如何在2024年编写Android应用程序
如何在2024年编写Android应用程序
本文将介绍以下内容:
- 针对性能进行优化的单活动多屏幕应用程序 (没有片段)。
- 应用程序架构和模块化 → 每个层面。
- Jetpack Compose 导航。
- Firestore。
- 应用程序架构(模块化特征驱动的清晰架构)。
为什么要在应用程序中遵循架构?
应用程序架构就像您代码的蓝图。它可以智能地组织事物,使您的应用程序具有以下优点:
- 易于理解和修复:没有混乱的代码。您可以快速找到并编辑所需内容。例如,如果您想添加一个按钮(转到 UI 层)。如果您想更改 UI 组件的验证逻辑(转到用例层)。
- 可扩展和具有未来性:添加新功能非常简单,并且在大多数情况下,应用程序可以轻松适应新技术。
- 可测试和可靠:可以早期发现错误,从而使应用程序更加平稳、可靠。提示:尝试为核心层编写更多测试。
- 有益于团队协作:开发人员可以同时处理不同部分,而不会相互干扰,特别是如果他们正在处理不同的功能。
- 可持续和长久:您的应用程序将保持健康并保持相关性多年。
投资于架构,观察您的应用程序繁荣!
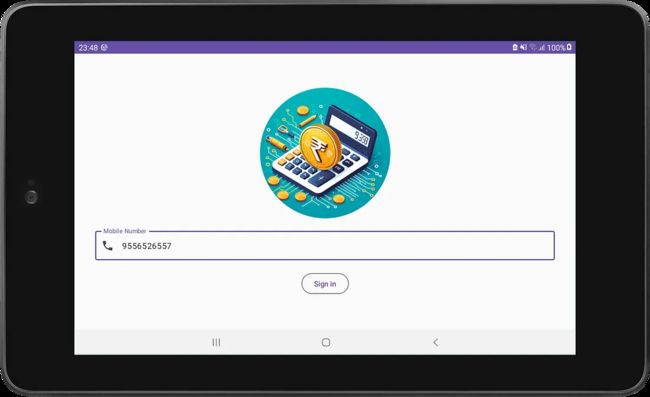
App Screens
该应用程序有2个屏幕:登录和注销。

面向未来的灵活性
使用 Kotlin 构建的本机 Android 应用程序可以无缝地过渡到各种平台,包括 iOS、Android、macOS、Windows、Linux 等。这要归功于 Kotlin Multiplatform。
该应用程序模块化以实现其未来的灵活性。
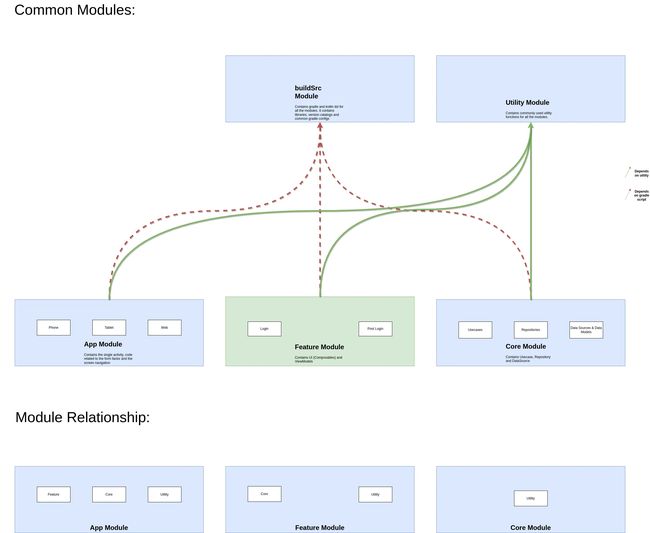
模块化
以下是应用程序中的模块:
- app
- feature
- core
- utility
- buildSrc


应用程序模块
职责
它就像我们应用程序的船长。它会将您带到应用程序的正确屏幕,适应不同的设备(手机、平板电脑、智能手表、电视等),甚至计划在不同的平台(Android、iOS 等)上进行冒险 —— 这都归功于 Kotlin 的魔法。
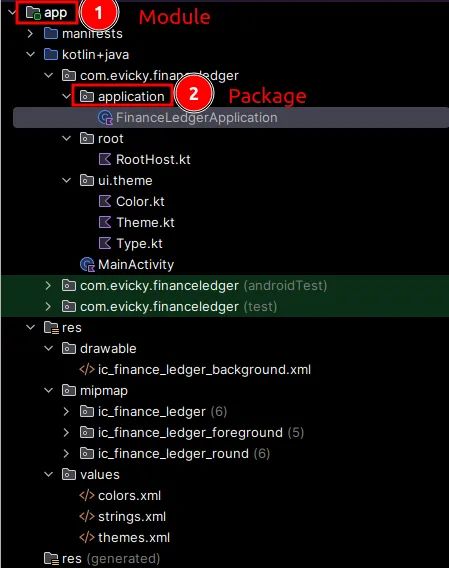
应用程序模块包含主活动(单个活动)和 Jetpack Compose 导航的 RootHost。
Jetpack Compose 导航是什么?
