Multi-Armed Bandit(MAB)多臂老虎机问题学习笔记
(17条消息) 推荐系统详解(六)MAB问题_ziqiiii的博客-CSDN博客_上下文多臂强盗(mab)问题
(18条消息) UCB——上界置信算法_电通一枝花的博客-CSDN博客_ucb算法
图例↑结合一起看好理解
0.场景引入
在推荐系统中,选择很困难,因为一旦选择呈现给用户,如果不能得到用户的青睐,就失去了一个展示机会。如果跳出来看这个问题,选择时不再聚焦到具体每个选项,而是去选择类别,这样压力是不是就小了很多?比如说,把推荐选择具体物品,上升到选择策略。如果后台算法中有三种策略:按照内容相似推荐,按照相似好友推荐,按照热门推荐。每次选择一种策略,确定了策略后,再选择策略中的物品,这样两个步骤。
1.随机调度问题可分为三大类:一批随机作业的调度问题, 多臂老虎机问题,排队系统的调度问题
2.多臂老虎机基本问题:
1. 有K台machine,每次选取其中一台pull the lever,该machine提供一个random的reward,每一台machine的reward服从特定的概率分布。
2. 一个gambler有N次lever pulls的机会,他的目标是使得回报reward最大化,那么他要确定这N次pull 的arm的顺序。显然,作为一个聪明的赌徒,他会记录下每一次得到的reward,试图找出能给出最大reward的那台machine,尽量多次数的去pull这台machine 的arm。
3.多臂老虎机下衍生出的问题
对于每一轮选择,主要面对的问题是Exploitation-Exploration.(以及冷启动问题)
①EE问题:上面提到过的exploit-explore问题;比如已知某用户对A产品感兴趣,那么在大多数时间要给他推送A的链接才能赚钱,这就是exploit;但是为了赚更多的钱,就需要知道他还对哪些产品感兴趣,那么在有些时候就可以尝试一下给他推送B,C,D,E等选择看用户的反应,这就是explore。
②用户冷启动问题:面对新用户时如何用尽量少的次数,猜出用户的大致兴趣
3.1 针对EE问题,Bandit 算法可以入药
Bandit 算法并不是指一个算法,而是一类算法。现在就来介绍一下 Bandit 算法家族怎么解决这类选择问题的。首先,来定义一下,如何衡量选择的好坏?Bandit 算法的思想是:看看选择会带来多少遗憾,遗憾越少越好。在 MAB 问题里,用来量化选择好坏的指标就是累计遗憾,计算公式如图所示。
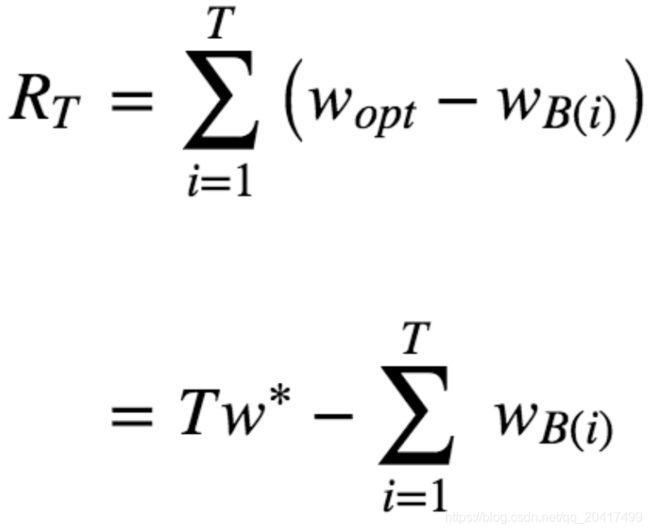
简单描述一下这个公式。公式有两部分构成:一个是遗憾,一个是累积。求和符号内部就表示每次选择的遗憾多少。
Wopt 就表示,每次都运气好,选择了最好的选择,该得到多少收益,
WBi 就表示每一次实际选择得到的收益,两者之差就是“遗憾”的量化,在 T 次选择后,就有了累积遗憾
在这个公式中:为了简化 MAB 问题,每个臂的收益不是 0,就是 1,也就是伯努利收益,对同样的多臂问题,用不同的 Bandit 算法模拟试验相同次数,比比看哪个 Bandit 算法的累积遗憾增长得慢,那就是效果较好的算法。
Bandit 算法中有几个关键元素:臂,回报,环境
1. 臂:每次推荐要选择候选池,可能是具体物品,也可能是推荐策略,也可能是物品类别;
2. 回报:用户是否对推荐结果喜欢,喜欢了就是正面的回报,没有买账就是负面回报或者零回报;
3. 环境:推荐系统面临的这个用户就是不可捉摸的环境。
Bandit算法分类介绍
①汤普森采样算法
算法原理:假设每个臂是否产生收益,起决定作用的是背后有一个概率分布,产生收益的概率为 p。每个臂背后绑定了一个概率分布(贝塔分布);每次做选择时,让每个臂的概率分布各自独立产生一个随机数,按照这个随机数排序,输出产生最大随机数那个臂对应的物品。
贝塔分布有 a 和 b 两个参数。这两个参数决定了分布的形状和位置:
1. 当 a+b 值越大,分布曲线就越窄,分布就越集中,这样的结果就是产生的随机数会容易靠近中心位置;
2. 当 a/(a+b) 的值越大,分布的中心位置越靠近 1,反之就越靠近 0,这样产生的随机数也相应第更容易靠近 1 或者 0。
在推荐系统的设计中,贝塔分布的 a 参数看成是推荐后得到用户点击的次数,把分布的 b 参数看成是没有得到用户点击的次数
②UCB算法
- 普通UCB
第二个常用的 Bandit 算法就是 UCB 算法,UCB 算法全称是 Upper Confidence Bound,即置信区间上界。置信区间可以简单直观地理解为不确定性的程度,区间越宽,越不确定,反之就很确定。每个候选的回报均值都有个置信区间,随着试验次数增加,置信区间会变窄,相当于逐渐确定了到底回报丰厚还是可怜。每次选择前,都根据已经试验的结果重新估计每个候选的均值及置信区间。选择置信区间上界最大的那个候选。
