Apache Hive详解
目录
一、引入
Hive简介
为什么要使用Hive
Hive的特点
Hive的发展历程
二、Hive架构体系
三、MySQL安装
安装准备
安装
卸载(了解)
四、Hive集群搭建
准备工作
安装过程
五、Hive的MySQL元数据库与表
六、Hive库操作
七、Hive表操作
八、Hive查询结果四大排序
九、Hive函数
内置函数
关系运算符
算术运算符
逻辑运算符
复数运算符
Hive常用内置函数
一、引入
Hive简介
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
我们可以将hive想象成mysql,他就是对hdfs存储的数据进行增删改查的。
比如要计算user.txt中用户们出现了几次,我们来看看hive的实现过程:
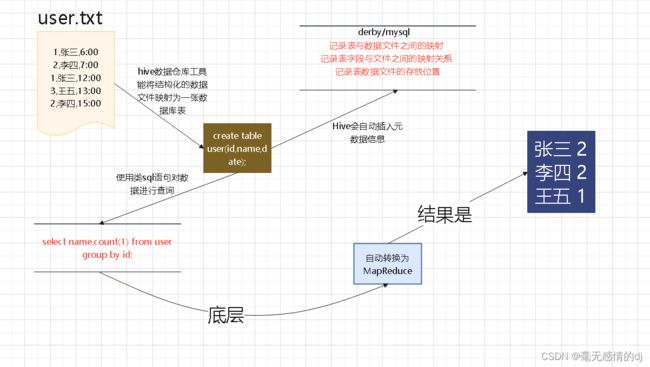
为什么要使用Hive
为什么不直接使用Hadoop
- 人员学习成本高
- 项目要求周期短
- MapReduce实现复杂查询逻辑开发难度大
为什么使用Hive
- 操作接口采用SQL语法,提供快速开发能力
- 免去了写MapReduce,减少开发人员学习成本
- 功能扩展很方便
Hive的特点
- hive延迟高,适合高吞吐量,批量,海量数据处理
- 语法和SQL相似,学习成本低,避免去写复杂的MapReduce,缩短开发周期
- Hive支持自由的扩展集群的规模,一般不需要重启服务
- Hive支持自定义函数,用户可以根据自己的需求去定义函数
- 良好的容错性,节点出现问题,SQL仍然可以成功执行
Hive的发展历程
在Hive的发展历程中,不得不提的就是Stinger
Stinger不是一个项目或产品,而是一种提议,旨在将Hive性能提升100倍,包括Hive的改进和Tez项目两个部分。
Stinger分了几个阶段来做:Phase 1、2、3 ,Stringer.next;这几个阶段对Hive性能的提升是非常至关重要的
07/08 facebook
13/05 hive-0.11 Stinger Phase 1 加入了ORC/HiveServer2
13/10 hive-0.12 Stinger Phase 2 ORC improvement(对ORC做了些改善)
14/04 hive-0.13 Stinger Phase 3 Tez/Vectorized query engine(加入了Tez和支持向量化的查询)
14/11 hive-0.14 Stinger.next Phase 1 Cost-based optimizer(Cost-based简称CBO) (Cost-based的优化 很牛逼 算法各方面的优化 Spark现在也在做)
…… …….
当时有一句话:The Stinger Initiative making Apache Hive 100 times faster
二、Hive架构体系

Hive的体系结构主要分为以下几个部分:
- 用户接口
- 用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是 Cli,Cli 启动的时候,会同时启动一个 hive 副本。Client 是 hive 的客户端,用户连接至 hive Server。在启动 Client 模式的时候,需要指出 hive Server 所在节点,并且在该节点启动 hive Server。 WUI 是通过浏览器访问 hive。
- 元数据存储
- hive 将元数据存储在数据库中,如 mysql、derby。hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器、执行器
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
- Hadoop
- hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(不包含 * 的查询,比如 select * from tbl 不会生成 MapReduce 任务)。
三、MySQL安装
为什么学Hive还要安装MySQL:
- metastore是hive元数据的集中存放地
- metastore默认使用内嵌的derby数据库作为存储引擎
- 但是你在哪路径下,执行hive指令,就在哪路径下生成metastore_db。建一套数据库文件,这样是极其不合适的,公司里每个人若不一样,则会显得非常混杂。导致员工之间无法公用交流。
- Derby引擎的缺点:一次只能打开一个会话
- 使用Mysql作为外置存储引擎,多用户同时访问
hive只是个工具,包括它的数据分析,依赖于mapreduce,它的数据管理,依赖于外部系统;
Hive提供了增强配置,可将数据库替换成mysql等关系型数据库,将存储数据独立出来在多个服务示例之间共享。
这也是为什么,在安装hive时,也需要配置mysql了。
安装准备
- 1、检查是否已经安装过mysql,执行命令
- rpm -qa | grep mysql
- 如果已存在,则执行删除命令 后边为Mysql目录
- rpm -e --nodeps mysql-xxxx
- 2、查询所有Mysql对应的文件夹
- whereis mysqlm
- find / -name mysql
- 删除相关目录或文件
- rm -rf /usr/bin/mysql /usr/include/mysql /data/mysql /data/mysql/mysql
- 验证是否删除完毕
- whereis mysqlm
- find / -name mysql
确保先执行以下命令:
systemctl stop firewalld #关闭防火墙
安装perl与net-tools依赖
1:yum install net-tools -y
2:yum install perl* -y
安装
下载地址:MySQL :: Download MySQL Community Server
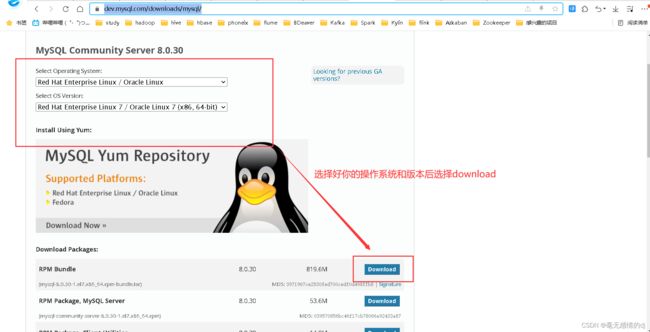
上传安装包后创建目录放置解压包:mkdir /opt/mysql
解压:tar -xvf mysql-8.0.26-1.el7.x86_64.rpm-bundle.tar -C /opt/mysql
可以看到解压后的文件都是 rpm 文件,所以需要用到 rpm 包资源管理器相关的指令安装这些 rpm 的安装包
在安装执行 rpm 安装包之前先下载 openssl-devel 插件,因为 mysql 里面有些 rpm 的安装依赖于该插件。
yum install openssl-devel
安装完该插件之后,依次执行以下命令安装这些 rpm 包
