windows安装stable-diffusion-webui教程
整合包对非技术出身的同学比较友好,因为秋叶大佬把相关的东西已经都整合好了,只需要点点点就行了。当然懂编程的同学就更没有问题了。
准备
为了保证AI绘画的效率,建议在本机安装Nvidia独立显卡,也就是俗称的N卡,并且显存要达到6G以上,6G只能出图,如果要做训练建议12G以上。推荐选择RTX40系列及以上的显卡型号,最低也要选择RTX30系列。如果你没有N卡,可以使用CPU进行图形计算,但是性价比较低,出图速度较慢。此外,还需要确保CPU性能足够高,并且搭配至少16G的内存。总的来说,如果只是进行简单的图形处理或者体验,可以使用CPU,但不适合搞AI绘画。
看到这里,有的同学可能会有点失望了,没有这么好的机器就玩不了AI绘画吗?别担心,我们还可以使用云主机,下一篇我会分享使用云主机的姿势。
安装前看自己显卡型号的方法:
1、电脑左下角点击WIndows窗口图标,然后点击“设置”。
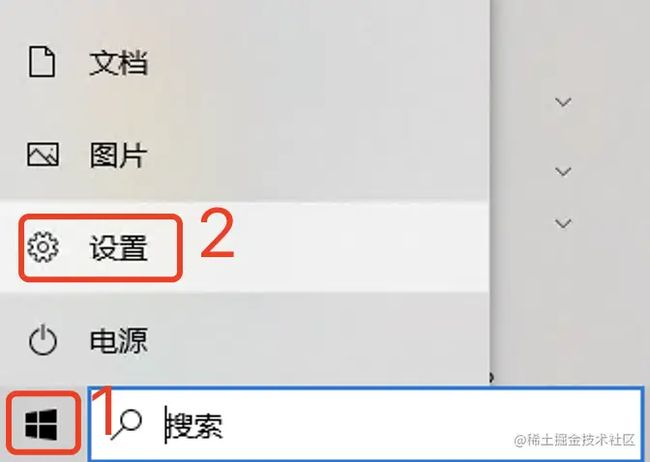
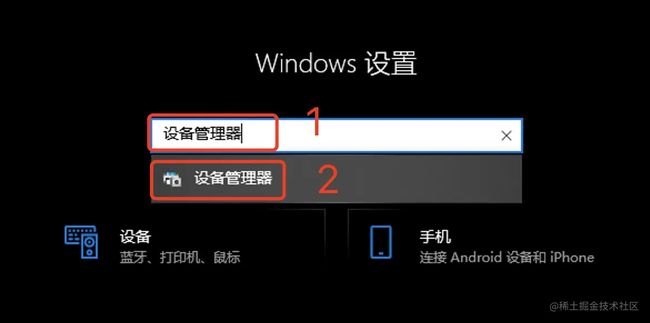
2、在打开的窗口中,搜索“设备管理器”,找到后点击打开。
3、找到“显示适配器”,就可以看自己的显卡了。如果是Nvidia的显卡,就会有这几个字。我这个演示的电脑是不是N卡,所以只能以CPU的方式运行。

下载
所有需要的东西都放到盘盘里边了,大家自行下载即可:
pan.baidu.com/s/1Hvw8ptSv… 提取码: bmm1
为了方便大家搞AI绘画,这里边不仅包含了秋叶大佬的整合包,还有很多的大模型、Lora模型、ControlNet模型等等,总计大约有100多G,全部下载下来会很慢。
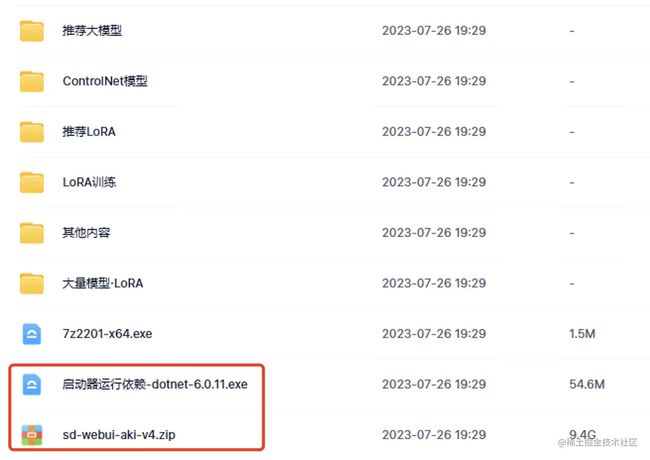
但是没必要都下载下来再安装,先把最后两个文件下载下来就行了,鉴于百度限速,可能也需要几个小时,大家耐心等待,磨刀不误砍柴工!
启动
下载完上边说的两个文件就可以启动。
1、安装驱动。这个整合包是由 .NET6 (就是一个软件基础平台)驱动的, 大家需要先安装“启动器运行依赖-dotnet-6.0.11.exe”这个文件。

