【MySQL】表的约束
表的约束
- 一、空属性
- 二、默认值
- 三、列描述
- 四、zerofill
- 五、主键
- 六、自增长
- 七、唯一键
- 八、外键
- 真正约束字段的是数据类型,如果插入的数据超出了对应数据类型的取值范围,那么数据将会插入失败。
- 但是数据类型的约束很单一,为了更好的保证数据的合法性,从业务逻辑角度保证数据的正确性,MySQL中出现了表的约束,目的就是为了尽可能保证数据安全,减少用户的误操作可能性。
- 表的约束有很多,本篇博客主要介绍如下几个:
null/not null、default、comment、zerofill、primary key、auto_increment、unique key、foreign key。
一、空属性
- 空属性有两个值:
null(默认的)和not null(不为空) - 数据库默认字段基本都是字段为空,但是实际开发时,尽可能保证字段不为空,因为数据为空没办法参与运算。
例如通过select可以看到null的值为null。如下:
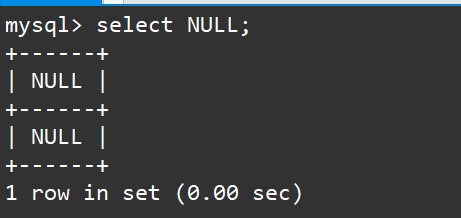
我们对尝试对空值进行运算,如下:

由于空值无法参与运算,因此null值加一后得到的还是null。
下面我们去构建一个班级成员表,每一个学生都要有一个班级:
create table class( name varchar(20), room_id tinyint );
desc class;

下面我们对这个表进行插入一些数据:张飞,2,刘备,2,曹操,1,孙权,3。
进行插入:
insert into class(name, room_id) values ('张飞',2);
insert into class(name ,room_id) values ('刘备',2);
insert into class(name, room_id) values ('曹操',1);
insert into class(name) values ('孙权');

插入完毕,我们查看一下表内容:
select * from class;

咦,孙权同学怎么会没有班级呢?仔细看一看我们的插入SQL,我们发现是我们在插入时,少写了room_id的相关信息,于是我们就要重新进行录入信息,可是这种出错是人为不小心出错,如果我们没有及时发现,那可能就会产生不好的后果,为了避免这种低级失误,我们就可以对这两个字段都加上not null约束,这样,当我们有信息没有录入完全时就会报错,我们就能够及时发现并修改。
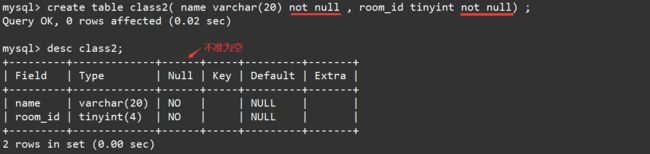
我们重新创建这个表,并进行信息录入:
create table class2( name varchar(20), room_id tinyint );
desc class;
进行插入:
insert into class2(name, room_id) values ('张飞',2);
insert into class2(name ,room_id) values ('刘备',2);
insert into class2(name, room_id) values ('曹操',1);
insert into class2(name) values ('孙权');
insert into class2(name, room_id) values ('孙权', 3);

插入完毕,我们查看一下表内容:
select * from class2;

表中的信息,都是正确的!在我们希望插入数据时有些字段不能为NULL时,我们就可以使用not null约束。
二、默认值
默认值:某一种数据会经常性的出现某个具体的值,可以在一开始就指定好,在需要真实数据的时候,用户可以选择性的使用默认值。
例如:我们去银行开户,当我们开户时不存钱那么我们的银行卡余额就应该的0元,如果我们存钱了,就应该是我们存的钱。
create table account( name varchar(20) not null, money decimal(10,2) default 0.00);
desc account;
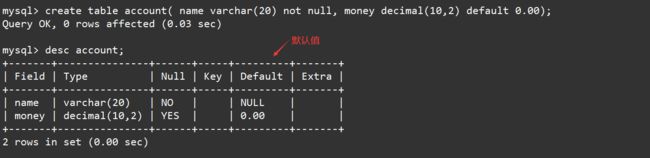
插入一些数据,张飞,12000,曹操,然后进行查看表中的内容