- rpm -ivh mysql-community-common-8.0.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-client-plugins-8.0.26-1.el7.x86_64.rpm
- rpm -e mariadb-libs --nodeps #解决下一行代码可能会出现的
依赖检测失败错误- rpm -ivh mysql-community-libs-8.0.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-libs-compat-8.0.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-devel-8.0.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-client-8.0.26-1.el7.x86_64.rpm
- rpm -ivh mysql-community-server-8.0.26-1.el7.x86_64.rpm
在 Linux 中 MySQL 安装好了之后系统会自动的注册一个服务,服务名称叫做 mysqld,所以可以通过以下命令操作 MySQL:
- 启动 MySQL 服务:systemctl start mysqld
- 重启 MySQL 服务:systemctl restart mysqld
- 关闭 MySQL 服务:systemctl stop mysqld
启动服务:systemctl start mysqld
现在我们就可以登录MySQL了,但是登录MySQL需要密码对不对,不要慌,rpm 安装 MySQL 会自动生成一个随机密码,可在 /var/log/mysqld.log 这个文件中查找该密码(切记:如果之前你的机器上mysql没有删除干净,现在这个文件就是空的):
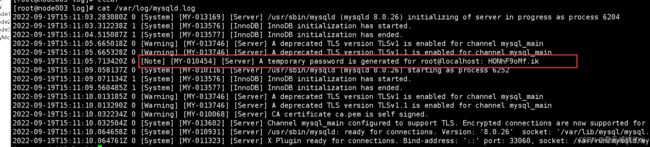
[Note] [MY-010454] [Server] A temporary password is generated for root@localhost: HONhF9oMf.ik
我这里生成的随机密码是HONhF9oMf.ik
登录:
mysql -u root -p

我们先修改密码(在当前登录成功页执行代码):
# 将密码复杂度校验调整简单类型
set global validate_password.policy=0; #分号不可少
# 设置密码最少位数限制为 4 位
set global validate_password.length=4; #分号不可少# 设置新密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; #分号不可少
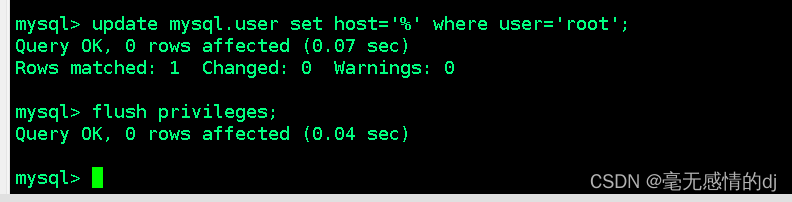
修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
update mysql.user set host='%' where user='root';
flush privileges; #重新加载权限表
 卸载(了解)
卸载(了解)
卸载 MySQL 前需要先停止 MySQL
命令:systemctl stop mysqld
停止 MySQL 之后查询 MySQL 的安装文件:rpm -qa | grep -i mysql
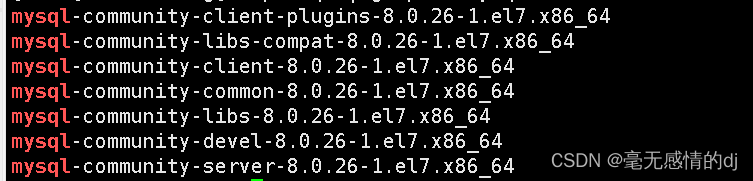
卸载上述查询出来的所有的 MySQL 安装包
rpm -e mysql-community-client-plugins-8.0.26-1.el7.x86_64 --nodeps
rpm -e mysql-community-server-8.0.26-1.el7.x86_64 --nodeps
rpm -e mysql-community-common-8.0.26-1.el7.x86_64 --nodeps
rpm -e mysql-community-libs-8.0.26-1.el7.x86_64 --nodeps
rpm -e mysql-community-client-8.0.26-1.el7.x86_64 --nodeps
rpm -e mysql-community-libs-compat-8.0.26-1.el7.x86_64 --nodeps
删除MySQL的数据存放目录
rm -rf /var/lib/mysql/
删除MySQL的配置文件备份
rm -rf /etc/my.cnf.rpmsave
四、Hive集群搭建
准备工作
注:在Hive集群搭建之前需完成Hadoop-HDFS详解与HA,完全分布式集群搭建(细到令人发指的教程)
下载hive安装包:Index of /dist/hive
下载mysql连接java驱动:Download mysql-connector-java-5.1.23-bin.jar : mysql « m « Jar File Download
这里以apache-hive-3.1.2-bin.tar.gz 为例;
将压缩包上传至node001节点上

安装过程
解压安装包
解压:tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/
重命名:mv /opt/apache-hive-3.1.2-bin/ /opt/hive-3.1.2
配置环境变量
终端输入:vim /etc/profile
末行加入:
export HIVE_HOME=/opt/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbinsource /etc/profile
hive-env.sh
终端输入:vim /opt/hive-3.1.2/conf/hive-env.sh
末行加入:
export HADOOP_HOME=/opt/hadoop-3.1.2
export HIVE_CONF_DIR=/opt/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/opt/hive-3.1.2/libhive-site.xml
终端输入:vim /opt/hive-3.1.2/conf/hive-site.xml
添加配置:
javax.jdo.option.ConnectionURL
jdbc:mysql://node001:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
datanucleus.schema.autoCreateAll
true
hive.metastore.schema.verification
false
hive.cli.print.header
true
hive.cli.print.current.db
