大数据技术与应用开发赛项笔记
各种启动命令
修改mysql数据库编码:alter database shtd_result CHARACTER SET utf8;
hadoop : start-all.sh
hive服务: hive --service metastore
hive 客户端 :hive
dolphinscheduler服务:./bin/dolphinscheduler-daemon.sh start standalone-server
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。
默认的用户名和密码是 admin/dolphinscheduler123hive服务:hive --service hiveserver2
hive2连接:beeline -u jdbc:hive2://192.168.182.103:10000 -n root关闭hadoop安全模式 hdfs dfsadmin -safemode leave
azkaban启动服务:bin/azkaban-solo-start.sh
azkaban停止服务:bin/azkaban-solo-shutdown.shazkaban服务端口:8081
azkaban用户名和密码默认都是azkabanclickhouse服务端启动命令:systemctl start clickhouse-server
clickhouse客户端启动:clickhouse-client --password clickhouse --port 9001
zookeeper服务启动:bin/zkServer.sh start
zookeeper查看状态:bin/zkServer.sh status
zookeeper客户端:bin/zkCli.sh
kafka启动命令:bin/kafka-server-start.sh -daemon config/server.properties
kafka停止命令:bin/kafka-server-stop.sh
kafka客户端:bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 2 --replication-factor 2 --topic hello
hbase服务:start-hbase.sh
hbase客户端:bin/hbase shell
flinkonyarn:bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
flink服务端启动:start-cluster.sh
hudi-shell 启动命令
# Spark 3.2
spark-shell\
--packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
spark-sql --packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
spark-submit --master yarn --packages org.apache.hudi:hudi-spark3.2-bundle_2.12:0.12.0 --class gs_2.task03 ./bigdata03.jar 2
# Spark 3.1
spark-shell \
--packages org.apache.hudi:hudi-spark3.1-bundle_2.12:0.12.0 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
spark-submit --master yarn --packages org.apache.hudi:hudi-spark3.1-bundle_2.12:0.12.0 --class gs_2.task03 ./bigdata03.jar 2
hudi加载从idea指定路径创建的表
create table hudi_existing_tbl using hudi
location '/tmp/hudi/hudi_existing_table';
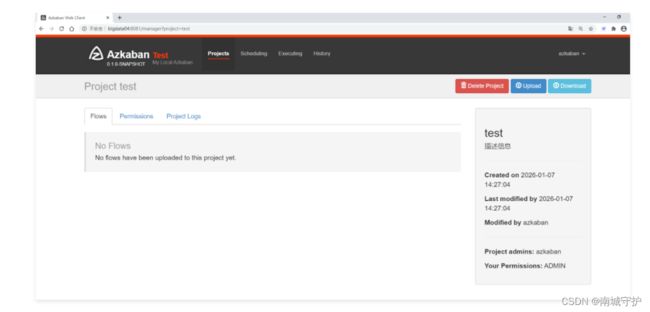
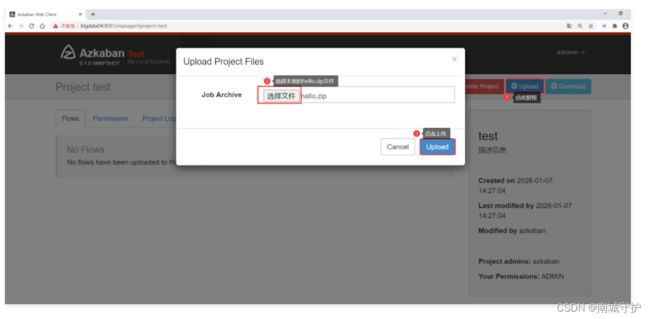
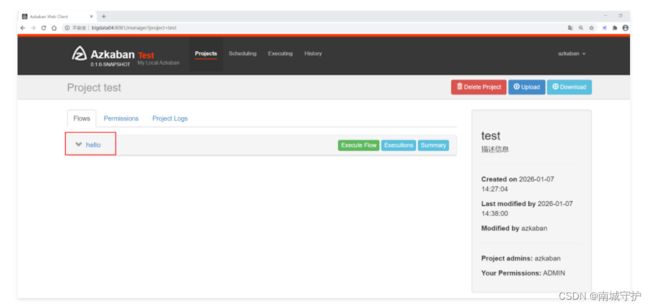
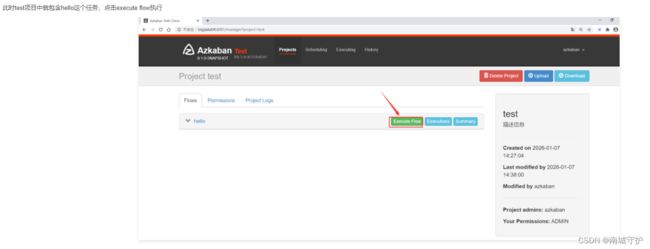
Azkaban调度器
Clickhouse类型和建表语句
create table cs(
provinceid Int,
provincename String,
provinceavgconsumption Float64,
regionid Int,
regionname String,
regionavgconsumption Float64,
comparison String
)
ENGINE=MergeTree()
ORDER BY (provinceid);数值类型里面包含Int、UInt、Float、Decimal这些。
针对Int类型,我们在使用MySQL的时候一般会用到TinyInt、SmallInt、Int、BigInt之类的。因为不同的Int类型取值范围是不一样的,需要根据业务需求选择合适的类型。
但是ClickHouse里面没有提供这些Int类型,他提供了Int8、Int16、Int32、Int64来表示4种大小的Int类型。
其中Int8的取值范围是-128~127(-2的7次方到2的7次方-1),和MySQL中的TinyInt取值范围是一样的。和Java中的byte类型的取值范围也是一样的。
Int16的取值范围是-32768~32767(-2的15次方到2的15次方-1),和MySQL中的SmallInt取值范围是一样的。和Java中的short类型的取值范围也是一样的。
Int32的取值范围是-2147483648~2147483647(-2的31次方到2的31次方-1),和MySQL中的Int取值范围是一样的。和Java中的int类型的取值范围也是一样的。
Int64的取值范围是-9223372036854774808~9223372036854774807(-2的63次方到2的63次方-1),和MySQL中的BigInt取值范围是一样的。和Java中的long类型的取值范围也是一样的。
所以一般默认使用Int32即可。
ClickHouse也支持无符号的整数,使用前缀U表示。UInt8的取值范围是0~255。(0到2的8次方-1)UInt16的取值范围是0~65535。(0到2的16次方-1)UInt32的取值范围是0~4294967295(0到2的32次方-1)UInt64的取值范围是0~18446744073709551615(0到2的64次方-1)
针对Float类型,ClickHouse提供了Float32和Float64。
其中Float32表示单精度浮点数,最多保证小数点后7位的精度,类似于MySQL中的Float类型。
Float64表示双精度浮点数,最多保证小数点后16位的精度,类似于MySQL中的Double类型。
如果要求更高精度的数值运算,则需要使用Decimal类型了。
ClickHouse提供了Decimal32(S)、Decimal64(S)、Decimal128(S)这三种简写形式。Decimal32表示限制数字总位数是1~9,最多9位,通过S指定小数位数。Decimal64表示限制数字总位数是10~18,最多18位,通过S指定小数位数。Decimal128表示限制数字总位数是19~38,最多38位,通过S指定小数位数。
一般一些金融相关的数据为了保证小数点精度,会使用Decimal类型进行存储。
注意:ClickHouse中的数据类型在使用的时候,首字母都是需要大写的,有一些数据类型也是可以使用小写的,但是最终存储到ClickHouse里面之后还是以大写的形式存储的,所以建议大家还是按照标准写法去写。
其中有一些特殊用法:int = Int32 float = Float32,大家看到这些写法能认出来就行了。
环境前置
配置代码
package Environment
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import java.util.Properties
class environment_util {
Logger.getLogger("org").setLevel(Level.ERROR)
// 数据库链接与用户信息
private val url = "jdbc:mysql://192.168.10.1/shtd_store?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai"
private val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","admin")
// 解决报错:Exception in thread "main" java.sql.SQLException: No suitable driver
// 原因:找不到驱动
prop.setProperty("driver","com.mysql.cj.jdbc.Driver")
// 获取sparkSession
def getSparkSession:SparkSession={
val conf = new SparkConf().setMaster("local").setAppName("国赛第一套")
new SparkSession.Builder().config(conf)
.config("hive.exec.dynamic.partition","true")
.config("hive.exec.dynamic.partition.mode","nonstrict")
// 解决hive查询中报错:Failed with exception java.io.IOException:org.apache.parquet.io.ParquetDecodingException: Can not read value at 0 in block -1 in file hdfs://bigdata01:9000/
// 出现这个报错的根本原因是因为Hive和Spark中使用的不同的parquet约定引起的。
.config("spark.sql.parquet.writeLegacyFormat","true")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.storeAssignmentPolicy","LEGACY")
.enableHiveSupport().getOrCreate()
}
// 读取MySql表
def readMysql(tableName:String):DataFrame={
getSparkSession.read.jdbc(url,tableName,prop)
}
//写入MySql表
def writeMySql(dataFrame: DataFrame,tableName:String,database:String):Unit={
dataFrame.write.mode("overwrite").jdbc(s"jdbc:mysql://192.168.10.1/$database?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai",tableName,prop)
}
def readHudi(tableName:String,database:String="ods",partition:String="/*/*"):DataFrame={
this.getSparkSession.read.format("hudi").load(this.getHuDiPath(tableName,database) + partition)
}
def writeHudi(df:DataFrame,tableName:String,path:String="ods",preCombineField:String,primaryKey:String="id",partition:String="etl_date"):Unit={
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs
df.write.format("hudi")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD.key(),preCombineField)
.option(RECORDKEY_FIELD.key(),primaryKey)
.option(PARTITIONPATH_FIELD.key(),partition)
.option(OPERATION.key(),"insert_overwrite")
.option(TBL_NAME.key(),tableName)
.mode("append")
.save(s"/user/hive/warehouse/${path}_ds_hudi.db/$tableName")
}
def getHuDiPath(tableName:String,database:String="ods"):String= {
"/user/hive/warehouse/"+database+"_ds_hudi.db/" + tableName
}
}
代码
package Environment
import org.apache.spark.sql.functions.{col, current_timestamp}
import org.apache.spark.sql.types.{DecimalType, LongType}
object environment {
def main(args: Array[String]): Unit = {
/**
* 作者: 南城
* 使用说明:
* hive_environment 初始化hive的环境
* hudi_environment 初始化hudi的环境
* 注意:
* (在使用hudi_environment这个之前需要先使用hive_environment)
*/
val gs_1_util = new environment_util
// hive 环境
// hive_environment(gs_1_util)
hudi_environment(gs_1_util)
}
def hudi_environment(gs_1_util:environment_util): Unit = {
val spark = gs_1_util.getSparkSession
// hudi_ods
Map(
"user_info" -> "operate_time",
// "sku_info" -> "operate_time",
"sku_info" -> "create_time",
"base_province" -> "create_time",
"base_region" -> "create_time",
"order_info" -> "operate_time",
"order_detail" -> "create_time"
).foreach(tableName => {
println(tableName._1 + " 执行sql ………………")
var df = spark.sql(s"select * from ods.${tableName._1}")
if (tableName._1.equals("base_region") || tableName._1.equals("base_province")) {
df = df.withColumn("create_time", current_timestamp())
}
if (tableName._1.equals("order_info")) {
df = df
.withColumn("final_total_amount", col("final_total_amount").cast(DecimalType(10, 0)))
.withColumn("user_id", col("user_id").cast(LongType))
}
df.show(5)
df.printSchema()
println(tableName._1 + " 存入中 ………………")
gs_1_util.writeHudi(df, s"${tableName._1}", preCombineField = tableName._2)
println(tableName._1 + " 采集完毕 !!!!")