结果符合我们的预期,也省去了我们插入时的烦恼!
同时设置not null和default
- 一旦给某一字段设置了默认值,那么该字段将不会出现空值,因为就算插入数据时没有指明该字段的值,也会使用该字段的默认值进行填充。
- 而给某一字段设置
not null属性的目的是约束该字段不能为空,因此一个字段设置了default属性后,再设置not null属性就没有意义了。
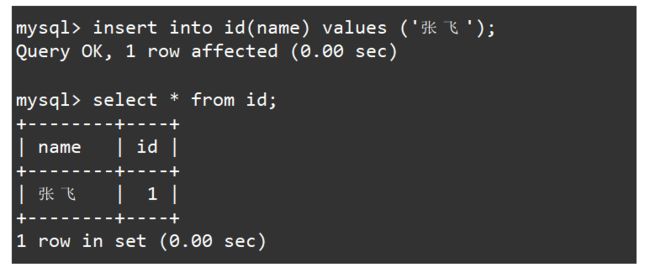
比如创建一个id表,表当中包括姓名和id,将id同时设置default和not null约束。如下:
create table id(name varchar(20), id int not null default 1);
desc id;

此时在向表中插入数据时可以不指明id进行插入,此时会使用id的默认值。如下:
三、列描述
列描述是在创建表的时候用来对各个字段进行描述的,列描述会根据表创建语句保存,一般是用来给程序员或DBA了解表的相关信息的,相当于一种注释。
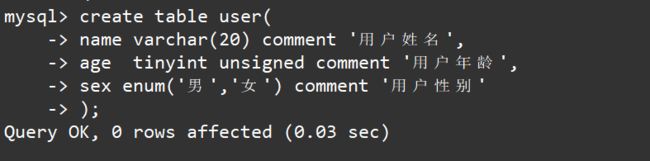
比如创建一个用户表,表当中包含用户名、用户的年龄和用户的性别,在每一个字段后面添加上对应的列描述。如下:
create table user( name varchar(20) comment '用户姓名', age tinyint unsigned comment '用户年龄', sex enum('男','女') comment '用户性别' );
创建表完毕后,通过show create table 表名 \G就可以看到创建表时的相关细节,包括列描述。如下:

四、zerofill
-
以前我们在使用
desc 表名查看表的结构时,我们发现数值类型后面的圆括号中有一个数字,这个数字代表的是显示宽度。 -
对应数值类型设置
zerofill属性后,如果数据的宽度小于设定的宽度则自动填充0,当然zerofill只是影响了显示的效果,并不会影响数据的具体值。
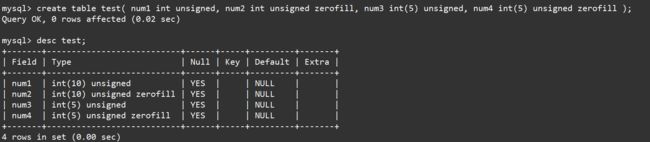
比如创建一个表,表当中包含num1和num2,num3,num4四列整型数据:
- num1与num3不设置zerofill属性,但是num3的显示宽度设置为5。
- num2与num4设置zerofill属性,但是num4的显示宽度设置为5。
(对于int unsigned由于没有符号位,所以最大的数字就是42亿多,所以默认的显示宽带为10,即10位数字宽度,如果有符号位则为11)
create table test( num1 int unsigned, num2 int unsigned zerofill, num3 int(5) unsigned, num4 int(5) unsigned zerofill );
desc test;
zerofill的正常显示效果
向表中插入一条记录,指明所有的值均为1:
-
由于我们没有给num1和num3字段设置
zerofill属性,因此查看表中数据时显示出来的都是1,并没有显示宽度的概念。 -
对于num2和num4由于我们设置了
zerofill属性,因此查看表中数据时位数不够会给我们进行补0操作,有显示宽度的概念。
如下:

超出设定的宽度后
zerofill的显示效果
- 当超出设定的宽度后
zerofill的约束效果就"消失"了。
我们给num3指定的显示宽度为5,但是int unsigned能存放的数据最大值是能有10位的,所以这里我们插入11111111,然后看num4的显示效果。

