NLP基础2-词向量之Word2Vec
NLP基础1-词向量之序号化,One-Hot,BOW/TF,TF-IDF
NLP基础2-词向量之Word2Vec
NLP基础3-词向量之Word2Vec的Gensim实现
文章目录
- 一、Word Embedding
-
- 1. 什么是词嵌入,Word Embedding?
- 2. 词嵌入技术的优势:
- 3. 词嵌入的相关算法
- 二、Word2Vec 基本介绍
-
- 1. 两个算法:
- 2. 两个优化方法
- 3. 主要应用
- 4. 主要缺点
- 5. 目标函数
- 三、Word2Vec-CBOW
-
- 1. 前向过程
- 2. 代码实现
- 四、Word2Vec-Skip-gram
-
- 1. 前向过程
- 2. 代码实现
- 总结
- 参考资料
一、Word Embedding
1. 什么是词嵌入,Word Embedding?
词嵌入是一种将词汇表中的单词或短语映射为固定长度向量的技术,通过词嵌入技术我们可以将 one-hot 编码表示的高维稀疏向量转为低维稠密的向量。
举例说明
我门将单词 “we” 用 one-hot 编码表示,维度为(1,N),其中 N 为词汇表大小
词嵌入层的维度大小为(N,V),其中 V 为嵌入层维度,通常为 100 左右
(1,N)* (N,V)= (1,V),该低维稠密的向量就可以表征单词 “we”
Note: 由于one-hot编码只在对应位置为1,其余位置均为0,这就类似于在词嵌入层中的查找某一行的向量,因此词嵌入层的每一行其实就是代表一个单词的特征信息

2. 词嵌入技术的优势:
- 相比上万维的 ont-hot 编码,词嵌入的效率更高并且更具有通用性,可以用在不同的NLP任务中;
- 可以理解单词与单词之间的语义信息,并进行词语推理,语义相似的词在向量空间上也会更相近;
3. 词嵌入的相关算法
- 基于矩阵分解的主题模型:LDA,NMF 等
- 基于神经网络的 Word2Vec:CBOW,Skip-Gram 等
二、Word2Vec 基本介绍
1. 两个算法:
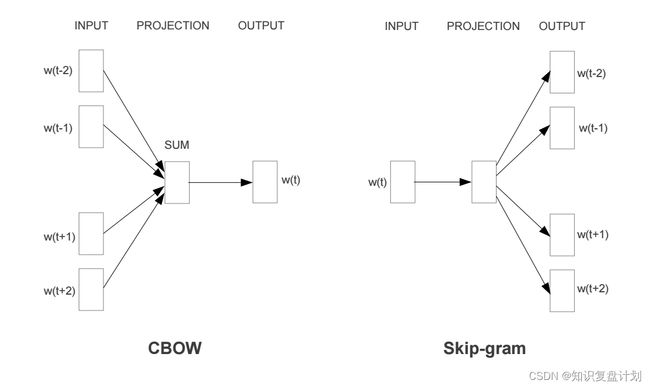
continuous bag-of-words(CBOW) 和 Skip-gram
- CBOW 是根据上下文预测中心词
- Skip-gram 则相反,是根据中心词预测上下文
这两种方法训练得到的隐层参数即为词向量
2. 两个优化方法
- 负采样 (Negative Sampling)
- 层次 Softmax (Hierarchical Softmax)
相关论文:Mikolov et. al., 2013. Efficient estimation of word representations in vector space.