})
// hudi_dwd
Map(
"dim_user_info" -> "operate_time",
"dim_sku_info" -> "dwd_modify_time",
"dim_province" -> "dwd_modify_time",
"dim_region" -> "dwd_modify_time"
).foreach(tableName => {
println(tableName + " 开始执行 sql ………………")
val df = spark.sql(s"select * from dwd.${tableName._1}")
df.show()
println(tableName + " 开始存入 ………………")
gs_1_util.writeHudi(df, s"${tableName._1}", "dwd", tableName._2)
println(tableName + " 数据采集完毕!!!")
})
}
def hive_environment(gs_1_util:environment_util): Unit = {
println("""环境执行中""")
gs_1_util.getSparkSession.sql(
"""
|drop table if exists ods.user_info
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists ods.user_info
|(
|`id` bigint,
|`login_name` string,
|`nick_name` string,
|`passwd` string,
|`name` string,
|`phone_num` string,
|`email` string,
|`head_img` string,
|`user_level` string,
|`birthday` date,
|`gender` string,
|`create_time` timestamp,
|`operate_time` timestamp
|) partitioned by (`etl_date` string)
|row format delimited
|fields terminated by '\001'
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table ods.user_info partition (etl_date = "19971201")
|select 6814,
|"89xtog",
|"阿清",
|"",
|"成清",
|13935394894,
|"[email protected]",
|"",
|1,
|date("1965-04-26"),
|"M",
|timestamp("2020-04-26 18:55:55"),
|timestamp("2020-04-26 5:53:55")
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists ods.sku_info;
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists ods.sku_info
|(
|`id` bigint,
|`spu_id` bigint,
|`price` decimal(10, 0),
|`sku_name` string,
|`sku_desc` string,
|`weight` decimal(10, 2),
|`tm_id` bigint,
|`category3_id` bigint,
|`sku_default_img` string,
|`create_time` timestamp
|) partitioned by (etl_date string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table ods.sku_info partition (etl_date = "19971201")
|select 1,
|1,
|2220,
|"测试",
|"new sku_desc",
|0.24,
|2,
|61,
|"http://AOvKmfRQEBRJJllwCwCuptVAOtBBcIjWeJRsmhbJ",
|timestamp("1997-12-01 12:21:13")
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists ods.base_province
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists ods.base_province
|(
|`id` bigint,
|`name` string,
|`region_id` string,
|`area_code` string,
|`iso_code` string,
|`create_time` timestamp
|) partitioned by (etl_date string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table ods.base_province partition (etl_date = "19971201")
|select 0, "测试", 0, 110000, "CN-11", null
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists ods.base_region
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists ods.base_region
|(
|`id` string,
|`region_name` string,
|`create_time` timestamp
|) partitioned by (etl_date string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table ods.base_region partition (etl_date = "19971201")
|select 0, "测试", null
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists ods.order_info
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists ods.order_info
|(
|`id` bigint,
|`consignee` string COMMENT '收货人',
|`consignee_tel` string COMMENT '收件人电话',
|`final_total_amount` decimal COMMENT '总金额',
|`order_status` string COMMENT '订单状态',
|`user_id` bigint COMMENT '用户id(对应用户表id)',
|`delivery_address` string COMMENT '送货地址',
|`order_comment` string COMMENT '订单备注',
|`out_trade_no` string COMMENT '订单交易编号(第三方支付用)',
|`trade_body` string COMMENT '订单描述(第三方支付用)',
|`create_time` timestamp COMMENT '创建时间',
|`operate_time` timestamp COMMENT '操作时间',
|`expire_time` timestamp COMMENT '失效时间',
|`tracking_no` string COMMENT '物流单编号',
|`parent_order_id` bigint COMMENT '父订单编号',
|`img_url` string COMMENT '图片路径',
|`province_id` int COMMENT '省份id(对应省份表id)',
|`benefit_reduce_amount` decimal(16, 2) COMMENT '优惠金额',
|`original_total_amount` decimal(16, 2) COMMENT '原价金额',
|`feight_fee` decimal(16, 2) COMMENT '运费'
|) partitioned by (etl_date string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table ods.order_info partition (etl_date = "19971201")
|select 3443,
|"测试",
|13207871570,
|1449.00,
|1005,
|2790,
|"第4大街第5号楼4单元464门",
|"描述345855",
|214537477223728,
|"小米Play 流光渐变AI双摄 4GB+64GB 梦幻蓝 全网通4G 双卡双待 小水滴全面屏拍照游戏智能手机等1件商品",
|timestamp("1997-04-25 18:47:14"),
|timestamp("1997-04-26 18:59:01"),
|timestamp("2020-04-25 19:02:14"),
|"",
|null,
|"http://img.gmall.com/117814.jpg,20,0.00,1442.00,7.00",
|20,
|0.00,
|1442.00,
|7.00
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists ods.order_detail
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists ods.order_detail
|(
|`id` bigint COMMENT '主键',
|`order_id` bigint COMMENT '订单编号(对应订单信息表id)',
|`sku_id` bigint COMMENT '商品id(对应商品表id)',
|`sku_name` string COMMENT '商品名称',
|`img_url` string COMMENT '图片路径',
|`order_price` decimal(10, 2) COMMENT '购买价格(下单时的商品价格)',
|`sku_num` string COMMENT '购买数量',
|`create_time` timestamp COMMENT '创建时间',
|`source_type` string COMMENT '来源类型',
|`source_id` bigint COMMENT '来源编号'
|) partitioned by (etl_date string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table ods.order_detail partition (etl_date = "19971201")
|select 8621,
|3443,
|4,
|"测试",
|"http://SXlkutIjYpDWWTEpNUiisnlsevOHVElrdngQLgyZ",
|1442.00,
|1,
|timestamp("1997-12-01 18:47:14"),
|2401,
|null
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists dwd.dim_user_info
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists dwd.dim_user_info
|(
|`id` bigint,
|`login_name` string,
|`nick_name` string,
|`passwd` string,
|`name` string,
|`phone_num` string,
|`email` string,
|`head_img` string,
|`user_level` string,
|`birthday` date,
|`gender` string,
|`create_time` timestamp,
|`operate_time` timestamp,
|`dwd_insert_user` string,
|`dwd_insert_time` timestamp,
|`dwd_modify_user` string,
|`dwd_modify_time` timestamp
|) partitioned by (etl_date string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert overwrite table dwd.dim_user_info partition (etl_date = "20220719")
|select 476,
|"mtjbajlpg",
|"琬琬",
|"",
|"臧凤洁",
|13981274672,
|"[email protected]",
|"",
|1,
|date("1996-04-26"),
|"F",
|timestamp("2020-04-26 18:57:55"),
|timestamp("2020-04-26 00:31:50"),
|"user1",
|timestamp("1997-12-01 00:00:00"),
|"user1",
|timestamp("2022-07-23 10:06:16")
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists dwd.dim_sku_info
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists dwd.dim_sku_info
|(
|`id` bigint,
|`spu_id` bigint,
|`price` decimal(10, 0),
|`sku_name` string,
|`sku_desc` string,
|`weight` decimal(10, 2),
|`tm_id` bigint,
|`category3_id` bigint,
|`sku_default_img` string,
|`create_time` timestamp,
|`dwd_insert_user` string,
|`dwd_insert_time` timestamp,
|`dwd_modify_user` string,
|`dwd_modify_time` timestamp
|)
|PARTITIONED BY ( `etl_date` string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert into table dwd.dim_sku_info partition (etl_date = "20220719")
|select 1,
|1,
|2220,
|"测试",
|"new sku_desc",
|0.24,
|2,
|61,
|"http://AOvKmfRQEBRJJllwCwCuptVAOtBBcIjWeJRsmhbJ",
|timestamp("1997-12-01 12:21:13"),
|"user1",
|timestamp("1997-12-01 00:00:00"),
|"user1",
|timestamp("1997-12-01 00:00:01")
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists dwd.dim_province
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists dwd.dim_province
|(
|`id` bigint,
|`name` string,
|`region_id` string,
|`area_code` string,
|`iso_code` string,
|`create_time` timestamp,
|`dwd_insert_user` string,
|`dwd_insert_time` timestamp,
|`dwd_modify_user` string,
|`dwd_modify_time` timestamp
|) PARTITIONED BY ( `etl_date` string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert overwrite table dwd.dim_province partition (etl_date = "19971201")
|select 0,
|"测试",
|0,
|110000,
|"测试",
|timestamp("1997-07-20 20:52:27.395000000"),
|"user1",
|timestamp("1997-12-01 00:00:00"),
|"user1",
|timestamp("1997-12-01 00:00:01")
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists dwd.dim_region
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists dwd.dim_region
|(
|`id` string,
|`region_name` string,
|`create_time` timestamp,
|`dwd_insert_user` string,
|`dwd_insert_time` timestamp,
|`dwd_modify_user` string,
|`dwd_modify_time` timestamp
|) PARTITIONED BY ( `etl_date` string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|insert overwrite table dwd.dim_region partition (etl_date = "19971201")
|select 0,
|"测试",
|timestamp("1997-07-20 20:53:10.658000000"),
|"user1",
|timestamp("1997-12-01 00:00:00"),
|"user1",
|timestamp("1997-12-01 00:00:01")
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists dwd.fact_order_info
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table if not exists dwd.fact_order_info
|(
|`id` bigint,
|`consignee` string,
|`consignee_tel` string,
|`final_total_amount` decimal(10),
|`order_status` string,
|`user_id` bigint,
|`delivery_address` string,
|`order_comment` string,
|`out_trade_no` string,
|`trade_body` string,
|`create_time` timestamp,
|`operate_time` timestamp,
|`expire_time` timestamp,
|`tracking_no` string,
|`parent_order_id` bigint,
|`img_url` string,
|`province_id` int,
|`benefit_reduce_amount` decimal(16, 2),