在 Jetpack Compose 中,导航通常是使用 Navigation 组件管理的,就像在传统的基于 XML 的 Android UI 中一样。导航组件有助于在应用程序中的不同可组合(UI 组件)之间导航。
应用程序包
应用程序包含 Koin 依赖注入框架的初始化代码和 Firebase 初始化代码。Firestore 是该应用程序的后端。在下面的文章中可以了解更多关于 Koin 的信息。
https://levelup.gitconnected.com/koin-the-kotlin-kmp-dependency-injection-framework-dafaf9b85639?source=post_page-----04c9d8614c27--------------------------------
package com.evicky.financeledger.application
import android.app.Application
import com.evicky.core.di.useCaseModule
import com.evicky.feature.di.viewModelModule
import org.koin.core.context.startKoin
class FinanceLedgerApplication: Application() {
override fun onCreate() {
super.onCreate()
// FirebaseApp.initializeApp(this)
startKoin {
modules(
dataSourceModule, repoModule, useCaseModule, viewModelModule, coroutineDispatcherProviderModule
)
}
}
}
基于安全原因,Firestore 从 GitHub 存储库中删除。代码已被注释以供参考。
//MainActivity.kt
package com.evicky.financeledger
import android.os.Bundle
import androidx.activity.ComponentActivity
import androidx.activity.compose.setContent
import com.evicky.financeledger.root.RootHost
import com.evicky.financeledger.ui.theme.FinanceLedgerTheme
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
FinanceLedgerTheme {
RootHost()
}
}
}
}
-
你是否注意到了上面的代码,
MainActivity没有像 Android 的 View 系统(基于 XML 的旧视图系统)一样扩展AppCompatActivity。它是扩展了ComponentActivity,这意味着该代码使用了 Jetpack Compose 库来构建 UI。 -
onCreate事件管理器具有androidx.activity:activity-compose库的setContentlambda 函数。 -
setContent是使用 Jetpack Compose 定义屏幕 UI 的入口点。它接受一个描述要显示的 UI 元素层次结构的composable函数作为参数。 -
FinanceLedgerTheme和RootHost是可组合函数。 -
setContent使用了一个特定于此应用程序的 material 3 主题,名为FinanceLedgerTheme。
该主题包含了 RootHost 的可组合函数。
让我们看一下 RootHost 的实现。
Root package
package com.evicky.financeledger.root
import androidx.compose.runtime.Composable
import androidx.navigation.compose.NavHost
import androidx.navigation.compose.rememberNavController
import com.evicky.feature.login.signInScreen
import com.evicky.feature.register.navigateToRegisterScreen
import com.evicky.feature.register.registerScreen
import com.evicky.feature.util.SIGNIN_ROUTE
import com.evicky.utility.logger.Log
@Composable
internal fun RootHost() {
val rootController = rememberNavController()
NavHost(
navController = rootController,
startDestination = SIGNIN_ROUTE,
) {
signInNavGraph(
onSignInPress = {
rootController.navigateToPostLoginScreen(it)
}
)
postLoginNavGraph()
}
}
@Composable注解告诉编译器RootHost是一个可组合函数。
什么是注解?