true
hive.server2.webui.host
node001
hive.server2.webui.port
10002
hive.metastore.warehouse.dir
/hive/warehouse
配置日志组件
首先添加放置日志文件的目录:mkdir -p /opt/hive-3.1.2/logs
复制log4j模板文件:
cp /opt/hive-3.1.2/conf/hive-log4j2.properties.template hive-log4j2.properties
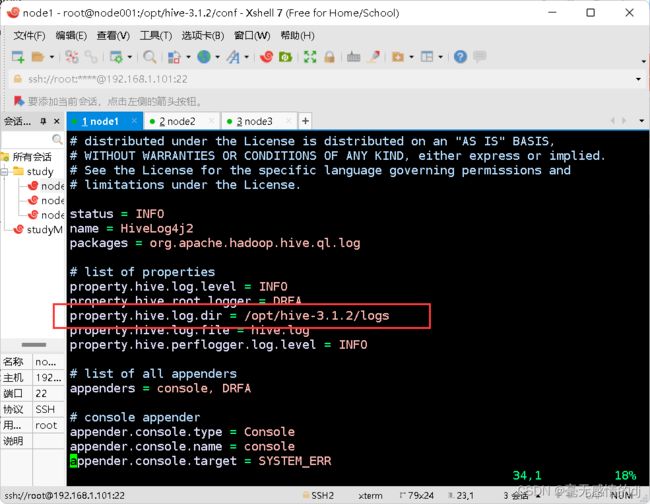
终端输入:vim /opt/hive-3.1.2/conf/hive-log4j2.properties
将/opt/hive-3.1.2/logs添加到property.hive.log.dir
core-site.xml
终端输入:vim /opt/hadoop-3.1.2/etc/hadoop/core-site.xml
添加配置:
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*

添加驱动包
MySQL驱动
mysql-connector-java-5.1.23-bin.jar.zip,下载地址见上文
将其上传到/opt/hive-3.1.2/lib目录
执行:unzip mysql-connector-java-5.1.23-bin.jar.zip #进行解压
Guava包
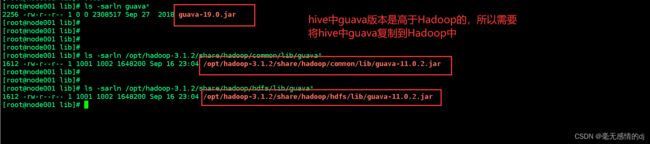
删除hadoop中guava-*.jar包
rm -rf /opt/hadoop-3.1.2/share/hadoop/common/lib/guava*
rm -rf /opt/hadoop-3.1.2/share/hadoop/hdfs/lib/guava*
将Hive的Guava拷贝给hadoop
cp /opt/hive-3.1.2/lib/guava-19.0.jar /opt/hadoop-3.1.2/share/hadoop/common/lib/
cp /opt/hive-3.1.2/lib/guava-19.0.jar /opt/hadoop-3.1.2/share/hadoop/hdfs/lib/
分发
拷贝hive到其他节点
scp -r /opt/hive-3.1.2/ node002:/opt/
scp -r /opt/hive-3.1.2/ node003:/opt/
拷贝profile到其他节点
scp /etc/profile node002:/etc/
scp /etc/profile node003:/etc/
ssh root@node002 "source /etc/profile"
ssh root@node003 "source /etc/profile"
拷贝core-site.xml到其他节点
scp /opt/hadoop-3.1.2/etc/hadoop/core-site.xml node002:/opt/hadoop-3.1.2/etc/hadoop/
scp /opt/hadoop-3.1.2/etc/hadoop/core-site.xml node003:/opt/hadoop-3.1.2/etc/hadoop/
guava
进入node002节点
# 删除hadoop中guava-*.jar包
[root@node002 ~]# rm -rf /opt/hadoop-3.1.2/share/hadoop/common/lib/guava*
[root@node002 ~]# rm -rf /opt/hadoop-3.1.2/share/hadoop/hdfs/lib/guava*# 将Hive的Guava拷贝给hadoop
[root@node002 ~]# cp /opt/hive-3.1.2/lib/guava-19.0.jar /opt/hadoop-3.1.2/share/hadoop/common/lib/
[root@node002 ~]# cp /opt/hive-3.1.2/lib/guava-19.0.jar /opt/hadoop-3.1.2/share/hadoop/hdfs/lib/
guava
进入node003节点
# 删除hadoop中guava-*.jar包
[root@node003 ~]# rm -rf /opt/hadoop-3.1.2/share/hadoop/common/lib/guava*
[root@node003 ~]# rm -rf /opt/hadoop-3.1.2/share/hadoop/hdfs/lib/guava*# 将Hive的Guava拷贝给hadoop
[root@node003 ~]# cp /opt/hive-3.1.2/lib/guava-19.0.jar /opt/hadoop-3.1.2/share/hadoop/common/lib/
[root@node003 ~]# cp /opt/hive-3.1.2/lib/guava-19.0.jar /opt/hadoop-3.1.2/share/hadoop/hdfs/lib/
客户端配置文件
修改node002与node003的hive-site.xml
如果不修改将会造成脑裂。
终端输入:vim /opt/hive-3.1.2/conf/hive-site.xml
修改为:
datanucleus.schema.autoCreateAll
false
hive.metastore.schema.verification
false
hive.cli.print.header
true
hive.cli.print.current.db
true
hive.server2.webui.host
node001
hive.server2.webui.port
10002
hive.metastore.warehouse.dir
/hive/warehouse
hive.metastore.uris
thrift://node001:9083
初始化元数据(很重要):
schematool -initSchema -dbType mysql
使用测试
在启动hive之前确保先启动zookeeper与Hadoop集群
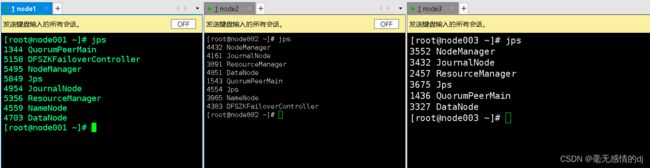
启动:Hive服务
在node001输入:hive --service metastore
在node002或者node003输入:hive

node002或node003执行:show databases; 进行测试
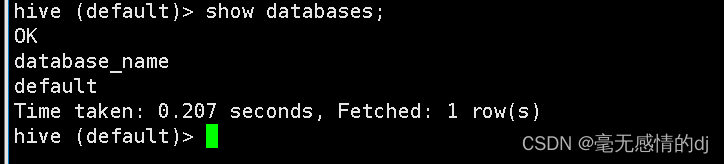
到此hive搭建成功!