|`original_total_amount` decimal(16, 2),
|`feight_fee` decimal(16, 2),
|`dwd_insert_user` string,
|`dwd_insert_time` timestamp,
|`dwd_modify_user` string,
|`dwd_modify_time` timestamp
|) PARTITIONED BY ( `etl_date` string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|drop table if exists dwd.fact_order_detail
|""".stripMargin)
gs_1_util.getSparkSession.sql(
"""
|create table dwd.fact_order_detail
|(
|id bigint,
|order_id bigint,
|sku_id bigint,
|sku_name string,
|img_url string,
|order_price decimal(10, 2),
|sku_num string,
|create_time timestamp,
|source_type string,
|source_id bigint,
|`dwd_insert_user` string,
|`dwd_insert_time` timestamp,
|`dwd_modify_user` string,
|`dwd_modify_time` timestamp
|) PARTITIONED BY ( `etl_date` string)
|row format delimited
|fields terminated by "\001"
|stored as textfile
|""".stripMargin)
println("""环境执行结束""")
}
}
任务B:hive离线数据处理--电商(25分)
子任务一:数据抽取
编写Scala代码,使用Spark将MySQL的shtd_store库中表user_info、sku_info、base_province、base_region、order_info、order_detail的数据增量抽取到Hive的ods库中对应表user_info、sku_info、base_province、base_region、order_info、order_detail中。
- 抽取shtd_store库中user_info的增量数据进入Hive的ods库中表user_info。根据ods.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中sku_info的增量数据进入Hive的ods库中表sku_info。根据ods.sku_info表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.sku_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中base_province的增量数据进入Hive的ods库中表base_province。根据ods.base_province表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.base_province命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中base_region的增量数据进入Hive的ods库中表base_region。根据ods.base_region表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.base_region命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中order_info的增量数据进入Hive的ods库中表order_info,根据ods.order_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.order_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中order_detail的增量数据进入Hive的ods库中表order_detail,根据ods.order_detail表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。使用hive cli执行show partitions ods.order_detail命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
配置类代码
package gs_1
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import java.util.Properties
class gs_1_util {
Logger.getLogger("org").setLevel(Level.ERROR)
// 数据库链接与用户信息
private val url = "jdbc:mysql://192.168.10.1/shtd_store?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai"
private val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","admin")
// 解决报错:Exception in thread "main" java.sql.SQLException: No suitable driver
// 原因:找不到驱动
prop.setProperty("driver","com.mysql.cj.jdbc.Driver")
// 比赛MySQL 5.0用下面的驱动
prop.setProperty("driver","com.mysql.jdbc.Driver")
// 获取sparkSession
def getSparkSession:SparkSession={
val conf = new SparkConf().setMaster("local").setAppName("国赛第一套")
new SparkSession.Builder().config(conf)
.config("hive.exec.dynamic.partition","true")
.config("hive.exec.dynamic.partition.mode","nonstrict")
// 解决hive查询中报错:Failed with exception java.io.IOException:org.apache.parquet.io.ParquetDecodingException: Can not read value at 0 in block -1 in file hdfs://bigdata01:9000/
// 出现这个报错的根本原因是因为Hive和Spark中使用的不同的parquet约定引起的。
.config("spark.sql.parquet.writeLegacyFormat","true")
.enableHiveSupport().getOrCreate()
}
// 读取MySql表
def readMysql(tableName:String):DataFrame={
getSparkSession.read.jdbc(url,tableName,prop)
}
//写入MySql表
def writeMySql(dataFrame: DataFrame,tableName:String,database:String):Unit={
dataFrame.write.mode("overwrite").jdbc(s"jdbc:mysql://192.168.10.1/$database?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai",tableName,prop)
}
}
package gs_1
import org.apache.spark.sql.SaveMode
import org.apache.spark.sql.functions.lit
object task01 {
def test1(util:gs_1_util,tableName:String):Unit={
// 静态分区设置
val partition = "20230926"
// 读取mysql和ods库的表
util.readMysql(tableName).createOrReplaceTempView(tableName)
tableName match {
// 对user_info 表的处理
case "user_info" | "order_info" =>
// 读取 ods hive中最大的时间
val ods_max_time = util.getSparkSession.sql(
s"""
|select
| max(greatest(operate_time,create_time)) max_time
|from
| ods.${tableName}
|""".stripMargin).collect()(0)(0)
println(s"$tableName,create_time和operate_time最大时间为:$ods_max_time")
// 比较大小和添加静态分区的字段
println(s" ${tableName} 执行比较大小和添加静态分区的字段sql中")
val frame = util.getSparkSession.sql(
s"""
|select
| *,
| '20230926' etl_date
|from
| ${tableName}
|where
| operate_time > '${ods_max_time}'
|or
| create_time > '${ods_max_time}'
|""".stripMargin)
frame.show(20)
// 写入hive ods库
println(s" ${tableName} 写入hive ods库执行中")
frame.write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"ods.${tableName}")
// 对 sku_info表 的处理
case "sku_info" | "order_detail" =>
val ods_max_time = util.getSparkSession.sql(
s"""
|select
| max(create_time) max_time
|from
| ods.${tableName}
|""".stripMargin).collect()(0)(0)
println(s"$tableName,create_time最大时间为:$ods_max_time")
// 比较大小和添加静态分区的字段
println(s" ${tableName} 执行比较大小和添加静态分区的字段sql中")
val frame = util.getSparkSession.sql(
s"""
|select
| *,
| '20230926' etl_date
|from
| ${tableName}
|where
| create_time > '${ods_max_time}'
|""".stripMargin)
frame.show(20)
// 写入hive ods库
println(s" ${tableName} 写入hive ods库执行中")
frame.write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"ods.${tableName}")
// 对 base_province | base_region 表处理
case "base_province" | "base_region" =>
val max_ods_id = util.getSparkSession.sql(s"select max(id) from ods.${tableName}").collect()(0)(0)
println(s"$tableName,最大id为:$max_ods_id")
val frame = util.getSparkSession.sql(
s"""
|select
| *,
| current_timestamp() create_time,
| '20230926' etl_date
|from
| ${tableName}
|where
| id > ${max_ods_id}
|""".stripMargin)
frame.show(20)
println(s"${tableName} 存入中")
frame.write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"ods.${tableName}")
}
}
def main(args: Array[String]): Unit = {
val gs_1_util = new gs_1_util
// 抽取shtd_store库中user_info的增量数据进入Hive的ods库中表user_info。
test1(gs_1_util,"user_info")
// 抽取shtd_store库中sku_info的增量数据进入Hive的ods库中表sku_info。
test1(gs_1_util,"sku_info")
// 抽取shtd_store库中base_province的增量数据进入Hive的ods库中表base_province。
test1(gs_1_util,"base_province")
// 抽取shtd_store库中base_region的增量数据进入Hive的ods库中表base_region。
test1(gs_1_util,"base_region")
// 抽取shtd_store库中order_info的增量数据进入Hive的ods库中表order_info
test1(gs_1_util,"order_info")
// 抽取shtd_store库中order_detail的增量数据进入Hive的ods库中表order_detail
test1(gs_1_util,"order_detail")
}
}
子任务二:数据清洗
编写Scala代码,使用Spark将ods库中相应表数据全量抽取到Hive的dwd库中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
- 抽取ods库中user_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_user_info最新分区现有的数据,根据id合并数据到dwd库中dim_user_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据operate_time排序取最新的一条),分区字段为etl_date且值与ods库的相对应表该值相等,同时若operate_time为空,则用create_time填充,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条记录第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均存当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。使用hive cli执行show partitions dwd.dim_user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库sku_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_sku_info最新分区现有的数据,根据id合并数据到dwd库中dim_sku_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。使用hive cli查询表dim_sku_info的字段id、sku_desc、dwd_insert_user、dwd_modify_time、etl_date,条件为最新分区的数据,id大于等于15且小于等于20,并且按照id升序排序,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库base_province表中昨天的分区(子任务一生成的分区)数据,并结合dim_province最新分区现有的数据,根据id合并数据到dwd库中dim_province的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。使用hive cli在表dwd.dim_province最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods库base_region表中昨天的分区(子任务一生成的分区)数据,并结合dim_region最新分区现有的数据,根据id合并数据到dwd库中dim_region的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。使用hive cli在表dwd.dim_region最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 将ods库中order_info表昨天的分区(子任务一生成的分区)数据抽取到dwd库中fact_order_info的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,同时若operate_time为空,则用create_time填充,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli执行show partitions dwd.fact_order_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 将ods库中order_detail表昨天的分区(子任务一中生成的分区)数据抽取到dwd库中fact_order_detail的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。使用hive cli执行show partitions dwd.fact_order_detail命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
package gs_1
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions.{col, when}
object task02 {
def test01(util:gs_1_util,odsTableName:String,dwdTableName:String):Unit={
// user_info operate_time 为空用 create_time 填充 || "sku_info" | "base_province" | "base_region" 无要求
odsTableName match {
case "user_info" =>
println(s" ${odsTableName} 读取ods表和dwd表,同时若operate_time为空,则用create_time填充………… ")
// 读取ods表和dwd表
util.getSparkSession.sql(s"select * from ods.${odsTableName}")
// 同时若operate_time为空,则用create_time填充
.withColumn("operate_time",when(col("operate_time").isNull,col("create_time")).otherwise(col("operate_time")))
