Python 爬取“工商秘密”微博后,我做了这个“可视化大屏”(附gif图)

前言
微博作为我的日常软件之一,平时除了看看热搜、肖战(哈哈),我还会时不时看看秘密,虽然从来都没有投过稿,但还是会对一些感兴趣的内容评论评论或者点点赞,前两天刷秘密突然很想知道,
秘密为同学们发布最多的是哪些内容?与哪些相关?
或者哪些同学喜欢去秘密下方评论?
评论最多的微博多于什么相关?
秘密经常会在什么时间发布微博?
发布的微博都是情感正向的还是负向的?
当然这些问题后台应该最清楚,也有直接的数据,不过这里我想通过爬取的数据来看看这些问题,或许会得出不一样的结论。
开始爬虫之旅 (注:内容只是娱乐,微博内容是公开的,评论者的ID名将进行处理,只显示一部分)
抓取网址:https://m.weibo.cn/u/2514127734?uid=2514127734&t=0&luicode=10000011&lfid=100103type%3D1&q=%E5%B7%A5%E5%95%86%E7%A7%98%E5%AF%86
想要的数据包括:发布时间、发布的微博内容、评论、评论者、评论中的评论、评论者中的评论者;
未拿到的数据:评论数、点赞数、转发数、发布微博来源等;
知道想要的数据后,接下来就开始寻找数据。一般接口数据都会存在 XHR,所以沿着这个方向基本能找到数据。
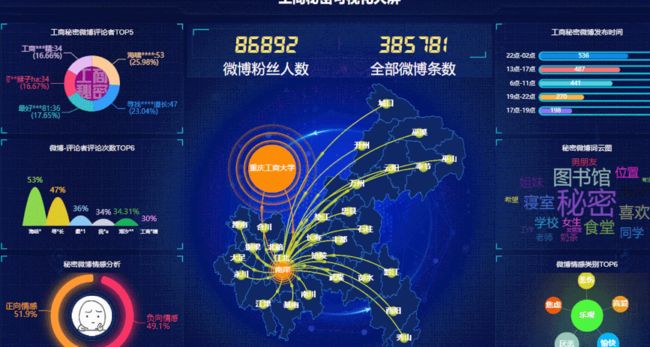
最终大屏效果
部分代码
for i in cards:
# 在提取json数据时,使用get方法,有就提取,没有就为空
# mblog可能有可能没有
if i.get('mblog'):
result1 = i.get('mblog')['text']
ids = i.get('mblog')['id']
# print(result1,ids)
# print('\n')
cop = re.compile("[^\u4e00-\u9fa5]") # 匹配不是中文、大小写、数字的其他字符
string1 = cop.sub('', result1)
# print(string1)
# print('\n')
# result2 = re.sub('<[^<]+?>', '', result1).replace('\n', '').strip()
sheet.append([string1,'0','0','0','0','0'])
# =======微博下面的评论
# time.sleep(1)
# md = re.findall('',result1)[0].split('/')[-1]
url = 'https://m.weibo.cn/comments/hotflow?id='+ ids +'&mid='+ ids +'&max_id_type=0'
response1 = requests.get(url,timeout=30,headers=headers)
dat1 = response1.json()
if dat1['ok'] == 1:
pinglun_num = dat1['data']['total_number']
da = dat1['data']['data']
for i in da:
pinglun = cop.sub('', i['text'])
created_at = i['created_at']
user1 = i['user']['screen_name']
sheet.append(['0',created_at,pinglun,user1,'0','0'])
# =======微博下面的评论的评论
if i['total_number'] > 0 and i['comments']!=False:
comments = i['comments']
for g in comments:
text = cop.sub('', g['text'])
user2 = g['user']['screen_name']
sheet.append(['0','0','0','0',text,user2]) 在线excel合并:http://www.docpe.com/excel/combine-excel.aspx
为了防止被封,这里在爬取时设置了随机头以及2秒的睡眠,并且没有一次性拿太多,分批次拿,每个批次保存在不同的excel文件,最终利用在线excel合并得到如下数据:
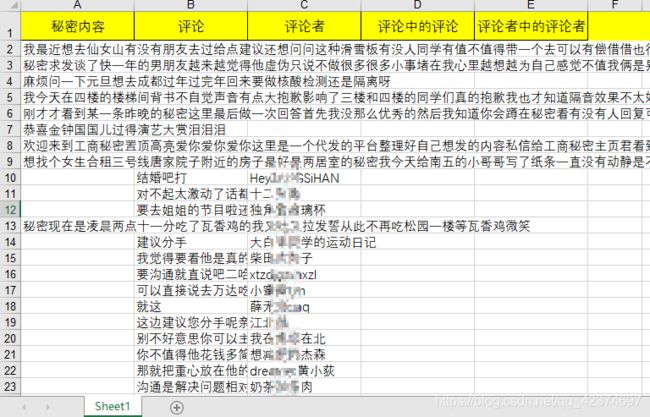
这里总的拿到接近10000条数据(包括无效数据),其中秘密内容和相关评论大概有近2000条,评论者8000左右(包括重复ID)
对数据进行处理,包括删除重复值、异常值(特殊字符)、数据脱敏等。基本的脏数据处理好之后,下面就可以开始分析啦。
秘密微博词云图
首先,把爬取到的所有微博筛选出来。

接下来,将数据导入程序中,得到如下的词云图。

或者,修改一下蒙版。

可以发现在最近这段时间,秘密发布的微博内容中这几个词出现得最多,包括:考研、图书馆、寝室、学校等,临近考研,同学们可能都比较关心学校啊、图书馆啊、座位位置啊这些,这里也祝愿咱们学校的考研人都能取得理想成绩,但行好事,莫问前程。
除此之外,喜欢、女朋友、男朋友等词语也常常出现在微博中,也许是冬天适合谈恋爱吧,记得多买一杯古茗奶茶,把它捧在手心里,暖暖的,很贴心!