五、主键
主键:primary key用来唯一的约束该字段里面的数据,不能重复,不能为空,一张表中最多只能有一个,主键所在的列通常是整数类型。
通过主键我们能够很方便后续进行查找。
普通主键
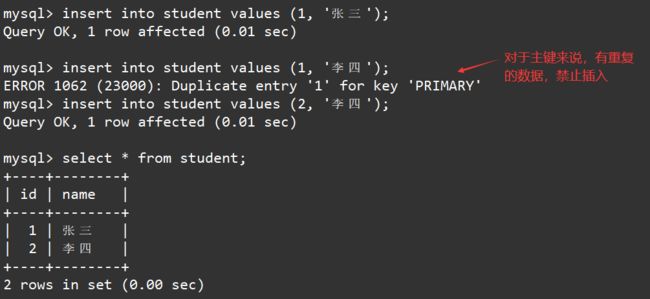
比如创建一个学生表,表当中包含学生的学号和姓名,由于学生的学号是不会重复的,因此可以将其设置成主键。如下:
create table student(id int unsigned primary key comment '学号', name varchar(20) not null comment '姓名');
desc student;

有主键约束时,插入表中的记录的主键字段不能重复,如果插入记录的主键与表中已有记录的主键重复,这时就会因为主键冲突而插入失败。如下:
insert into student values (1, '张三');
insert into student values (1, '李四');
insert into student values (2, '李四');
select * from student;
- 删除主键
使用下面的SQL即可删除指定表的主键,因为一个表只有一个主键,因此删除主键时只用指明要删除哪张表的主键即可。
alter table 表名 drop primary key
比如这里删除学生表的主键后再查看表结构,可以看到id对应的Key列的PRI已经没有了。如下:

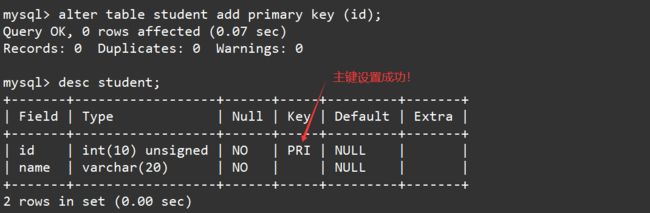
- 增加主键
对于已经创建好了的表,使用下面的SQL
alter table 表名 add primary key (列名)
可以给指定列设置成主键,但是需要注意的是,只有列当中的值不为空并且不重复的列才能被设置成主键。 比如这里重新将学号设置成学生表的主键后再查看表结构,可以看到id对应的Key列的PRI又回来了。如下:
ps:虽然我们可以在中途给某一列添加主键,但是最好创建表时就指定好主键,不然在表的使用过程中,当我们想要为某一列设置主键时但是这一列已经出现了重复数据了,这时我们设置主键就会失败,除非将重复的数据给删除掉然后再添加主键。
复合主键
- 一张表中最多只能有一个主键,但是一个主键是可以由多个字段一起构成来执行主键的功能,这种主键叫做复合主键。
- 复合主键用来唯一约束多个字段里面的数据,表当中每条记录的这多个字段不能同时重复也不能为空。
语法:
在创建表的时候,在所有字段之后,使用primary key(主键字段列表)来创建复合主键。
比如创建一个进程表,表当中包含进程的IP地址、端口号和进程的相关信息,并将IP地址和端口号组合起来形成一个复合主键。
create table process (ip varchar(15) comment 'ip地址',
port smallint unsigned comment '端口号',
info varchar(128) comment '相关信息',
primary key(ip, port));
desc process;

在向进程表中插入数据时,只有插入进程的IP和端口均出现冲突时才会产生主键冲突,否则就允许插入。如下:
insert into process values ('127.0.0.1', 8080, '测试进程1');
insert into process values ('127.0.0.2', 8080, '测试进程2');
insert into process values ('127.0.0.1', 8081, '测试进程3');
insert into process values ('127.0.0.1', 8081, '测试进程4');
insert into process values ('127.0.0.1', 8080, '测试进程4');
select * from process;

查看表中插入的数据可以看到,表当中有重复的IP地址,也有重复的端口号,但是不会出现IP和端口均重复的,这就是复合主键的作用!
- 删除复合主键
与普通主键一样,使用下面的SQL,因为一个表只有一个主键,因此删除主键时只用指明要删除哪张表的主键即可。
alter table 表名 drop primary key
比如这里删除进程表的复合主键后再查看表结构,可以看到ip和port对应的Key列的PRI都没有了:
alter table process drop primary key;

