MongoDB保姆级指南(下):无缝集成SpringData框架,一篇最全面的Java接入指南!
引言
前面的两篇文章已经将MongoDB大多数知识进行了阐述,不过其中的所有内容,都基于原生的MongoDB语法在操作。可是,在实际的日常开发过程中,我们并不会直接去接触MongoDB,毕竟MongoDB只能算作是系统内的一个组件,无法仅依靠它来搭建出一整套系统。
我们都是高级语言的开发者,就如同MySQL一样,在不同语言中,都会有各自的驱动、ORM框架,MongoDB亦是如此,而在Java中如何使用MongoDB呢?总共有两种方案:
-
①
MongoDB-Driver:官方提供的数据库驱动,可以基于此执行各种MongoDB支持的操作; -
②
Spring-Data-MongoDB:Spring对原生驱动的封装,提供了更简易的API。
通常来说,我们一般不会使用第一种方式操作MongoDB,类比MySQL,第一种方案就相当于原生的JDBC,而第二种方案就相当于MyBatis/Plus、JPA、Hibernate这种持久层框架。两者相比较,显然后者对开发者更加友好,也能在极大程度上提升开发效率,从而满足Boss的“快速开发”理念。
好了,本文会以Spring-Data-MongoDB作为客户端框架,一点点阐述在Java中如何使用MongoDB提供的众多命令,那么,下面开始吧~
其实当你掌握了Spring-Data-MongoDB的用法,也就掌握了SpringData系列的框架用法,比如Spring-Data-JPA,用起来和本文讲的Spring-Data-MongoDB没有太大区别,因为SpringData体系下的大多数框架,核心设计是共通的,如果你之前对SpringData不熟悉,本文也能助你掌握这方面的技术栈~
一、SpringData-MongoDB入门
如果使用过SpringData-JPA的小伙伴,在使用SpringData-MongoDB会有种异常的熟悉感,因为它们都出自于Spring组织,所以秉持着相同的框架风格,为什么这么说呢?一点点往下看就明白了。
这里先基于SpringBoot快速搭建出一个Java工程,接着在pom.xml中引入下述依赖:
org.springframework.boot
spring-boot-starter-data-mongodb
这里使用的是spring-boot-starter,所以无需指定版本号,默认会跟SpirngBoot版本保持一致,我这里SpringBoot版本为2.7.15,接着可以配置一下application.yml文件,如下:
spring:
data:
mongodb:
uri: mongodb://zhuzi:[email protected]:27017/zhuzi
这段配置特别容易看懂,所以不做过多解释,配置完成后,为了方便后续操作,这里再引入一下Lombok的依赖:
com.alibaba.fastjson2
fastjson2
2.0.27
org.projectlombok
lombok
1.18.12
好了,依赖、配置都弄好后,接着来编写与MongoDB集合相映射的实体类,如下:
@Data
@Document(collection = "xiong_mao")
public class Panda implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private Integer id;
private String name;
private Integer age;
private String color;
private Food food;
}
@Data
public class Food implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private String grade;
}
这里没啥太值得注意的,和MyBatisPlus也很相似,由于目前实体类名和集合名不一样,因此使用@Document显示指定一下集合名词,其次用@Id注解显示指定出主键。接着来看food属性,因为这是一个嵌入文档,所以咱们又定义了另外一个类Food,并将其作为了Panda类的一个属性,SpringData在映射时,会拿着food属性名+Food类里的属性名拼接,形成food.name这样的格式,正好和MongoDB嵌入文档的使用方式相同。
实体类搞好后,接着来写经典的MVC三层,目前仅是为了测通,为此,只编写持久层和业务层,这里先写前者:
@Repository
public interface PandaRepository extends MongoRepository {}
如你所见,持久层仅仅定义了一个接口,而后继承了SpringData提供的MongoRepository接口,并传递了两个泛型,前者代表与当前Repository绑定的实体类(集合),后者表示集合内的主键类型。除此之外,咱们什么都不用写,因为SpringData会通过动态代理的方式,帮我们生成基础的CRUD方法。
接着来编写Service层,遵循传统的项目编码风格,先定义接口,再撰写实现类,接口定义如下:
public interface PandaService {
void save(Panda panda);
void deleteById(Integer id);
void update(Panda panda);
Panda findById(Integer id);
List findAll();
}
其中定义了五个基本的增删改查方法,注释也没写,毕竟一眼就能看懂的代码,接着看看实现类:
@Service
public class PandaServiceImpl implements PandaService {
@Autowired
private PandaRepository pandaRepository;
@Override
public void save(Panda panda) {
pandaRepository.save(panda);
}
@Override
public void deleteById(Integer id) {
pandaRepository.deleteById(id);
}
@Override
public void update(Panda panda) {
pandaRepository.save(panda);
}
@Override
public Panda findById(Integer id) {
return pandaRepository.findById(id).get();
}
@Override
public List findAll() {
return pandaRepository.findAll();
}
}
又是一眼能看懂的代码,这里将前面定义的PandaRepository注入了进来,而后实现了PandaService接口的每个方法,每个方法中没有包含任何业务逻辑,只是单纯调了pandaRepository的默认方法,不过这里注意:update修改方法,调用的也是pandaRepository.save()方法实现,这是为什么呢?大家可以点进save()方法看看:
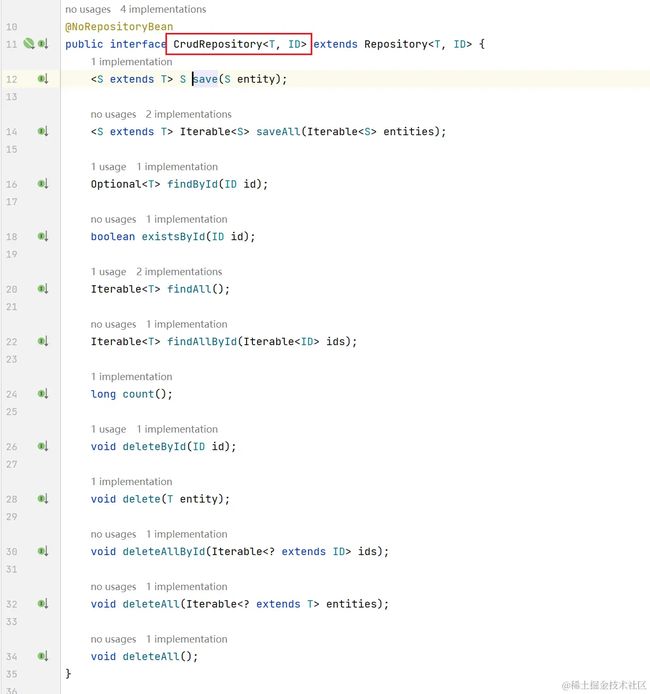
此时不难发现,这些方法最终会调用到CrudRepository接口提供的基本方法,而这个CRUD接口中,并没有提供update()系列的方法,而save()插入相同_id的数据时,会直接覆盖上一次的数据,为此,我们可以通过该方法间接实现修改功能,只不过每次修改之前,需要先find一次将原数据查询出来。
好了,剩下的就是编写测试用例了,这一步更简单,如下:
@SpringBootTest
public class PandaServiceTest {
@Autowired
private PandaService pandaService;
@Test
void testSave() {
Panda panda = new Panda();
panda.setId(111);
panda.setName("黑黑");
panda.setColor("黑色");
panda.setAge(8);
Food food = new Food();
food.setName("黑晶竹");
food.setGrade("A");
panda.setFood(food);
pandaService.save(panda);
}
@Test
void testDelete() {
pandaService.deleteById(111);
}
@Test
void testFindById() {
Panda panda = pandaService.findById(111);
System.out.println(panda);
}
@Test
void TestUpdate() {
Panda panda = pandaService.findById(111);
panda.setAge(9);