在 Kotlin 中,注解是一种元数据形式,您可以将其添加到代码中,以提供有关代码元素(如类、函数或属性)的额外信息。Kotlin 中的注解类似于 Java 中的注解。
在这里,@Composable 将函数标记为 UI 组件。这些函数被称为可组合函数,它们定义了用户界面的特定部分,并且可以嵌套使用以创建 UI 元素的层次结构。
RootHost() 函数包含了组合导航代码。它将引导您到应用程序中的正确屏幕,成为您应用程序的导航器!
在 Jetpack Compose 中,通常使用导航组件来管理导航,就像在传统的基于 XML 的 Android UI 中一样。导航组件有助于在应用程序中的不同可组合(UI 组件)之间进行导航。
让我们稍后继续讨论代码!
Utility module
职责:
实用程序或助手模块的目的是为所有模块提供应用程序中常见或可重复使用的功能。
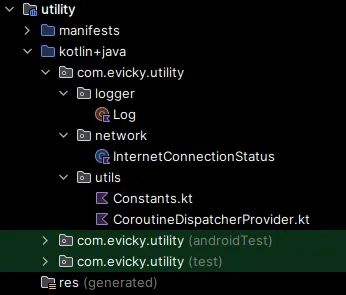
Logger package
为什么我们需要有一个日志记录器包,当我们在 Android 中有默认的 Logging 库时呢?
一些第三方开源日志记录库具有很好的功能。有时您的应用程序可能有多个日志记录库。如果我们以这种方式拥有它,那么日志记录库将很容易地添加/替换。无需更改应用程序的每个文件中都有日志的文件。为了更容易更换日志记录库。
为什么要更换日志记录库?
回到2021年,您可能听说过著名的开源日志记录库“Log4j”中报告了一个关键漏洞。全世界的开发人员都因听到这个漏洞而感到困惑,并且在短时间内难以更换他们的日志记录库。
Log4j 漏洞
- 发现:在广泛用于 Java 应用程序中的受欢迎的 Log4j 日志记录库中发现了一个关键漏洞(CVE-2021-44228)。
- 影响:它允许攻击者在受影响的系统上执行任意代码,可能导致数据盗窃、勒索软件攻击或完全接管系统。
- 严重性:由于易于利用和广泛使用,被评为“关键”。
package com.evicky.utility.logger
import android.util.Log
object Log {
fun v(tag: String, msg: String?, throwable: Throwable? = null) =
msg?.run {
Log.v(tag, this, throwable)
}
fun d(tag: String, msg: String?, throwable: Throwable? = null) =
msg?.run {
Log.d(tag, this, throwable)
}
fun i(tag: String, msg: String?, throwable: Throwable? = null) =
msg?.run {
Log.i(tag, this, throwable)
}
fun w(tag: String, msg: String?, throwable: Throwable? = null) =
msg?.run {
Log.w(tag, this, throwable)
}
fun e(tag: String, msg: String?, throwable: Throwable? = null) =
msg?.run {
Log.e(tag, this, throwable)
}
}
Network package
网络包包含用于检查互联网连接性的代码。它会 ping Google 的轻量级服务器以了解网络连接状态。在应用程序中了解互联网连接性至关重要。
请参考 GitHub 存储库获取代码。
Utils package
此包包含帮助程序类。
为什么我们应该在 helper 类中有 Coroutine Dispatcher Provider?