秘密微博评论者
这里我一共拿到8010个用户ID(包括重复值),均进行了处理。
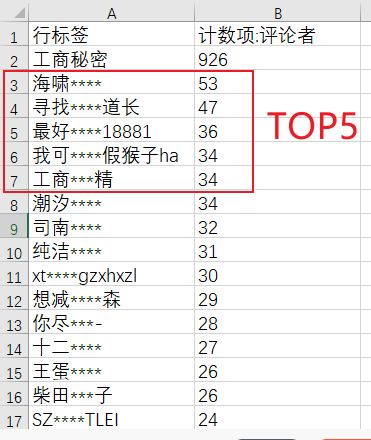
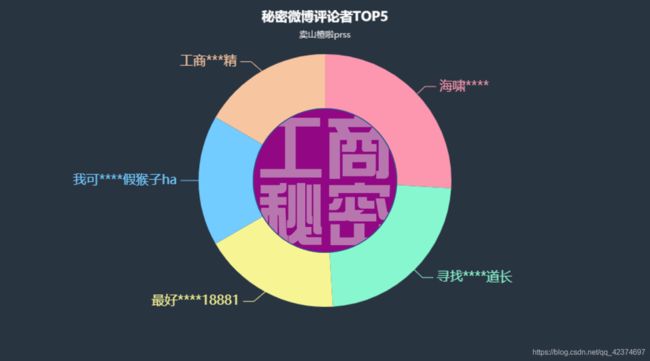
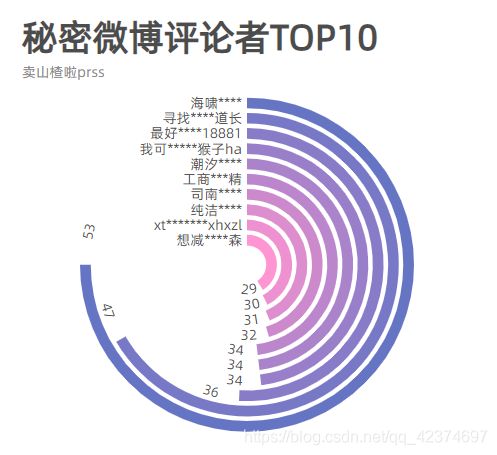
用数据透视表进行统计后,得到如下数据,可以看到最近一段时间在秘密下方评论最多的ID名是 海啸*****,其次是寻找****道长、最好18881、我可假猴子ha、工商**精。
数据可视化呈现代码如下:
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import osos.chdir(r'C:\Users\Administrator\Desktop')
ID = ['海啸****','寻找****道长','最好****18881','我可****假猴子ha','工商***精']
values = [53,47,36,34,34]
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
.add("", zip(ID,values),radius=["40%", "70%"])
.set_global_opts(
title_opts=opts.TitleOpts(title="秘密微博评论者TOP5",subtitle="卖山楂啦prss",pos_top="2%",pos_left = 'center'),
toolbox_opts=opts.ToolboxOpts(
# 是否显示该工具
is_show=True,
))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}",font_size=18))
.render("数据可视化.html")
)效果如下:
下面在看一下 ID 名为 海啸****同学,都在秘密平台上评论了些什么词语(这里数据较少)

评论的微博与哪些相关:

秘密微博情感分析