安装过.NET6的同学可以跳过这一步,不懂的再安装一遍也没问题。
2、解压“sd-webui-aki-v4.zip”。自己选择一个磁盘,比如D盘,直接解压到D盘根目录就行了。然后进入解压后的文件夹 sd-webui-aki-v4 。
双击“A启动器.exe”,它会自动下载一些最新的程序文件。我这里还弹出了“设置Windows支持长路径”,确定就可以了。
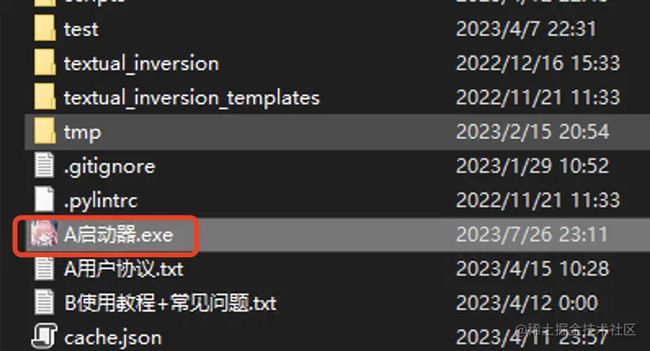
启动成功后,会打开下边这个界面。如果啥都做完了,也没打开这个界面,就再次双击这个文件,一般就打开了,还打不开的找我。
在这个启动界面中点击右下角的“一键启动”按钮。
然后会弹出一个控制台窗口,做一些初始化的操作,出现“Startup time ...”的提示就代表启动成功了。
然后这个工具会自动在浏览器中打开SD WebUI的窗口。不小心关了的时候,也可以用 http://127.0.0.1:7860 再次打开。打开的界面如下图所示:

出图
只需要简单5步:
1、Stable Diffusion 模型:anything-v5,这个是整合包自带的默认大模型,不用选就是它。
2、外挂VAE模型:选择 840000 这个,这东西就像个滤镜,用它出图的颜色比较丰富。
3、提示词:想要画个什么,就在这里写,需要是英文。
4、反向提示词:不想要在图片中出现什么,就把它写在这里,这里填写的“EasyNegative”是整合包附带的一个通用反向提示词的代号。
5、其它参数先不管,点击“生成”按钮。
6、生成速度取决于你的计算机性能,等一会就会出图了。点击可以放大,右键可以下载。