// 抽取ods库中user_info表中昨天的分区(子任务一生成的分区)数据
.where(col("etl_date") === "20230926")
// 为了使后面的数据对齐,所以这里删掉分区字段
.drop("etl_date")
.createOrReplaceTempView(s"${odsTableName}")
util.getSparkSession.sql(s"select * from dwd.${dwdTableName}")
// 为了使后面的数据对齐,所以这里删掉分区字段
.drop("etl_date")
// 同时若operate_time为空,则用create_time填充
.withColumn("operate_time",when(col("operate_time").isNull,col("create_time")).otherwise(col("operate_time")))
.createOrReplaceTempView(s"${dwdTableName}")
case "sku_info" | "base_province" | "base_region" =>
println("""" sku_info" | "base_province" | "base_region" 无要求 """)
// 读取ods表和dwd表
util.getSparkSession.sql(s"select * from ods.${odsTableName}")
// 抽取ods库中user_info表中昨天的分区(子任务一生成的分区)数据
.where(col("etl_date") === "20230926")
// 为了使后面的数据对齐,所以这里删掉分区字段
.drop("etl_date")
.createOrReplaceTempView(s"${odsTableName}")
util.getSparkSession.sql(s"select * from dwd.${dwdTableName}")
// 为了使后面的数据对齐,所以这里删掉分区字段
.drop("etl_date")
.createOrReplaceTempView(s"${dwdTableName}")
}
println("为ods表新增4个字段")
util.getSparkSession.sql(
s"""
|select
| *,
| 'user1' dwd_insert_user,
| current_timestamp() dwd_insert_time,
| 'user1' dwd_modify_user,
| current_timestamp() dwd_modify_time
|from
| ${odsTableName}
|""".stripMargin).createOrReplaceTempView(s"${odsTableName}_1")
println("添加成功,表如下:")
util.getSparkSession.sql(s"""select * from ${odsTableName}_1""").show(false)
println("合并ods表和dwd表")
util.getSparkSession.sql(s"select * from ${odsTableName}_1").union(util.getSparkSession.sql(s"select * from ${dwdTableName}")).createOrReplaceTempView(s"ods_dwd_${odsTableName}")
println("合并成功,表如下:")
util.getSparkSession.sql(s"""select * from ods_dwd_${odsTableName}""").show(false)
odsTableName match {
case "user_info" =>
println(s"""${dwdTableName} 修改的数据以id为合并字段,根据operate_time排序取最新的一条.若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值""")
val frame = util.getSparkSession.sql(
s"""
|select
| *,
| lead(dwd_insert_time) over(partition by id order by operate_time desc) lead_dwd_insert_time,
| row_number() over(partition by id order by operate_time desc) row_number,
| "20230926" etl_date
|from
| ods_dwd_${odsTableName}
|""".stripMargin)
// 等于1为新增的数据
.where(col("row_number") === 1)
// 若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变
.withColumn("dwd_insert_time",when(col("lead_dwd_insert_time").isNotNull,col("lead_dwd_insert_time")).otherwise(col("dwd_insert_time")))
// 删除中间字段
.drop("lead_dwd_modify_time","row_number")
println("执行 sql 成功,表如下:")
frame.show(truncate = false,numRows = 20)
println("""这里有个报错:Exception in thread "main" org.apache.spark.sql.AnalysisException: Cannot overwrite table dwd.dim_user_info that is also being read from""")
println("""读写同时报错,我的解决办法是,创建临时表b,删除原表a,表b创建表a,表a删除。""")
frame.write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"dwd.${dwdTableName}_B") // 创建 B
util.getSparkSession.sql(s"drop table dwd.${dwdTableName}") // 删除 A
util.getSparkSession.sql(s"select * from dwd.${dwdTableName}_B").write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"dwd.${dwdTableName}") // 复制B创建A
util.getSparkSession.sql(s"drop table dwd.${dwdTableName}_B") // 删除 B
println(s"dwd.${dwdTableName}存入成功")
case "sku_info" | "base_province" | "base_region" =>
println("修改的数据以id为合并字段,根据operate_time排序取最新的一条.若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值")
val frame = util.getSparkSession.sql(
s"""
|select
| *,
| lead(dwd_insert_time) over(partition by id order by create_time desc) lead_dwd_insert_time,
| row_number() over(partition by id order by create_time desc) row_number,
| "20230926" etl_date
|from
| ods_dwd_${odsTableName}
|""".stripMargin)
// 等于1为新增的数据
.where(col("row_number") === 1)
// 若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变
.withColumn("dwd_modify_time",when(col("lead_dwd_insert_time").isNotNull,col("lead_dwd_insert_time")).otherwise(col("dwd_insert_time")))
// 删除中间字段
.drop("lead_dwd_insert_time","row_number")
println("执行sql成功,表如下:")
frame.show(truncate = false,numRows = 20)
println("""这里有个报错:Exception in thread "main" org.apache.spark.sql.AnalysisException: Cannot overwrite table dwd.dim_user_info that is also being read from""")
println("""读写同时报错,我的解决办法是,创建临时表b,删除原表a,表b创建表a,表a删除。""")
frame.write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"dwd.${dwdTableName}_B") // 创建 B
util.getSparkSession.sql(s"drop table dwd.${dwdTableName}") // 删除 A
util.getSparkSession.sql(s"select * from dwd.${dwdTableName}_B").write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"dwd.${dwdTableName}") // 复制B创建A
util.getSparkSession.sql(s"drop table dwd.${dwdTableName}_B") // 删除 B
println(s"dwd.${dwdTableName}存入成功")
}
}
def test02(util:gs_1_util,odsTableName:String,dwdTableName:String):Unit={
println(s" ${odsTableName} 动态处理分区中 ………… ")
println("读取ods表")
util.getSparkSession.sql(s"select * from ods.${odsTableName}").createOrReplaceTempView(odsTableName)
println(s" ${odsTableName} 读取成功,表如下:")
util.getSparkSession.sql(s"select * from ${odsTableName}").show(false)
println(s" ${odsTableName} 添加列")
val frame = util.getSparkSession.sql(
s"""
|select
| *,
| 'user1' dwd_insert_user,
| cast(current_timestamp() as timestamp) as dwd_insert_time,
| 'user1' dwd_modify_user,
| cast(current_timestamp() as timestamp) as dwd_modify_time,
| date_format(create_time,"yyyyMMdd") etl_date1
|from
| ${odsTableName}
|""".stripMargin)
.drop("etl_date") //由于原来有静态分区,所以这里需要将静态分区列删除
.withColumnRenamed("etl_date1","etl_date") //这里把需要定义为动态分区的名字,重新改回来
println(s" ${odsTableName} 添加成功,表如下")
println(s" ${odsTableName} 只有order_info 表需要order_info为空的话填充create_time")
if(odsTableName.equals("order_info")){ frame.withColumn("operate_time",when(col("operate_time").isNull,col("create_time")).otherwise(col("operate_time"))) }
frame.show(false)
println(s" ${odsTableName} 存入中")
frame.write.mode("overwrite").partitionBy("etl_date").saveAsTable(s"dwd.${dwdTableName}")
println(s"dwd.${dwdTableName}存入成功")
}
def main(args: Array[String]): Unit = {
val gs_1_util = new gs_1_util
// 静态分区处理
// test01(gs_1_util,"user_info","dim_user_info")
// test01(gs_1_util,"sku_info","dim_sku_info")
// test01(gs_1_util,"base_province","dim_province")
// test01(gs_1_util,"base_region","dim_region")
// 动态分区处理
test02(gs_1_util,"order_info","fact_order_info")
test02(gs_1_util,"order_detail","order_detail")
}
}
子任务三:指标计算
编写Scala代码,使用Spark计算相关指标。
注:在指标计算中,不考虑订单信息表中order_status字段的值,将所有订单视为有效订单。计算订单金额或订单总金额时只使用final_total_amount字段。需注意dwd所有的维表取最新的分区。
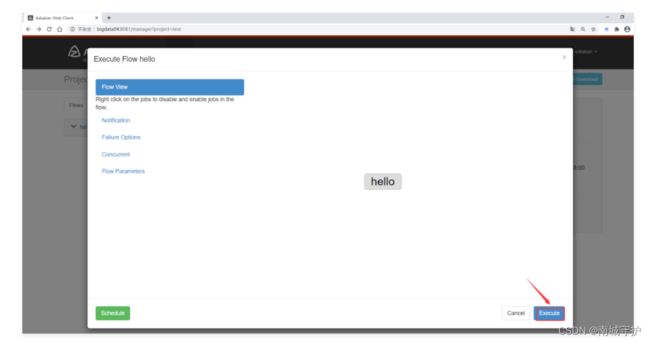
- 本任务基于以下2、3、4小题完成,使用Azkaban完成第2、3、4题任务代码的调度。工作流要求,使用shell输出“开始”作为工作流的第一个job(job1),2、3、4题任务为并行任务且它们依赖job1的完成(命名为job2、job3、job4),job2、job3、job4完成之后使用shell输出“结束”作为工作流的最后一个job(endjob),endjob依赖job2、job3、job4,并将最终任务调度完成后的工作流截图,将截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
# job1.job
type=command
command=echo "开始"# job2.job
type=command
dependencies=job1
command=spark-submit --master yarn --class gs_1.task03 /a/bigdata03.jar 1# job3.job
type=command
dependencies=job1
command=spark-submit --master yarn --class gs_1.task03 /a/bigdata03.jar 2# job4.job
type=command
dependencies=job1
command=spark-submit --master yarn --class gs_1.task03 /a/bigdata03.jar 3# endjob.job
type=commend
dependencies=job2,job3,job4
command=echo "结束"任务截图 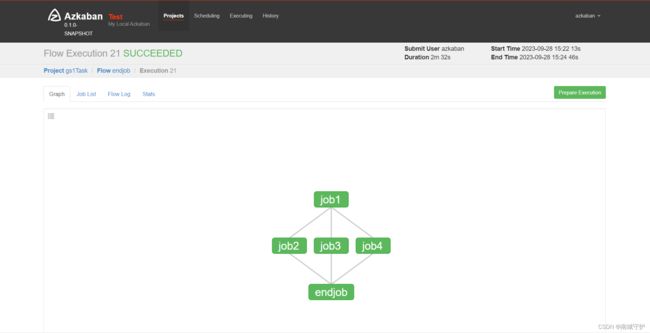
- 根据dwd层表统计每个省份、每个地区、每个月下单的数量和下单的总金额,存入MySQL数据库shtd_result的provinceeverymonth表中(表结构如下),然后在Linux的MySQL命令行中根据订单总数、订单总金额、省份表主键均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 |
类型 |
中文含义 |
备注 |
| provinceid |
int |
省份表主键 |
|
| provincename |
text |
省份名称 |
|
| regionid |
int |
地区表主键 |
|
| regionname |
text |
地区名称 |
|
| totalconsumption |
double |
订单总金额 |
当月订单总金额 |
| totalorder |
int |
订单总数 |
当月订单总数 |
| year |
int |
年 |
订单产生的年 |
| month |
int |
月 |
订单产生的月 |
- 请根据dwd层表计算出2020年4月每个省份的平均订单金额和所有省份平均订单金额相比较结果(“高/低/相同”),存入MySQL数据库shtd_result的provinceavgcmp表(表结构如下)中,然后在Linux的MySQL命令行中根据省份表主键、该省平均订单金额均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 |
类型 |
中文含义 |
备注 |
| provinceid |
int |
省份表主键 |
|
| provincename |
text |
省份名称 |
|
| provinceavgconsumption |
double |
该省平均订单金额 |
|
| allprovinceavgconsumption |
double |
所有省平均订单金额 |
|
| comparison |
text |
比较结果 |
该省平均订单金额和所有省平均订单金额比较结果,值为:高/低/相同 |
- 根据dwd层表统计在两天内连续下单并且下单金额保持增长的用户,存入MySQL数据库shtd_result的usercontinueorder表(表结构如下)中,然后在Linux的MySQL命令行中根据订单总数、订单总金额、客户主键均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 |
类型 |
中文含义 |
备注 |
| userid |
int |
客户主键 |
|
| username |
text |
客户名称 |
|
| day |
text |
日 |
记录下单日的时间,格式为 yyyyMMdd_yyyyMMdd 例如: 20220101_20220102 |
| totalconsumption |
double |
订单总金额 |
连续两天的订单总金额 |
| totalorder |
int |
订单总数 |
连续两天的订单总数 |
package gs_1
object task03 {
def test01(util:gs_1_util):Unit={
println("读取dim_province、dim_region、fact_order_info中")
util.getSparkSession.sql("""select * from dwd.dim_province""").createOrReplaceTempView("dim_province")
util.getSparkSession.sql("""select * from dwd.dim_region""").createOrReplaceTempView("dim_region")
util.getSparkSession.sql("""select * from dwd.fact_order_info""").createOrReplaceTempView("fact_order_info")