pandaService.update(panda);
}
@Test
void testFindAll(){
List pandas = pandaService.findAll();
pandas.forEach(System.out::println);
}
}
该测试类中,将咱们定义的PandaService注入了进来,而后为每一个service方法写了用例,具体的执行结果就不贴了,诸位可以自己执行一下看看结果,其实和操作MySQL没有太大差异。
二、SpringData-MongoDB进阶
OK,在前面简单过了一下SpringData-MongoDB基础的增删改查操作,但实际开发过程中,只掌握这些远远不够,面对复杂多变的业务场景,咱们需要灵活使用不同API来满足需求,为此,接下来会一点点继续拆解SpringData-MongoDB的其他API。
2.1、实体类注解
前面在定义实体类时,简单介绍了@Id、@Document两个注解,这里先全面介绍一些常用注解。
-
@Document:作用于类上面,被该注解修饰的类,会和MongoDB中的集合相映射,如果类名和集合名不一致,可以通过collection参数来指定。 -
@Id:标识一个字段为主键,可以加在任意字段上,但如果该字段不为_id,每次插入需要自己生成全局唯一的主键;如果不设置@Id主键,MongoDB会默认插入一个_id值来作为主键。 -
@Transient:被该注解修饰的属性,在CRUD操作发生时,SpringData会自动将其忽略,不会被传递给MongoDB。 -
@Field:作用于普通属性上,如果Java属性名和MongoDB字段名不一致,可以通过该注解来做别名映射。 -
@DBRef:一般用来修饰“嵌套文档”字段,主要用于关联另一个文档。 -
@Indexed:可作用于任意属性上,被该注解修饰的属性,如果MongoDB中还未创建索引,在第一次插入时,SpringData会默认为其创建一个普通索引。 -
@CompoundIndex:作用于类上,表示创建复合索引,可以通过name参数指定索引名,def参数指定组成索引的字段及排序方式。 -
@GeoSpatialIndexed、@TextIndexed:和上面的@Indexed注解作用相同,前者代表空间索引,后者代表全文索引。
好了,上面这些便是SpringData-MongoDB提供用于修饰实体类的注解,其实除此之外,还有些由SpingData提供的通用注解,但这里不再例举,毕竟上述这些已经够用了。
2.2、自定义方法
经过前面的案例,会发现SpringData-MongoDB提供了默认的CRUD方法,那如果现在有个需求,没有对应的默认方法怎么办?这时可以自定义方法,但SpringData是以方法命名来决定方法怎么执行的,规范如下:
-
findBy:根据指定的单个条件进行等值查询; -
findBy:根据指定的多条件进行And And<...> and查询; -
findBy:根据指定的多条件进行Or Or<...> or查询; -
findBy:根据指定的单个条件进行等值查询;Equals -
findBy:对指定的单个字段进行In in查询,入参为一个列表; -
findBy:对指定的单个字段进行Like like模糊查询; -
findBy:查询指定字段不为空的数据;NotNull -
findBy:对指定的单个字段进行GreaterThan >范围查询; -
findBy:对指定的单个字段进行GreaterThanEqual >=范围查询; -
findBy:对指定的单个字段进行LessThan <范围查询; -
findBy:对指定的单个字段进行LessThanEqual <=范围查询; -
Page<...> findBy<...>:根据指定的条件进行分页查询; -
countBy:根据指定的条件字段进行计数统计; -
findTop:根据指定字段做等值查询,并返回前By n条数据; -
findBy:根据指定字段进行Between between范围查询; -
findDistinctBy:根据指定的单个条件进行去重查询; -
findFirstBy:根据指定的单个条件进行等值查询(只返回满足条件的第一个数据); -
findBy:根据第一个字段做等值查询,并根据第二个字段做排序;OrderBy -
……:
大家看下来不难发现,SpringData-MongoDB其实提供了一组命名约束,结合自定义的实体类字段,可以让SpringData帮我们生成各类执行语句,这里总体归类一下,在Repository中自定义方法,不同单词开头的含义如下:
-
以
get、find、read、query、stream开头,代表是查询数据的方法; -
以
count开头,代表是计数统计的方法; -
以
delete、remove开头,代表是删除数据的方法; -
以
exists开头,代表是判断是否存在的方法; -
以
search开头,代表是全文搜索的方法; -
以
update开头,代表是修改数据的方法;
上面这些便是SpringData-MongoDB所有支持的方法类型,这些方法后面可以跟关键字,以find开头的方法为例:
-
By:表示当前方法生成的查询语句,会根据By后面的逻辑来组成; -
FirstBy:表示当前方法生成的语句,只会返回符合条件的第一条数据; -
DistinctBy:表示当前方法生成的语句,会对符合条件的数据去重; -
TopBy:表示当前方法生成的语句,只会返回符合条件的前N条数据; -
<实体类名称>By:表示当前方法生成的语句,只会返回一条数据; -
<实体类名称>sBy:表示当前方法生成的语句,会返回多条数据; -
AllBy:表示当前方法生成的语句,会返回多条或所有数据; -
DistinctFirstBy:表示当前方法生成的语句,只会返回去重后的第一条数据; -
DistinctTopBy:表示当前方法生成的语句,只会返回去重后的前N条数据;
OK,在这些关键字之后,都是跟具体的字段名(实体类的属性名),字段名称后面可以接的关键字如下(同样以find为例):
-
Or:表示当前查询方法有多个条件,多个条件之间为“或者”关系; -
And:表示当前查询方法有多个条件,多个条件之间为“并且”关系; -
OrderBy:表示当前查询会涉及到排序,后面需要跟一个排序字段; -
Between:表示当前方法为between范围查询; -
GreaterThan:表示当前方法为>查询; -
GreaterThanEqual:表示当前方法为>=查询; -
LessThan:表示当前方法为<查询; -
LessThanEqual:表示当前方法为<=查询; -
After:和GreaterThan差不多,相当于查询指定数值之后的数据; -
Before:和LessThan差不多,查询指定条件之前的数据; -
Containing:查询某字段中包含指定字符的数据; -
Empty:表示当前方法会查询指定字段为空的数据,与之含义类似的还有Null、Exists; -
Equals:表示当前方法会根据指定字段做等值查询; -
Is:和Equals差不多; -
In:表示当前方法为in多值匹配查询; -
Like:表示当前方法为like模糊查询; -
Not:可以和上述大多数关键字组合,带有Not的则含义相反,如NotEmpty表示不为空; -
……
上面列出了大多数常用的连接关键字,看着是不是尤其的多?但其实不需要你死记,因为当你在IDEA工具编写方法时,它也会自动提示你!这里随便来定义几个方法,帮助诸位加深理解:
@Repository
public interface PandaRepository extends MongoRepository {
Integer countByAge(Integer age);
List findByNameLike(String keyword);
Panda findPandaByAgeAndName(int age, String name);
List findByColorOrAge(String color, int age);
Panda findFirstByColorNotNull();
List findByAgeGreaterThanEqual(int age);
List findByIdIn(List ids);
List findByColorOrderByAgeDesc(String color);
List findTop3ByAgeLessThan(int age);
}
上面定义的方法就不挨个测试了,其实效果就如同注释中所说的一样,感兴趣的可以自行测试看看。
这里说个题外话,编程里有句话叫做:好的代码不用写注释,这点在SpringData中体现的淋漓尽致,当你熟悉它这套命名约束后,再去看别人定义的Repository方法时,就算他人不写注释,你也完全可以看懂,Why?因为你们遵循着完全相同的编码规范、命名约束,他不可能写其他风格的代码,毕竟命名不按规范来,定义的方法压根无法执行~
2.3、分页查询
前面了解了SpringDataMongoDB中的自定义方法,接着来看看经典的“分页查询”,在这里该怎么玩呢?