协程中的硬编码分发器使协程的可测试性更加困难。如果您在 Android Studio 中集成了它,Sonar Lint 将报告警告。因此,协程的分发器从此辅助类中注入。
请参考下面的文章系列,以了解有关 Kotlin 协程的更多信息。
https://levelup.gitconnected.com/the-ultimate-kotlin-coroutine-concept-test-on-android-part-1-826d8066d0c4?source=post_page-----04c9d8614c27--------------------------------
Core module
职责:
核心模块包括用例、存储库、数据模型和数据源。您甚至可以有一个以上的模块,每个模块有两个层级。决策应根据您的需求进行。
Use cases(用例)→ 封装业务逻辑并协调交互。
Repositories(存储库)→ 充当数据访问的抽象层,决定使用哪个数据源。
Data models(数据模型)→ 表示应用程序数据的结构。
Data sources(数据源)→ 处理与底层存储的直接交互,管理读写操作。
这种分层方法促进了Android应用程序中的模块化、可扩展性,并且便于进行测试。即使您使用iOS或Android,此核心模块也不会被大幅修改。它独立于设备形态、操作系统和本地化。
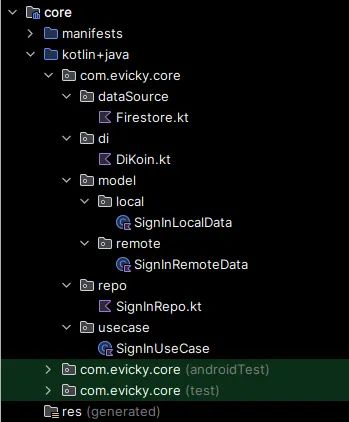
DataSource package
DataSource → 处理与底层存储的直接交互,管理读写操作。
package com.evicky.core.dataSource
import com.evicky.utility.logger.Log
import kotlinx.coroutines.suspendCancellableCoroutine
import kotlin.coroutines.resume
interface IDataSource {
suspend fun writeData(
documentPath: String,
data: Any,
logTag: String,
writeSuccessLogMessage: String,
writeFailureLogMessage: String
): Boolean
suspend fun readData(logTag: String, documentPath: String): Map<String, Any>?
suspend fun deleteData(
documentPath: String,
logTag: String,
writeFailureLogMessage: String
): Boolean
}
class Firestore : IDataSource {
// private val fireStore: FirebaseFirestore = FirebaseFirestore.getInstance()
override suspend fun writeData(
documentPath: String,
data: Any,
logTag: String,
writeSuccessLogMessage: String,
writeFailureLogMessage: String,
) = suspendCancellableCoroutine { continuation ->
try {
// fireStore.document(documentPath).set(data)
// .addOnCompleteListener { task ->
// if (task.isSuccessful) {
// Log.i(logTag, "Data write success to firestore db $writeSuccessLogMessage: $documentPath")
// if (continuation.isActive) continuation.resume(true)
// } else {
// Log.e(logTag,
// "Data write failed to firestore db $writeFailureLogMessage: $documentPath. Error Message: ${task.exception?.message}",
// task.exception)
// if (continuation.isActive) continuation.resume(false)
// }
// }
// sendSuccessResultIfOfflineForDocumentWrite(fireStore.document(documentPath), continuation)
} catch (exception: Exception) {
Log.e(logTag,
"Exception from execution: Data write failed to firestore db. $writeFailureLogMessage: $documentPath. Error Message: ${exception.message}",
exception)
if (continuation.isActive) continuation.resume(false)
}
}
override suspend fun readData(logTag: String, documentPath: String): Map<String, Any>? =
// fireStore.document(documentPath).get().await().data
null
override suspend fun deleteData(
documentPath: String,
logTag: String,
writeFailureLogMessage: String,
) = suspendCancellableCoroutine { continuation ->
try {
// fireStore.document(documentPath).delete()
// .addOnCompleteListener { task ->
// if (task.isSuccessful) {
// Log.i(logTag, "Delete Success in firestore db: $documentPath")
// if (continuation.isActive) continuation.resume(true)
// } else {
// Log.e(logTag,
// "Delete Failure in firestore db: $writeFailureLogMessage: $documentPath. Error Message: ${task.exception?.message}",
// task.exception)
// if (continuation.isActive) continuation.resume(false)
// }
//
// }
} catch (exception: Exception) {
Log.e(logTag,
"Exception from execution: Delete Failure in firestore db: $writeFailureLogMessage: $documentPath. Error Message: ${exception.message}",
exception)
if (continuation.isActive) continuation.resume(false)
}
}
}
/**
* While the device is in offline we won't get success or failure task result for writes to firestore.