五、Hive的MySQL元数据库与表
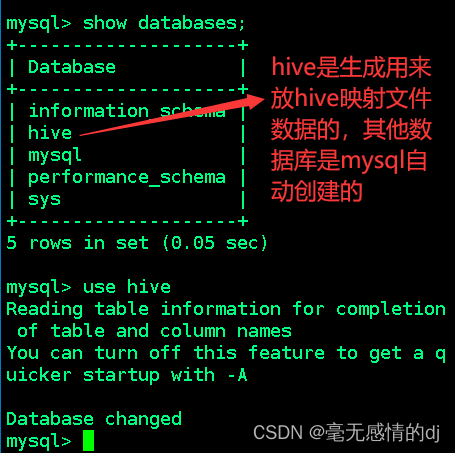
hive这个数据库并不是自动创建的而是通过上文hive-site.xml配置文件所决定的。
javax.jdo.option.ConnectionURL
jdbc:mysql://node001:3306/hive?createDatabaseIfNotExist=true
通过show tables; 可以看到hive自动创建的一些表
mysql> show tables;
+-------------------------------+
| Tables_in_hive |
+-------------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| CTLGS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| I_SCHEMA |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| MATERIALIZATION_REBUILD_LOCKS |
| METASTORE_DB_PROPERTIES |
| MIN_HISTORY_LEVEL |
| MV_CREATION_METADATA |
| MV_TABLES_USED |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NEXT_WRITE_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| REPL_TXN_MAP |
| ROLES |
| ROLE_MAP |
| RUNTIME_STATS |
| SCHEMA_VERSION |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TXN_TO_WRITE_ID |
| TYPES |
| TYPE_FIELDS |
| VERSION |
| WM_MAPPING |
| WM_POOL |
| WM_POOL_TO_TRIGGER |
| WM_RESOURCEPLAN |
| WM_TRIGGER |
| WRITE_SET |
+-------------------------------+
74 rows in set (0.00 sec)
Hive元数据中一些重要的表结构与用途:方便impala,SparkSQL,Hive等组件访问元数据库的理解。
1、存储Hive版本的元数据表(VERSION)
- 该表结构简单却是很重要的
- 如果该表出现问题,根本进入不了Hive-Cli,当该表不存在的情况,就会报错"Table 'hive.version' doesn't exist"
- 该表中数据只能有一条,如果存在多条,会造成hive启动不起来
表结构如下:
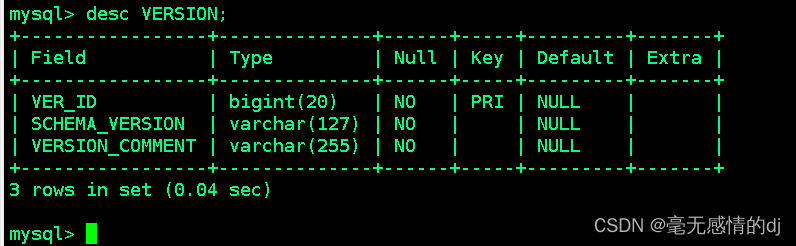
| 字段名 | 说明 | 示例数据 |
| VER_ID | ID主键 | 1 |
| SCHEMA_VERSION | hive版本 | 1.1.1 |
| VERSION_COMMENT | 版本说明 | Updated the data |
2、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
DBS:数据库表
- 该表存储Hive中所有数据库的基本信息
表结构如下:

| 字段名 | 说明 | 示例数据 |
| DB_ID | 数据库ID | 1 |
| CTLG_NAME | 目录名 | hive |
| DESC | 数据库描述 | Default Hive database |
| DB_LOCATION_URI | 数据HDFS路径 | hdfs://bdp/hive/warehouse |
| NAME | 数据库名 | default |
| OWNER_NAME | 所有者名称 | public |
| OWNER_TYPE | 所有者角色 | ROLE |
DATABASE_PARAMS:该表存储数据库的相关参数,在CREATE DATABASE时候用WITH DBPROPERTIES(property_name=property_value, …)指定的参数。
表结构如下:
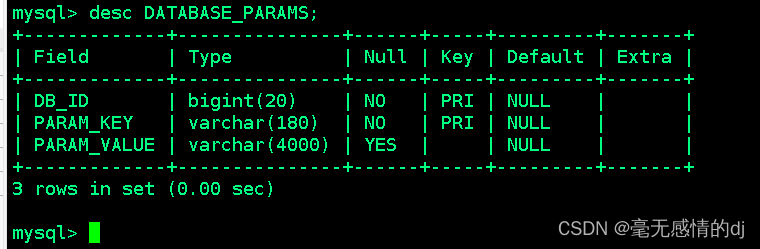
| 字段名称 | 说明 | 示例数据 |
| DB_ID | 数据库ID | 1 |
| PARAM_KEY | 参数名 | createdby |
| PARAM_VALUE | 参数值 | root |
DBS和DATABASE_PARAMS这两张表通过DB_ID字段关联。
3、Hive数据表相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。
TBLS:该表中存储Hive表,视图,索引表的基本信息
表结构如下:

| 字段名 | 说明 | 示例数据 |
| TBL_ID | 表ID | 1 |
| CREATE_TIME | 创建时间 | 5678542364 |
| DB_ID | 数据库ID | 2(对应DBS中DB_ID) |
| LAST_ACCESS_TIME | 最后访问时间 | 6485123468 |
| OWNER | 所有者 | root |
| OWNER_TYPE | 使用者角色 | ROLE |
| RETENTION | 保留字段 | 0 |
| IS_REWRITE_ENABLED | 是否覆盖启用 | 0 |
| SD_ID | 序列化配置信息 | 86(对应SDS中SD_ID) |
| TBL_NAME | 表名 | ex_detail_ufdr_30streaming |
| TBL_TYPE | 表类型 | MANAGED_TABLE、EXTERNAL_TABLE、INDEX_TABLE、VIRTUAL_YABLE |
| VIEW_EXPANDED_TEXT | 视图的详细HQL语句 | select 字段1,字段2,字段3 from ex_detail_ufdr_30streaming; |