除了在这个WebUI上直接下载图片,我们还可以通过启动工具下载,如下图所示,红框圈出的就是各种生成方式保存图片的位置,单击就可以打开本机目录。

进阶
为了更好的绘图,这里介绍几个基础并且常用的概念:
模型:可以理解成一个函数,输入一些参数,得到一些返回值。只不过这里谈到的模型的参数特别多,几十亿、上百亿、上千亿。在Stable Diffusion中,我们可以简单的认为参数就是提示词、反向提示词、图片尺寸、提示词引导系数、随机数种子等等,返回值就是图片数据。
大模型:有时也称为基础模型,文件一般很大,常见的都在2G-5G。这是因为它们使用了很多的图片进行训练,累积了大量的数据。SD官方发布了一个基础模型,但是因为比较通用,兼顾的方面比较多,特点不足,所以大家一般很少使用。比如有的人喜欢二次元、有的人喜欢真实、有的人喜欢3D,用官方模型出图的效果不是最优的,所以很多组织或者个人就专门训练某方面的模型,并发布到社区给大家使用。
盘盘中提供了一些大模型,大家可以去下载:
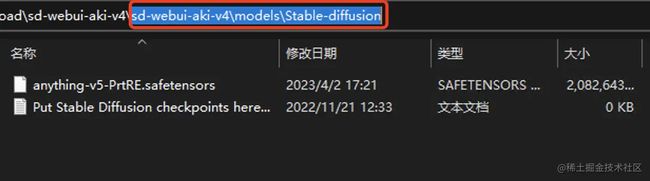
然后放到整合包的这个目录下:sd-webui-aki-v4\models\Stable-diffusion,从盘盘下载的整合包中已经默认有一个大模型。
VAE模型:这个东西有点类似手机中编辑照片时的滤镜,可以处理图片的颜色和线条,让图片看起来色彩更丰富饱满。很多大模型会自带VAE模型,这时候我们就不需要再给它搭配一个VAE,当然也有不自带的,这时就需要搭配一个。上图选择的 840000 是一个常用的的VAE模型,如果你生成的图片比较灰暗,可以试试这个VAE。其实秋叶整合包提供了四个选项,如下图所示,我一般都选“自动识别”,除了 840000,animevae 是专门优化二次元图片的。一般这两个VAE模型就够了。

Lora模型:这是一种基于大模型的风格模型,比如我们画小姐姐的时候,可以用一些Lora模型来控制人物的服装、头饰;生成机械四肢的时候,可以用一些Lora模型来强化肢体上覆盖的机甲样式;画风景图的时候,可以用一些Lora模型来控制绘画的风格。
可以从盘盘中的这两个目录下载:

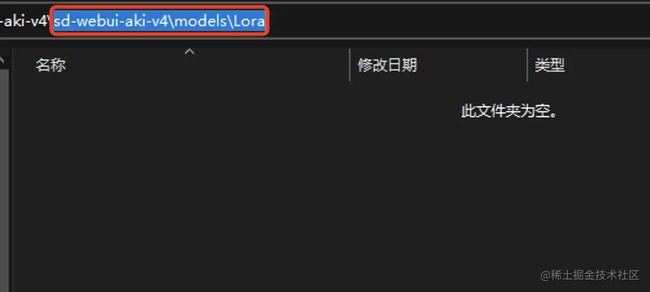
下载后放到整合包的这个目录下:sd-webui-aki-v4\models\Lora,初始状态下里边是空的。
提示词:对图像的描述,也就是想画一幅什么样的画。比如我上边使用的:a girl,但是这个提示词过于简单,AI虽然画出了一个女孩,但是他不知道你脑子里的女孩长什么样子,如果要画的更符合你的需求,你还要告诉他更多细节才好,比如女孩的头发是什么颜色、穿着什么衣服、站着还是坐着、在户外还是室内等等。提示词在AI绘画中特别重要,后边我会专门分享如何写好提示词。
反向提示词:不想在图片中出现的东西,比如树、桌子、6根手指、缺胳膊断腿等等,在上边的示例中我使用了“EasyNegative”,这是一个嵌入模型的代号,可以认为它代表了很多常见的反向提示词,使用它就不用一个个输入了,也不占用过多的提示词。
随机数种子:上边没有演示这个参数,但是它是AI绘画的魅力之一。即使其它的参数都相同,只要随机数不同,每次生成就会出来不同的图片,创意几乎无穷无尽。
先说这么多吧,学习重在持之以恒,不要撑着,后边我们慢慢再讲。
更新
Stable Diffusion WebUI 经常会修复一些BUG和增加新功能,在这里可以把它更新到最新版本。

以上就是本文的主要内容,感谢阅读。
如果想第一时间获得我的最新分享,欢迎关注dou~yin~:AI王师傅