* So getting the meta data to send the result back to the caller if the data is from cache.
*/
//fun sendSuccessResultIfOfflineForDocumentWrite(
// documentReference: DocumentReference,
// continuation: CancellableContinuation为什么我们应该为 dataSource 有一个接口和类?难道只使用类就不够了吗?因为 repository 将为测试模拟拥有接口和类。
repository 和 dataSource 是否应该有专门的接口和类?
虽然在存储库中只有一个类对数据源有一个接口也是可行的,但是在 Android Clean Architecture 中为存储库和数据源引入接口提供以下优点:
1)可测试性:
对于存储库:拥有存储库接口使得更容易创建模拟实现以测试更高级别的组件。
对于数据源:拥有数据源接口允许更容易地测试依赖于数据源的组件,因为您可以提供模拟实现。
2)多个实现:
对于存储库:存储库接口允许多个存储库实现(例如远程和本地),轻松切换或合并数据源而不影响更高级别的组件(例如 usecase、viewmodels 等)。
对于数据源:数据源接口允许多个数据源实现(例如 API 和本地数据库),提供灵活性。
3)易于重构:
对于存储库:如果底层数据源实现发生更改,拥有存储库接口可以使您在不影响更高级别的组件的情况下进行更改。
对于数据源:如果数据源实现发生更改,则数据源接口提供了明确的合同,使得更容易更新实现。
在此应用程序中有两个数据源。Google 的 Firestore 和 Amazon 的 DynamoDB。根据用户类型,数据源会动态地绑定到应用程序。用户类型决策是在存储库层中进行的。稍后将讨论这个问题。
出于安全原因,Firestore 已从 GitHub 存储库中删除。DynamoDb 实现没有实际代码,如果需要,您可以实现它。
我相信以上代码对开发人员很友好。如果不是,请告诉我。我会尝试解释一下。
Repo package
Repositories → 充当数据访问的抽象层,决定使用哪个数据源。
package com.evicky.core.repo
import com.evicky.core.dataSource.DynamoDb
import com.evicky.core.dataSource.Firestore
import com.evicky.core.dataSource.IDataSource
import com.evicky.core.model.local.SignInLocalData
interface ISignInRepo {
suspend fun writeData(documentPath: String, data: SignInLocalData, logTag: String): Boolean
suspend fun readData(logTag: String, path: String): Map<String, Any>
}
class SignInRepo(firestore: Firestore, dynamoDb: DynamoDb): ISignInRepo {
private val isPremiumUser = false // This data may come from some other data source
private val dataSource: IDataSource = if (isPremiumUser) dynamoDb else firestore
override suspend fun writeData(documentPath: String, data: SignInLocalData, logTag: String): Boolean = dataSource.writeData(
documentPath = documentPath, data = data, logTag = logTag, writeSuccessLogMessage = "Data written successfully", writeFailureLogMessage = "Data write failed")
override suspend fun readData(logTag: String, path: String): Map<String, Any> = dataSource.readData(logTag, documentPath = path) ?: mapOf()
}
在数据源包部分,为什么同时需要接口和类的原因已经说明。在这里,接口用于关注点分离和测试。
数据源的选择是由存储库层决定的。在这里,数据源是通过 isPremiumUser 布尔状态的帮助来选择的。这些数据来自其他数据源。它可以来自 jetpack datastore,或者像 mongoDB 或 Firestore 或 DynamoDB 这样的单独数据库,或者来自应用内购买信息。在这里,为了简单起见,它是硬编码的。
数据源是单例,由 koin di 框架注入。
Firestore 在此处被选为数据源。
Model package
Data models → 表示应用程序数据的结构。
