12张图片](http://img.e-com-net.com/image/info8/683c4609d96e419da82fc1eb71ec9b31.jpg)
与 子序列各自与原序列的相关性系数序列 ![]() ,进行点对点的相乘如图figure2所示的那样,这里的k个序列是通过算子Topk从τ个序列选择出来的最相似的k个序列。
,进行点对点的相乘如图figure2所示的那样,这里的k个序列是通过算子Topk从τ个序列选择出来的最相似的k个序列。
为什么要选K个出来(k<τ)?否则计算量就太大啦?大多少?待会儿再看
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第13张图片](http://img.e-com-net.com/image/info8/95fcf948f8fe4c8997b0f4ccf846b84a.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第14张图片](http://img.e-com-net.com/image/info8/6b262c9590db4a0fbc950f1e56d9a47c.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第15张图片](http://img.e-com-net.com/image/info8/e0c2fd50b76547338c0d71882df1bf43.jpg)
解释一下Roll函数,Figure2(right)中通过roll得到时滞后的序列,然后得到原序列与序列![]()
各自的相关性
![]() ,
,
再把得到的相关性做一个softmax, 把相关性值转化为一个有概率分部规律的值

其中Zi为第i个节点的输出值,C为输出节点的个数,即分类的类别个数。通过Softmax函数就可以将多分类的输出值转换为范围在[0, 1],和为1的概率分布。
最后再通过Fusion进行一个加权融合,把这个滞后的子序列![]()
总结一下:
1.![]() 通过算子Topk得到
通过算子Topk得到
2.再通过SoftMax得到probability
3.算出probability再做Fusion加权平均
我们在这里用公式把上述描述的东西表达一下:
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第16张图片](http://img.e-com-net.com/image/info8/180e36684e3e4c41a4aff33ae1ecb07b.jpg)
最后这个AutoCorrelation(Q,K,v),大家可能有点迷糊,以前在传统Transformer里面这里是self-attention,我们现在换成Auto-Correlation了,通过的Fusion加权平均相当于一个attention-scorex序列(自相关系数x序列)的一个情况,就得到了关注序列
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第17张图片](http://img.e-com-net.com/image/info8/9a7c0571e91a4fcab0e413b7152ce7ef.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第18张图片](http://img.e-com-net.com/image/info8/842bf5a9254a450ca101139f9bf4e5bd.jpg)
与vanilla(普通的)transformer一样,类比在encoder与decoder之间的attention(粉色括号里面),K,V都来自encoder![]() ,并且会被Resize到length-O,Q来自之前的decoder模块
,并且会被Resize到length-O,Q来自之前的decoder模块
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第19张图片](http://img.e-com-net.com/image/info8/16f85a9985324e1a966549f0c91755d8.jpg)
谈一下效率问题,序列长度为n,你要lag N次,lag一次就要与原序列求一次相关性,这样计算的时间复杂度就会特别高,就是![]()
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第20张图片](http://img.e-com-net.com/image/info8/bd95749c54154918b8ef71d99adbec6c.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第21张图片](http://img.e-com-net.com/image/info8/e4de226c1465401cbb159169abc715c3.jpg)
作者为了加快这个过程,使用FFT去求这个相关性(真牛逼),这下time complexity直接降到![]()
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第22张图片](http://img.e-com-net.com/image/info8/3e37dbde75004accb42250a804e3f03f.jpg)
这里傅里叶相关的知识大家自己 去网上看吧,挺多的,FFT应用领域很广泛比如还有CV的图像压缩。![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第23张图片](http://img.e-com-net.com/image/info8/0c6213d9e6264b459ac6b9d57d67052f.jpg)
与其他attention family作对比
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第24张图片](http://img.e-com-net.com/image/info8/11f82621ee844885975f529ac76f67c6.jpg)
理论部分讲完了讲讲具体实验部分吧
3.具体实验
数据集概括:
We extensively evaluate the proposed Autoformer on six real-world benchmarks, covering five mainstream time series forecasting applications: energy, traffic, economics, weather and disease.
具体可以看论文里面P7介绍
https://arxiv.org/pdf/2106.13008.pdf
通常来讲评价指标都是MSE与MAE,预测的序列长度越大,表现越差,符合对长序列预测难度的定义
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第25张图片](http://img.e-com-net.com/image/info8/ae06365f3460495aac59c6a62d948c18.jpg)
完成细节:参数配置与显卡环境
L2 loss,Adam optimizer,lr=10e-4,Batch_size=32,early stop in 10 epochs,a single NVIDIA TITAN RTX 24GB GPUs,论文中的Autoformer代码Encoder用了两层(N=2),Decoder用了一层(M=1),自相关的超参数c在(1~3)的时候能够很好的权衡表现和效率
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第26张图片](http://img.e-com-net.com/image/info8/5059d51e65324e57bb165fa4b36fa081.jpg)
顺便查了一下清华这个小组用的GPU和当前使用的3090做对比,看是否能进行复现工作
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第27张图片](http://img.e-com-net.com/image/info8/2af89cf761f941ccad486709eb55f693.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第28张图片](http://img.e-com-net.com/image/info8/c12b660745d54bc4a6b72282b0b125eb.jpg)
其他Baseline

![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第29张图片](http://img.e-com-net.com/image/info8/dd13f59760974d4f9a12fe2864b0bc99.jpg) 实验主要的结果//这段官方分析讲的很好,好好看
实验主要的结果//这段官方分析讲的很好,好好看
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第30张图片](http://img.e-com-net.com/image/info8/45f1b9af10f34972994df172f8a77d19.jpg)
最后这段的最后一句不愧是大家之作,提出了别人工作表现最好分析原因,再道出其不好之处突出自己的工作,让人信服又认可。
消融实验
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第31张图片](http://img.e-com-net.com/image/info8/2e2735687f6a41d585c7f6e0b03434e4.jpg)

