python股票分析挖掘预测技术指标知识大全(1)
本人股市多年的老韭菜,各种股票分析书籍,技术指标书籍阅历无数,萌发想法,何不自己开发个股票预测分析软件,选择python因为够强大,它提供了很多高效便捷的数据分析工具包,
我们已经初步的接触与学习其中数据分析中常见的3大利器---Numpy,Pandas,Matplotlib库。
也简单介绍一下数据获取的二种方法,通过金融数据接口和爬虫获取。
既然有了数据,python知识也入门了。那么重点要对这些数据分析,来预测股票的未来的大概率走势,让我们这些韭菜们心里有底。
(1)指标有用论
相信技术指标有用论是我们能开发这套股票预测系统的最大的信念和动力。
有一句名言:股市没有新鲜事,不可能有的。投机向群山一样古老,亘古长存,从未改变。股市上今天发生的事,过去曾经发生过,将来还会在此发生。
对过去的数据进行技术分析来预测未来的走势从概率学,统计学,数学的角度是完全科学和可实施的,所以才会有各种的技术指标,算法分析等等。
那么问题来了,股市小散看过各种技术书籍,各种技术指标难记于心的不乏少数,但是市场永远是二八定律,技术指标在手,亏的人远远占大多数。
道理很简单,技术指标不会骗人,程序不会骗人,但是股市是这个世界上最复杂,最具欺骗性的博弈游戏,既然所有技术指标都是根据以往的数据进行计算来预测未来,庄家可以利用大量资金技术和时间来做出虚假技术指标来骗小散入局,简称骗线,还有重要的一点,股市是对人性最大的考验,所有的技术指标不能100%的预测未来,胜算概率超过6成已经很完美了,这也是量化交易大行其道,机器没有感情,按照算法自动交易,挣钱肯定大于亏钱。
(2)编写股票分析挖掘软件核心目的
目前市场上各种交易预测软件汗牛充栋,包括证劵交易软件上kdj,macd,bill,ma等几十种技术指标已经相当完善。 但是用的人多了,盈亏还是二八定律,那就做点交易软件上没有的,增加胜算概率。
代码满足以下条件
(1)多指标共振
比如macd,kdj,boll,ma,lstm算法,线性回归算法同时预测买卖点。因为庄家多个指标同时做到骗线,难度大
(2)量价优先
量是所有指标的前提,股票交易如果每天冷冷清清,那么所有指标是不可靠的,量起来代表股票开始活跃了
(3)背离共振
多个指标有背离,比金叉死叉更加真实
(4)AI算法加持
线性回归算法,贝叶斯算法,lstm长短期记忆神经网络进行数据训练预测
注:只有满足上述大部分条件的股票再纳入自选股票池,当然,这是我个人对技术指标分析的浅薄看法,在测试和使用过程中不断调整算法来最大限度增加预测胜算概率,不足之处欢迎大家交流
(3)常见技术指标
技术指标总几十种,简单的介绍一下几个常见的
(1)指标之王MACD
MACD(Moving Average Convergence / Divergence),平滑异同平均线。是利用收盘价的短期(常用为12日)指数移动平均线与长期(常用为26日)指数移动平均线之间的聚合与分离状况,对买进、卖出时机作出研判的技术指标。
MACD指标是最著名的趋势性指标,其主要特点是稳健性,这种指标不过度灵敏的特性对短线而言固然有过于缓慢的缺点,但正如此也决定其能在周期较长、数据数目较多行情中给出相对稳妥的趋势指向。
当MACD从负数转向正数,是买的信号。当MACD从正数转向负数,是卖的信号。当MACD以大角度变化,表示快的移动平均线和慢的移动平均线的差距非常迅速的拉开,代表了一个市场大趋势的转变。
使用方法 : 随股价上升MACD翻红,即白线上穿黄线(先别买),其后随股价回落,DIF(白线)向MACD(黄线)靠拢,当白线与黄线粘合时(要翻绿未翻绿),此时只需配合日K线即可,当此时K线有止跌信号,如:收阳,十字星等.(注意,在即将白黄粘合时就要开始盯盘囗,观察卖方力量),若此时能止跌称其为”底背驰”.