首先需要定义一个Repository方法,如下:
Page findByAgeNotNull(Pageable pageable);
命名约束完全相同,区别就在于返回类型,以及入参类型不同,这里的返回类型声明成了Page,而入参列表中需要新增一个Pageable,接着继续封装一下Service层:
Page pageByAgeNotNull(int pageNumber, int pageSize);
@Override
public Page pageByAgeNotNull(int pageNumber, int pageSize) {
PageRequest pageReq = PageRequest.of(pageNumber - 1, pageSize);
return pandaRepository.findByAgeNotNull(pageReq);
}
写好Service层后,为了测试分页功能是否正常,这里再编写一个单元测试:
@Test
void testPage(){
Page pandas = pandaService.pageByAgeNotNull(1, 3);
int totalPages = pandas.getTotalPages();
long totalElements = pandas.getTotalElements();
System.out.println("总页数:" + totalPages);
System.out.println("总行数:" + totalElements);
System.out.println("第一页的数据为:");
List data = pandas.getContent();
data.forEach(System.out::println);
}
这个用例很简单,无非就是调用了一下service方法,而后传递了页码、条数,接着从Page对象中,拿到了总页数、总行数,以及具体的分页数据,输出结果如下:
总页数:6
总行数:16
第一页的数据为:
Panda(id=1, name=肥肥, age=3, color=黑白色, food=null)
Panda(id=4, name=黑熊, age=3, color=黑白色, food=Food(name=黄金竹, grade=S))
Panda(id=5, name=白熊, age=4, color=null, food=Food(name=翠绿竹, grade=B))
效果很明显,总共有16条数据,每页三条总共6页,这里获取了第一页的数据,拿到的分页结果也符合age字段不为空的特性,当然,大家也可以自行改改页码测试,这里不再重复贴结果,毕竟分页使用起来尤为简单。
2.4、自定义MongoDB语句
前面掌握了遵循SpringData的命名规范,通过自定义Repository方法,完成了对MongoDB数据的增删改查操作,但这种方式有个缺陷,就是必须遵守规范去给方法命名,使用时难免会有种约束感,能不能自由一点呢?当然可以。
以前操作传统关系型数据库时,无论是在任何ORM框架中,都支持通过注解来编写简单SQL,例如MyBatis:
@Select("select * from zhu_zi where id = #{id}")
ZhuZi selectById(@Param("id") Integer id);
那在SpringDataMongoDB中,支不支持这种注解形式定义语句呢?答案是当然可以,来看个例子:
@Query("{'name': ?0}")
List queryXxx(String name);
List queryXxx(String name);
@Override
public List queryXxx(String name) {
return pandaRepository.queryXxx(name);
}
这个代码特别简单,重点看repository里定义的接口方法:queryXxx(),在方法上面有一个@Query注解,这用于自定义查询语句,其中声明根据name字段进行查询,?0表示方法参数的索引(占位符),此处的0表示第一个参数name,下面看看测试结果:
@Test
void testQueryXxx() {
List pandas = pandaService.queryXxx("肥肥");
pandas.forEach(System.out::println);
}
Panda(id=1, name=肥肥, age=3, color=粉色, food=null)
*/
这里并没有遵循SpringData的命名规范,但仍然根据name字段查询到了数据,效果同预期中的一样,除此之外,还有另外几个注解,分别对应其他操作:
-
@Update:用于自定义更新语句的注解; -
@DeleteQuery:用于自定义删除语句的注解; -
@CountQuery:用于自定义统计语句的注解; -
@ExistsQuery:用于自定义查询语句,但执行后只返回是否存在满足条件的数据,并不返回具体的文档; -
@Aggregation:用于自定义聚合管道语句的注解; -
……
除开上述列出的外,其实还有一些注解,具体大家可以去看看org.springframework.data.mongodb.repository这个包,关于这些注解的用法就不再过多说明,毕竟用注解写原生语句的机会并不多,实际开发中,要么根据命名规范自定义方法,要么使用MongoTemplate写复杂操作(后续会细说)。
2.5、SpingDataMongoDB事务机制
在之前的篇章中提到过,MongoDB本身支持事务,那SpingDataMongoDB中该如何使用事务呢?如下:
void mongoTransaction();
@Override
public void mongoTransaction() {
ClientSession session = mongoClient.startSession();
try{
session.startTransaction();
Panda panda = new Panda();
panda.setId(222);
panda.setName("白白");
panda.setColor("白色");
panda.setAge(1);
MongoCollection collection = mongoClient
.getDatabase("zhuzi")
.getCollection("xiong_mao");
collection.insertOne(session, Document.parse(JSONObject.toJSONString(panda)));
int n = 100 / 0;
session.commitTransaction();
} catch (Exception e) {
session.abortTransaction();
e.printStackTrace();
}
session.close();
}
OK,对于每一步代码的含义,这里已经在上面写出了注释,为此不再重复说明,整个流程很简单,上面是一个向MongoDB插入单个文档的方法,如果执行成功,提交事务;如果执行出现异常,回滚事务,但要注意几点:
-
①事务依赖于
ClientSession开启,所以需要先打开ClientSession会话; -
②想要让当前写操作的事务生效,必须调用
MongoCollection的写方法; -
③前两个对象的获取,都依赖于
MongoClient对象,所以要记得注入该对象,如下:
@Autowired
private MongoClient mongoClient;
接着来写个测试用例,看看事务到底会不会生效呢?如下:
@Test
void testMongoTransaction() {
pandaService.mongoTransaction();
}
按理来说,由于咱们手动加了一行100/0,因此肯定会报错而后回滚,但是来看看实际执行结果:
Caused by: com.mongodb.MongoCommandException:
Command failed with error 20 (IllegalOperation):
'Transaction numbers are only allowed on a replica set member
or mongos' on server 192.168.229.136:27017. The full response is
{"ok": 0.0, "errmsg": "Transaction numbers are only allowed on a
replica set member or mongos", "code": 20, "codeName": "IllegalOperation"}
这个报错很明显,并不是取模零的异常,而是告诉咱们,事务只能在replicaSet副本集,或者mongos分片集群下生效,在单机的MongoDB上,事务无法正常开启,为此,在使用单机MongoDB时,事务并不能正常生效(如果你搭建了集群环境,上述代码是能正常执行、然后回滚数据的)。
三、MongoTemplate
前面的内容中,简单过了一下SpringData自定义方法、如何定义分页查询,以及如何通过注解自定义原生语句。不过更多时候,咱们都是在遵循着SpringData的命名规范编写,语句的生成、执行、数据聚合,全由SpringData自动完成。但,如果有一个特殊的需求,无法通过前面的方式查询到数据怎么办?这里就得用到MongoTemplate,可以用它来实现更加灵活的增删改查操作。
3.1、MongoTemplate方法分类
MongoTemplate中提供了不同的方法,用于执行不同类型的操作,首先来看看插入方法:
T insert(T objectToSave);
T insert(T objectToSave, String collectionName);
Collection insertAll(Collection objectsToSave);
Collection insert(Collection batchToSave, String collectionName);
Collection insert(Collection batchToSave, Class entityClass);
Collection doInsertBatch(String collectionName, Collection batchToSave,
MongoWriter writer);
T save(T objectToSave);
T save(T objectToSave, String collectionName);
观察下来会发现,这些方法对应着MongoDB自身提供的API,即insertOne、insertMany,如果入参T已经与一个集合映射,则无需额外指定类型、集合名,MongoTemplate会自动解析。但如果你想将一个字段完全不同的文档插入到某个集合,则可以显式指定集合名称。
接着来看看删除方法:
DeleteResult remove(Object object);
DeleteResult remove(Object object, String collectionName);
DeleteResult remove(Query query, Class entityClass);
DeleteResult remove(Query query, Class entityClass, String collectionName);
DeleteResult remove(Query query, String collectionName);
T findAndRemove(Query query, Class entityClass);
删除方法命名中都带remove,可以直接传入一个对象进行删除,也可以根据条件进行删除,没啥好讲的,接着看看修改方法:
ExecutableUpdate update(Class domainType);
UpdateResult upsert(Query query, UpdateDefinition update, Class entityClass);
UpdateResult updateFirst(Query query, UpdateDefinition update, String collectionName);
UpdateResult updateMulti(Query query, UpdateDefinition update, Class entityClass);
T findAndModify(Query query, UpdateDefinition update, Class entityClass);
T findAndReplace(Query query, S replacement, FindAndReplaceOptions options,
Class entityType, String collectionName, Class resultType);
修改方法有点多,所以这里省略了一些同名不同参的方法,其中只有updateMulti方法会更新所有满足条件的文档,其余方法都只会更新“满足条件”的第一个文档。为此,在使用时要额外注意:当你的操作涉及到多个文档修改时,请记住调用updateMulti()方法,而不是其他修改方法。
好了,关于这些方法如何使用放到后面说,再来看看查询方法,这也是MongoTemplate中最多的一类:
boolean exists(Query query, String collectionName);
T findById(Object id, Class entityClass);
T findOne(Query query, Class entityClass);
List find(Query query, Class entityClass);
List findAll(Class entityClass, String collectionName);
List findDistinct(Query query, String field, Class entityClass, Class resultClass);
long count(Query query, String collectionName);
AggregationResults aggregate(TypedAggregation aggregation, Class outputType);
上面同样省略了一些同名的重载方法,以及某些不常用的方法,诸位可以简单瞟几眼。除开上述增删改查四类方法外,MongoTemplate还提供了执行聚合管道命令的方法,如下:
AggregationResults aggregate(Aggregation aggregation,
String collectionName, Class outputType)
CloseableIterator aggregateStream(Aggregation aggregation,
String collectionName, Class outputType)
AggregationResults aggregate(TypedAggregation aggregation, Class outputType);
这里同样省略了一些重载方法,不过这并不重要,执行聚合管道操作的方法分为两大类,一类是同步执行的aggregate方法,即命令发给MongoDB服务端后,需要阻塞等待至MongoDB返回结果为止;而另一类是支持响应式编程的aggregateStream方法,可以通过调用subscribe()方法或其他响应式编程操作来处理聚合结果(后面再细说)。
前面对MongoTemplate的常用方法有了一定认识后,下面来说说如何使用MongoTemplate。
3.2、Query与Criteria对象
在上一节中,大家会看到许多入参类型为Query的方法,这到底是个啥东东?
