HTTP协议
文章目录
- 一、HTTP 是什么
- 二、HTTP协议格式
- 三、手动构造 HTTP 请求
- 四、HTTPS
一、HTTP 是什么
1. 概念
HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的应用层协议,应用层一方面是需要自定义协议,另一方面也会用到一些现成的协议。HTTP协议,就是最常用到的应用层协议。
- 超文本:文本指的是字符串,超文本则是除了能传输字符串,还能传输其他的内容,如图片、字体、视频、音频等
HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均为TCP, HTTP3 基于 UDP 实现)
现在的网址往往是https开头的,https会为了防止运营商劫持,由http进化而来的
应用层协议
TCP/IP负责数据的通信,即从A端传送到B端,但是两端还需要对数据进行加工处理或使用(说明书),所以还需要一层【不关心通信细节,关心应用细节】的协议 ----- 应用层协议。
因为应用有不同的场景,所以应用层协议是有不同种类的,其中最经典常用的就是HTTP协议
2. HTTP协议的工作过程
客户端往往是浏览器/手机app,服务器则是访问那个网站的服务器
eg. 如果要访问搜狗,就需要在网址栏上输入搜狗的域名,这个域名就会通过DNS解析成一个IP地址,再进一步构造成一个HTTP请求,把他发送给搜狗的服务器,搜狗的服务器就会根据这个HTTP请求,返回对应的HTTP响应,这个响应里面就会携带一些数据,比如HTML文件、CSS文件等
注意,当我们访问一个网站的时候,可能涉及不止一次的HTTP请求/响应的交互过程

二、HTTP协议格式
HTTP 是一个文本格式的协议,可以通过抓包工具进行捕捉。抓包工具可以理解为一个“代理”,浏览器访问时,先将HTTP请求发给抓包工具,抓包工具再把请求转发给对应的服务器。返回响应时,也是如此。
空行相当于是“报头的结束标记/报头和正文之间的分隔符”,用于避免“粘包问题”
HTTPS 加密之后是变成二进制了,但是抓包工具解析HTTPS的话,可以将HTTPS数据进行解密,从而还原出原本的HTTP内容(文本)
1. 请求
- 首行:方法 +url + 版本,使用空格分隔
- Header(请求头):请求的属性,冒号分割的键值对
- 每组属性之间使用 \n 分隔
- 遇到空行表示Header部分结束
- Body:空行后面的内容
- 允许为空字符串,如果Body存在,则在Header里,会有一个Content - Length 属性来标识Body的长度
- Body 中的格式是有很多种的,也是键值对,但是经历了urlencode
(1)url ------- 统一资源定位符
区域概念

-
https : 协议方案名. 常见的有 http 和 https, 也有其他的类型. (例如访问 mysql 时用的
jdbc:mysql ) -
user:pass : 登陆信息. 现在的网站进行身份认证一般不再通过 URL 进行了,一般都会省略
-
www.example: 服务器地址,可以是ip地址,也可以是域名,域名会通过 DNS 系统解析成一个具体的 IP 地址
-
80:端口号,是用来区分应用程序的。
-
dir/index.htm : 带层次的文件路径,用于确认访问的是服务器上的哪个资源
-
uid=1 : 查询字符串(query string),表示访问资源的时候,带上什么样的参数,对资源进行补充说明
- 本质是一个键值对结构。键值对之间使用 & 分隔,键和值之间使用 = 分隔
- 这里键和值的含义,都是程序员自定义的。只有写这串代码的程序员才知道是什么意思
-
#ch1:片段标识符,主要用于页面内跳转,常用于文档类的网站中,通过不同的片段标识跳转到文档的不同章节)
关于省略问题
- IP地址/域名省略:此时相当于是访问当前服务器的地址