- 增加复合主键
与普通主键一样,使用下面的SQL,对于已经创建好了的表,使用下面的SQL来增加复合主键
alter table 表名 add primary key (列名)
比如这里重新将ip和port设置成进程表的复合主键后再查看表结构,可以看到ip和port对应的Key列的PRI又回来了。如下:
alter table process add primary key (ip,port);

六、自增长
-
自增长就是自动增长,设置了自增长属性的字段,插入数据时如果不给该字段值,那么系统会自动找出当前字段当中已有的最大值,将最大值进行+ 1后的值插入该字段。
-
任何一个字段要做自增长,前提是其本身必须是一个索引(Key一栏有值),并且自增长字段必须是整数类型,一张表最多只能有一个自增长字段。
-
自增长通常和主键搭配使用,作为逻辑主键。一般而言,建议将主键设计成与当前业务无关的字段,避免因为业务逻辑的调整而需要修改主键。
比如创建一个学生表,表当中包含id和name,将id同时设置成主键和自增长字段。如下:
create table auto_student( id int primary key auto_increment, name varchar(20) not null);
desc auto_student;
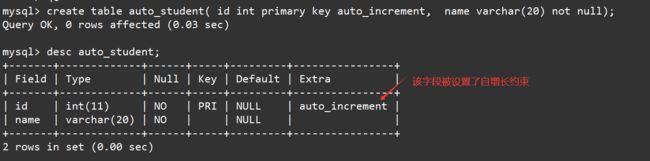
向表中插入第一条记录时如果没有指明自增长字段的值,那么自增长字段的值默认将会从1开始,后续向表中插入记录时如果也不指明自增长字段的值,那么自增长字段的值就会依次递增。如下:

当然,插入记录的时候也可以指明自增长字段的值,此时将会使用该值进行插入,但注意指明的值不能和表中已有的id值重复。如下:

此后向表中插入记录时如果又不指明自增长字段的值,那么自增长字段的值将会从id列中找出最大值,将最大值加一后得到的值作为自增长字段的值进行插入。如下:
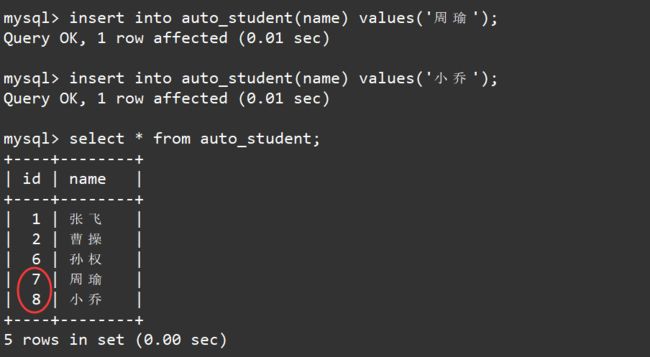
思考一下 : 为什么MySQL知道我们当前的自增值的最大值是多少呢?
其实我们可以通过查看表创建时的相关信息得到答案
show create table auto_student \G
可以看到其实MySQL记录了了当前自增值的值为多少,当然,我们也可以在创建表时,在表外设置这个值。

七、唯一键
-
一张表中有往往有很多字段需要唯一性,数据不能重复,但是一张表中只能有一个主键,为了解决这个问题唯一键就出现了。
-
唯一键和主键都能保证字段中数据的唯一性,但唯一键允许字段为空,并且可以多个字段为空,空字段不做唯一性比较。
-
需要注意的是,不是主键具有唯一性,而是某个具有唯一性的字段被选择成为了主键,而那些不是主键但是同样需要唯一性约束的字段就应该设置成唯一键。
关于唯一键和主键的区别:
我们可以简单理解成,主键更多的是标识唯一性的方便我们进行索引。而唯一键更多的是保证在业务上,不要和别的信息出现重复。
乍一听好像没啥区别,我们举一个例子:
假设一个场景(当然,具体可能并不是这样,仅仅为了帮助大家理解)
比如在公司,我们需要一个员工管理系统,系统中有一个员工表,员工表中有两列信息,一个身份证号码,一个是员工工号,我们可以选择身份号码作为主键。
而我们设计员工工号的时候,需要一种约束:而所有的员工工号都不能重复。这个员工号代表的就是在业务上不能重复,我们设计表的时候,需要这个约束,那么就可以将员工工号设计成为唯一键。
一般而言,我们建议将主键设计成为和当前业务无关的字段,这样,当业务调整的时候,我们可以尽量不会对主键做过大的调整。
例如创建一个学生表,表当中包含学生的学号、姓名和电话号码,将我们选择学号作为主键,但同时每个学生的电话号码也应该具有唯一性约束,因此应该将电话号码设置成唯一键。如下:
create table uni_student(
id int primary key auto_increment comment '学号',
name varchar(20) not null comment '姓名',
tel char(11) unique comment '电话号码' );
desc uni_student;