println("读取dim_province、dim_region、fact_order_info成功,表展示如下:")
util.getSparkSession.sql("select * from dim_province").show(numRows = 2,truncate = false)
util.getSparkSession.sql("select * from dim_region").show(numRows = 2,truncate = false)
util.getSparkSession.sql("select * from fact_order_info").show(numRows = 2,truncate = false)
println("指标计算第一题-----第一个sql求订单总数,订单总金额执行中-------")
val frame = util.getSparkSession.sql(
"""
|select
| b.id provinceid,
| b.name provincename,
| a.id regionid,
| a.region_name regionname,
| sum(c.final_total_amount) totalconsumption,
| count(a.id) totalorder
|from
| dim_region a
|join
| dim_province b
|on
| a.id = b.region_id
|join
| fact_order_info c
|on
| b.id = c.province_id
|group by
| b.id,b.name,a.id,a.region_name,year(c.create_time),month(c.create_time)
|""".stripMargin)
println("指标计算第一题-----第一个sql求订单总数,订单总金额执行成功---表如下:")
frame.show(false)
println("模拟在Linux的MySQL命令行中根据订单总数、订单总金额、省份表主键均为降序排序,查询出前5条")
frame.createOrReplaceTempView("provinceeverymonth")
util.getSparkSession.sql("""select * from provinceeverymonth order by totalorder desc,totalconsumption desc,provincename desc limit 5""").show()
util.writeMySql(dataFrame = frame,"provinceeverymonth","shtd_result");println("存入成功")
}
def test02(util: gs_1_util): Unit ={
println("读取dim_province、dim_region、fact_order_info中")
util.getSparkSession.sql("""select * from dwd.dim_province""").createOrReplaceTempView("dim_province")
util.getSparkSession.sql("""select * from dwd.fact_order_info""").createOrReplaceTempView("fact_order_info")
println("读取dim_province、dim_region、fact_order_info成功,表展示如下:")
util.getSparkSession.sql("select * from dim_province").show(numRows = 2,truncate = false)
util.getSparkSession.sql("select * from fact_order_info").show(numRows = 2,truncate = false)
val frame = util.getSparkSession.sql(
"""
|select
| *,
| case
| when provinceavgconsumption > allprovinceavgconsumption then '高'
| when provinceavgconsumption = allprovinceavgconsumption then '相同'
| when provinceavgconsumption < allprovinceavgconsumption then '低'
| end comparison
|from(
|select
| a.id provinceid,
| a.name provincename,
| avg(b.final_total_amount) over(partition by a.name) provinceavgconsumption,
| avg(b.final_total_amount) over() allprovinceavgconsumption
|from
| dim_province a
|join
| fact_order_info b
|on
| a.id = b.province_id
|)
|""".stripMargin)
.dropDuplicates("provinceid")
println("""模拟在Linux的MySQL命令行中根据省份表主键、该省平均订单金额均为降序排序,查询出前5条,结果如下:""")
frame.createOrReplaceTempView("provinceavgcmp")
util.getSparkSession.sql("""select * from provinceavgcmp order by provinceid desc,provinceavgconsumption desc limit 5""").show(false)
util.writeMySql(frame,"provinceavgcmp","shtd_result");println("存入成功")
}
def test03(util: gs_1_util):Unit={
util.getSparkSession.sql("""select * from dwd.dim_user_info""").createOrReplaceTempView("dim_user_info")
util.getSparkSession.sql("""select * from dwd.fact_order_info""").createOrReplaceTempView("fact_order_info")
println("""读取dim_user_info和fact_order_info表成功,结果展示如下:""")
util.getSparkSession.sql("select * from dim_user_info").show(numRows = 2,truncate = false)
util.getSparkSession.sql("select * from fact_order_info").show(numRows = 2,truncate = false)
println(
"""
|这里有三个查询,实现的功能分别为:
|第一个子查询:
| 拿出题目所需的所有字段,下一个记录的时间,一天的订单总金额,一天的订单总数
|第二个子查询:
| 拿出下一天的订单总金额,下一天的订单总数
|第三个查询
| 筛选相差一天的时间的订单,并把两天的记录的时间拼接,两天订单总金额相加,两天订单总数相加
|最后:sql 开始执行——————————
|""".stripMargin)
val frame = util.getSparkSession.sql(
"""
|select
| id userid,
| name username,
| concat(date_format(create_time,"yyyyMMdd"),"_",date_format(lead_create_time,"yyyyMMdd")) day,
| sum+lead_sum totalconsumption,
| count+lead_count totalorder
|from(
|select
| *,
| lead(sum) over(partition by id order by create_time) lead_sum,
| lead(count) over(partition by id order by create_time) lead_count
|from(
|select
| a.id,
| a.name,
| b.create_time,
| b.final_total_amount,
| lead(b.create_time) over(partition by a.id order by b.create_time) lead_create_time,
| sum(b.final_total_amount) over(partition by a.id,date_format(b.create_time,"yyyyMMdd")) sum,
| count(a.id) over(partition by a.id,date_format(b.create_time,"yyyyMMdd")) count
|from
| dim_user_info a
|join
| fact_order_info b
|on
| a.id = b.user_id))
|where
| datediff(lead_create_time,create_time) = 1
|""".stripMargin)
println("sql执行结束\n模拟在Linux的MySQL命令行中根据订单总数、订单总金额、客户主键均为降序排序,查询出前5条,结果如下:")
frame.createOrReplaceTempView("usercontinueorder")
util.getSparkSession.sql("""select * from usercontinueorder order by totalorder desc,totalconsumption desc,userid desc limit 5""").show(false)
util.writeMySql(frame,"usercontinueorder","shtd_result");println("保存成功")
}
def main(args: Array[String]): Unit = {
val gs_1_util = new gs_1_util
if(args.length == 1){
args(0) match {
case "1" => test01(gs_1_util)
case "2" => test02(gs_1_util)
case "3" => test03(gs_1_util)
case _ => println("----------------参数有误---------------")
}
}
// test01(gs_1_util)
// test02(gs_1_util)
// test03(gs_1_util)
}
}
任务B:hudi离线数据处理--电商(25分)
子任务一:数据抽取
编写Scala代码,使用Spark将MySQL的shtd_store库中表user_info、sku_info、base_province、base_region、order_info、order_detail的数据增量抽取到Hudi的ods_ds_hudi库(路径为/user/hive/warehouse/ods_ds_hudi.db)的user_info、sku_info、base_province、base_region、order_info、order_detail中。
- 抽取shtd_store库中user_info的增量数据进入Hudi的ods_ds_hudi库中表user_info。根据ods_ds_hudi.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,若operate_time为空,则用create_time填充,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中sku_info的增量数据进入Hudi的ods_ds_hudi库中表sku_info。根据ods_ds_hudi.sku_info表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.sku_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中base_province的增量数据进入Hudi的ods_ds_hudi库中表base_province。根据ods_ds_hudi.base_province表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.base_province命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中base_region的增量数据进入Hudi的ods_ds_hudi库中表base_region。根据ods_ds_hudi.base_region表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.base_region命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中order_info的增量数据进入Hudi的ods_ds_hudi库中表order_info,根据ods_ds_hudi.order_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.order_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中order_detail的增量数据进入Hudi的ods_ds_hudi库中表order_detail,根据ods_ds_hudi.order_detail表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.order_detail命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
- 配置类
-
package gs_2 import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.sql.{DataFrame, SparkSession} import java.util.Properties class gs_2_util { Logger.getLogger("org").setLevel(Level.ERROR) // 数据库连接 def getUrl(string: String):String={ s"jdbc:mysql://192.168.10.1/$string?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai" } private val prop = new Properties() prop.setProperty("user","root") prop.setProperty("password","admin") prop.setProperty("driver","com.mysql.cj.jdbc.Driver") //clickhouse连接 val clickUrl = "jdbc:clickhouse://192.168.10.100:8123/shtd_result" val clickProp = new Properties() clickProp.setProperty("user","default") clickProp.setProperty("password","123456") // clickProp.setProperty("driver","ru.yandex.clickhouse.ClickhouseDriver") def getSparkSession:SparkSession={ val conf = new SparkConf().setMaster("local").setAppName("大数据应用开发") new SparkSession.Builder().config(conf) .config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")//设置了Spark的序列化器为KryoSerializer。序列化器是指在Spark中将数据进行序列化和反序列化的机制。KryoSerializer是一种高效的序列化器,可以提供更快速的数据传输和处理。 .config("spark.sql.storeAssignmentPolicy","LEGACY")//设置了Spark SQL的存储分配策略为"LEGACY"。存储分配策略是指在Spark SQL中写入数据时,如何将数据分配到不同的分区或文件中。"LEGACY"是一种旧的策略,它按照数据的插入顺序来决定数据的分配位置,而不是根据数据的键或其他规则。 .getOrCreate() } def readMysql(tableName:String,database:String="shtd_store"):DataFrame={ println(" 读取Mysql表" + tableName) this.getSparkSession.read.jdbc(this.getUrl(database),tableName,prop) } def writeMysql(dataFrame: DataFrame,tableName:String,database:String = "shtd_store"):Unit={ println(tableName + "存入中 ……") dataFrame.write.mode("overwrite").jdbc(this.getUrl(database),tableName,prop) println(tableName + "存入成功 !!!") } def readHudi(tableName:String,database:String="ods",partition:String="/*/*"):DataFrame={ this.getSparkSession.read.format("hudi").load(this.getHuDiPath(tableName,database) + partition) } def writeHudi(df:DataFrame,tableName:String,preCombineField:String,database:String="ods",primaryKey:String="id",partition:String="etl_date"):Unit={ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ import org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs df.write.format("hudi") .options(getQuickstartWriteConfigs) .option(PRECOMBINE_FIELD.key(),preCombineField) .option(RECORDKEY_FIELD.key(),primaryKey) .option(PARTITIONPATH_FIELD.key(),partition) .option(OPERATION.key(),"insert_overwrite") .option(TBL_NAME.key(),tableName) .mode("append") .save(this.getHuDiPath(tableName,database)) } def getHuDiPath(tableName:String,database:String="ods"):String= { println("/user/hive/warehouse/"+database+"_ds_hudi.db/" + tableName) "/user/hive/warehouse/"+database+"_ds_hudi.db/" + tableName } }代码