eg.访问b站主页,请求中必须要带上bilibili的域名,响应内容就是bilibili主页的html,这个html里又会出发一些其他的http请求,这些后续触发的http请求,就可以省略ip,相当于使用和获取刚才获得bilibili 的html一样的ip - 端口号:
(1)可以被省略,当端口号省略的时候, 浏览器会根据协议类型自动决定使用哪个端口。例如 http 协议默认使用 80 端口, https 协议默认使用 443 端口。
(2)<1024的端口号 ---- 知名端口号,都被一些常用的服务器瓜分了,号码越小,表示资历越老 - 带层次的文件路径:
如果省略,相当于访问的是【/】,也就是根目录。第一个【/】是根节点,通常根节点会对应到服务器的主页 - 查询字符串:
可以让后端代码根据情况进行处理
URL encode
query string 中可能会带有一些特殊符号,而这些特殊符号,可能在url中本身就有一定的含义(相当于不能用关键词作为变量名),这会导致浏览器/服务器解析失败,所以就需要转换
转换规则:把要转换的内容的二进制的每个字节都用十六进制进行表示,然后每个字节前面加上一个%
(2)方法
方法描述的是【语义】,表示这次请求要干什么,常用的方法是 POST 和 GET
GET:从服务器中获取XXX
POSt:向服务器传输一个XXX
但是事实上,GET和POST不一定遵守上述语义
GET:GET 请求一般没有body
POST:POST一般在登录/上传的场景中出现
登录时,直接展示在url里,感觉不太安全。上传时,因为内容太多,直接放到url里,也会显得不安全
区别:
(1)GET 是把一些自定义的数据放到query string里,body 通常是空的。放在url里,用户能直接看到。
(2)POST 是把一些自定义的数据放到body里,query string 通常是空的。放到body中,用户没法直接看到
因为POST和GET数据本质上放哪里都可以,所以本质上没啥区别
关于POST 和 GET 区别的错误解释:
- 比较长的数据放到body中(使用post),是因为GET请求中的url长度有限制
- RFC 标准文档中明确表示,url的长度不作限制要求。(机器资源有限的时代,不同的浏览器可能对url长度有限制,但现在基本没有了)
- POST 比 GET 更安全,传输的数据不容易被黑客截获或破解
- POST 只是把传输的数据让普通用户没法直接看到,这不影响黑客是否容易截获。保证安全的关键,是对传输的敏感数据,进行加密
- GET 和 POST 语义不同
- 设计者最初是赋予了不同语义,但是实践中,不一定会完全遵守
- GET是幂等的,POST不是幂等的
- 幂等:每次给予相同的东西,都会反馈同样的东西。不会一天变一个样
- RFC文档里上是,建议这么设计,实际开发中,并不保证会遵守
- 是否要幂等,要根据实际场景进行取舍,比如查询账户余额就需要是幂等的,而浏览器搜搜的广告排行,则不是幂等的,会随时做出改变
- GET请求可以被缓存,POST不能被缓存
- 缓存的前提是幂等(下次用的时候,可以直接拿上次的结果,要求结果不会变)
其他方法:
- DELETE 删除服务器指定资源
- OPTIONS 返回服务器所支持的请求方法
- HEAD 类似于GET,只不过响应体不返回,只返回响应头
- TRACE 回显服务器端收到的请求,测试的时候会用到这个
- CONNECT 预留,暂无使用
2. 响应
HTTP响应的内容通常是HTML、CSS、JS等,浏览器显示的网页其实是从服务器下载下来,从而能够正常显示的
- 首行:版本号 + 状态码 + 状态码解释
- Header(请求头):请求的属性,冒号分割的键值对
- 每组属性之间使用 \n 分隔
- 遇到空行表示Header部分结束
- Body:空行后面的内容