用过MyBatisPlus框架的小伙伴一定不陌生,在MP中查询、修改、删除数据时,如果不想编写xml文件,咱们可以通过Warpper条件构造器,以Java代码的形式指定where条件,从而快捷、方便的实现条件修改、查询、删除功能。
而SpringData-MongoDB,Query、Criteria对象的作用亦是如此,通过Java对象的方式,完全取代掉MongoDB原生的shell语法,比如你想实现一个条件查询,可以这样写:
List findByColor(String color);
public List findByColor(String color) {
Query query = new Query();
query.addCriteria(Criteria.where("color").is(color));
return mongoTemplate.find(query, Panda.class);
}
这样就实现了按照颜色字段来查询数据的效果,当然,上面的查询条件还可以简写为:
Query query = Query.query(Criteria.where("color").is(color));
这样指定的条件,效果和前面new的方式相同,来看看效果:
@Test
void testFindByColor(){
List pandas = pandaService.findByColor("黑白色");
pandas.forEach(System.out::println);
}
Panda(id=1, name=肥肥, age=3, color=黑白色, food=null)
Panda(id=2, name=花花, age=null, color=黑白色, food=null)
Panda(id=4, name=黑熊, age=3, color=黑白色, food=Food(name=黄金竹, grade=S))
*/
从结果中可以看出,和我们预期中的效果相同,的确实现了按颜色查询集合文档的效果。
3.2.1、Query查询对象详解
经过上述小案例的学习后,各位应该大致对SpringData中的条件构造器有了基本认知,接着来详细说说Query对象,各方法的作用如下:
Query.query(CriteriaDefinition criteriaDefinition);
addCriteria(CriteriaDefinition criteriaDefinition);
with(Sort sort);
with(Pageable pageable);
skip(long skip);
limit(int limit);
Field fields();
好了,Query类中实则定义了几十个方法,但较为常用的则是上面列出的这几个,通常咱们理解上面这几个方法的作用即可,下面结合前面的案例,简单过一下这些方法:
List findByColorAndAge(String color, int age);
@Override
public List findByColorAndAge(String color, int age) {
Query query = Query.query(Criteria.where("color").is(color));
query.addCriteria(Criteria.where("age").is(age));
query.with(Sort.by(Sort.Direction.DESC, "_id"));
query.skip(1);
query.limit(1);
query.fields().include("_id", "name", "age");
return mongoTemplate.find(query, Panda.class);
}
@Test
void testFindByColorAndAge(){
List pandas = pandaService.findByColorAndAge("黑白色", 3);
pandas.forEach(System.out::println);
}
这个案例中,几乎将前面列出的方法都用上了,接着来看看结果:
Panda(id=1, name=肥肥, age=3, color=黑白色, food=null)
Panda(id=4, name=黑熊, age=3, color=黑白色, food=Food(name=黄金竹, grade=S))
*/
Panda(id=1, name=肥肥, age=3, color=null, food=null)
*/
来根据代码推导一下过程,首先基于给定的条件,会找到id=1、4这两条数据;其次会基于id降序,结果集变为4、1这个顺序;然后回通过skip跳过第一条数据,即id=4这条数据;接着通过limit限制返回一条数据,拿到id=1这条数据;最后通过fields指定返回的字段,因为没有要求返回color、food,所以最终结果集相应字段为null。
好了,这个结果和咱们预期中的完全相同,不过上面这些案例中,又涉及到了一些新对象,如Sort、Field等,这些对象也会有相应API,这里简单过一下,先来看看Sort类:
private Sort(Direction direction, List properties);
public static Sort by(String... properties);
public static Sort by(List orders);
public static Sort by(Order... orders);
public static Sort by(Direction direction, String... properties);
public Sort descending();
public Sort ascending();
public static final Direction DEFAULT_DIRECTION;
static {
DEFAULT_DIRECTION = Sort.Direction.ASC;
}
这里咱们重点关注by()方法即可,排序主要有两个入参,一个是排序方式,另一个是排序字段,如果调用不指定排序方式的by方法,默认使用DEFAULT_DIRECTION升序方式。再者,我们可以直接指定这两个参数,也可以封装成Order对象,Order内部类如下:
public static class Order implements Serializable {
private final Direction direction;
private final String property;
public static Order by(String property) {
return new Order(Sort.DEFAULT_DIRECTION, property);
}
public static Order asc(String property) {
return new Order(Sort.Direction.ASC, property, DEFAULT_NULL_HANDLING);
}
public static Order desc(String property) {
return new Order(Sort.Direction.DESC, property, DEFAULT_NULL_HANDLING);
}
public boolean isAscending() {
return this.direction.isAscending();
}
public boolean isDescending() {
return this.direction.isDescending();
}
}
Order类并不难懂,无非是对排序方式、排序字段的封装,用起来也差不多,只不过在使用时,需要先构建一个Order对象,而后再传入到Sort对象中,如下:
query.with(Sort.by(Sort.Order.desc("_id")));
好了,另一个Direction类没啥好讲的,就是一个枚举类,里面就定义了ASC、DESC两个枚举,下面来看看Filed类,该类主要用于投影查询,即调用Query.fileds()方法时产生的对象,如下:
public Field fields();
public class Field {
public Field include(String... fields);
public Field exclude(String... fields);
public Field slice(String field, int offset, int size);
public Field position(String field, int value);
public Field elemMatch(String field, Criteria elemMatchCriteria);
}
上面列出了Filed类中的常用方法,这里主要关心前面两个方法,一个是指定需要返回的字段列表,另一个是指定需要排除的字段列表,如下:
query.fields().include("name", "age").exclude("_id");
而对于后面的几个方法,都是用于数组/嵌套类型的字段,一般情况下使用较少,为此,这里不再举例说明,下面重点来看看Criteria条件构造器对象。
3.2.2、Criteria条件对象详解
在MongoTemplate中提供的大部分增删改方法,其中都会有一个Query类型的入参,而Query对象无法指定过滤条件,因此需要结合Criteria对象来指定条件,大家可以把Criteria理解成MyBatisPlus框架的Warpper对象,当然,它们两者在使用上也相差不大。
在前面的案例中,咱们曾写过这样的代码:
Query query = Query.query(Criteria.where("color").is(color));
query.addCriteria(Criteria.where("age").is(age));
其实这两者都是在指定过滤条件,最终都会转变成一个Criteria对象传入到Query对象中,下面来看看其中的方法:
public static Criteria where(String key);
public Criteria and(String key);
public Criteria is(Object value);
public Criteria isNull();
public Criteria ne(@Nullable Object value);
public Criteria lt(Object value);
public Criteria lte(Object value);
public Criteria gt(Object value);
public Criteria lt(Object value);
public Criteria in(Object... values);
public Criteria nin(Object... values);
public Criteria all(Object... values);
public Criteria exists(boolean value);
public Criteria not();
public Criteria regex(String regex);
public Criteria orOperator(Criteria... criteria);
public Criteria andOperator(Criteria... criteria);
public Criteria norOperator(Criteria... criteria);
上面列出了Criteria类中大多数常用方法,其他一些要么属于操作嵌套文档、地理空间的方法,要么就比较小众冷门的方法,所以不再详细罗列。其实大家观察这些方法的命令,应该也能摸清楚大致含义,无非就是原生语法,转变成了Java代码形式,前面自定义Repository方法也是相同的含义,将各种条件表达式,以“方法命名规范”的形式来编写。