| VIEW_ORIGINAL_TEXT | 视图的原始HQL语句 | select * from ex_detail_ufdr_30streaming; |
TABLE_PARAMS:数据表属性信息表
该表存储表/视图的属性信息
表结构入下:
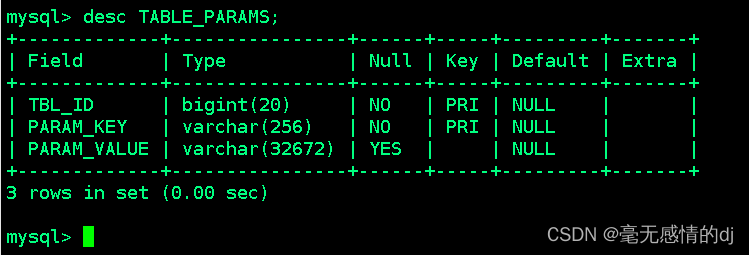
| 字段名 | 说明 | 示例数据 |
| TBL_ID | 表ID | 1 |
| PARAM_KEY | 属性名 | totalSize、numRows、EXTERNAL |
| PARAM_VALUE | 属性值 | 578436548、12458967、TRUE |
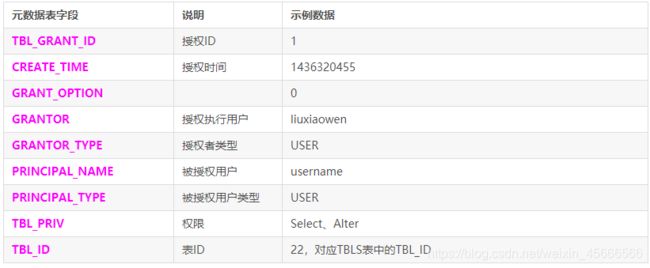
TBL_PRIVS:授权表
该表存储表/视图的授权信息
4、Hive文件存储信息相关的元数据表
由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。
表结构如下:
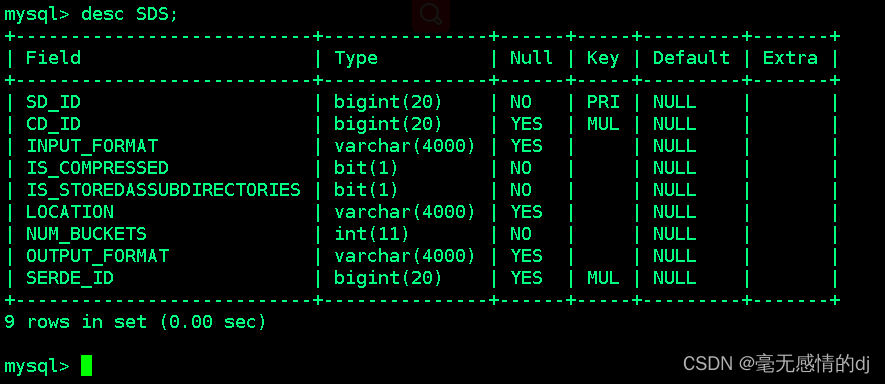
| 字段名 | 说明 | 示例数据 |
| SD_ID | 存储信息ID | 1 |
| CD_ID | 字段信息ID | 21(对应CDS表) |
| INPUT_FORMAT | 文件输入格式 | org.apache.hadoop.mapred. TextInputFormat |
| IS_COMPRESSED | 是否压缩 | 0 |
| IS_STOREDASSUBDIRECTORIES | 是否以子目录存储 | 0 |
| LOCATION | HDFS路径 | hdfs://192.168.1.101:9000/ detail_ufdr_streaming_test |
| NUM_BUCKETS | 分桶数量 | 5 |
| OUTPUT_FORMAT | 文件输出格式 | org.apache.hadoop.hive.ql.io. HiveIgnoreKeyTextOutputFormat |
| SERDE_ID | 序列化ID | 3(对应SERDES表) |
SD_PARAMS: 该表存储Hive存储的属性信息,在创建表时候使用STORED BY ‘storage.handler.class.name’ [WITH SERDEPROPERTIES (…)指定。
表结构如下:

| 字段名 | 说明 | 示例数据 |
| SD_ID | 存储配置ID | 1 |
| PARAM_KEY | 属性名 | |
| PARAM_VALUE | 属性值 |
SERDES:该表存储序列化使用的类信息
表结构如下:

| 字段名 | 说明 | 示例数据 |
| SERDE_ID | 序列化配置ID | 1 |
| DESCRIPTION | 描述 | |
| DESERIALIZER_CLASS | 并行类 | |
| NAME | 名字 | |
| SERDE_TYPE | 序列化类型 | |
| SLIB | 系统库 | |
| SERIALIZER_CLASS | 序列化类 |
SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符
表结构如下:
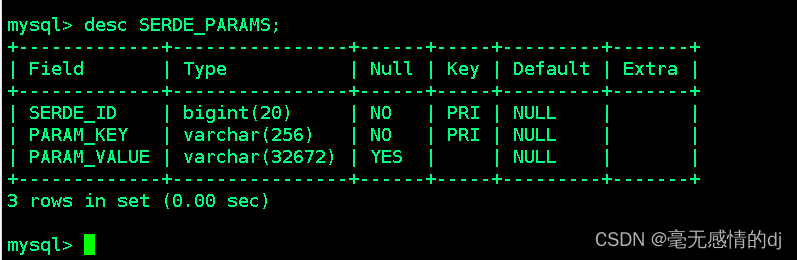
| 字段名 | 说明 | 示例数据 |
| SERDE_ID | 序列化配置ID | 1 |
| PARAM_KEY | 属性名 | |
| PARAM_VALUE | 属性值 |
5、Hive表字段相关的元数据表
COLUMNS_V2:该表存储表对应的字段信息
表结构如下:
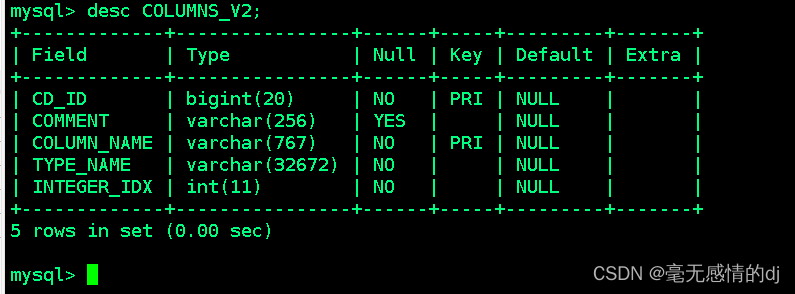
| 字段名 | 说明 | 示例数据 |
| CD_ID | 字段信息ID | 212 |
| COMMENT | 字段注释 | NULL |
| COLUMN_NAME | 字段名 | air_port_duration |
| TYPE_NAME | 字段类型名 | bigint |
| INTEGER_IDX | 字段顺序 | 119 |
6、Hive表分分区相关的元数据表
主要涉及PARTITIONS、PARTITION_KEYS、PARTITION_KEY_VALS、PARTITION_PARAMS
PARTITIONS:该表存储表分区的基本信息
表结构如下:
mysql> show create table PARTITIONS;
+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PARTITIONS | CREATE TABLE `PARTITIONS` (
`PART_ID` bigint(20) NOT NULL,
`CREATE_TIME` int(11) NOT NULL,
`LAST_ACCESS_TIME` int(11) NOT NULL,
`PART_NAME` varchar(767) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`SD_ID` bigint(20) DEFAULT NULL,
`TBL_ID` bigint(20) DEFAULT NULL,
PRIMARY KEY (`PART_ID`),
UNIQUE KEY `UNIQUEPARTITION` (`PART_NAME`,`TBL_ID`),
KEY `PARTITIONS_N50` (`SD_ID`),
KEY `PARTITIONS_N49` (`TBL_ID`),
CONSTRAINT `PARTITIONS_FK1` FOREIGN KEY (`SD_ID`) REFERENCES `SDS` (`SD_ID`),
CONSTRAINT `PARTITIONS_FK2` FOREIGN KEY (`TBL_ID`) REFERENCES `TBLS` (`TBL_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