-
package gs_2 object task01 { def test01(util:gs_2_util,tableName:String):Unit={ util.readHudi(tableName).createOrReplaceTempView("ods_"+tableName) // 模式匹配分别对不同需求的表进行操作 tableName match { case "user_info" | "order_info" => println("hudi -- " + tableName + " 开始获取operate_time/create_time 最大时间") val max_time = util.getSparkSession.sql( s""" |select | max(greatest(operate_time,create_time)) max_time |from | ods_${tableName} |""".stripMargin) .collect()(0)(0).toString println(tableName + "-hudi 最大时间为:" + max_time) util.readMysql(tableName).createOrReplaceTempView("shtd_store_"+tableName) println("shtd_store -- " + tableName + " operate_time或create_time作为增量字段") val df = util.getSparkSession.sql( s""" |select | *, | "20231026" etl_date |from | shtd_store_${tableName} |where | create_time > "${max_time}" |or | operate_time > "${max_time}" |""".stripMargin) util.writeHudi(df,tableName,"operate_time") case "sku_info" | "order_detail" => println("hudi -- " + tableName + " 开始获取create_time 最大时间") val max_time = util.getSparkSession.sql( s""" |select | max(create_time) max_time |from | ods_${tableName} |""".stripMargin) .collect()(0)(0).toString println(tableName + "-hudi 最大时间为:" + max_time) util.readMysql(tableName).createOrReplaceTempView("shtd_store_"+tableName) println("shtd_store -- " + tableName + " create_time作为增量字段") val df = util.getSparkSession.sql( s""" |select | *, | "20231026" etl_date |from | shtd_store_${tableName} |where | create_time > "${max_time}" |""".stripMargin) if(tableName.equals("order_detail")){ util.writeHudi(df,tableName,"create_time") }else{ util.writeHudi(df,tableName,"operate_time") } case "base_province" | "base_region" => println("hudi -- " + tableName + " 开始获取最大 id") val max_id = util.getSparkSession.sql( s""" |select | max(id) max_time |from | ods_${tableName} |""".stripMargin) .collect()(0)(0).toString println("hudi -- " + tableName + " 最大 id 为:" + max_id) util.readMysql(tableName).createOrReplaceTempView("shtd_store_"+tableName) println("shtd_store -- " + tableName + " id作为增量字段") val df = util.getSparkSession.sql( s""" |select | *, | current_timestamp() create_time, | "20231026" etl_date |from | shtd_store_${tableName} |where | id > "${max_id}" |""".stripMargin) util.writeHudi(df,tableName,"create_time") case _ => println(tableName + " 表不存在,请检查表名是否错误!!!") } } def main(args: Array[String]): Unit = { val gs_2_util = new gs_2_util // test01(gs_2_util,"user_info") // test01(gs_2_util,"sku_info") // test01(gs_2_util,"base_province") // test01(gs_2_util,"base_region") // test01(gs_2_util,"order_info") // test01(gs_2_util,"order_detail") gs_2_util.getSparkSession.stop() } }子任务二:数据清洗
编写Scala代码,使用Spark将ods库中相应表数据全量抽取到Hudi的dwd_ds_hudi库(路径为路径为/user/hive/warehouse/dwd_ds_hudi.db)中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
- 抽取ods_ds_hudi库中user_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_user_info最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_user_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据operate_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条记录第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均存当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions dwd_ds_hudi.dim_user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods_ds_hudi库sku_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_sku_info最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_sku_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell查询表dim_sku_info的字段id、sku_desc、dwd_insert_user、dwd_modify_time、etl_date,条件为最新分区的数据,id大于等于15且小于等于20,并且按照id升序排序,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods_ds_hudi库base_province表中昨天的分区(子任务一生成的分区)数据,并结合dim_province最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_province的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_province最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods_ds_hudi库base_region表中昨天的分区(子任务一生成的分区)数据,并结合dim_region最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_region的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_region最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 将ods_ds_hudi库中order_info表昨天的分区(子任务一生成的分区)数据抽取到dwd_ds_hudi库中fact_order_info的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,同时若operate_time为空,则用create_time填充,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions dwd.fact_order_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 将ods_ds_hudi库中order_detail表昨天的分区(子任务一中生成的分区)数据抽取到dwd_ds_hudi库中fact_order_detail的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell执行show partitions dwd_ds_hudi.fact_order_detail命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
package gs_2
import org.apache.spark.sql.functions.{col, current_timestamp, date_format, lit, when}
import org.apache.spark.sql.types.DecimalType
object task02 {
def test01(gs_2_util:gs_2.gs_2_util,ods_tableName:String,dwd_tableName:String):Unit={
var partition = ""
var dwd_etl_date = ""
var preCombineField = ""
// 对每个表定制化操作
ods_tableName match {
case "user_info" =>
partition = "operate_time"
dwd_etl_date = "20220719"
preCombineField = "operate_time"
case "sku_info" =>
partition = "create_time"
dwd_etl_date = "20220719"
preCombineField = "dwd_modify_time"
case "base_province" | "base_region" =>
partition = "create_time"
dwd_etl_date = "19971201"
preCombineField = "dwd_modify_time"
case _ => println("!!!表不存在!!!")
}
val ods_frame = gs_2_util.readHudi(ods_tableName)
.where(col("etl_date") === "20231026")
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",current_timestamp().cast("timestamp"))
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",current_timestamp().cast("timestamp"))
.drop("etl_date")
val dwd_frame = gs_2_util.readHudi(dwd_tableName,"dwd")
.where(col("etl_date") === dwd_etl_date)
.drop("etl_date")
ods_frame.union(dwd_frame).createOrReplaceTempView(ods_tableName+"__UNIO__"+dwd_tableName)
val frame = gs_2_util.getSparkSession.sql(
s"""
|select
| *,
| lead(dwd_insert_time) over(partition by id order by ${partition} desc) lead_dwd_insert_time,
| row_number() over(partition by id order by ${partition} desc) row_number,
| "20231026" etl_date
|from
| ${ods_tableName}__UNIO__${dwd_tableName}
|""".stripMargin)
.withColumn("dwd_insert_time",when(col("lead_dwd_insert_time").isNull,col("dwd_insert_time")).otherwise("lead_dwd_insert_time"))
.where(col("row_number") === 1)
.drop("lead_dwd_insert_time","row_number")
gs_2_util.writeHudi(frame,dwd_tableName,preCombineField,"dwd")
}
def test02(gs_2_util:gs_2.gs_2_util,ods_tableName:String,dwd_tableName:String):Unit={
gs_2_util.readHudi(ods_tableName).createOrReplaceTempView(ods_tableName)
var frame = gs_2_util.getSparkSession.sql(
s"""
|select
| *,
| "user1" dwd_insert_user,
| cast(current_timestamp() as timestamp) dwd_insert_time,
| "user1" dwd_modify_user,
| cast(current_timestamp() as timestamp) dwd_modify_time
|from
| ${ods_tableName}
|where
| etl_date = "20231026"
|""".stripMargin)
ods_tableName match {
case "order_info" =>
frame = frame.withColumn("operate_time",when(col("operate_time").isNull,col("create_time")).otherwise("operate_time"))
.withColumn("etl_date",date_format(col("create_time"),"yyyyMMdd"))
gs_2_util.writeHudi(frame,dwd_tableName,"operate_time","dwd")
case "order_detail" =>
frame = frame.withColumn("etl_date",date_format(col("create_time"),"yyyyMMdd"))
gs_2_util.writeHudi(frame,dwd_tableName,"dwd_modify_time","dwd")
}
}
def main(args: Array[String]): Unit = {
val gs_2_util = new gs_2_util
// test01(gs_2_util,"user_info","dim_user_info")
// test01(gs_2_util,"sku_info","dim_sku_info")
// test01(gs_2_util,"base_province","dim_province")
// test01(gs_2_util,"base_region","dim_region")
// test02(gs_2_util,"order_info","fact_order_info")
test02(gs_2_util,"order_detail","fact_order_detail")
gs_2_util.getSparkSession.stop()
}
}
子任务三:指标计算
编写Scala代码,使用Spark计算相关指标。
注:在指标计算中,不考虑订单信息表中order_status字段的值,将所有订单视为有效订单。计算订单金额或订单总金额时只使用final_total_amount字段。需注意dwd所有的维表取最新的分区。
- 本任务基于以下2、3、4小题完成,使用Azkaban完成第2、3、4题任务代码的调度。工作流要求,使用shell输出“开始”作为工作流的第一个job(job1),2、3、4题任务为并行任务且它们依赖job1的完成(命名为job2、job3、job4),job2、job3、job4完成之后使用shell输出“结束”作为工作流的最后一个job(endjob),endjob依赖job2、job3、job4,并将最终任务调度完成后的工作流截图,将截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 根据dwd层表统计每人每天下单的数量和下单的总金额,存入Hudi的dws_ds_hudi层的user_consumption_day_aggr表中(表结构如下),然后使用spark -shell按照客户主键、订单总金额均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 |
类型 |
中文含义 |
备注 |
| uuid |
string |
随机字符 |
随机字符,保证不同即可,作为primaryKey |
| user_id |
int |
客户主键 |
|
| user_name |
string |
客户名称 |
|
| total_amount |
double |
订单总金额 |
当天订单总金额。 |
| total_count |
int |
订单总数 |
当天订单总数。同时可作为preCombineField(作为合并字段时,无意义,因为主键为随机生成) |
| year |
int |
年 |
订单产生的年,为动态分区字段 |
| month |
int |
月 |
订单产生的月,为动态分区字段 |
| day |
int |
日 |
订单产生的日,为动态分区字段 |
