Python读取O文件以及N文件
Python读取O文件以及N文件
在学校的卫星定位实习中了解到了,O文件以及N文件格式y读取,记录下学习。(文章中使用的数据以及代码为华测接收机获取的,不支持中海达数据格式,但读取的文件差不多)
O文件解读(使用为华测接收机的数据文件)
解析部分
文件内容如图所示是文件的头~~(这里是用pycharm直接打开读取的)~~
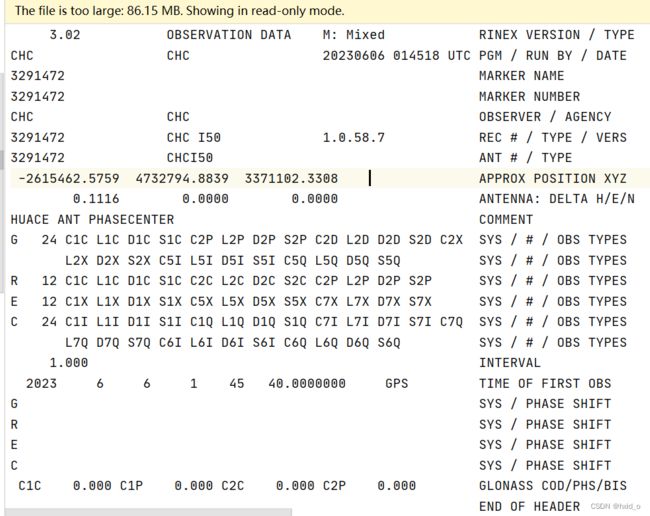
文件后续格式
这里的信息有助于我们理解每一个卫星的数据
G 24 C1C L1C D1C S1C C2P L2P D2P S2P C2D L2D D2D S2D C2X SYS / # / OBS TYPES
L2X D2X S2X C5I L5I D5I S5I C5Q L5Q D5Q S5Q SYS / # / OBS TYPES
R 12 C1C L1C D1C S1C C2C L2C D2C S2C C2P L2P D2P S2P SYS / # / OBS TYPES
E 12 C1X L1X D1X S1X C5X L5X D5X S5X C7X L7X D7X S7X SYS / # / OBS TYPES
C 24 C1I L1I D1I S1I C1Q L1Q D1Q S1Q C7I L7I D7I S7I C7Q SYS / # / OBS TYPES
L7Q D7Q S7Q C6I L6I D6I S6I C6Q L6Q D6Q S6Q SYS / # / OBS TYPES
# G --- GPS R --- GLONASS E --- Galileo C --- 北斗
# 重点使用的数据为 C1C --- 伪距 L1C ---载波
接下来是卫星的数据格式,接收机是以秒的单位来接受卫星,当然也会存在卫星数据错误和中断的情况,这些在读取文件时都需要考虑进去。如图这是接收机在这一秒内接收到的部分卫星数据,直到下一秒数据更新

根据以上条件,我们需要过滤文件头,可以以时间轴为键,保存每一个卫星编号的数据,来方便我们后续的使用。
Python代码以及相关注释(适用于大部分O文件数据)
# 编写的O文件读取函数,输入O文件路径,返回一个以时间为键的 字典变量
def read_O(path):
with open(path,"r") as f:
# 读取O文件,空格分割,取时间为间隔为键 后读取卫星数据
items = {}
temp = f.readlines()
for x in temp:
xl = x.split()
if len(xl) == 9:
date = ""
for i in range(len(xl)-1):
date += xl[i]+" "
date.replace("\n","")
#print(x)
items[date] = {}
if len(xl) == 25:
#(xl[0],xl[1]) 可能卫星数据会出现 接受到卫星,但是数据都是0的情况 需要将其过滤
if float(xl[1]) == 0:
pass
#print(date, xl[0], "卫星数据出错")
# 存在伪距为真,但载波为0的情况
if float(xl[2]) == 0:
pass
#print(date,xl[0], "载波错误")
else:
items[date][xl[0]] = []
items[date][xl[0]].extend(xl)
items.pop(list(items.keys())[0])
# print(items)
return items
结果展示
以下是用软件调试,查看的变量格式(总体)和秒内的数据


N文件解读
解析部分
和O文件的解读一样,这里先看文件头,但是这里的信息不多不能用于解析,到时候读取的时候直接过滤即可
接收机获取的文件头,是有缺陷的如果需要电离层参数,可以去武汉大学IGS数据中心下载广播星历,其中含有电离层参数。武汉大学IGS数据中心

N文件中保存是广播星历数据,每两个小时更新一次卫星的广播星历。如图所示,这里的数据我们在计算卫星坐标的时候都要用到,这里的D表示的就是10 即 6D+01 就是 6 * 10 ^ 1。具体每一个数据的含义可以参考((115条消息) RINEX广播星历文件读取(N文件)_是王久久阿的博客-CSDN博客)。

Python代码以及相关注释
# 因为文件格式后续都是一样的,因此再过滤到头部的不需要信息,后续我们直接文件,然后分割
# 分割的结果,如果有列表长度为10 代码有卫星编号 否则就是其他数据。因此处理如下
def read_22N(path):
items = {}
# 读取N文件 ,先过滤前4行 再读取所有行 迭代行,通过空格分割 当 10 确定键
id = ""
with open(path,"r") as f:
for i in range(4):
f.readline()
temp = f.readlines()
for x in temp:
xl = x.split()
if len(xl) == 10:
id = xl[0]
items[id] = []
items[id].extend(xl)
else:
items[id].extend(xl)
#print(temp)
return items
# 每个数据含义
Ndataitemkeys = [
"ID","Y","M","D","H","M","S","SMD","DIS","DISV",
'IODE','Crs','Delta_n','M0',
'Cuc','e','Cus','sqrt_A',
'TOE','Cic','OMEGA_A0','Cis',
'i0','Crc','omega','OMEGA_DOT',
'IDOT','L2Codes','GPSWEEK','L2PCODE',
'卫星精度','卫星健康状态','TGD','IODC',
'电文发送时刻','拟合区间','备用1','备用2'
]
# 将提取N文件中需要的卫星 转换下数据格式由字符串型 转为 float型 方便后续使用
#
def get_needs(items_22N):
xl_items = {}
for key in items_22N:
xl_items[key] = {}
for i in range(len(items_22N[key])):
x = items_22N[key][i]
if i >= 7:
x = float(x[:-4]) * pow(10, float(x[-3:]))
xl_items[key][Ndataitemkeys[i]] = x
else:
xl_items[key][Ndataitemkeys[i]] = x
return xl_items
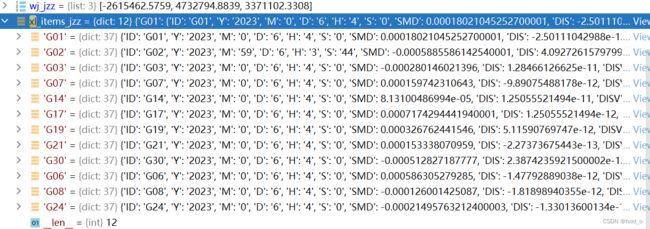
结果展示
图1直接读取到的全是字符串形式,不方便后续使用。因此需要转换,如图2

图2,用每个数据的含义作为键来保存数据。
总结
通过了解O文件和N文件的格式,通过最简单的读文件的方式,依靠共同特征和不同特征来分割达到想要的效果。