毕竟这里提供的方法,和前面的命名规范有很多共通之处,因此就随便来个例子练习一下:
Criteria criteria = Criteria.where("age")
.gte(3)
.and("food.grade")
.in("S", "B");
Query query = Query.query(criteria);
List pandas = mongoTemplate.find(query, Panda.class);
pandas.forEach(System.out::println);
Panda(id=5, name=白熊, age=4, color=null, food=Food(name=翠绿竹, grade=B))
Panda(id=4, name=黑熊, age=3, color=黑白色, food=Food(name=黄金竹, grade=S))
Panda(id=12, name=金熊, age=4, color=null, food=Food(name=黄金竹, grade=S))
* */
这个结果和代码没啥好说的,一眼就能看懂。不过这里注意:之前咱们写的例子,几乎每一步都是分开写的,但要注意,SpringDataMongoDB中的大多数方法,都支持函数式编程的链式调用风格,即可以一直.下去,不需要每行代码之间用;分割。
3.2、Update修改对象
前面讲完了Query、Criteria两个类之后,接着来详细说说Update对象,大家对这玩意儿或许有点陌生,毕竟前面都没出现过,对不?其实该对象主要作用于“修改”方法,可仔细观察MongoTemplate提供的修改方法,貌似入参都为UpdateDefinition类型呀!这里大家可以仔细去看看Update类的定义:
public class Update implements UpdateDefinition {}
从类头能明显看出,UpdateDefinition是个接口,而Update则是具体的实现类,所以到这里就清楚了,调用MongoTemplate提供的修改方法时,其实我们需要传递的是Update对象,这里先来个案例简单使用一下:
UpdateResult updateColorById(Integer id, String color);
@Override
public UpdateResult updateColorById(Integer id, String color) {
Query query = new Query(Criteria.where("id").is(id));
Update update = new Update().set("color", color);
return mongoTemplate.updateMulti(query, update, Panda.class);
}
@Test
void testUpdateAgeById() {
Panda oldPanda = pandaService.findById(1);
System.out.println("修改前的数据:" + oldPanda);
UpdateResult result = pandaService.updateColorById(1, "粉色");
System.out.println("受影响的行数:" + result.getModifiedCount());
Panda newPanda = pandaService.findById(1);
System.out.println("修改前的数据:" + newPanda);
}
上面这个案例,代码也特别容易看明白,上面总共有两个对象:Query、Update,其中Query对象用于承载过滤条件,而Update对象则用来承载要修改的数据,来看看输出结果:
修改前的数据:Panda(id=1, name=肥肥, age=3, color=黑白色, food=null)
受影响的行数:1
修改前的数据:Panda(id=1, name=肥肥, age=3, color=粉色, food=null)
*/
从修改前后的数据对比来看,本次修改的确生效了,而且最关键的一点是:**本次修改并没有触发全量替换,而是动态修改,即只变更了修改字段的值,其他字段没有变为Null**!这是因为MongoTemplate的update系列方法,底层使用了$set操作符。同时注意,Update系方法的返回值,都为UpdateResult对象,该对象主要有四个常用方法:
-
getMatchedCount():获取满足条件的文档数; -
getModifiedCount():获取本次修改操作影响的行数; -
getUpsertedId():如果本次修改操作为upsert操作,返回未匹配到数据、插入数据后生成的ID; -
wasAcknowledged():判断本次MongoDB服务端执行完成后,其返回值是否正确。
好了,大概认识了Update对象的用法后,接着来看看其中提供的方法:
public static Update update(String key, @Nullable Object value);
public Update set(String key, @Nullable Object value);
public Update setOnInsert(String key, @Nullable Object value);
public Update unset(String key);
public void inc(String key);
public Update inc(String key, Number inc);
public Update currentDate(String key);
public Update currentTimestamp(String key);
public Update push(String key, @Nullable Object value);
public Update pushAll(String key, Object[] values);
public Update pop(String key, Position pos);
public Update pull(String key, @Nullable Object value);
public Update pullAll(String key, Object[] values);
public Update addToSet(String key, @Nullable Object value);
public AddToSetBuilder addToSet(String key);
public Update each(Object... values);
public Update filterArray(CriteriaDefinition criteria);
public Update rename(String oldName, String newName);
OK,上面同样未曾将所有方法列出,仅仅只写了一些常用方法,其实如果你的集合中,不涉及到数组类型的字段,那只需要关注前半部分方法即可。当然,这里只说明了每个API的作用,想练习的小伙伴可以自行去玩一玩,不会使用直接问ChatGPT即可。
3.4、Aggregation聚合管道对象
在《MongoDB入门》[3]这一篇文章中,曾经提到过一点,如果你想实现较为复杂的操作,几乎都需要通过聚合管道来完成,MongoDB提供的聚合管道十分强大,几乎可以满足任何场景下的业务操作,而在Java中如何使用聚合管道呢?答案是Aggregation对象。
先从之前的篇章,cpoy过来一个原生的聚合管道命令,如下:
db.xiong_mao.aggregate([
{$group: {_id:"$age", count: {$sum:1}}},
{$sort: {_id:1}}
]);
这个案例比较简单,先基于年龄分组,再基于_id字段排序,如何转换成Java代码实现呢?如下:
@Test
void testAggregation() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.group("age").count().as("count"),
Aggregation.sort(Sort.Direction.ASC, "_id")
);
AggregationResults这里为了节省篇幅,就不再写service层代码了,直接在Test方法中写逻辑,上面的代码大家参考注释即可,这里重点说说语法。认真阅读过《入门篇》[4]的小伙伴应该还记得,MongoDB的聚合管道,可以指定多个的阶段,在每个阶段中进行不同的处理,而上述代码中亦是如此,不过该如何指定不同的阶段呢?大家看到中间的,了嘛?newAggregation()方法可以传入任意个Aggregation对象,每个对象则代表一个阶段。
同时,MongoDB原生的语法中,并没有提供$count统计操作符,想要实现计数,只能以$sum:1这种方式实现,而SpringData则封装了一个count()方法提供给咱们使用,可谓是十分贴切~
接着看看返回结果:AggregationResults对象,这个对象需要指定一个泛型,该泛型意味着返回结果的类型,我这里传入了Map,这是因为我懒得再次封装一个对象出来,如果大家以后有些聚合操作要经常执行,并且返回结果的字段已经确定,最好的做法还是封装一个entity类出来。这点先放一遍,先说说AggregationResults里的常用方法:
-
getMappedResults():返回映射的聚合结果集,即得到指定类型的集合(如案例中的List); -
getRawResults():返回未做映射处理的原始结果集,则获取MongoDB返回的BSON对象; -
getUniqueMappedResult():返回映射后的一个结果对象,在明确清楚聚合结果只有一条的情况使用; -
iterator():返回用于遍历聚合结果的迭代器,可以用于逐个处理聚合结果中的数据;
对于AggregationResults对象而言,咱们只要明白这几个方法的作用即可,至于其他没列出的并不重要。
3.4.1、Aggregation案例练习
好了,上阶段对SpringData聚合管道有了简单认知后,那聚合管道的其他方法呢?怎么使用?其实把MongoDB原生的聚合管道命令掌握后,在Java里的意思也是相同的,毕竟方法名字都没改,和操作符的名称一模一样,下面来些案例玩玩:
@Test
void testAggregation1() {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.group("color").max("age").as("max_age"),
Aggregation.sort(Sort.Direction.DESC, "max_age")
);
AggregationResults这个案例不难,相信大家一定能看懂,这里顺便演示了一下获取原生BSON对象,而后转换为JSON字符串输出的过程。下面再来一个稍微复杂的案例看看:
并求出每组的平均年龄、以及输出每组第一个、最后一个、所有熊猫姓名,
最后按照平均年龄升序排列 */
@Test
void testAggregation2() {
Criteria criteria = Criteria.where("food").exists(true).and("age").gte(3);
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.match(criteria),
Aggregation.group("food.grade")
.avg("age").as("avg_age")
.first("name").as("first_name")
.last("name").as("last_name")
.push("name").as("names"),
Aggregation.sort(Sort.Direction.ASC, "avg_age")