package com.evicky.core.model.local
data class SignInLocalData(val id: Long, val name: String)
package com.evicky.core.model.remote
import android.os.Parcelable
import kotlinx.parcelize.Parcelize
@Parcelize
data class SignInRemoteData(val id: Long, val name: String, val address: String, val occupat
在登录过程中有两个数据模型。
SignInRemoteData 是从数据源获取的,它包含了已登录用户的所有详细信息。
SignInLocalData 是从 SignInRemoteData 派生而来的。因为用户界面不需要已登录用户的每个细节,所以在更高级别的组件中(如用例、视图模型、组合等)使用 SignInLocalData。
Usecase package
Use cases → 封装业务逻辑并协调交互。
package com.evicky.core.usecase
import com.evicky.core.model.local.SignInLocalData
import com.evicky.core.model.remote.SignInRemoteData
import com.evicky.core.repo.ISignInRepo
import kotlinx.serialization.decodeFromString
import kotlinx.serialization.json.Json
class SignInUseCase(private val signInRepo: ISignInRepo) {
suspend fun writeData(data: SignInLocalData, logTag: String): Boolean {
return signInRepo.writeData(documentPath = "Users/UserId", data = data, logTag = logTag)
}
suspend fun readData(path: String, logTag: String): SignInLocalData {
val signInRemoteData = Json.decodeFromString<SignInRemoteData>(signInRepo.readData(logTag = logTag, path = path).toString())
return SignInLocalData(id = signInRemoteData.id, name = signInRemoteData.name)
}
}
存储库是一个工厂(每个注入将给出一个新实例),由 koin di 框架注入。
用例具有纯业务逻辑。它将数据源的 SignInRemoteData 转换为更高级别组件的 SignInLocalData。
这里使用 Kotlinx-serialization 库进行 Json 数据解析。
https://github.com/Kotlin/kotlinx.serialization
什么是业务逻辑?
业务逻辑是指特定的规则、计算和操作,定义了应用程序如何处理和操作数据以实现业务目标。在软件开发的背景下,业务逻辑通常封装在应用程序的后端中,远离用户界面,并负责实现系统的核心功能。
在清洁架构或类似的架构模式中,业务逻辑通常被组织成用例。用例表示系统向其用户提供的特定、离散的功能。用例封装了执行特定操作或实现应用程序中特定目标所需的逻辑。
Feature module
职责:
feature module充当表示层。它负责向用户呈现用户界面。
它包含了每个应用程序特性的视图模型(状态持有者(state holder))、Compose 导航图和组合(用户界面)(compose navgraph and the composable (UI) )。
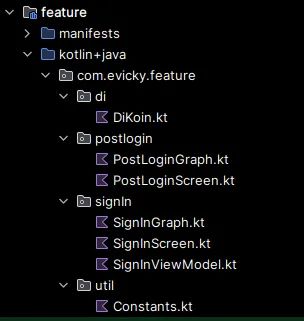

包含上面Screen的ui 和 state holder代码。
什么是状态持有者?
“state holder”通常指的是一种机制,用于在配置更改(如屏幕旋转)或 Android 组件(如 Activity 或 Fragment)的生命周期中管理和保留与 UI 相关的数据。
ViewModel 旨在以适应生命周期的方式持有和管理与 UI 相关的数据,使数据能够在配置更改时保留。这是通过将 ViewModel 与特定的生命周期关联起来实现的,通常与关联的 UI 组件的生命周期相关联。
这并不意味着只有 viewModel 才能作为状态持有者。一个普通的类也可以充当状态持有者。请参考下面的链接。
https://developer.android.com/jetpack/compose/state-hoisting?#classes-as-state-owner
https://developer.android.com/jetpack/compose/state-hoisting?#viewmodels-as-state-owner
SignInGraph:
是否需要为多个屏幕创建多个活动或片段?