PARTITION_KEYS:该表存储分区的字段信息。
表结构如下:
mysql> show create table PARTITION_KEYS;
+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PARTITION_KEYS | CREATE TABLE `PARTITION_KEYS` (
`TBL_ID` bigint(20) NOT NULL,
`PKEY_COMMENT` varchar(4000) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`PKEY_NAME` varchar(128) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`PKEY_TYPE` varchar(767) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`INTEGER_IDX` int(11) NOT NULL,
PRIMARY KEY (`TBL_ID`,`PKEY_NAME`),
KEY `PARTITION_KEYS_N49` (`TBL_ID`),
CONSTRAINT `PARTITION_KEYS_FK1` FOREIGN KEY (`TBL_ID`) REFERENCES `TBLS` (`TBL_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+----------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
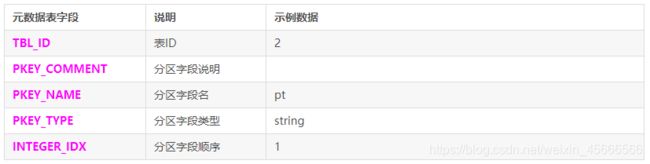
PARTITION_KEY_VALS:该表存储分区字段值
表结构如下:
mysql> show create table PARTITION_KEY_VALS;
+--------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PARTITION_KEY_VALS | CREATE TABLE `PARTITION_KEY_VALS` (
`PART_ID` bigint(20) NOT NULL,
`PART_KEY_VAL` varchar(255) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
`INTEGER_IDX` int(11) NOT NULL,
PRIMARY KEY (`PART_ID`,`INTEGER_IDX`),
KEY `PARTITION_KEY_VALS_N49` (`PART_ID`),
CONSTRAINT `PARTITION_KEY_VALS_FK1` FOREIGN KEY (`PART_ID`) REFERENCES `PARTITIONS` (`PART_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+--------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)

PARTITION_PARAMS:该表存储分区的属性信息
表结构如下:
mysql> show create table PARTITION_PARAMS;
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PARTITION_PARAMS | CREATE TABLE `PARTITION_PARAMS` (
`PART_ID` bigint(20) NOT NULL,
`PARAM_KEY` varchar(256) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`PARAM_VALUE` varchar(4000) CHARACTER SET latin1 COLLATE latin1_bin DEFAULT NULL,
PRIMARY KEY (`PART_ID`,`PARAM_KEY`),
KEY `PARTITION_PARAMS_N49` (`PART_ID`),
CONSTRAINT `PARTITION_PARAMS_FK1` FOREIGN KEY (`PART_ID`) REFERENCES `PARTITIONS` (`PART_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)

7、其他不常用的元数据表
- DB_PRIVS
- 数据库权限信息表。通过GRANT语句对数据库授权后,将会在这里存储。
- IDXS
- 索引表,存储Hive索引相关的元数据
- INDEX_PARAMS
- 索引相关的属性信息
- TBL_COL_STATS
- 表字段的统计信息。使用ANALYZE语句对表字段分析后记录在这里
- TBL_COL_PRIVS
- 表字段的授权信息
- PART_PRIVS
- 分区的授权信息
- PART_COL_PRIVS
- 分区字段的权限信息
- PART_COL_STATS
- 分区字段的统计信息
- FUNCS
- 用户注册的函数信息
- FUNC_RU
- 用户注册函数的资源信息
六、Hive库操作
创建数据库
create database test; # 创建名字为test的数据库
create database if not exists test; # 如果test数据库不存在就创建,存在就什么也不做
create database dbname location '路径'; #通过location指定数据库路径
create database dbname comment '描述信息'; #给数据库添加描述信息
查看数据库
show databases; # 展示所有数据库
show databases like 'haha*'; # 模糊匹配like; 显示包含haha前缀的数据库名称
切换数据库
use test; # 从当前数据库切换到test数据库