底背驰是买入的最佳时机!当股价高位回落,MACD翻绿,再度反弹,此时当DIF(白线)与MACD(黄线)粘合时{要变红未变红}若有受阻,如收阴,十字星等,就有可能”顶背驰”是最后的卖出良机!
python代码实现:
import pandas as pd
import talib
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
df = pd.read_csv("600276.csv")
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
dif, dea, bar = talib.MACD(df['close'].values, fastperiod=12, slowperiod=26, signalperiod=9)
dif[np.isnan(dif)], dea[np.isnan(dea)], bar[np.isnan(bar)] = 0, 0, 0
ax.plot(np.arange(0, len(df)), dif)
ax.plot(np.arange(0, len(df)), dea)
red_bar = np.where(bar > 0, 2 * bar, 0)
blue_bar = np.where(bar < 0, 2 * bar, 0)
ax.bar(np.arange(0, len(df)), red_bar, color="red")
ax.bar(np.arange(0, len(df)), blue_bar, color="blue")
ax.xaxis.set_major_locator(ticker.MaxNLocator(20))
def format_date(x, pos=None):
# 由于前面股票数据在 date 这个位置传入的都是int
# 因此 x=0,1,2,...
# date_tickers 是所有日期的字符串形式列表
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()
显示效果: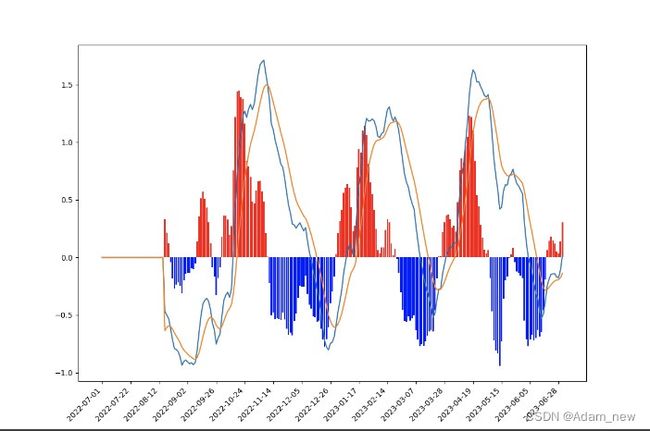
(2)随机指标KDJ
KDJ指标是比较综合的技术指标,它结合了股票市场趋势和股票价格缩量的两个条件。KDJ指标由K、D、J三个曲线组成,是通过对随机指标加以改进而发展出来的。一般投资者常用的参数为9、3、3。当KDJ曲线形态出现明显的底部、顶部、轮廓时,就说明多空形势已经发生变化,投资者可以在此时买入或卖出。(kdj指标对周线判断更加准确,日线最好结合其他指标)
python代码实现:
import pandas as pd
import talib
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
df = pd.read_csv("600276.csv")
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
df['K'], df['D'] = talib.STOCH(df['high'].values, df['low'].values, df['close'].values, fastk_period=9, slowk_period=3,
slowk_matype=0, slowd_period=3, slowd_matype=0)
df['K'].fillna(0,inplace=True)
df['D'].fillna(0,inplace=True)
df['J']=3*df['K']-2*df['D']
ax.plot(df["date"], df["K"], label ="K")
ax.plot(df["date"], df["D"], label ="D")
ax.plot(df["date"], df["J"], label ="J")
plt.legend()
ax.xaxis.set_major_locator(ticker.MaxNLocator(20))
def format_date(x, pos=None):