- 根据dwd_ds_hudi库中的表统计每个省每月下单的数量和下单的总金额,并按照year,month,region_id进行分组,按照total_amount逆序排序,形成sequence值,将计算结果存入Hudi的dws_ds_hudi数据库province_consumption_day_aggr表中(表结构如下),然后使用spark-shell根据订单总数、订单总金额、省份表主键均为降序排序,查询出前5条,在查询时对于订单总金额字段将其转为bigint类型(避免用科学计数法展示),将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 |
类型 |
中文含义 |
备注 |
| uuid |
string |
随机字符 |
随机字符,保证不同即可,作为primaryKey |
| province_id |
int |
省份表主键 |
|
| province_name |
string |
省份名称 |
|
| region_id |
int |
地区主键 |
|
| region_name |
string |
地区名称 |
|
| total_amount |
double |
订单总金额 |
当月订单总金额 |
| total_count |
int |
订单总数 |
当月订单总数。同时可作为preCombineField(作为合并字段时,无意义,因为主键为随机生成) |
| sequence |
int |
次序 |
|
| year |
int |
年 |
订单产生的年,为动态分区字段 |
| month |
int |
月 |
订单产生的月,为动态分区字段 |
- 请根据dws_ds_hudi库中的表计算出每个省份2020年4月的平均订单金额和该省所在地区平均订单金额相比较结果(“高/低/相同”),存入ClickHouse数据库shtd_result的provinceavgcmpregion表中(表结构如下),然后在Linux的ClickHouse命令行中根据省份表主键、省平均订单金额、地区平均订单金额均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
| 字段 |
类型 |
中文含义 |
备注 |
| provinceid |
int |
省份表主键 |
|
| provincename |
text |
省份名称 |
|
| provinceavgconsumption |
double |
该省平均订单金额 |
|
| regionid |
int |
地区表主键 |
|
| regionname |
text |
地区名称 |
|
| regionavgconsumption |
double |
地区平均订单金额 |
该省所在地区平均订单金额 |
| comparison |
text |
比较结果 |
省平均订单金额和该省所在地区平均订单金额比较结果,值为:高/低/相同 |
-
package gs_2 object task03 { def test01(gs_2_util:gs_2.gs_2_util):Unit={ gs_2_util.readHudi("dim_user_info","dwd").createOrReplaceTempView("dim_user_info") gs_2_util.readHudi("fact_order_info","dwd").createOrReplaceTempView("fact_order_info") gs_2_util.getSparkSession.sql( """ |select | a.id user_id, | a.name user_name, | sum(b.final_total_amount) total_amount, | count(a.id) total_count, | year(b.create_time) year, | month(b.create_time) month, | day(b.create_time) day |from | dim_user_info a |join | fact_order_info b |on | a.id = b.user_id |group by | a.id, | a.name, | year(b.create_time), | month(b.create_time), | day(b.create_time) |""".stripMargin) .createOrReplaceTempView("t1") val frame = gs_2_util.getSparkSession.sql("""select uuid() uuid,*,concat(year,'/',month,'/',day) etl_date from t1""") gs_2_util.writeHudi(frame,"user_consumption_day_aggr","total_count","dws","uuid") } def test02(gs_2_util: gs_2_util): Unit = { gs_2_util.readHudi("dim_province","dwd").createOrReplaceTempView("dim_province") gs_2_util.readHudi("fact_order_info","dwd").createOrReplaceTempView("fact_order_info") gs_2_util.readHudi("dim_region","dwd").createOrReplaceTempView("dim_region") gs_2_util.getSparkSession.sql( """ |select | a.id province_id, | a.name province_name, | b.id region_id, | b.region_name region_name, | sum(c.final_total_amount) total_amount, | count(a.id) total_count, | year(c.create_time) year, | month(c.create_time) month |from | dim_province a |join | dim_region b |on | a.region_id = b.id |join | fact_order_info c |on | c.province_id = a.id |group by | b.id, | b.region_name, | a.id, | a.name, | year(c.create_time), | month(c.create_time) |""".stripMargin) .createOrReplaceTempView("t1") gs_2_util.getSparkSession.sql( """ |select | uuid() uuid, | province_id, | province_name, | region_id, | region_name, | total_amount, | total_count, | row_number() over(order by year,month,region_id) sequence, | year, | month |from | t1 |""".stripMargin) .show() } def test03(gs_2_util:gs_2.gs_2_util):Unit={ gs_2_util.readHudi("dim_province","dwd").createOrReplaceTempView("dim_province") gs_2_util.readHudi("fact_order_info","dwd").createOrReplaceTempView("fact_order_info") gs_2_util.readHudi("dim_region","dwd").createOrReplaceTempView("dim_region") gs_2_util.getSparkSession.sql( """ |select | distinct(provinceid), | provincename, | provinceavgconsumption, | regionid, | regionname, | regionavgconsumption, | case | when provinceavgconsumption > regionavgconsumption then '高' | when provinceavgconsumption = regionavgconsumption then '相同' | when provinceavgconsumption < regionavgconsumption then '低' | end comparison |from( |select | a.id provinceid, | a.name provincename, | avg(c.final_total_amount) over(partition by a.id) provinceavgconsumption, | b.id regionid, | b.region_name regionname, | avg(c.final_total_amount) over(partition by b.id) regionavgconsumption |from | dim_province a |join | dim_region b |on | a.region_id = b.id |join | fact_order_info c |on | a.id = c.province_id |where | year(c.create_time) = "2020" and month(c.create_time) = "4" |) |""".stripMargin) .write.mode("append").jdbc(gs_2_util.clickUrl,"cs",gs_2_util.clickProp) /* create table cs( provinceid Int, provincename String, provinceavgconsumption Float64, regionid Int, regionname String, regionavgconsumption Float64, comparison String ) ENGINE=MergeTree() ORDER BY (provinceid); */ } def main(args: Array[String]): Unit = { val gs_2_util = new gs_2_util // test01(gs_2_util) // test02(gs_2_util) test03(gs_2_util) } }
- 根据dwd层表来计算每个地区2020年订单金额前3省份,依次存入MySQL数据库shtd_result的regiontopthree表中(表结构如下),然后在Linux的MySQL命令行中根据地区表主键升序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
-
字段
类型
中文含义
备注
regionid
int
地区表主键
regionname
text
地区名称
provinceids
text
省份表主键
用,分割显示前三省份的id
provincenames
text
省份名称
用,分割显示前三省份的name
provinceamount
text
省份名称
用,分割显示前三省份的订单金额(需要去除小数部分,使用四舍五入)
例如:
3
华东地区
21,27,11
上海市,江苏省,浙江省
100000,100,10
def test04(gs_2_util: gs_2_util): Unit = {
gs_2_util.readHudi("dim_province","dwd").createOrReplaceTempView("dim_province")
gs_2_util.readHudi("fact_order_info","dwd").createOrReplaceTempView("fact_order_info")
gs_2_util.readHudi("dim_region","dwd").createOrReplaceTempView("dim_region")
gs_2_util.getSparkSession.sql(
"""
|select
| regionid,
| regionname,
| concat(provinceids,",",provinceids_1,",",provinceids_2) provinceids,
| concat(provincenames,",",provincenames_1,",",provincenames_2) provincenames,
| concat(sum,",",sum_1,",",sum_2) provinceamount
|from(
|select
| regionid,
| regionname,
| provinceids,
| provincenames,
| sum,
| lead(provinceids) over(partition by regionid order by sum desc) provinceids_1,
| lead(provinceids,2) over(partition by regionid order by sum desc) provinceids_2,
| lead(provincenames,1) over(partition by regionid order by sum desc) provincenames_1,
| lead(provincenames,2) over(partition by regionid order by sum desc) provincenames_2,
| lead(sum,1) over(partition by regionid order by sum desc) sum_1,
| lead(sum,2) over(partition by regionid order by sum desc) sum_2,
| row_number() over(partition by regionid order by sum desc) row_number
|from(
|select
| b.id regionid,
| b.region_name regionname,
| a.id provinceids,
| a.name provincenames,
| sum(c.final_total_amount) sum
|from
| dim_province a
|join
| dim_region b
|on
| a.region_id = b.id
|join
| fact_order_info c
|on
| c.province_id = a.id
|group by
| b.id,
| b.region_name,
| a.id,
| a.name
|)
|)
|where
| row_number = 1
|""".stripMargin)
.show(10000,false)
}
任务B:hudi离线数据处理--工业(25分)
子任务一:数据抽取
编写Scala代码,使用Spark将MySQL库中表ChangeRecord,BaseMachine,MachineData, ProduceRecord全量抽取到Hudi的hudi_gy_ods库(路径为/user/hive/warehouse/hudi_gy_ods.db)中对应表changerecord,basemachine, machinedata,producerecord中。
- 抽取MySQL的shtd_industry库中ChangeRecord表的全量数据进入Hudi的hudi_gy_ods库中表changerecord,字段排序、类型不变,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。PRECOMBINE_FIELD使用ChangeEndTime,ChangeID和ChangeMachineID作为联合主键。使用spark-sql的cli执行select count(*) from hudi_gy_ods.changerecord命令,将spark-sql的cli执行结果分别截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中BaseMachine表的全量数据进入Hudi的hudi_gy_ods库中表basemachine,字段排序、类型不变,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。PRECOMBINE_FIELD使用MachineAddDate,BaseMachineID为主键。使用spark-sql的cli执行show partitions hudi_gy_ods.basemachine命令,将cli的执行结果分别截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中ProduceRecord表的全量数据进入Hudi的hudi_gy_ods库中表producerecord,剔除ProducePrgCode字段,其余字段排序、类型不变,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。PRECOMBINE_FIELD使用ProduceCodeEndTime,ProduceRecordID和ProduceMachineID为联合主键。使用spark-sql的cli执行show partitions hudi_gy_ods.producerecord命令,将spark-sql的cli的执行结果分别截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取MySQL的shtd_industry库中MachineData表的全量数据进入Hudi的hudi_gy_ods库中表machinedata,字段排序、类型不变,分区字段为etldate,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。PRECOMBINE_FIELD使用MachineRecordDate,MachineRecordID为主键。使用spark-sql的cli执行show partitions hudi_gy_ods.machinedata命令,将cli的执行结果分别截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
任务C:数据挖掘(10分)
子任务一:特征工程
剔除订单信息表与订单详细信息表中用户id与商品id不存在现有的维表中的记录,同时建议多利用缓存并充分考虑并行度来优化代码,达到更快的计算效果。
- 根据Hive的dwd库中相关表或MySQL中shtd_store中相关表(order_detail、sku_info),计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户(只考虑他俩购买过多少种相同的商品,不考虑相同的商品买了多少次),将10位用户id进行输出,输出格式如下,将结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下;结果格式如下:
-------------------相同种类前10的id结果展示为:--------------------
1,2,901,4,5,21,32,91,14,52
- 根据Hive的dwd库中相关表或MySQL中shtd_store中相关商品表(sku_info),获取id、spu_id、price、weight、tm_id、category3_id 这六个字段并进行数据预处理,对price、weight进行规范化(StandardScaler)处理,对spu_id、tm_id、category3_id进行one-hot编码处理(若该商品属于该品牌则置为1,否则置为0),并按照id进行升序排序,在集群中输出第一条数据前10列(无需展示字段名),将结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下。
