论文速看 Few-shot Image Generation with ElasticWeight Consolidation
Few-shot Image Generation with ElasticWeight Consolidation

Year: 2020
Paper link: link
文章目录
- Few-shot Image Generation with ElasticWeight Consolidation
-
- Abstract
-
- Induction
- Thoughts
-
- Related Work
-
- Few-shot learning
- Continuous learning
- What I get
- Questions
- Curial relative paper
- Method
-
- Analysis
- Importance measure
-
- Ablation
- Experiments
-
- dataset
- Quantitative comparisons
- Discussion
-
- Number of shots
- Regularization weight λ \lambda λ
- Dissimilarity between source and target
- Correspondence
- Conclusion
-
- do not know
- words
Abstract
We adapt a pretrained model, without introducing any additional parameters, to the few examples of the target domain.
Crucially, we regularize the changes of the weights during this adaptation, in order to best preserve the “information” of the source dataset, while fitting the target.
Induction
More formally, we study the problem of few-shot image generation in a continuous learning framework– training an algorithm to generate more data of a target domain, given only a few examples.
An underlying assumption with this setup is that the source and target domains share some latent factors, with some differences related to their distinct difference in appearance. For example, when transferring from real natural faces to emojis, variations in pose and expression can be naturally extended to the target domain.

Thoughts
A key property to note is that weights have different levels of importance; thus, each parameter should not be treated equally in the adaptation, or tuning process.
We propose to quantify the “importance” of each parameter, emphasizing preservation of important parameters during the tuning process.
In the discriminative modeling setting, Kirkpatrick et al. [17] propose Elastic Weight Consolidation(EWC), which evaluates the importance of each parameter by estimating its Fisher Information relative to the objective likelihood.
A key difference is in the generative setting, the training objective is not fixed.(?)
Nonetheless, we demonstrate that the Fisher Information can be estimated from a proxy objective(?) (a frozen discriminator) and are able to generate high-quality results of different target domains, even with extremely few examples ( ≤ 10 ) (\leq 10) (≤10).
In addition, we consider there will always be an inherent trade-off between preserving information from the source and adapting to the target domain.
Related Work
Few-shot learning
Few-shot learning [18] is first explored in discriminative tasks where the target class contains limited labelled instances, known as few-shot image classification.
The work of [28, 41] showed first promising high resolution results on complex natural images given the recent success in high-quality GAN training.
Such a pipeline involves many tedious manual designs and as we show later, works less effectively in extremely low-data cases.
[28] A. Noguchi and T. Harada. Image generation from small datasets via batch statistics adaptation. In ICCV, 2019.
[41] Y. Wang, A. Gonzalez-Garcia, D. Berga, L. Herranz, F. S. Khan, and J. van de Weijer. Minegan: effective knowledge transfer from gans to target domains with few images. In CVPR, 2020.
Continuous learning
Based on that, several recent work [35, 47, 43] extend these to the generative domain, i.e., learning different distributions sequentially without forgetting. However, all sequential tasks learned in those work are assumed to
contain enough data. The biggest difference of our focus is that for the target domain there are only a few examples. It is therefore necessary to distill knowledge learned from the previous source domain.
It is also noted that after the adaptation, we are no longer able to generate the data in source domain. What we are not trying to forget here is the diversity in source domain so that we could combine it with the style from the limited data of target domain to generate more diverse results.
[35] A. Seff, A. Beatson, D. Suo, and H. Liu. Continual learning in generative adversarial nets. arXiv preprint arXiv:1705.08395, 2017.
[47] M. Zhai, L. Chen, F. Tung, J. He, M. Nawhal, and G. Mori. Lifelong gan: Continual learning for conditional image generation. In ICCV, 2019.
[43] C. Wu, L. Herranz, X. Liu, J. van de Weijer, B. Raducanu, et al. Memory replay gans: Learning to generate new categories without forgetting. In NIPS, 2018.
What I get
- We see the authors compare the task mentioned in this paper with the continuous learning in the relative work which is so comprehending. Respect for the authors.
- realistic just mean are the generated images resample images from the target domain
- Concerning user study, a better method should fool users more easily to make a wrong decision.
- you can use LPIPS distance between a number of pairs of randomly generated images to measure the diversity of your generate model.
- Oh my God. Look at this. ‘Given that collecting real paired data is often labor intensive, one promising aspect of our method is that we can obtain unlimited number of synthetic paired data by leveraging the correspondence between the source and target model.’ Using the adaption method will help us to create new pairs of data. This idea is sparling while the effects is not good. Respect for the authors.
Questions
- λ = 5 × 1 0 8 \lambda=5\times10^8 λ=5×108 really? not big?
- How to calc the F F F information matrix during training?
Curial relative paper
[17] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho,A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
[26] A. Ly, M. Marsman, J. Verhagen, R. P. Grasman, and E.-J. Wagenmakers. A tutorial on fisher information. Journal of Mathematical Psychology, 80:40–55, 2017.
Method
Therefore, the remaining questions
- which weights are more important to preserve or have more freedom to change
- how to quantify such an importance factor so that we could regularize them via a loss function.
Analysis
We analyze the rate of change of the generator weights between the source and the target-adapted model.
It is interesting to know which weights change significantly when switching to learning another distribution.
We select real faces as the source domain using the CelebA dataset [24] ( ∼ 200 k \sim200k ∼200k images). For the target domain, we use emoji faces that depict stylized human-like heads. We use the Bitmoji API [11] to collect ∼ 80 k \sim80k ∼80k emoji images.
We design a five-layer DCGAN [30] network.
We first pretrain a generative model on faces and then fine-tune it on the emoji domain, both using the following adversarial loss:
L a d v = min G max D E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] L_{adv}=\mathop{\min}\limits_G\mathop{\max}\limits_DE_{x \sim p_{data(x)}}[\log D(x)]+E_{z\sim p_{z}(z)}[\log(1-D(G(z)))] Ladv=GminDmaxEx∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]