下面这个工作把Auto-Correlation替换为self-attention family做对比,当序列很长的时候,AC能够有更好的memory efficiency,表中“_”都爆内存了,这个表格还有一个反直觉的现象,就是输入长度变大的时候,输出不变,反而MSE变小,直觉理解是历史参考越久,预测相同的情况下会有更好的表现,有个猜测的原因可能是因为(数据集maybe)参考过久了历史的子序列,可能对未来序列预测没有太大影响反而会引入一些噪声,打比方在股市时效性比较高,市场变化比较快的情况下,大家一般会更关注近一年的股票表现,甚至近半年或者一个月做参考,不会出现拿过去五年的数据去评估未来的趋势。
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第32张图片](http://img.e-com-net.com/image/info8/150a1af92d7141b6b022515b727301b9.jpg) 模型分析
模型分析
渐进式分解效果: 随着序列分解单元的数量增加,模型的学到的趋势项会越来越接近数据真实结果,周期项可以更好的捕捉序列变化情况,这验证了渐进式分解的作用。
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第33张图片](http://img.e-com-net.com/image/info8/d04aab57a23f4a67a57b65d9b5ba05ba.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第34张图片](http://img.e-com-net.com/image/info8/0cc900fc380b4222bc1463f8ecef377d.jpg) 时序依赖可视化: 通过对比可以发现,Autoformer中自相关机制可以正确发掘出每个周期中的下降过程,并且没有误识别和漏识别,而自注意力机制存在错误和缺漏。
时序依赖可视化: 通过对比可以发现,Autoformer中自相关机制可以正确发掘出每个周期中的下降过程,并且没有误识别和漏识别,而自注意力机制存在错误和缺漏。
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第35张图片](http://img.e-com-net.com/image/info8/85c7782582e0490788261a807cb6dc00.jpg)
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第36张图片](http://img.e-com-net.com/image/info8/103bafcbef594a6b9e76a55cb0e1d899.jpg)
输出预测特征密度可视化的人为可解释性:对不同数据集的输出预测密度符合对数据集本身真实人为的理解
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第37张图片](http://img.e-com-net.com/image/info8/1fd47c6564b74463b8ab34d654c03b17.jpg) 效率分析: 在显存占用和运行时间两个指标上,自相关机制均表现出了优秀的空间时间效率,两个层面均超过自注意力机制,表现出高效的复杂度。
效率分析: 在显存占用和运行时间两个指标上,自相关机制均表现出了优秀的空间时间效率,两个层面均超过自注意力机制,表现出高效的复杂度。
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第38张图片](http://img.e-com-net.com/image/info8/82bb1229ca744dc19a504690ba51eefd.jpg)
总结
针对长时序列预测中的复杂时间模式难以处理与运算效率高的问题,我们提出了基于深度分解架构和自相关机制的Autoformer模型。通过渐进式分解和序列级连接,大幅提高了长时预测效率。
同时,Autoformer在能源、交通、经济、气象、疾病五大主流领域均表现出了优秀的长时预测结果,模型具有良好的效果鲁棒性,具有很强的应用落地价值。![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第39张图片](http://img.e-com-net.com/image/info8/6811115d869e400895415adffd1c6fde.jpg)
个人收获:FFT是一个非常厉害有用的算法,虽然过了几十年了,依然发挥着其核心价值,也让人意识到往往改动有大幅度提升不是非常创新的东西就是非常经典的东西,Transformer把attention机制进行替换也是一种技巧,大家之作的论文能够很好的反映别人的工作优点和缺点,来给自己的文章做铺垫。时间序列主要指标在于MSE,和MAE,再者时间序列指标本身还缺乏更有效的定义,在时间序列指标方面还有更多的上升空间,是个不错的研究方向,还有这篇文章的消融实验和对比实验做的非常好,可视化也让人清晰易懂,这是一篇让人觉得不错的论文,学习了Neurips论文的框架,写得简洁却又不失细节,活该人家中Ips,同时也体现了清华软件组的水平。
个人理解不足,关于FFT对attention的替换个人理解不深刻,需要继续阅读理解,后期给大家补上,如果有幸有人看到这里欢迎留言提醒我,找时间复现代码在其他数据集上进行测试。
感谢参考链接中各位学者提供的资料,最开始的资料来自于THUML
![Autoformer: 基于深度分解架构和自相关机制的长期序列预测模型[2021neurips][精读]_第40张图片](http://img.e-com-net.com/image/info8/0ebeb4a3bec44b348105b88e985390b3.jpg)
2022.5.14补充
https://blog.csdn.net/hymn1993/article/details/124746406?spm=1001.2101.3001.6650.16&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-16-124746406-blog-124536853.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-16-124746406-blog-124536853.pc_relevant_default&utm_relevant_index=20
参考资料
Autoformer:基于深度分解架构和自相关机制的长期序列预测模型
[论文精读] Autoformer:基于深度分解架构和自相关机制的长期序列预测模型_哔哩哔哩_bilibili
[时序] Autoformer:基于深度分解架构和自相关机制的长期序列预测模型 - 知乎
自相关与互相关 - 知乎
self-attention和rnn计算复杂度的对比_想念@思恋的博客-CSDN博客_attention计算复杂度