# 由于前面股票数据在 date 这个位置传入的都是int
# 因此 x=0,1,2,...
# date_tickers 是所有日期的字符串形式列表
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()
显示效果:
(3)均线指标
均线指标是股票投资者分析股票走势的最常用指标之一。它将股票价格在一段时间内的平均值作为参考值,自上而下穿越均线时为卖出信号等等。不同的均线周期对应着不同的时间跨度,一般市场上分别以5天线、10天线、20天线、30天线、60天线、120天线、250天线等为常用均线周期标准。通过均线指标,投资者可以从长期趋势和短期走势上分析,可以极大的协助投资者分析股票走势。
python 代码实现:
import pandas as pd
import talib
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
df = pd.read_csv("600276.csv")
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
df["SMA10"]=talib.SMA(df['close'],timeperiod=10)
df["SMA20"]=talib.SMA(df['close'],timeperiod=20)
df["SMA30"]=talib.SMA(df['close'],timeperiod=30)
df['SMA10'].fillna(method="bfill",inplace=True)
df['SMA20'].fillna(method="bfill",inplace=True)
df['SMA30'].fillna(method="bfill",inplace=True)
ax.plot(np.arange(0, len(df)), df['SMA10']) # 绘制5日均线
ax.plot(np.arange(0, len(df)), df['SMA20']) # 绘制10日均线
ax.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax.xaxis.set_major_locator(ticker.MaxNLocator(20))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
ax.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()
显示效果: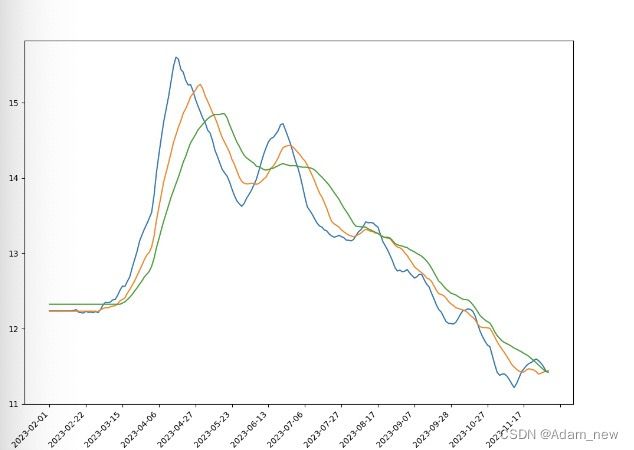
(4)成交量指标
成交量指标是股市中最好用的5个技术指标之一。它可以通过观察股票的成交量来评估市场的活跃程度和投资者的情绪。当股价上涨并且成交量放大时,就说明市场情绪热烈,投资者买入意愿强烈。成交量还可以与其他指标如成交额相比,更能反映股票的走势。因此,成交量指标在股市分析中具有重要的参考价值。
python代码实现:
import mpl_finance as mpf
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.ticker as ticker
import numpy as np
#创建绘图的基本参数
fig, axes = plt.subplots(2, 1, sharex=True, figsize=(15, 10))
ax1, ax2 = axes.flatten()
#获取刚才的股票数据
df = pd.read_csv("600271.csv")
mpf.candlestick2_ochl(ax1, df["open"], df["close"], df["high"], df["low"], width=0.6, colorup='r',colordown='green',alpha=1.0)
df['date'] = pd.to_datetime(df['date'])
df['date'] = df['date'].apply(lambda x: x.strftime('%Y-%m-%d'))
def format_date(x, pos=None):
if x < 0 or x > len(df['date']) - 1:
return ''
return df['date'][int(x)]
df["SMA5"] = df["close"].rolling(5).mean()
df["SMA10"] = df["close"].rolling(10).mean()
df["SMA30"] = df["close"].rolling(30).mean()
ax1.plot(np.arange(0, len(df)), df['SMA5']) # 绘制5日均线