Given a pretrained G G G and the adapted G ′ G' G′ , we compute the average change rate of weights at each convolution layer(here, we omit the bias and other parameters in the normalization layers): Δ = 1 N ∑ i ∣ θ i − θ i ′ ∣ ∣ θ i ∣ \Delta=\frac{1}{N}\sum_i \frac{|\theta_i-\theta_i'|}{|\theta_i|} Δ=N1∑i∣θi∣∣θi−θi′∣,where N N N is number of parameters, θ \theta θ and θ i \theta_i θi is the i-th parameter in model G G G and G ′ G' G′.
From the results shown in Figure 2 (middle), we observe that the weights in the last layer of the network change the least on average compared to other early layers. Similar observations are also found in other GAN architectures (e.g., LapGAN [4], StyleGAN [16]) using other source-target domain pairs. This implies that if we do the adaptation with a few examples, some weights in the last layer are more important and should be better preserved than those in other layers.(just fine?)
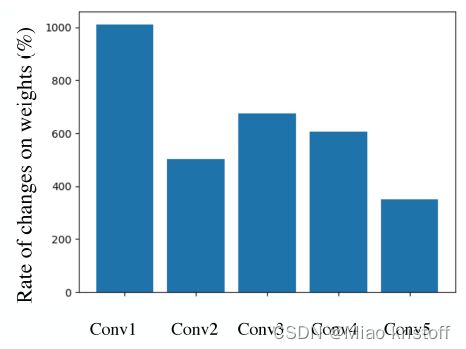
Importance measure
Recall that in mathematical statistics, the Fisher Information F F F could tell how well we estimate the model parameters given the observations [26].Given a pretrained generative model on the source domain, by generating a certain amount of data X X X given the learned values of network parameters θ S \theta_S θS, the Fisher information F F F can be computed as:
F = E [ − ∂ 2 ∂ θ S 2 L ( X ∣ θ S ) ] F=E[-\frac{\partial^2}{\partial \theta^2_S}L(X|\theta_S)] F=E[−∂θS2∂2L(X∣θS)]
where L ( X ∣ θ S ) L(X|\theta_S) L(X∣θS) is the log-likelihood function which is equivalent to computing the binary crossentropy loss using the output of a discriminator. For simplicity, we use the output of the discriminator and show the average F F F of weights at different layers in the G model trained on real faces in Figure 2 (right).
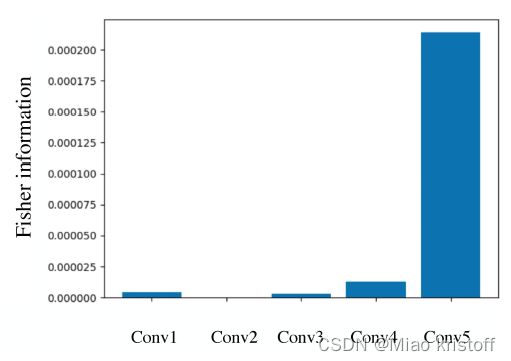
We notice that the weights in the last layer have much higher F than those in other layers. Considering our previous observation on the rate of change of weights in Figure 2 (middle), we could directly use F F F as an importance measure for weights and add a regularization loss to penalize the weight change during the adaptation to the target domain as follows:
L a d a p t = L a d v + λ ∑ i F i ( θ i − θ S , i ) 2 L_adapt = L_{adv}+\lambda\sum\limits_iF_i(\theta_i-\theta_{S,i})^2 Ladapt=Ladv+λi∑Fi(θi−θS,i)2
The second term in Equation was first proposed in [17] for the classification task and called the Elastic Weight Consolidation(EWC) loss. While the work of [17] uses the EWC loss to avoid forgetting how to classify old classes after learning new classes and there is sufficient data for all classes, here we want to demonstrate its effectiveness in the few-shot generative setting.