删除数据库
drop database test; # 删除test数据库
drop database if exists test; # 如果test数据库存在就删除否则什么也不做
drop database test cascade; # 强制删除test数据库
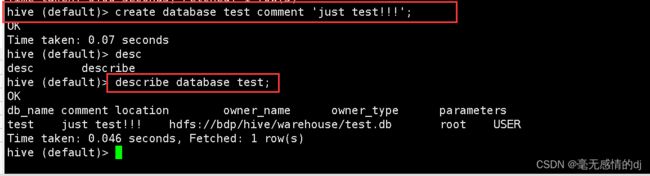
查看数据库的详细描述
desc database test; # 查看test数据库的详细信息
describe database test; # 查看test数据库的详细信息
七、Hive表操作
显示数据库中的表
show tables; # 显示所有表
show tables like 'tab_*'; # 显示tab_开头的所有表
show tables 'tab_*'; # 显示tab_开头的所有表
desc tab_name; # 显示表的详细信息
describe tab_name; # 显示表的详细信息
创建表
建表语法:
create [external] table [if not exists] table_name (
col_name data_type [comment '字段描述信息']
col_name data_type [comment '字段描述信息'])
[comment '表的描述信息']
[location '指定表的路径']
[partitioned by (col_name data_type,...)]
[clustered by (col_name,col_name,...)]
[sorted by (col_name [asc|desc],...) into num_buckets buckets]
[row format row_format]
[location location_path]其中中括号[ ]里面为可选参数;发现其最简单的建表语句是:
create table 表名(字段名 字段类型)
简单的表创建
create table tab_test(name string, age int);
指定字段分隔符
create table tab_test(name string,age int)
row format delimited fields terminated by ',';
创建外部表
create external table tab_test(name string,age int)
row format delimited fields terminated by ',';
外部表和普通表(内部表)的区别:
- 外部表有external修饰,表数据保存在hdfs上,该位置由用户指定。删除表时,只会删除表的元数据,所以外部表不是由Hive完全管理的
- 普通表没有external修饰,表数据保存在Hive默认的路径下,数据完全由Hive管理,删除表时元数据和表数据都会一起删除。
使用场合
- 希望做数据备份并且不经常改变的数据,存放在外部表可以减少失误操作
- 数据清洗转换后的中间结果,可以存放在内部表,因为Hive对内部表支持的功能比较全面,方便管理
- 处理完成的数据由于需要共享,可以存储在外部表,这样能够防止失误操作,增加数据的安全性
创建分区表
create table tab_part(name string,age int)
partitioned by (sex string)
row format delimited fields terminated by ',';
- 分区表指的是在创建表时指定的partition的分区空间。
- partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
创建表,指定location
create table tab_location(name string,age int)
row format delimited fields terminated by ','
location 'hdfs://192.168.1.101:9000/user/hive/tables/';
创建带桶的表
create table student(id int,name string,age int)
partitioned by (sex string)
clustered by(id)
sorted by (age) into 2 buckets
row format delimited fields terminated by ',';
-
分桶是相对分区进行更细粒度的划分。
-
分桶将整个数据内容按照某列属性值取 hash 值进行区分,具有相同 hash 值的数据进入到同一个文件中。
作用是
- 取样 sampling 更高效。没有分区的话需要扫描整个数据集。
- 提升某些查询操作效率,例如 map side join
修改表
添加分区
# 按照sex='male',sex='female'进行分区
alter table student add partition(sex='male') partition(sex='female');
删除分区
alter table student drop partition(sex='male');
重命名表
alter table table_name rename to new_table_name;
增加列
alter table student add columns (rank string);
或者
alter table student replace columns (height string);
删除表
drop table tab_name;
drop table if exists tab_name;
八、Hive查询结果四大排序
- order by
- order by是全局排序,会将所有的数据分发到一个reduce中去。
- sort by
- sort by 是对每个reduce中的数据进行排序,确保单个reduce中的数据都是有序的,这样后续对数据使用一次归并排序就可确保数据全局有序。
- distribute by