- 允许为空字符串,如果Body存在,则在Header里,会有一个Content - Length 属性来标识Body的长度
- 如果服务器返回一个html页面,那么html页面内容就在body中
在抓包观察响应数据的时候, 可能会看到压缩之后的数据, 形如:
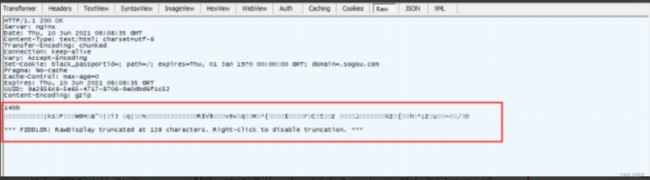
网络传输中 “带宽” 是一个稀缺资源, 为了传输效率更高往往会对数据进行压缩。点击 Fiddler 中的【 Rsponsebody is encoded.Cllick to decode 】即可进行解压缩, 看到原始的内容
(1)HTTP状态码:
1xx:信息状态码,接受到请求正在处理
2xx:成功状态码,请求正常处理完毕
3xx:重定向状态码,需要进行附加操作来完成请求
4xx:客户端错误状态码,服务器无法处理请求
5xx:服务器错误状态码,服务器处理请求出错
状态码就是对这次响应的定性:成功、失败的各种原因
常见的HTTP状态码:
- 200 成功
- 403 访问的资源没有权限
- 404 访问的资源不存在
- 502 服务器挂了
- 504 服务器超时了
- 302 临时重定向(浏览器会自动跳转到其他的页面)
- 301 永久重定向
eg. 使用浏览器访问www.aaa.com 这个url,此时,请求发给对应的服务器,结果返回了302,同时告诉你要去访问 www.bbb.com ,于是浏览器收到这个响应之后,就会自动跳转到www.bbb.com
(2)body:
正文的具体格式取决于 Content-Type:
- text/html
- text/css
- application/javascript
- application/json
3. 认识报头
整体是键值对结构,query string和body中的键值对,是由程序员自定义的。但是header 中的键值对,大部分是标准规定的,小部分是自定义的
(1)Host:
表示服务器主机的地址和端口,虽然url中已经写了,但是假如使用了代理,那么host里的内容就会和url里的不一致
(2)Content-Length:表示 body 中的数据长度,是多少字节
(3)Content-Type:
请求
表示请求的 body 中的数据格式。针对这个数据,应该如何解析,如何理解,HTTP协议有很多用途,传输的数据也同样有很多种类
- application/x-www-form-urlencoded: form 表单提交的数据格式,此时 body 的格式形如:
title=test&content=hello
- multipart/form-data:大部分上传文件/图片是这种情况
- application/json: 数据为 json 格式. body 格式形如:
{“username”:“123456789”,“password”:“xxxx”,“code”:“jw7l”,“uuid”:“d110a05ccde64b16
a861fa2bddfdcd15”}
响应
响应报头的基本格式和请求报头的格式基本一致
响应中的 Content-Type 常见取值有以下几种:
- text/html : body 数据格式是 HTML
- text/css : body 数据格式是 CSS
- application/javascript : body 数据格式是 JavaScript
- application/json : body 数据格式是 JSON
(4)User-Agent
主要包含当前机器的系统和浏览器的版本。以前主要是用来适配不同的浏览器,现在由于浏览器的功能都趋于完善,现在主要是用来区分是PC端还是移动端

(5)referer
表示当前页面是从哪里跳转来的。直接搜索什么的,请求是不会带referer的
(6)Cookie
概念