);
AggregationResults代码和结果,大家可以花个一分钟仔细看看,每行都写了注释,结果也的确达到了起初的需求,大家可以试着多理解、多练习,自然而然就掌握了如何去写,最后再来一个案例吧:
原文档的name、age字段、原文档在各分组中的下标,同时要支持分页功能 */
@Test
void testAggregation3() {
int pageSize = 2;
Criteria criteria = Criteria.where("food").exists(true);
for (int pageNumber = 1; pageNumber <= 3; pageNumber++) {
Aggregation aggregation = Aggregation.newAggregation(
Aggregation.match(criteria),
Aggregation.group("food.grade").push("$$ROOT").as("pandas"),
Aggregation.unwind("pandas", "index", true),
Aggregation.project("_id","pandas.name","pandas.age","index"),
Aggregation.skip((pageNumber - 1) * pageNumber),
Aggregation.limit(pageSize)
);
AggregationResults这个案例需求是我瞎编的,没有任何逻辑可言,目的在于帮大家熟悉复杂场景下的API用法,代码的含义可参考注释,重点来说说执行结果,这个结果有些小伙伴可能看的有点懵,其实特别简单。_id代表原本的food.grade食物等级,而index则是原文档在各分组中的下标,因为原文档按顺序被压入了pandas数组,为啥会有重复值呢?
很简单,因为这个下标是以“分组”来区分的,上述B分组只有一个文档,所以index=0,A分组中有三个文档,所以index=0、1、2,其他分组以此类推……,这样解释后,相信大家一定能看懂这个执行结果。
到这里,关于SpringData中如何使用聚合管道的案例,就暂且告一段落了,如果大家感觉还没有尽兴,可以自行回到《入门篇-聚合管道查询》[5]阶段,将其中每个案例用Java代码实现一遍~
3.5、ExampleMatcher匹配器对象
前面讲完了聚合管道,接着来说说匹配器,这是SpringData家族都有的对象,用于在匹配查询条件时对查询对象进行更细粒度的匹配配置,我们可以通过它自定义匹配的行为,好比排除某些字段、只匹配某些字段等。
可能按上面这么说,估计大家也不太明白这玩意儿的作用,那么先上个简单例子,大家看完自然而然就明白了,如下:
@Test
void testExampleMatcher() {
Panda panda = new Panda();
panda.setName("黑黑");
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnoreCase()
.withMatcher("name", ExampleMatcher.GenericPropertyMatchers.contains());
Example example = Example.of(panda, matcher);
Criteria criteria = new Criteria().alike(example);
List pandas = mongoTemplate.find(Query.query(criteria), Panda.class);
pandas.forEach(System.out::println);
}
Panda(id=111, name=黑黑, age=9, color=黑色, food=Food(name=黑晶竹, grade=A))
*/
上面是个使用ExampleMatcher的案例,从结果来看,无非就是基于name字段做查询,最终查到了“黑黑”这条数据,重点来看看匹配器的定义:
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnoreCase()
.withMatcher("name", ExampleMatcher.GenericPropertyMatchers.contains());
这是在定义匹配规则,withIgnoreCase()表示忽略大小写,withMatcher()表示具体的匹配逻辑,对于name字段的条件,会以contains()包含规则去匹配,大家可以尝试把案例中的“黑黑”替换为“黑”,执行时照样能匹配到“黑黑”这条数据,因为“黑黑”包含了“黑”。
经过上述解释,相信诸位应该大致清楚ExampleMatcher的作用了吧?它可以针对每个字段,自定义细粒度的匹配规则,ExampleMatcher提供了三个方法用于创建匹配器:
static ExampleMatcher matching();
static ExampleMatcher matchingAll();
static ExampleMatcher matchingAny();
下面再来看看ExampleMatcher中,自定义匹配规则的方法:
ExampleMatcher withMatcher(String propertyPath, GenericPropertyMatcher genericPropertyMatcher);
ExampleMatcher withStringMatcher(StringMatcher defaultStringMatcher);
ExampleMatcher withIgnoreCase();
ExampleMatcher withIncludeNullValues();
ExampleMatcher withIgnoreNullValues();
ExampleMatcher withTransformer(String propertyPath, PropertyValueTransformer
propertyValueTransformer);
ExampleMatcher withIgnorePaths(String... ignoredPaths);
OK,上面这些方法简单了解一下,看withMatcher()方法的入参,是一个GenericPropertyMatcher类型,而该类中提供了一些内置规则方法,比如前面的contains()包含规则,其他方法如下:
public GenericPropertyMatcher contains();
public GenericPropertyMatcher startsWith();
public GenericPropertyMatcher endsWith();
public GenericPropertyMatcher exact();
public GenericPropertyMatcher regex();
public GenericPropertyMatcher caseSensitive();
public GenericPropertyMatcher ignoreCase();
上面便是常用的匹配规则,了解这些后,再回到前面的案例加深理解:
Panda panda = new Panda();
panda.setName("黑");
ExampleMatcher matcher = ExampleMatcher.matching()
.withIgnoreCase()
.withMatcher("name", ExampleMatcher.GenericPropertyMatchers.contains());
Example example = Example.of(panda, matcher);
Criteria criteria = new Criteria().alike(example);
List pandas = mongoTemplate.find(Query.query(criteria), Panda.class);
pandas.forEach(System.out::println);
加上这些注释后,大家是不是就能很好理解了?其实整体很简单,就是一种“另类”的条件查询,可以针对每个字段指定多条匹配规则。
好了,关于这玩意儿就此打住,其实ExampleMatcher用的也不是特别多,大家在这里了解即可,因为前面讲到的其他查询方式,足以满足日常开发中的所有需求,匹配器只有在某些特殊的业务场景下,才会使用。
四、MongoDB配置详解
到这里,前面已经将SpringDataMongoDB的大多数操作讲述完毕,掌握上述所有知识后,满足日常开发已不再是难事,接着来看看MongoDB的配置,这里是指application.yml文件中的配置,先上个配置文件:
spring:
data:
mongodb:
host: 192.168.229.136
port: 27017
database: zhuzi
username: zhuzi
password: 123456
authentication-database: zhuzi
auto-index-creation: on
下面解释一下每个参数的作用:
-
host:部署MongoDB服务的机器IP; -
port:MongoDB服务的端口号,默认为27017; -
database:当前项目连接的数据库; -
username:连接MongoDB的账号; -
password``MongoDB账号的密码; -
uri:前五项的合集; -
authentication-database:认证的数据库(连接用的账号,不在连接的库下时使用); -
auto-index-creation:是否自动创建索引的配置;
这些即是常用的参数配置,基本上在之前都有接触过,所以不过多展开细说。
4.1、副本集配置
经过第二篇:《MongoDB集群篇》[6]的学习,各位接触到了MongoDB副本集群,那SpringDataMongoDB如何配置成副本集模式呢?语法如下:
mongodb://username:password@[host:port1],[host:port2],[....]/database?options
这一段要写在uri里面,例如:
uri: mongodb://zhuzi:[email protected]:27018,192.168.229.137:27019,192.168.229.137:27020/zhuzi?connect=replicaSet&slaveOk=true&replicaSet=zhuzi
其中的参数说明如下:
-
connect:连接模式,指定为replicaSet代表连接副本集群; -
slaveOk:从节点是否可读,为true表示可读,执行语句时,读操作自动发往从节点; -
replicaSet:副本集群的名称,这里为zhuzi;
将uri换成上述这个格式后,就配置好了副本集连接参数,并且SpringData会自动根据执行的操作,将请求分发到不同类型的节点,从而实现读写分离的效果(大家可以自行去执行原本的操作,来检测配置是否生效)。
4.2、分片集群配置
在上篇中还提到了分片集群,那SpringData中如何连接分片集群呢?这里语法类似,但不需要跟option参数,只需要配置所有mongos所在的IP、端口即可,如下:
uri: mongodb://zhuzi:[email protected]:27024,192.168.229.137:27025/zhuzi
上篇中,27024、27025被咱们做成了路由节点,为此,这里配置这两个节点即可,配置完成后,SpringData会自动去将请求交给mongos节点,再由mongos根据配置的分片键、分片算法,将请求分发到具体的分片节点(具体测试大家可以自行去玩玩)。
4.3、多数据源整合
不知大家是否还记得,之前曾说过:虽然MongoDB支持事务,但其事务功能存在一定缺陷,那假设咱们实际开发过程中,某些业务又特别依赖事务怎么办?这是最好的做法是:将这些事务依赖项强的数据,还是存储在传统的关系型数据库里!