ax1.plot(np.arange(0, len(df)), df['SMA10']) # 绘制10日均线
ax1.plot(np.arange(0, len(df)), df['SMA30']) # 绘制30日均线
ax1.xaxis.set_major_formatter(ticker.FuncFormatter(format_date))
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right')
red_pred = np.where(df["close"] > df["open"], df["volume"], 0)
blue_pred = np.where(df["close"] < df["open"], df["volume"], 0)
ax2.bar(np.arange(0, len(df)), red_pred, facecolor="red")
ax2.bar(np.arange(0, len(df)), blue_pred, facecolor="blue")
#显示出来
plt.show()
效果:
(5)布林线BOLL
林带是股市中最好的技术指标之一。布林带由三条线将中线包在一起,形成股价的波动范围。通过布林带,我们可以在股价波动时观察到股价的波动情况,从而做出更准确的交易决策。此外,布林带还具有较好的可预测性,可以根据股价的走势进行趋势判断。通过布林带技术指标,我们可以及时发现股价的波动,做出买入或卖出的决策。因此,布林带是股市中最好的技术指标之一。
还有几十种指标不一一介绍了
(4)算法模型
(1)线性回归算法
线性回归是人工智能领域中最常用的统计学方法之一。在许多不同的应用领域中,线性回归都是非常有用的,常用于金融预测,推荐系统等等
线性回归模型也有许多改进和扩展版本,例如多元线性回归、逻辑回归、岭回归、lasso回归、弹性网回归等等。这些模型可以更好地处理实际应用中的不同情况,例如多个自变量、非线性关系、高维度数据等等。
(2)长短记忆神经网络LSTM
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,可以用于对股票金融数据进行训练预测
python代码实现
# !/usr/bin/env python
# coding=utf-8
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 从文件中获取数据
origDf = pd.read_csv('test.csv')
df = origDf[['Close', 'High', 'Low','Open' ,'Volume']]
featureData = df[['Open', 'High', 'Volume','Low']]
# 划分特征值和目标值
feature = featureData.values
target = np.array(df['Close'])
# 划分训练集,测试集
feature_train, feature_test, target_train ,target_test = train_test_split(feature,target,test_size=0.05)
pridectedDays = int(math.ceil(0.05 * len(origDf))) # 预测天数
lrTool = LinearRegression()
lrTool.fit(feature_train,target_train) # 训练
print(lrTool.score(feature_train,target_train))
# 用测试集预测结果
predictByTest = lrTool.predict(feature_test)
# 组装数据
index=0
# 在前95%的交易日中,预测结果和收盘价一致
while index < len(origDf) - pridectedDays:
df.loc[index,'predictedVal']=origDf.loc[index,'Close']
df.loc[index,'Date']=origDf.loc[index,'Date']
index = index+1
predictedCnt=0
# 在后5%的交易日中,用测试集推算预测股价
while predictedCnt效果: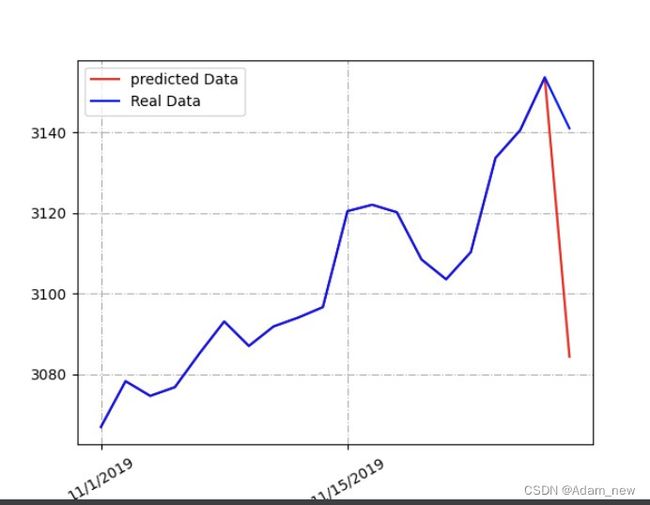
其他也可以通过贝叶斯算法,随机森林模型等几十种算法模型对股票数据进行预测和分析, 不一一讲解。
注:上述文章只是对技术指标和算法有个简单的介绍,每一种算法模型和技术指标需要深入的了解,到时候再单独开章详细介绍每种指标的详细用法和原理,谢谢大家
上述python代码我已经放到csdn,欢迎大家下载。
有不足之处欢迎大家多指点。