浏览器第一次和服务器建立上联系后,刚开始浏览器上是没有任何和这个服务器相关的数据的。但是,用户在网页操作中,会产生出很多的“临时性”数据,这些数据,有的可以放到服务器这边存储(下次可以直接获取到),有的不太重要的,则可以放到浏览器这边存储(下次访问也可以直接用,但是换了台电脑可能就无了)
而Cookie 正是 浏览器本地存储数据的一种机制,当产生一个临时数据后,可以在Cookie中写入一个数据,浏览器就会自动存储这个数据(存储在浏览器所在电脑的硬盘上),后续再访问B站,浏览器就能把这个数据读出来,并且放到http请求中
浏览器不能直接访问硬盘,将数据写入文件中,网站可以轻易访问用户的文件系统,是十分危险的。Cookir 提供了一系列安全性和保护隐私性的措施。
存储形式
Cookie 是按照键值对的方式来存储一些字符串,这些键值对往往都是浏览器返回来的(由程序员自定义的内容),浏览器会把这些键值对按照“域名”分类存储
(7)Session
场景:
一个网站的Cookie会存储很多键值对,但是有一个特别重要的键值对,是用来存储用户的“身份信息”的,这样就可以不用重复登录了
为了实现身份识别的效果,不仅仅需要Cookie 来支持,在服务器这边也需要一个Session来支持
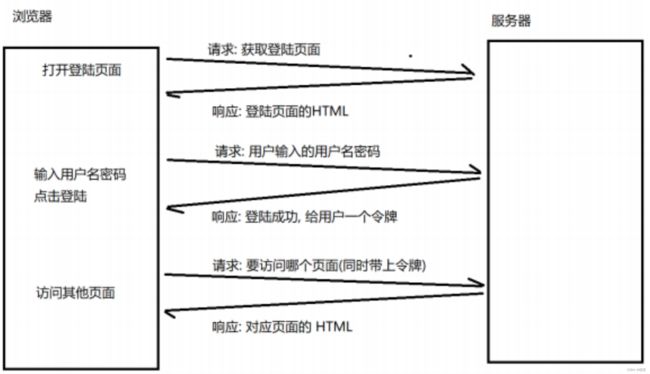
这个令牌对应的就是 sessionId,通过浏览器返回给浏览器,然后被保存在Cookie 中
在返回SessionId时,服务器也会创建出一个对应的Session(电子档案),Session 里面会记录一些关键信息,可以理解为哈希表式存储,以SessionId 为key(身份标识),Session为value(电子档案的详情),把所有数据组织起来
后续访问网站的其他页面,Cookie字段中,都会带上SessionId,服务器就可以根据SessionId知道当前用户的身份信息
三、手动构造 HTTP 请求
1. 通过 form 表单构造 HTTP 请求
<form action="http://abcdef.com/myPath" method="GET">
<input type="text" name="userId">
<input type="text" name="classId">
<input type="submit" value="提交">
</form>
action 属性:描述了构造的HTTP请求中url是什么
method 属性:对应 HTTP 请求的方法
name 里面的值就是键值对中的键,用户在输入框中输入的内容就是键值对的值(用来向服务器提交数据),这些会被放到http请求的query string / body 中
form 表单,只能支持 get 和 post,不能支持 put、delete、options 等其他方法
2. 通过 js 的 ajax
(1) ajax 是一种异步的通信方式,通过代码发出了http请求,请求发出去后,js代码就可以继续往下执行了。当服务器的响应回来后,会自动通知代码,然后也就可以进一步处理响应了。等待的职责,放到了被发起者的身上(主要任务不是只等他,可以在做自己的事的同时等他)
(2) 特点:可以不需要 刷新页面/页面跳转 就能进行数据传输。比起form表单,更加灵活,form表单必须要传些参数
(3)在 JavaScript 中可以通过 ajax 的方式构造 HTTP 请求
ajax是 js 提供的一组api,原生的api用起来不是很方便
$.ajax({
type:'get',
url:'https://www.sogou.com',
contentType:'application/x-www-form-urlencoded', //对应header中的content-Type部分
data:'aaa=111&&bbb=222' //对应请求中的body部分
//表示服务器返回响应时,要如何处理
success:function(body){
//相当于System.out.printIn