不需要。在引入Jetpack Compose及其导航组件后,这个说法已经过时。
使用Jetpack Compose进行导航
导航组件为Jetpack Compose应用程序提供支持。您可以在不同的组合项之间进行导航。
在此应用程序中,使用了Compose导航进行屏幕导航。
以下是Jetpack Compose导航的工作原理概述:
- NavHost: NavHost作为可导航到的屏幕(组合项)的容器。
- NavGraph: NavHost包含定义导航路由的NavGraph。它指定了应用程序中不同组合项之间的连接。
- Navigation Actions: 通过调用导航操作来触发导航。例如,您可以使用navigate函数从一个组合项跳转到另一个组合项。
- Back Navigation: Jetpack Compose还提供了使用navController的popBackStack()函数处理返回导航的方法。
现在您已经了解了导航的工作原理。让我们进入代码。
package com.evicky.feature.signIn
import androidx.compose.runtime.getValue
import androidx.lifecycle.compose.collectAsStateWithLifecycle
import androidx.navigation.NavGraphBuilder
import androidx.navigation.compose.composable
import com.evicky.feature.util.SIGNIN_ROUTE
import org.koin.androidx.compose.koinViewModel
fun NavGraphBuilder.signInNavGraph(
onSignInPress: (String) -> Unit
) {
composable(route = SIGNIN_ROUTE) {
val viewModel: SignInViewModel = koinViewModel()
val loginUiState by viewModel.signInUiState.collectAsStateWithLifecycle()
SignInScreen(
signInUiState = loginUiState,
onSignInPress = { if (loginUiState.errorMessage.isEmpty() && loginUiState.phoneNumber.isNotEmpty()) onSignInPress.invoke(it) },
onPhoneNumberChange = { updatedValue ->
viewModel.onPhoneNumberChange(updatedValue)
}
)
}
}
这个NavGraphBuilder扩展函数的调用者位于App模块的Root包中。
MainActivity中的RootHost()函数调用了NavHost。NavHost调用了这个SignInNavGraph。
为了简洁起见,我在这里再次粘贴代码:
@Composable
internal fun RootHost() {
val rootController = rememberNavController()
NavHost(
navController = rootController,
startDestination = SIGNIN_ROUTE,
) {
signInNavGraph(
onSignInPress = {
rootController.navigateToPostLoginScreen(it)
}
)
postLoginNavGraph()
}
}
NavHost应该只有一个NavController。这是通过上面的rememberNavController()函数创建的。NavHost具有控制器和起始目标。起始目标是一个必需的参数,如果没有它,代码将无法运行。- 起始目标的
NavGraph应该在NavHost的lambda表达式中给出,否则代码将无法运行。 SIGNIN_ROUTE是一个字符串,它充当路由字符串,就像Web应用程序的URL一样。例如,app://com.evicky.finance/jetpack。在这里,"jetpack"是特定组合函数的路由,调用导航操作时将呈现屏幕。NavGraph应该至少有一个组合函数,并且该函数应该具有路由。路由应该与NavHost的起始目标相同。否则,应用程序将无法运行。- 在这里,NavHost有两个相当于两个屏幕的导航图。
NavGraphBuilder.signInNavGraph()有一个名为SignInScreen的屏幕。SignInScreen包含渲染UI的代码。SignInScreen由嵌套的组合函数组成,这些函数将为用户渲染UI。
本文不讨论SignInScreen的代码,因为它超出了本文的范围。
未来将会为Jetpack Compose制作专门的文章系列。请继续关注作者的最新动态。
BuildSrc模块
该模块包含所有模块的Gradle文件的代码。该模块利用TOML文件和Gradle约定插件的功能,提供简洁且可重用的Gradle代码。
查看更多内容:
https://levelup.gitconnected.com/say-goodbye-to-script-duplication-gradle-convention-plugin-for-android-code-reuse-multi-module-21c0eb24447d?source=post_page-----04c9d8614c27--------------------------------
Github
https://github.com/evignesh/FinLedgerPublic
参考
https://developer.android.com/topic/modularization
https://developer.android.com/topic/architecture/intro
https://developer.android.com/jetpack/compose/documentation