| 字段 |
类型 |
中文含义 |
备注 |
| id |
double |
主键 |
|
| price |
double |
价格 |
|
| weight |
double |
重量 |
|
| spu_id#1 |
double |
spu_id 1 |
若属于该spu_id,则内容为1否则为0 |
| spu_id#2 |
double |
spu_id 2 |
若属于该spu_id,则内容为1否则为0 |
| ..... |
double |
|
|
| tm_id#1 |
double |
品牌1 |
若属于该品牌,则内容为1否则为0 |
| tm_id#2 |
double |
品牌2 |
若属于该品牌,则内容为1否则为0 |
| …… |
double |
|
|
| category3_id#1 |
double |
分类级别3 1 |
若属于该分类级别3,则内容为1否则为0 |
| category3_id#2 |
double |
分类级别3 2 |
若属于该分类级别3,则内容为1否则为0 |
| …… |
|
|
|
结果格式如下:
--------------------第一条数据前10列结果展示为:---------------------
1.0,0.892346,1.72568,0.0,0.0,0.0,0.0,1.0,0.0,0.0
子任务二:推荐系统
- 根据子任务一的结果,计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户id(只考虑他俩购买过多少种相同的商品,不考虑相同的商品买了多少次),并根据Hive的dwd库中相关表或MySQL数据库shtd_store中相关表,获取到这10位用户已购买过的商品,并剔除用户6708已购买的商品,通过计算这10位用户已购买的商品(剔除用户6708已购买的商品)与用户6708已购买的商品数据集中商品的余弦相似度累加再求均值,输出均值前5商品id作为推荐使用 ,将执行结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下。
结果格式如下:
------------------------推荐Top5结果如下------------------------
相似度top1(商品id:1,平均相似度:0.983456)
相似度top2(商品id:71,平均相似度:0.782672)
相似度top3(商品id:22,平均相似度:0.7635246)
相似度top4(商品id:351,平均相似度:0.7335748)
相似度top5(商品id:14,平均相似度:0.522356)
package gs_1
import org.apache.spark.SparkConf
import org.apache.spark.ml.feature.{OneHotEncoder, StandardScaler, StringIndexer, VectorAssembler}
import org.apache.spark.ml.linalg.{BLAS, Vector, Vectors}
import org.apache.spark.ml.{Pipeline, PipelineStage}
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry}
import org.apache.spark.sql.{DataFrame, Row}
object task04 {
def test01(util: gs_1_util):String={
util.readMysql("order_detail").createOrReplaceTempView("detail_table")
util.readMysql("order_info").createOrReplaceTempView("info_table")
util.readMysql("sku_info").createOrReplaceTempView("sku_table")
util.readMysql("user_info").createOrReplaceTempView("user_table")
val spark = util.getSparkSession
//用户id 商品id
spark.sql(
"""
|select
|distinct
|i.user_id,
|d.sku_id
|from
|info_table i
|join detail_table d on i.id = d.order_id
|join sku_table s on d.sku_id = s.id
|join user_table u on i.user_id = u.id
|""".stripMargin)
.createTempView("t1")
//6708购买的商品
spark.sql(
"""
|select
|sku_id
|from t1
|where user_id = 6708
|""".stripMargin)
.createTempView("t2")
val sku_rdd = spark.sql(
"""
|select
|t1.user_id,
|count(*) rk
|from
|t1
|join t2 on t1.sku_id = t2.sku_id
|where t1.user_id != 6708
|group by t1.user_id
|order by rk desc
|limit 10
|""".stripMargin)
val str = sku_rdd.rdd.collect().map(_.getLong(0)).mkString(",")
println(str)
val row = util.getSparkSession.sql("""select * from t2""").collect().map(_ (0).toString()).mkString(",")
row
}
def cosineSimilarity(vec1: Vector, vec2: Vector): Double = {
val dotProduct = vec1.dot(vec2)
val norm1 = Vectors.norm(vec1,2)
val norm2 = Vectors.norm(vec2,2)
dotProduct / (norm1 * norm2)
}
// 计算两组用户特征的平均余弦相似度,并输出结果
def calculateAndPrintTop5(
userFeatures1: Array[(Long, Vector)],
userFeatures2: Array[(Long, Vector)]
): Unit = {
val similarities = for {
(userId1, vector1) <- userFeatures1
(userId2, vector2) <- userFeatures2
} yield (userId1, userId2, cosineSimilarity(vector1, vector2))
val top5Similarities = similarities
.groupBy(_._1)
.mapValues(_.sortBy(-_._3).take(5))
.toList
.sortBy(_._2.head._3)(Ordering[Double].reverse)
.take(5)
println("------------------------推荐Top5结果如下------------------------")
top5Similarities.zipWithIndex.foreach {
case ((userId1, userId2Similarities), index) =>
val avgSimilarity = userId2Similarities.map(_._3).sum / userId2Similarities.length.toDouble
val topSimilarity = userId2Similarities.head
println(
s"相似度top${index + 1}(商品id:${topSimilarity._2},平均相似度:$avgSimilarity)"
)
}
}
def test02(util: gs_1_util):DataFrame={
util.readMysql("sku_info").createOrReplaceTempView("sku_info")
val frame = util.getSparkSession.sql("""select distinct id,spu_id,price,weight,tm_id,category3_id from sku_info order by id""")
val columns = Array("spu_id","tm_id","category3_id")
println(
"""进行---------------------------------------------------------------------
|StringIndexer 编码:
| columns 是一个包含列名的集合
| map 对columns中的每个列名执行相同的操作
| setInputCol 设置输入列,也就是要编码的列名,‘colName’是当前循环的列名
| setOutputCol 设置输出列,也就是存储编码结果的列名,这里是在输入列名的基础上加上‘_indexed’后缀
| setHandleInvalid("keep") 设置处理无效值的策略为”keep“,这表示如果遇到未知的类别值,讲保留原始值而不引发错误
| indexers 是一个包含了创建的‘StringIndexer’对象的集合,每个对象对应一个列的处理
| 例如,如果你有一个包含 "red"、"blue" 和 "green" 的颜色列,经过此处理后,它们将被编码为整数,如 0、1 和 2,以便输入到机器学习算法中。
|""".stripMargin)
val indexers = columns.map { colName =>
new StringIndexer().setInputCol(colName).setOutputCol(colName + "_indexed").setHandleInvalid("keep")
}
println(
"""
|进行--------------------------------------------------------------------
|one-hot 编码
| setInputCols 设置输入列,用来进行独热编码
| setOutputCols 设置输出列
|编码后的样子:(13,[2],[1.0])
| 13 一共13个变量
| 2 非0元素的索引值
| 1.0 只有一个非0元素的值,为1.0
|""".stripMargin)
// onehot处理
val onehoter = new OneHotEncoder()
.setInputCols(columns.map(_ + "_indexed"))
.setOutputCols(columns.map(_ + "_onehot"))
println(
"""
|进行----------------------------------------------------------------------
|特征向量组装器(VectorAssembler)
| featureCol 是一个包含特征列名称的数组,其中包括 "price" 和 "weight" 列。这些列包含了你希望合并为一个特征向量的特征。
| VectorAssembler 用于将多个特征列合并成一个特征向量列
| setInputCols(featureCol) 设置了输入列,告诉 VectorAssembler 需要合并哪些列。在这里,它会合并 "price" 和 "weight" 列。
| setOutputCol("scaledFeatures") 设置了输出列的名称,这是合并后的特征向量列的名称。在这里,合并后的特征向量将被存储在一个名为 "scaledFeatures" 的新列中。
|例如:
| +-----+-------+----------------+
| |price|weight | scaledFeatures |
| +-----+-------+----------------+
| | 10.0| 2.1 | [10.0, 2.1] |
| | 15.0| 3.3 | [15.0, 3.3] |
| | 20.0| 2.7 | [20.0, 2.7] |
| | 12.0| 2.9 | [12.0, 2.9] |
| +-----+-------+----------------+
|""".stripMargin)
// StandardScaler处理
var featureCol = Array("price","weight")
val assemble = new VectorAssembler()
.setInputCols(featureCol)
.setOutputCol("scaledFeatures")
println(
"""
|进行---------------------------------------------------------------
|标准化(StandardScaler)
| setInputCol 设置输入列
| setOutputCol 设置输出列
| setWithStd 设置标准差(标准差为true),表示要在标准化过程中考虑特征的标准差。标准差是一个衡量数据分散程度的指标,标准化会将特征缩放到具有单位标准差。
| setWithMean 设置均值(均值标志为false),表示在标准化过程中不考虑特征的均值,如果设置为true,则会将特征缩放到具有零均值
|这段代码的目的是使用 StandardScaler 对 "scaledFeatures" 列进行标准化处理,使其具有单位标准差,同时不进行均值的调整。标准化是一种数据预处理技术,有助于确保不同尺度的特征对机器学习模型的影响是一致的,从而提高模型的性能。标准化后的结果将存储在新的列 "scaledFeatures_result" 中。
|处理结果展示:
| scaledFeatures|scaledFeatures_result
| [2220.0,0.24] |[0.759105832811737,0.15528316608735387]
| [3321.0,15.24]|[1.135581293138639,9.86048104654697]
| [3100.0,15.24]|[1.060012649421795,9.86048104654697]
|""".stripMargin)
val scaler = new StandardScaler()
.setInputCol("scaledFeatures")
.setOutputCol("scaledFeatures_result")
.setWithStd(true)
.setWithMean(false)
println(
"""
|进行------------------------------------------------------------------------
|VectorAssembler(组合列)
|结果:(42,[0,1,2,5,18,36],[1.0,0.759105832811737,0.15528316608735387,1.0,1.0,1.0])
| 42 这是整个稀疏向量的长度,表示有42个位置(或特征)。
| [0, 1, 2, 5, 18, 36] 这是一个包含非零值的位置索引数组。它告诉我们在稀疏向量中的哪些位置有非零值。在这个例子中,分别有非零值的位置是 0、1、2、5、18 和 36。
| [1.0, 0.759105832811737, 0.15528316608735387, 1.0, 1.0, 1.0] 这是与上述位置索引数组中相应位置对应的值数组。它告诉我们每个非零位置的值。例如,位置0的值是1.0,位置1的值是0.759105832811737,以此类推。
|我们可以通过下标来取出这42个值
|""".stripMargin)
// 输出到一列
featureCol = Array("id","scaledFeatures_result")++columns.map(x => x + "_onehot")
val assemble1 = new VectorAssembler()
.setInputCols(featureCol)
.setOutputCol("features")
val pipeline_frame = new Pipeline().setStages(indexers++Array(onehoter,assemble,scaler,assemble1)).fit(frame).transform(frame)
val spark = util.getSparkSession
println("""导入隐式转换""")
import spark.implicits._
println(
"""
|进行-----------------------------------------------------------------------------------------------
|输出一行十列
| asInstanceOf 强制类型转换为向量
| map1 遍历每一行
| x 由于是row类型的,所以强制转换为向量
| toArray 转换为数组,数组包含了一行的元素
| map2 遍历每一行
| take(10) 取出每一行前十列
| mkString 将每一行前十列拼接成一个字符串
| rdd 转成一个rdd
| collect()(0) 将数据返回到客户端,拿出第一行
| println 打印
|""".stripMargin)
println(pipeline_frame.select("features").map(x => x(0).asInstanceOf[Vector].toArray).map(_.take(10).mkString(",")).rdd.collect()(0))
pipeline_frame
}
def test03(gs_1_util: gs_1_util,frame:DataFrame,string: String): Unit = {
val spark = gs_1_util.getSparkSession
import spark.implicits._
frame.select("id", "features").createOrReplaceTempView("t1")
//由于6708用户购买商品很少,所以模拟7条数据
val string1 = string + ",1,2,3,4,5,6,7"
val user6708Features = gs_1_util.getSparkSession.sql(s"""select * from t1 where id in (${string1})""").map {
case Row(id: Long, vector: Vector) => (id, vector)
}.collect()
val otherUserFeatures = gs_1_util.getSparkSession.sql(s"""select * from t1 where id not in (${string1})""").map {
case Row(id: Long, vector: Vector) => (id, vector)
}.collect()
calculateAndPrintTop5(user6708Features, otherUserFeatures)
}
def main(args: Array[String]): Unit = {
val gs_1_util = new gs_1_util
// test01(gs_1_util)
// test02(gs_1_util)
test03(gs_1_util,test02(gs_1_util),test01(gs_1_util))
}
}