Ablation
To demonstrate the effectiveness of regularization during target adaptation, we specifically ablate the second term (i.e., the EWC loss) in Equation (3).The blue curve in Figure 3 (left) shows how fast the weights are changing without any regularization. Here we compute the EWC loss for visualization but do not use it, by setting λ = 0 \lambda = 0 λ=0. From the comparison of loss values in Figure 3 (left), we learn that adapting a few new examples only should not alter the original weight too much so that the information (e.g., diversity) from the source domain could be preserved.
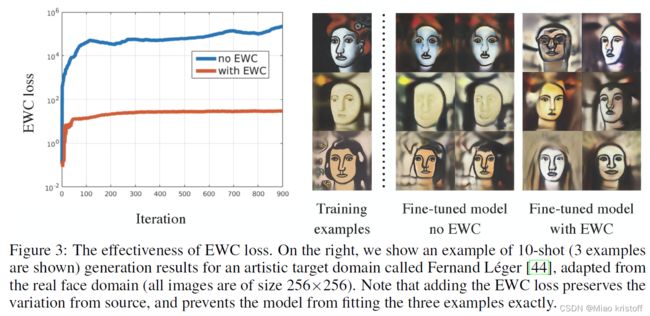
Experiments
We evaluate our method against three others: NST [6], BSA [28], and Mine-GAN [41].The Neural Style (NST) work of [6] represents a family of neural style transfer methods as adaptation to a new domain can be also regarded as a style transfer task.Both [28] and [41] also focus on adapting models from a source to a target domain but they introduce additional parameters. The BSA method [28] is adding new batch norm layers into the original BigGAN generator [2] and learning new parameters only during the adaptation.
The MineGAN approach [41] adds a small mining network M M M in front of the original Progressive GAN generator [15] and proposes a two-stage fine-tuning strategy(i.e., fine-tune M M M first and then fine-tune M M M jointly with the generator). For all experiments of our method in this work, we use the StyleGAN [16] framework.
dataset
We use the FFHQ dataset [16] as the source for real faces and several other face databases as the target: emoji faces from the Bitmoji API [11]; animal faces from the AFHQ dataset [3] and portrait paintings from the Artistic-Faces dataset [44].
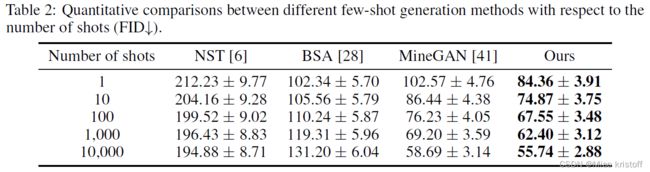
Quantitative comparisons
While we only use a few examples from the target domain to perform the adaptation, we divide the quantitative study into two parts, based on whether the target domain contains abundant data for evaluation.
If the target domain originally has a lot of real data, we select the commonly used Fréchet Inception Distance (FID) [10] which measures the quality of generated images obtained by the adapted model.
For target domains that have only a few examples available, FID is not a good metric for measuring the generation quality. Therefore, we conduct user studies to evaluate how realistic our generated results are compared with real examples.
For measuring diversity, we use the LPIPS metric [48] to measure the similarity among results, i.e. the distance between a number of pairs of randomly generated images.