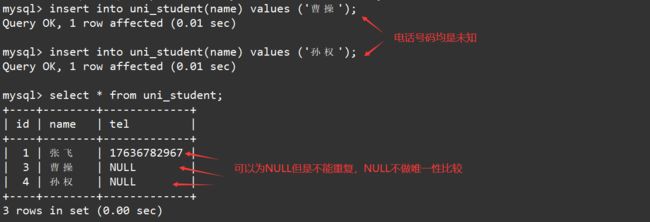
向表中插入记录时,如果插入记录中的电话号码与表中已有记录的电话号码出现重复,那么就会因为唯一键冲突而插入失败。如下:

此外,向表中插入的记录可以不指明唯一键字段的值,此时该字段默认为空,不做唯一性比较。如下:
八、外键
-
外键用于定义主表和从表之间的关系:外键约束主要定义在从表上,主表则必须是有主键约束或
unique约束。 -
当定义外键后,要求外键列数据 必须在主表的主键列存在或为
null。
语法:
foreign key (字段名) references 主表(列)
例如我们要设置两张表,一张学生表,一张班级表,如下:

可以看出上面的两张表出现了数据冗余,我们实际需要一个班级id就行了,于是我们就可以设计成让stu->class_id和myclass->id形成关联的关系,这就需要使用到了外键约束了。
下面我们就对上面的示意图进行创建:
- 先创建一个班级表作为主表,表当中包含班级的id和班级名,并将班级id设置为自增主键。
create table class(
id int primary key auto_increment comment '班级编号',
name varchar(20) not null comment '班级名称');
desc class;

- 再创建一个学生表作为从表,表当中包含学生的id、姓名以及学生所在班级对应的id,并将学生表中的班级id列设置成外键,关联到班级表中的班级id列。如下:
create table stu(
id int unsigned primary key comment '学号',
name varchar(20) not null comment '姓名',
class_id int comment '学生所对应的班级',
foreign key (class_id) references class(id));

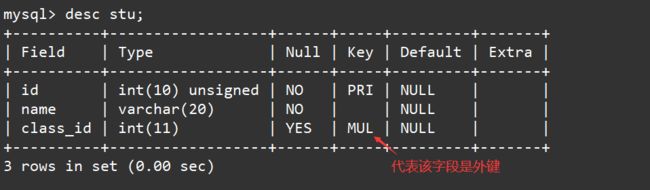
表创建完毕后查看学生表的表结构,可以看到学生表中的班级id对应的Key列出现了MUL标志,这表明class_id已经成功被设置成了外键。如下:
desc stu;
为了演示外键约束的功能和特性,我们先向班级表中插入两条记录。如下:
insert into class values (1, '机器人工程');
insert into class values (2, '通信工程');

这时向学生表中插入记录时,如果插入的记录对应的班级id是班级表中存在的,或者插入的班级id为null,那么此时是允许进行插入的。如下:

但如果插入学生表的记录对应的班级id是3 ,相当于插入学生表的这条记录对应的班级并不存在,此时将会插入失败,这就是外键约束。如下:

这就是刚才我们说的:当定义外键后,要求外键列数据 必须在主表的主键列存在或为null。
对于外键的依赖字段的数据进行删除
在这个学生和班级的示例中,我们的从表stu的外键字段class_id是依赖于主表class的id。
当我们删除主表中id对应的数据时,必须要确保这个id字段不能有数据还在关联。
select * from stu;
select * from class;
delete from class where id=2;

所以这里当我们想要删除2号班级时,必须先将确保这个班里面没有学生。
delete from class where id=2;
delete from class where id=2;
select * from class;
select * from stu;