console.log('ok');
}
})
- $.ajax:用来发起 ajax 请求的方法
- $ 在 js 中,是一个合法的变量名,该变量在 jQuery 中已经定义好了。$ 对象里有很多方法,都已经被 jQuery 封装好了
- {} 表示的是 js的对象(键值对),键值对可以有多个,键值对固定都是string类型,可以写‘’,也可以写“”,或者不写。键值对之间用,分割,键和值之间用:分割
- success 的值是一个函数,这个函数会在收到响应的时候,被浏览器自动调用,调用的时候,就会把响应的body,通过参数传给这个函数 ------ 回调函数
3. Java 代码(其他各种语言的代码)
创建一个Socket,往里面按照HTTP协议的格式写数据
4. 借助第三方工具
比如postman ,一个老牌的http客户端
四、HTTPS
HTTPS 也是一个应用层协议. 是在 HTTP 协议的基础上引入了一个加密层
HTTP 协议内容都是按照文本的方式明文传输的. 这就导致在传输过程中出现一些被篡改的情况
即运营商劫持,为了避免它,在HTTP基础上进行了一层加密
1. 前置概念
- 明文:真正要传输的数据
- 密文:明文经过加密后的数据
- 密钥:密码本
- 加密:明文 + 密钥 ===> 密文
- 解密:密文 + 密钥 ===> 明文
- 对称加密:加密和解密,使用的是相同的密钥
- 非对称加密 :加密和解密,使用的是不同的密钥
- 一个是公钥,一个私钥。可以使用公钥加密,私钥解密,也可以使用私钥加密,公钥解密
2. HTTPS的工作方式
因为直接传明文,风险极大,所以需要加密后的密文
加密的方式有很多, 但是整体可以分成两大类: 对称加密 和 非对称加密
(1) 引入对称加密
引入对称加密之后, 即使数据被截获, 由于不知道密钥是什么,因此就无法进行解密, 也就不知道请求的真实内容是什么了
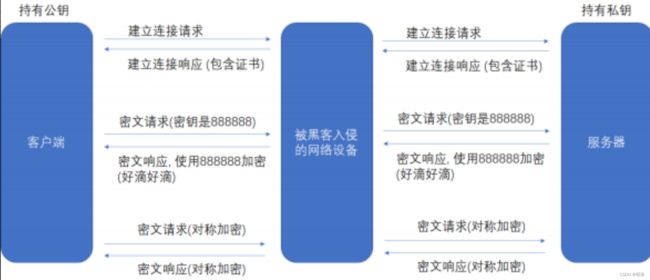
问题1:因为同一时刻,服务器要给多个客户端提供响应,如果密钥都是一样的,那么十分容易扩散,乃至被黑客捕获。所以,服务器就需要维护每个客户
端和每个密钥之间的关联关系,但是这也十分麻烦

解决方法:服务器和客户端共同协议用什么密文

衍生问题1:
如果直接把密钥明文传输, 那么黑客也就能获得密钥了, 此时后续的加密操作就形同虚设了。所以,要给密钥加密,然后要给密钥加密的密钥加密……无线套娃了
解决方法:引入非对称加密
(2) 引入对称加密
公钥和私钥是配对的. 最大的缺点就是运算速度非常慢,比对称加密要慢很多。公钥给谁都行,但是私钥只能自己持有

由于中间的网络设备没有私钥, 即使截获了数据, 也无法还原出内部的原文, 也就无法获取到对称密钥
由于对称加密的效率比非对称加密高很多, 因此只是在开始阶段协商密钥的时候使用非对称加密,后续的传输仍然使用对称加密
问题1:客户端无法确定这个公钥是不是被黑客伪造的(中间人攻击)
解决方法:引入证书,通过第三方确保,来证明这个公钥是有效的
(3) 引入证书
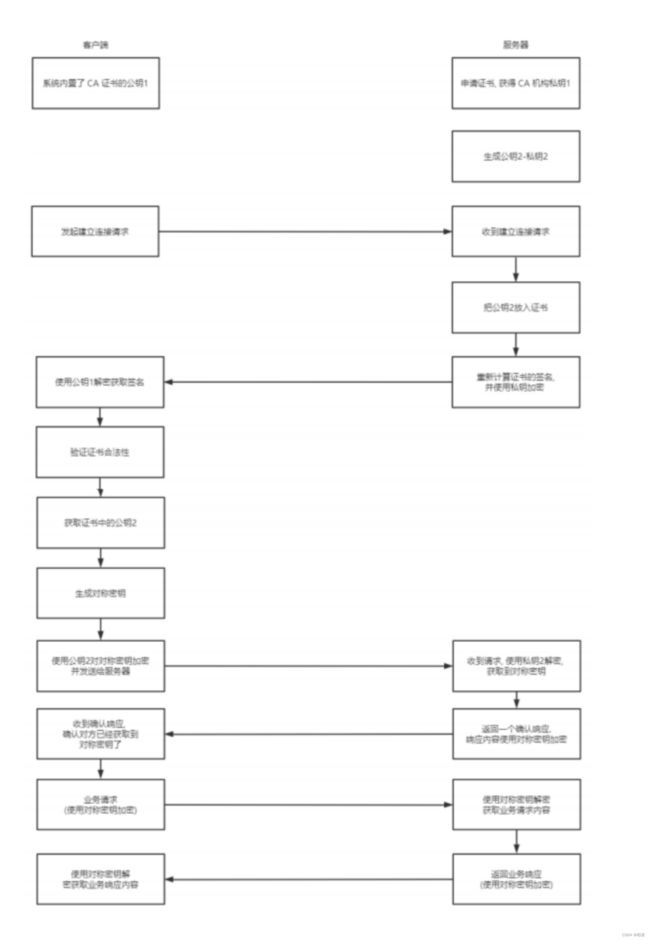
在客户端和服务器刚一建立连接的时候, 服务器给客户端返回一个 证书,这个证书包含了刚才的公钥, 也包含了网站的身份信息。类似于一个结构化的字符串,包含了许多内容。
当客户端获取到这个证书之后, 会对证书进行校验(防止证书是伪造的) ------ 客户端通过操作系统里已经存的了的证书发布机构的公钥进行解密, 还原出原始的哈希值, 再与传过来的进行校验
针对数字签名进行解密
- 黑客替换数字签名
- 数字签名是先计算校验和,再使用认证机构的私钥进行解密。黑客因为不知道私钥是什么,所以无法解密
- 黑客无法替换整个证书
- 证书中有网站的域名,如果和网站的域名一样,无法通过审核,不一样,客户端那边能比对发现错误
(4) 全部流程