Discussion
Number of shots

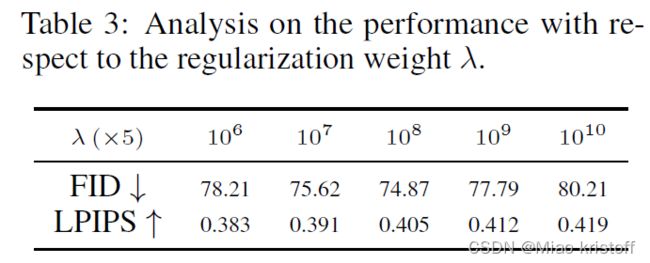
Regularization weight λ \lambda λ
The parameter λ \lambda λ in Equation (3) controls the power of regularization term added during the adaptation.
A larger value of λ \lambda λ would preserve too many details of the source, which hinders the adaptation to the target domain but preserves more diversity.
A smaller value of λ \lambda λ gives too much freedom on the changes of weight, which may result in the over-fitting to the target domain and reduce the diversity.
This represents the unavoidable trade-off we achieved between inheriting from the source and adapting to the target.
We empirically set λ = 5 × 1 0 8 \lambda =5 \times 10 ^8 λ=5×108 in all our experiments. In addition, we find that (i) if the source and target are more similar (e.g., from the male face to female face), select a larger λ \lambda λ to constrain the weight changes because a minor change might be enough for the adaptation, and (ii) if more target data is given, select a smaller λ \lambda λ.An extreme case is that there is no need to do any regularization (i.e., λ \lambda λ = 0) if there is abundant data available in target domain.
Dissimilarity between source and target

On the rightmost, the results of color pencil landscape domain adapted from FFHQ obviously do not make much sense as we could still observe the silhouette of face preserved. Adding the EWC regularization is not sufficient to change the semantic shape from face to landscape.

Correspondence

Given that collecting real paired data is often labor intensive, one promising aspect of our method is that we can obtain unlimited number of synthetic paired data by leveraging the correspondence between the source and target model.
Conclusion
In this work, we focus on the challenging task of unconditional image generation in low-data regime. Given a few examples only in the target domain, we adapt a pretrained generative model learned on the source domain with abundant data to generate more data of the target domain.
The proposed method is simple and effective, and may shed light on more future understandings of the learned parameters.
do not know
- DCGAN strided two dimensional convolutional transpose layers
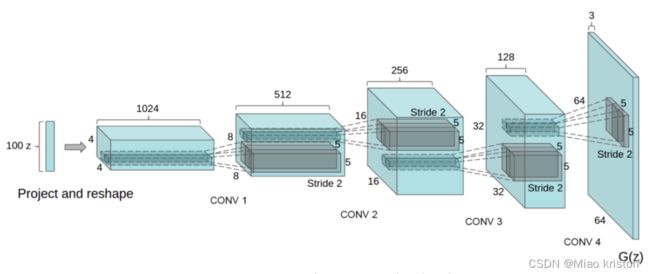
# Generator Code
'''Notice, how the inputs we set in the input section (nz, ngf, and nc) influence the generator architecture in code. nz is the length of the z input vector, ngf relates to the size of the feature maps that are propagated through the generator, and nc is the number of channels in the output image (set to 3 for RGB images). Below is the code for the generator.'''
class Generator(nn.Module):
def __init__(self, ngpu):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# state size. ``(ngf*8) x 4 x 4``
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# state size. ``(ngf*4) x 8 x 8``
nn.ConvTranspose2d( ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# state size. ``(ngf*2) x 16 x 16``
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# state size. ``(ngf) x 32 x 32``
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. ``(nc) x 64 x 64``
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self, ngpu):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is ``(nc) x 64 x 64``
nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf) x 32 x 32``
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*2) x 16 x 16``
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*4) x 8 x 8``
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. ``(ndf*8) x 4 x 4``
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
words
consolidation合并,整合
proxy代理,代表
discriminative辨别
distill v. 蒸馏,提取;滴下
unlikely adj. 不太的;没希望的
deviate vi. 越轨;脱离
cluttered 杂乱,混乱
imperative 必要的,紧急的, 极重的,命令的,祈使的
conjecture推测,猜想