3. 主要应用
- 获取单词之间的相似度
- 求当前单词对应相似度最高的 TopK 个单词
- 获取词向量,一般用于需要语义特征的下游任务
- 迁移学习,将训练好的词向量作为 Embedding 层的初始权重
4. 主要缺点
在不同文本中,相同单词的词向量是一样的,但是在实际情况下,不同文本的相同单词不一定是同一个意思;另外,它也不能考虑上下文的内容。因此 Word2Vec 本质上是静态的,后续 BERT 通过动态提取词向量解决了上述问题。
5. 目标函数
未完待续
三、Word2Vec-CBOW
CBOW 就是根据上下文词预测目标词,对于某个词的上下文,需要提前设置一个上下文窗口长度,然后通过窗口内的词语预测目标词
举例说明:
文本:“I love study english every day”,我们设置窗口为 2
那么上下文词 → 目标词就如下所示:
I love english every → study
love study every day → english
1. 前向过程
输出数据的维度为(N,T),表示 N 个文本, 每个文本有 T 个单词
- 第一步:Embedding 层将输入的上下文词都转换为上下文词的向量(N,T,E)
- 第二步:然后继续求出这些上下文词向量的平均值/和,即上下文的特征信息,一般而言求均值,因为求和的结果与序列长度有关,越长的序列,值就越大 (N,E)
- 第三步:Linear 层接受上下文向量并将其转换为输出向量;注意:这里的计算量非常大 (N, vocab_size)
- 第四步:用 Softmax 函数将器转换为各个类别的置信度

2. 代码实现
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim=128):
"""
:param vocab_size: 单词表的大小
:embedding_dim: w
:return: 模型的输出
"""
super(CBOW, self).__init__()
self.emb_layer = nn.Embedding(vocab_size, embedding_dim)
self.output_layer = nn.Linear(embedding_dim, vocab_size)
def forward(self, x):
"""
前向过程
:param x: [N,T] long
:return: 模型的输出
"""
x = self.emb_layer(x) # [N,T] -> [N,T,embedding_dim]
x = torch.sum(x, dim=1) # [N,T,embedding_dim] -> [N,embedding_dim]
x = self.output_layer(x) # [N,embedding_dim] -> [N,vocab_size] #得到的是每个样本对应的每个词的概率
return x
四、Word2Vec-Skip-gram
Skip-gram就是根据中心词预测上下文词,对于某个词的中心词,需要提前设置一个上下文窗口长度,然后通过窗口内的词语预测上下文词
举例说明:
文本:“I love study english every day”,我们设置窗口为 2
那么目标词 → 上下文词就如下所示:
study → I love english every
english → love study every day
1. 前向过程
输出数据的维度为(N,T),表示 N 个文本, 每个文本有 T 个单词
- 第一步:Embedding 层将输入的目标词都转换为目标词的向量(N,1,E)
- 第二步:然后将这个目标词的维度转换成 (N,E)
- 第三步:Linear 层接受目标词向量并将其转换为输出向量;注意:这里的计算量非常大 (N, vocab_size)
- 第四步:用 Softmax 函数将器转换为词汇表的每个词是目标词上下文的可能性
2. 代码实现
class SkipGram(nn.Module):
def __init__(self, vocab_size, embedding_dim=128):
super(SkipGram, self).__init__()
self.emb_layer = nn.Embedding(vocab_size, embedding_dim)
self.output_layer = nn.Linear(embedding_dim, vocab_size)
def forward(self, x):
"""
前向过程
:param x: [N,1] long
:return: 模型的输出
"""
x = self.emb_layer(x) # [N,1] -> [N,1,embedding_dim]
x = x[:,0,:] # [N,1,embedding_dim] -> [N,embedding_dim]
x = self.output_layer(x) # [N,embedding_dim] -> [N,vocab_size] #得到的是每个样本对应的每个词的概率
return x
总结
Word2Vec 将词汇表的每个单词的 One-Hot 编码映射为低维稠密的词向量,这种技术可以让具有较相似语义信息的单词在向量空间上的距离也相近。但是 Word2Vec 是静态词向量,因为这种技术对于相同的词id来说,他们的词向量是相同的,但是这种方式无法表达在不同文本尽管是同一个词但是能表达不同的意思,或是无法表达多义词,因为它尽管是一个词但是它应该具有不同的词向量。对于这种情况,后续的 Bert 可以通过动态的方式提取词向量,从而解决上述问题。
参考资料
- Language Models, Word2Vec, and Efficient Softmax Approximations
- word2vec原理(一) CBOW与Skip-Gram模型基础
- word2vec连续词袋模型CBOW详解,使用Pytorch实现