这里使用模型对每一条微博进行情感分析,分析其积极分值和消极分值。但有个问题是,秘密前段时间“改版了”,许多内容合并成一条发布,这就会导致最终的模型训练结果会有偏差,这里我并没有解决这个问题,所以结果可能具有不合理性。
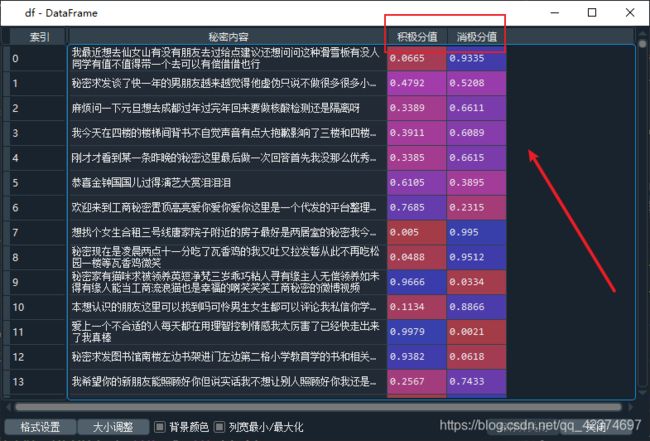
进一步的判断出每条微博的情感倾向。
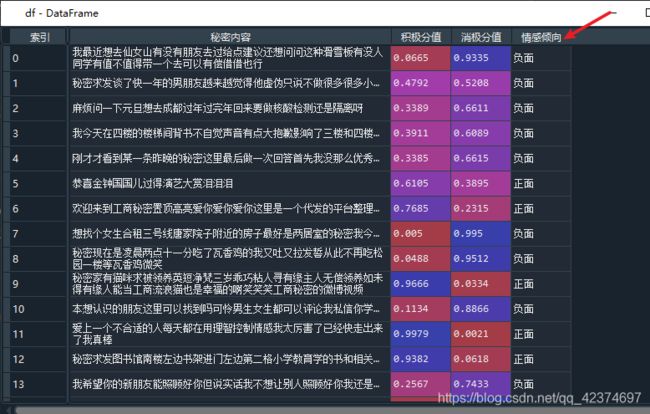
数据可视化:总的来说,最近秘密发布的微博的情感倾向还是比较均衡的,差异并不大,正向情感略高于负向情感。
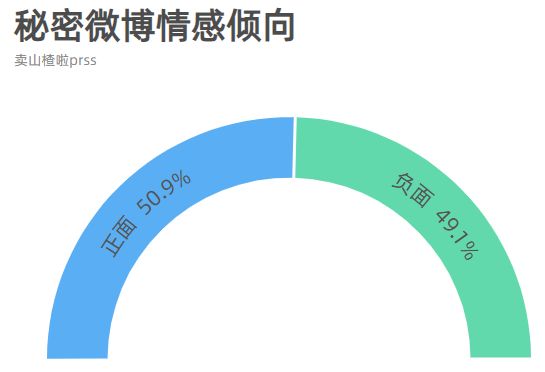
秘密微博发布时间分析
由于忘记拿发布时间的数据,所以这里从头在爬取一次,这次只要发布是时间,拿到的数据如下。
这里的时间数据是中国标准时间,需要进行转换。
import pandas as pd
import numpy as np
df = pd.read_excel('C:\\Users\\Administrator\\Desktop\\发布时间.xlsx')
def trans_format(time_string, from_format='%a %b %d %H:%M:%S +0800 %Y', to_format='%Y-%m-%d %H:%M:%S'):
"""
@note 时间格式转化
:param time_string:
:param from_format:
:param to_format:
:return:
"""
time_struct = time.strptime(time_string,from_format)
times = time.strftime(to_format, time_struct)
return times
if __name__ == "__main__":
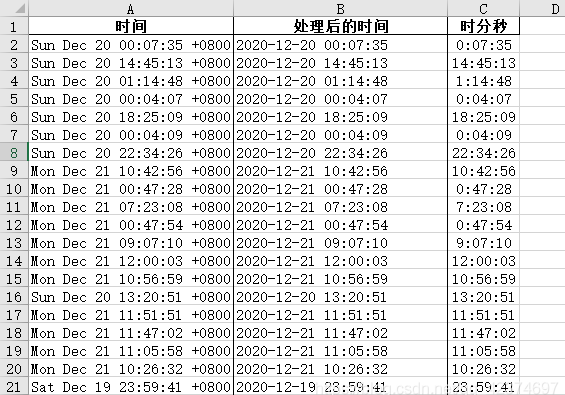
df["处理后的时间"] = df['时间'].apply(trans_format)转换后的数据如下:
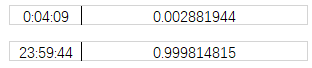
利用python 将时分秒变成小数。因为时间就是至1之间的小数,0是一天的开始,1就是1天了,所以时间是至1之间的小数,也就是中午12点是0.5。