“选择置信区间上界最大的那个候选”,这句话反映了几个意思:如果候选的收益置信区间很宽,相当于被选次数很少,还不确定,那么它会倾向于被多次选择,这个是算法冒风险的部分;如果候选的置信区间很窄,相当于被选次数很多,比较确定其好坏了,那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分;UCB 是一种乐观冒险的算法,它每次选择前根据置信区间上界排序,反之如果是悲观保守的做法,可以选择置信区间下界排序。
它为每个臂评分,每次选择评分最高的候选臂输出,每次输出后观察用户反馈,回来更新候选臂的参数。每个臂的评分公式为:

公式有两部分,加号前面是这个候选臂到目前的平均收益,反应了它的效果,后面的叫做 Bonus,本质上是均值的标准差,反应了候选臂效果的不确定性,就是置信区间的上边界。t 是目前的总选择次数,Tjt 是每个臂被选择次数。
观察这个公式,如果一个候选的被选择次数很少,即 Tjt 很小,那么它的 Bonus 就会较大,在最后排序输出时有优势,这个 Bonus 反映了一个候选的收益置信区间宽度,Bonus 越大,候选的平均收益置信区间越宽,越不确定,越需要更多的选择机会
反之如果平均收益很大,就是说加号左边很大,也会在被选择时有优势。
这个评分公式也和汤普森采样是一样的思想:
1. 以每个候选的平均收益为基准线进行选择;
2. 对于被选择次数不足的给予照顾;
3. 选择倾向的是那些确定收益较好的候选。
- 进阶版-LinUCB
“Yahoo!”的科学家们在 2010 年基于 UCB 提出了 LinUCB 算法,它和传统的 UCB 算法相比,最大的改进就是加入了特征信息,每次估算每个候选的置信区间,不再仅仅是根据实验,而是根据特征信息来估算,这一点就非常的“机器学习”了。
LinUCB 算法做了一个假设:一个物品被选择后推送给一个用户,其收益和特征之间呈线性关系。在具体原理上,LinUCB 有一个简单版本以及一个高级版本。简单版本其实就是让每一个候选臂之间完全互相无关,参数不共享。高级版本就是候选臂之间共享一部分参数。
具体内容见参考文章1,或者下次我再整理一下单独发一篇
总结:LinUCB 不再是上下文无关地,像盲人摸象一样从候选臂中去选择了,而是要考虑上下文因素,比如是用户特征、物品特征和场景特征一起考虑。每一个候选臂针对这些特征各自维护一个参数向量,各自更新,互不干扰。每次选择时用各自的参数去计算期望收益和置信区间,然后按照置信区间上边界最大的输出结果。观察用户的反馈,简单说就是“是否点击”,将观察的结果返回,结合对应的特征,按照刚才公式,去重新计算这个候选臂的参数。
当 LinUCB 的特征向量始终取 1,每个候选臂的参数是收益均值的时候,LinUCB 就是 UCB。说完简单版的 LinUCB,再看看高级版的 LinUCB。与简单版的相比,就是认为有一部分特征对应的参数是在所有候选臂之间共享的,所谓共享,也就是无论是哪个候选臂被选中,都会去更新这部分参数。
③Epsilon 贪婪算法
这是一个朴素的算法,也很简单有效,思想有点类似模拟退火,做法如下。
1. 先选一个 (0,1) 之间较小的数,叫做 Epsilon,也是这个算法名字来历。
2. 每次以概率 Epsilon 做一件事:所有候选臂中随机选一个,以 1-Epsilon 的概率去选择平均收益最大的那个臂。
是不是简单粗暴?Epsilon 的值可以控制对探索和利用的权衡程度。这个值越接近 0,在探索上就越保守。
3.2 处理冷启动问题
推荐系统冷启动问题可以用 Bandit 算法来解决一部分。大致思路如下:
1. 用分类或者 Topic 来表示每个用户兴趣,我们可以通过几次试验,来刻画出新用户心目中对每个 Topic 的感兴趣概率。
2. 这里,如果用户对某个 Topic 感兴趣,就表示我们得到了收益,如果推给了它不感兴趣的 Topic,推荐系统就表示很遗憾 (regret) 了。
3. 当一个新用户来了,针对这个用户,我们用汤普森采样为每一个 Topic 采样一个随机数,排序后,输出采样值 Top N 的推荐 Item。注意,这里一次选择了 Top N 个候选臂。
4. 等着获取用户的反馈,没有反馈则更新对应 Topic 的 b 值,点击了则更新对应 Topic 的 a 值
参考文章:
(17条消息) 推荐系统详解(六)MAB问题_ziqiiii的博客-CSDN博客_上下文多臂强盗(mab)问题(17条消息) 推荐系统详解(六)MAB问题_ziqiiii的博客-CSDN博客_上下文多臂强盗(mab)问题(17条消息) 推荐系统详解(六)MAB问题_ziqiiii的博客-CSDN博客_上下文多臂强盗(mab)问题
关于Multi-Armed Bandit(MAB)问题及算法 - 简书 (jianshu.com)