3D目标检测(教程+代码)

随着计算机视觉技术的不断发展,3D目标检测成为了一个备受关注的研究领域。与传统的2D目标检测相比,3D目标检测可以在三维空间中对物体进行定位和识别,具有更高的准确性和适用性。本文将介绍3D目标检测的相关概念、方法和代码实现。
一、3D目标检测的基本概念
1. 3D目标检测是什么?
3D目标检测是指在三维场景中检测和识别物体的过程。与传统的2D目标检测相比,3D目标检测可以提供更加精确的物体位置和姿态信息,适用于许多实际应用,例如自动驾驶、机器人导航、增强现实等领域。
2. 3D目标检测的难点是什么?
3D目标检测的难点主要包括以下几个方面:
(1)数据获取困难:获取三维场景数据需要使用专门的传感器或摄像机,成本较高,数据集数量有限。
(2)数据处理复杂:三维场景数据需要进行点云处理、网格化等操作,对算法和计算资源要求较高。
(3)数据标注困难:标注三维物体需要进行立体标注,标注成本较高,标注人员需要专业知识和技能。
二、3D目标检测的常见方法
1. 基于深度学习的3D目标检测
深度学习是当前3D目标检测领域的主流方法。通常采用点云或三维网格作为输入数据,在经过卷积、池化等操作后,使用全连接层输出物体的类别、位置和姿态信息。常见的深度学习模型包括PointNet、VoxelNet、Frustum PointNet等。
2. 基于几何学的3D目标检测
基于几何学的3D目标检测方法通常基于传统的计算几何或机器视觉算法,例如支持向量机、随机森林等。这些方法通常使用手工设计的特征和规则来实现目标检测和识别功能。虽然这些方法在一些领域和场景下仍然具有优势,但在复杂场景下的推广和应用受到了限制。
三、3D目标检测的代码实现
下面将介绍一个基于深度学习的3D目标检测代码实现案例,使用的是PointNet++算法。
1. 环境搭建
本案例使用Python语言和PyTorch深度学习框架,需要安装numpy、h5py、scipy、tqdm等库。同时,需要安装CUDA和cuDNN等支持GPU加速的工具。
2. 数据预处理
本案例使用KITTI数据集进行实验,需要对原始数据进行预处理,包括点云转换、数据划分、标注等操作。具体操作可参考官方文档或相关教程。
3. 模型训练
本案例使用PointNet++算法进行模型训练,代码实现可参考GitHub上的开源代码。在训练过程中需要设置网络结构、损失函数、优化器等参数,并使用训练集和验证集进行训练和测试。训练过程需要耗费较长时间,需要充分利用GPU加速和分布式训练等技术。
4. 模型评估
在模型训练完成后,需要对其进行评估和测试。本案例使用验证集和测试集进行评估,计算准确率、召回率、F1值等指标,并可使用混淆矩阵和ROC曲线进行可视化分析。
四、总结
本文介绍了3D目标检测的基本概念、常见方法和代码实现。随着计算机视觉技术的不断发展,3D目标检测在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。未来的研究将致力于进一步提高算法的性能和效率,以满足实际应用的需求。
概述
3d Objectron是一种适用于日常物品的移动实时3D物体检测解决方案。它可以检测2D图像中的物体,并通过在Objectron数据集上训练的机器学习(ML)模型估计它们的姿态.
下图为模型训练后推理的结果!

算法
我们建立了两个机器学习管道来从单个RGB图像预测物体的3D边界框:一个是两阶段管道,另一个是单阶段管道。两阶段管道比单阶段管道快3倍,准确率相似或更好。单阶段管道擅长检测多个物体,而两阶段管道适用于单个主导物体。
单价段训练模型:
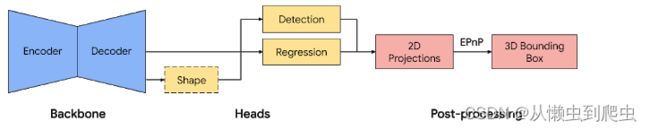
我们的单级流技术路线图,如图所示,模型骨干具有基于MobileNetv2的编码器-解码器架构。我们采用多任务学习方法,同时预测物体的形状、检测和回归。形状任务根据可用的真实注释,例如分割,预测物体的形状信号。如果在训练数据中没有形状注释,则此步骤是可选的。对于检测任务,我们使用注释的边界框并适合高斯到盒子,其中心在盒子重心处,标准偏差与盒子大小成比例。检测的目标是预测具有峰值表示物体中心位置的此分布。回归任务估计八个边界框顶点的二维投影。为了获得边界框的最终3D坐标,我们利用了一个成熟的姿态估计算法(EPnP)。它可以恢复物体的3D边界框,而不需要先验知识。给定3D边界框,我们可以轻松地计算物体的姿态和大小。该模型足够轻,可以在移动设备上实时运行(在Adreno 650移动GPU上以26 FPS的速度运行)。
主要代码和结果
结果:

获取现实世界的3D训练数据
尽管由于自动驾驶汽车依赖于3D捕捉传感器(如LIDAR)的研究的流行,有大量的街景3D数据可用,但是对于更精细的日常物品的具有真实3D标注的数据集非常有限。为了解决这个问题,我们开发了一种新颖的数据管道,利用移动增强现实(AR)会话数据。随着ARCore和ARKit的到来,数亿部智能手机现在具有AR功能,并且能够在AR会话期间捕获附加信息,包括相机姿态、稀疏3D点云、估计的照明和平面表面。
为了标注地面真实数据,我们构建了一个新颖的注释工具,可用于AR会话数据,允许注释者快速为物体标注3D边界框。此工具使用分屏视图,在左侧显示覆盖了3D边界框的2D视频帧,以及在右侧显示3D点云、相机位置和检测到的平面的视图。注释者在3D视图中绘制3D边界框,并通过检查2D视频帧的投影来验证其位置。对于静态对象,我们只需要在一个帧中标注一个对象,并使用AR会话数据的地面真实相机姿态信息将其传播到所有帧,这使得该过程高效。
主要代码:
with mp_objectron.Objectron(static_image_mode=True,
max_num_objects=5,
min_detection_confidence=0.5,
model_name='Shoe') as objectron:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
##全部代码请联系---------->qq1309399183<-----------------------
# Convert the BGR image to RGB and process it with MediaPipe Objectron.
results = objectron.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if not results.detected_objects:
print(f'No box landmarks detected on {file}')
continue
print(f'Box landmarks of {file}:')
annotated_image = image.copy()
for detected_object in results.detected_objects:
mp_drawing.draw_landmarks(
annotated_image, detected_object.landmarks_2d, mp_objectron.BOX_CONNECTIONS)
mp_drawing.draw_axis(annotated_image, detected_object.rotation,
detected_object.translation)
cv2.imwrite('/tmp/annotated_image' + str(idx) + '.png', annotated_image)
QQ767172261全部代码可交流私信
主要讲解:主要调用库函数,然后可以对视频流或者读取电脑摄像头,真正做到方便实用,高效快捷,实时显示结果 实施输出模型,可以毕业设计用。