比如这里:
最终处理结果:
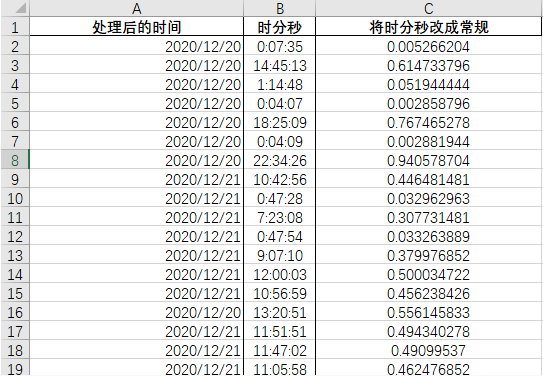
接下来开始分箱。
bins = pd.read_csv(r"处理后的数据.csv")
bins
def cut_bins(x):
if 0.083333<= x <0.250000:
return '02:00:00--06:00:00'
elif 0.250000 <=x <0.458333:
return '06:00:00--11:00:00'
elif 0.458333 <=x <0.541667:
return '11:00:00--13:00:00'
elif 0.541667 <=x <0.708333:
return '13:00:00--17:00:00'
elif 0.708333 <=x <0.791667:
return '17:00:00--19:00:00'
elif 0.791667 <=x <0.916667:
return '19:00:00--22:00:00'
else:
return '22:00:00--02:00:00'
bins['所在时间段'] = bins['将时分秒改成常规'].map(cut_bins)
bins结果如下:
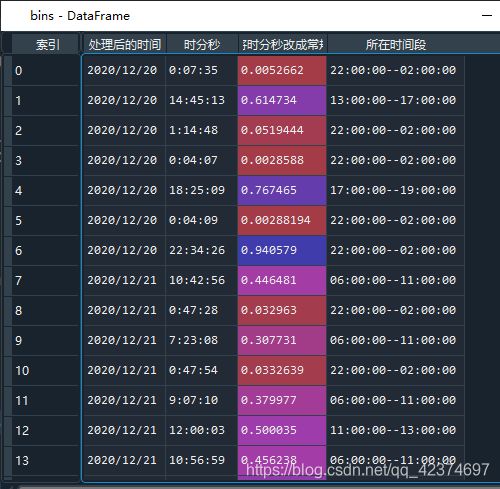
统计:
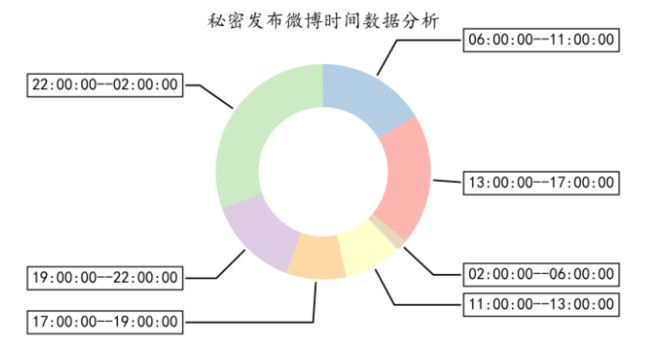
bins['所在时间段'].value_counts()数据可视化:可以看到,秘密经常会在 22:00:00 – 02:00:00 这个时间段发布微博,其次是下午13:00:00–17:00:00。
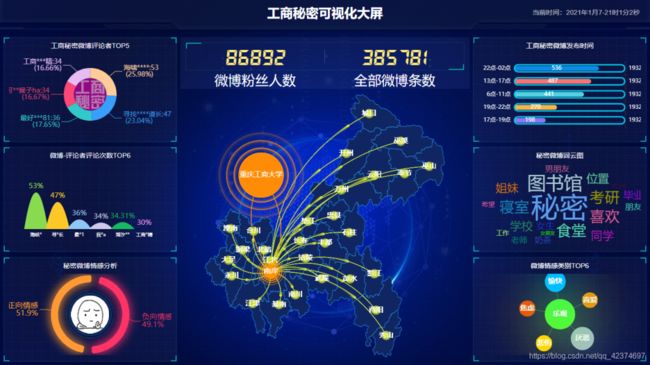
可视化大屏
将图表整合,进行可视化大屏呈现。
效果链接:http://tan-07.gitee.io/ctbu-secret/
项目地址:https://gitee.com/tan-07/ctbu-secret
结果如下:
完整源码获取指南
点击关注公号:我是IT小王子
回复:工商秘密,获取本文完整代码!