啥意思呢?就比如MySQL、MongoDB一起使用,数据量较大、事务要求不高的数据,放入到MongoDB中;而事务要求较高、增量不算太快的业务数据,则依旧放在MySQL里面,怎么整合呢?其实很简单,把MySQL的驱动、连接池依赖引入进来,而后和之前一样配置即可,如下:
mysql
mysql-connector-java
8.0.28
com.zaxxer
HikariCP
4.0.3
接着再配置一下数据库的信息:
spring:
datasource:
url: jdbc:mysql://.....
username: zhuzi
password: zhuzi
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.zaxxer.hikari.HikariDataSource
hikari:
minimum-idle: 0
maximum-pool-size: 20
idle-timeout: 10000
auto-commit: true
connection-test-query: SELECT 1
而后就可以实现多数据源操作啦,要存到MySQL的数据,就用之前的MyBatis、JPA、Hibernate等框架,实体类、Dao层按之前的逻辑编写。而要存到MongoDB中的数据,就按本文的方式编写实体类、repository层即可。
五、库内分表方案
好了,上一阶段几乎都是简单的配置,没有任何难点,因此没有刻意展开讲述,下面来看一个特殊场景,假设现在采用MongoDB存储客服的聊天记录,其他数据全部存到MySQL,假设这里每天有10W个客户会话,每个客户平均的消息对话数量为50条,稍微算算每日数据的增量:
100000 * 50 = 5000000(五百万条)
单日暴增500W数据,虽然MongoDB号称大数据存储组件,但目前仅有一个业务的数据存在里面,直接上分片集群显然大材小用了,该怎么存储?在之前的MySQL专栏,其实出过一章:《库内分表篇》[7],用来讲述该如何解决这类问题,同样的思想也可以用到MongoDB上,即:按照一定维度对数据进行分表(分集合)。
5.1、数据拆分思路
常规的做法有两种,一种是按时间分,另一种是按数据量来划分,想要将数据分发到同一个库、不同集合中,最关键的在于如何计算出:一条数据究竟该落入哪个集合?后续操作时又能精准拿到?这个问题解决后,其他就不再是问题,下面展开讲讲。
相较于MySQL做库内分表,MongoDB实现起来的难度低许多许多,Why?大家回想一下前面MongoTemplate提供的方法:
insert(T objectToSave, String collectionName);
remove(Query query, String collectionName);
updateMulti(Query query, UpdateDefinition update, String collectionName);
find(Query query, String collectionName);
findAll(Query query, String collectionName);
......
大家观察这些方法的最后一个参数,会明显发现,增删改查方法都支持指定集合名称!也就意味着,我们只需要计算出集合名词,就能实现“库内分表”。同时,MongoDB由于其无模式特性,咱们也不需要提前创建表结构,每当数据量增长到一定程度时,就能自动使用一个新集合来存储。
当然,如果之前没阅读过《库内分表篇》[8]的小伙伴,看起来或许会有点懵懂,因此建议大家可以去看看前面那篇文章,下面开始实操,这里先给出一个公用的实体类:
@Data
public class ZhuZi {
private Long id;
private String name;
}
5.2、按时间划分
按时间维度来分表(专业称呼叫分集合,但分表比较顺口,后续都以分表来称呼),首先得以时间字段作为分片键,这里也可以为时间戳,所以咱们首先来编写一个ID生成器,主要用于生成时间戳类型的ID:
public class IdGenerator {
* 获取时间戳ID(生产换成雪花ID,雪花ID包含时间戳,具备全局唯一性)
* */
public static long getTimeStampId() {
return System.currentTimeMillis();
}
}
这个主键生成器尤为简单,就是获取了一下当前的系统时间戳,但这样做并不专业,我仅仅是为了演示,图个方便,更好的做法是使用雪花ID算法,生成出来的ID会包含时间戳,并且可以保证全局唯一性(大家不想自己写,可以直接去拷贝MyBatisPlus里的雪花ID生成类)。
好了,有了上述这个简陋的ID生成器后,接着再来写动态分表的策略类,首先定义一个接口:
public interface DynamicCollection {
* 获取目标集合名的方法
* */
String getTargetCollectionName(T criteria);
}
这个接口实则非常简单,里面就定义了一个“获取目标集合(表)名”的方法,为啥要定义这个接口呢?因为可能会存在多种分片策略,为此,先抽象出一个公共的接口来定义分片行为。再来看方法的入参,它是一个泛型,这里主要用于指定分片键的类型,下面来看具体的实现:
public class DateTimeDynamicCollection implements DynamicCollection {
private static final ThreadLocal monthTL =
ThreadLocal.withInitial(() ->
new SimpleDateFormat("yyyyMMdd"));
private static final String collectionPrefix = "zhuzi_";
* 根据时间戳获取目标集合名(每天的数据归档到一个集合)
* @param timeStamp 时间戳
* @return 集合名
*/
@Override
public String getTargetCollectionName(Long timeStamp) {
Date date = new Date(timeStamp);
return collectionPrefix + (monthTL.get().format(date));
}
}
这是一个根据日期时间分表的实现类,入参为一个时间戳,接着内部会将时间戳转为yyyyMMdd格式的字符串,最后拼接上对应的前缀名,然后对外返回出“目标表名”,相当于按“天”分表,是不是特别简单?答案是Yes,毕竟这只是个Demo,旨在讲清如何实现动态分表。
接着来编写测试用例,如下:
@Autowired
private MongoTemplate mongoTemplate;
@Test
void testDynamicCollectionByDateTime(){
ZhuZi zhuZi = new ZhuZi();
long id = IdGenerator.getTimeStampId();
zhuZi.setId(id);
zhuZi.setName("竹子一号");
DynamicCollection dynamic = new DateTimeDynamicCollection();
mongoTemplate.insert(zhuZi, dynamic.getTargetCollectionName(id));
}
这个用例特简单,先获取了一下当前时间戳作为主键,接着再通过生成的ID,得到了要插入的目标表名,最后通过mongoTemplate.insert()方法,将这条数据插入到了对应的集合中,下面去MongoDB看看:
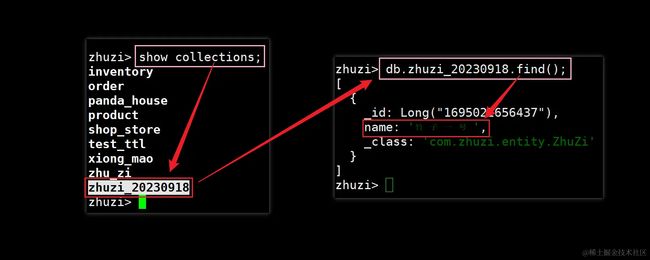