- distribute by 会将数据按照字段进行hash,确保相同内容的数据都分发到同一个reduce中,一般配合 sort by 字段使用。
- cluster by
- cluster by 相当于 distribute by 和 sort by 合用,不过 cluster by 只能使用升序排列。
九、Hive函数
Hive 中的函数,分三种:
- UDF
(一进一出,普通函数) - UDTF
(多进一出,聚合函数) - UDAF
(一进多出,炸裂函数)
内置函数
关系运算符
| 操作符 | 操作数 | 描述 |
|---|---|---|
| A = B | 所有原始类型 | 如果表达式A等于表达式B,则为TRUE,否则为FALSE。 |
| A != B | 所有原始类型 | 如果表达式A不等于表达式B,则为TRUE,否则为FALSE。 |
| A < B | 所有原始类型 | 如果表达式A小于表达式B,则为TRUE,否则为FALSE。 |
| A <= B | 所有原始类型 | 如果表达式A小于或等于表达式B,则为TRUE,否则为FALSE。 |
| A > B | 所有原始类型 | 如果表达式A大于表达式B,则为TRUE,否则为FALSE。 |
| A >= B | 所有原始类型 | 如果表达式A大于或等于表达式B,则为TRUE,否则为FALSE。 |
| A IS NULL | 所有类型 | 如果表达式A的计算结果为NULL,则为TRUE,否则为FALSE。 |
| A IS NOT NULL | 所有类型 | 如果表达式A的计算结果为NULL,则为FALSE,否则为TRUE。 |
| A LIKE B | String | 如果字符串模式A与B匹配,则为TRUE,否则为FALSE。 |
| A RLIKE B | String | 如果A或B为NULL,则为NULL;如果A的任何子字符串与Java正则表达式B匹配,则为TRUE;否则为FALSE。 |
| A REGEXP B | String | 与RLIKE相同。 |
算术运算符
| 操作符 | 操作数 | 描述 |
|---|---|---|
| A + B | 所有数字类型 | 给出将A和B相加的结果。 |
| A - B | 所有数字类型 | 给出从A减去B的结果。 |
| A * B | 所有数字类型 | 给出A和B相乘的结果。 |
| A / B | 所有数字类型 | 给出将B除以A的结果。 |
| A % B | 所有数字类型 | 给出由A除以B产生的余数。 |
| A & B | 所有数字类型 | 给出A和B的按位与的结果。 |
| A | B | 所有数字类型 | 给出A和B的按位或的结果。 |
| A ^ B | 所有数字类型 | 给出A和B的按位XOR(异或)结果。 |
| ~A | 所有数字类型 | 给出A的按位NOT的结果。 |
逻辑运算符
| 操作符 | 操作数 | 描述 |
|---|---|---|
| A AND B | 布尔值 | 如果A和B均为TRUE,则为TRUE,否则为FALSE。 |
| A && B | 布尔值 | 与A和B相同。 |
| A OR B | 布尔值 | 如果A或B或两者均为TRUE,则为TRUE,否则为FALSE。 |
| A || B | 布尔值 | 与A或B相同。 |
| NOT A | 布尔值 | 如果A为FALSE,则为TRUE,否则为FALSE。 |
| !A | 布尔值 | 与NOT A相同。 |
复数运算符
| 操作符 | 操作数 | 描述 |
|---|---|---|
| A[n] | A 是一个数组,n是一个整数 | 它返回数组A中的第n个元素。第一个元素的索引为0。 |
| M[key] | M 是Map |
它返回对应于映射中键的值。 |
| S.x | S 是一个结构 | 它返回S的x字段。 |
Hive常用内置函数
查看系统自带的函数(内置函数)
show functions;
默认内置了 289 个函数。通过命令desc function 函数名可以查看自带函数的描述;desc function extended 函数名可查看自带函数详细的用法。
# 1.查看函数描述
hive (test)> desc function upper;
OK
tab_name
upper(str) - Returns str with all characters changed to uppercase
Time taken: 0.014 seconds, Fetched: 1 row(s)
# 2.查看函数详细用法
hive (test)> desc function extended upper;
OK
tab_name
upper(str) - Returns str with all characters changed to uppercase
Synonyms: ucase
Example:
> SELECT upper('Facebook') FROM src LIMIT 1;
'FACEBOOK'
Function class:org.apache.hadoop.hive.ql.udf.generic.GenericUDFUpper
Function type:BUILTIN
Time taken: 0.066 seconds, Fetched: 7 row(s)
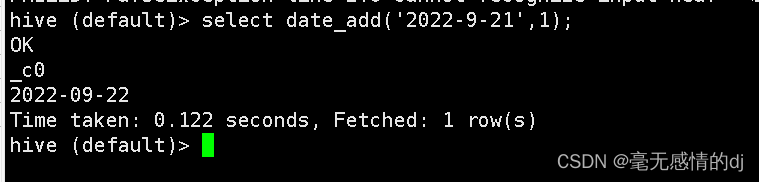
- date_add、date_sub函数(加减天数)
select date_add('2022-9-21',1); # 第一个参数是具体日期,第二个参数是执行加操作的天数
- date_format函数
select date_format('2022-9-21','yyyy-MM-dd HH:mm:ss'); # 日期格式化操作

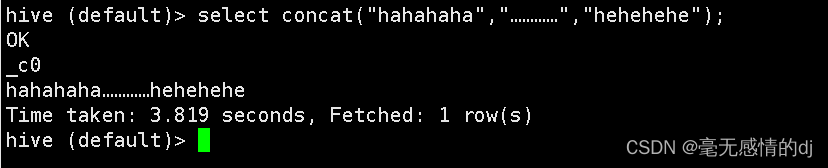
- concat函数
select concat("hahahaha","…………","hehehehe");
参考资料
Hive百度百科
Linux-安装MySQL(详细教程)
Hive之深入了解元数据
Hive元数据信息表详解
Hive的数据库和表操作
Hive 内置运算符