如上图所示,MongoDB中的确多了一个zhuzi_20230918的集合,并且“竹子一号”这条数据,也成功插入到了该集合中,接着再来换一个时间戳试试看,如下:
@Test
void testDynamicCollectionByDateTime() throws ParseException {
ZhuZi zhuZi = new ZhuZi();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
long timeStamp = sdf.parse("2023-11-11 11:11:11").getTime();
zhuZi.setId(timeStamp);
zhuZi.setName("竹子二号");
DynamicCollection dynamic = new DateTimeDynamicCollection();
mongoTemplate.insert(zhuZi, dynamic.getTargetCollectionName(zhuZi.getId()));
}
这里咱们手动创建了一个时间为2023-11-11 11:11:11的Date对象,并将其转变为了时间戳,接着依旧和之前代码相差不大,直接来看结果:
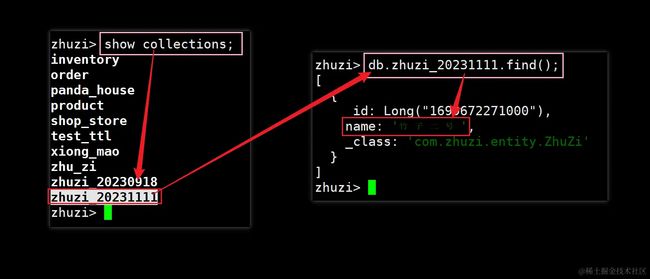
效果十分明显,此时又多出了一个zhuzi_20231111集合,并且“竹子二号”也被插入到了其中,此时动态分表的目的已然达成,那其他操作又该怎么办呢?比如查询、修改、删除……,很简单,基于目前的分片键:id,去对数据进行操作即可,例如查询:
long id = 1699672271000L;
DynamicCollection dynamic = new DateTimeDynamicCollection();
String target = dynamic.getTargetCollectionName(id);
Query query = Query.query(Criteria.where("_id").is(id));
ZhuZi zhuzi = mongoTemplate.findOne(query, ZhuZi.class, target);
System.out.println(zhuzi);
ZhuZi(id=1699672271000, name=竹子二号)
*/
效果很明显,查询到了“竹子二号”这条数据,好了,对于修改、删除操作就不再演示,过程都类似,记住这里的核心思想:每次操作必须传入分片键,因为需要通过分片键来计算表名,从而才能操作对应的表,如果没有分片键字段,就只能对所有集合全部执行一次相应操作。
以上述案例来说,如果要基于name字段查询数据,就无法解析出“目标集合名”,只能对所有集合发起查询,而后再对数据进行汇总,如果集合数量过多,假设有100个,此时的执行效率堪忧,而这样的问题,在Sharding-Sphere这样的框架中,为了提升性能,底层会采用多线程去并发查询,大家也可以借鉴这点思想,个人不再继续完善。
5.3、按数据量划分
前面讲了按时间分表,现在再来说说业内另一种常见的分片策略,即按数据量划分,例如一千万条数据为一张表,怎么做呢?首先你的数据中,必须存在一个记录当前行数的值,这里可以选用自增ID来实现,毕竟自增ID天生具备这个功能,为此,这里再在之前的ID生成器中新增一个方法:
private static final AtomicLong ATOMIC_LONG = new AtomicLong(1);
* 获取自增ID(生产换成特定的原子累加器,如MySQL自增、Redis自增)
* */
public static long getIncrId() {
return ATOMIC_LONG.incrementAndGet();
}
这里依旧是Demo模式,专业做法并不能依靠AtomicLong来维护自增序列,因为服务一旦重启,这个计数器会清零重新开始,就会和之前自增生成的序列产生冲突,所以最好选用第三方中间件来维护自增序列,如数据库、Redis……啥的都行。
咱们目前不考虑这么多,能出效果就行,这里再写一个按数量量分片的策略实现类:
public class DataVolumeDynamicCollection implements DynamicCollection {
private static final String collectionPrefix = "zhuzi_";
* 根据自增ID获取目标集合名(每一千万条数据归档到一个集合)
* @param incrValue 自增ID
* @return 集合名
*/
@Override
public String getTargetCollectionName(Long incrValue) {
return collectionPrefix + (incrValue / 10000000);
}
}
又是一个特别简单的实现过程,这里会通过外部生成的自增ID,对1000W求商(相除),因为Java的/运算,并不会得到余数,所以这里会返回一个整数,例如:
1 / 10000000 = 0;
10000001 / 10000000 = 1;
20000001 / 10000000 = 2;
而后直接与定义好的前缀拼接,从而得到的目标表名。当然,这里的表前缀名是完全一样的,最好的做法是将这个重复的定义,抽象为一个常量类,或者枚举类,方便于后续维护,并且能减少冗余代码,感兴趣的小伙伴可以自己去改造一下~
OK,下面直接来写单元测试,看看效果:
@Test
void testDynamicCollectionByDataVolume(){
ZhuZi zhuZi = new ZhuZi();
long id = IdGenerator.getIncrId();
zhuZi.setId(id);
zhuZi.setName("一号竹子");
DynamicCollection dynamic = new DataVolumeDynamicCollection();
mongoTemplate.insert(zhuZi, dynamic.getTargetCollectionName(id));
}
代码不解释了,和之前近乎一模一样,唯一区别就在于换了实现类,直接上效果图:

可以看到,这里又多出了一个zhuzi_0集合,并且“一号竹子”也被插入到了其中,至于其他测试就不再重复叙述了,大家可以试着手动分配一个值为10000001L的ID,同样能观察到zhuzi_1集合的出现……。与前面的时间分片策略类似,基于数据量分片后,无论任何操作都需要传入分片键字段,如果不传递,则会导致无法计算出目标表名……。
PS:这也是数据分片存在的通病,不管是传统的分库分表,还是例如
TiDB这样的分布式数据库,又或者上篇所提到的MongoDB分片集群,都存在这样的缺陷,一旦数据被分片存储,操作数据时就必须传入分片键,否则只能对所有分片节点都执行一遍操作。
五、SpringData-MongoDB篇总结
好了,叨叨絮絮了一大堆,本篇核心是:**Java如何基于SpringData-MongoDB框架,平滑接入MongoDB作为数据存储服务**,我们一点点从基础入门,到常用API、进阶API、配置详解、高级用法……,逐步进行了全面阐述,相信认真看完本文的你,在项目中需要使用MongoDB时,一定会显得如鱼得水~
最后,这里也总结一下本文提到的四种CRUD模式:
-
①基于
MongoRepository提供的命名约束,自定义方法实现基本增删改查; -
②基于注解形式,编写原生语句实现特定的增删改查;
-
③基于
MongoTemplate编写定制化的增删改查; -
④基于
ExampleMatcher进行复杂的增删改查;
其中最常用的是①、③,至于其他两种近乎不用,大家心里知道就行,毕竟①、③几乎能满足日常开发中的所有需求~