Spark内容分享(二十四):Apache Spark 在爱奇艺的应用实践
目录
Apache Spark 在爱奇艺的现状
Spark计算框架应用优化
Spark SQL 服务的落地与优化
总结与展望
Apache Spark 在爱奇艺的现状
Apache Spark 是爱奇艺大数据平台主要使用的离线计算框架,并支持部分流计算任务,用于数据处理、数据同步、数据查询分析等场景:
-
数据处理:在数据开发平台中支持开发者提交 Spark Jar 包任务或Spark SQL 任务对数据进行ETL处理。
-
数据同步:爱奇艺自研的BabelX数据同步工具基于Spark 计算框架开发,支持 Hive、MySQL、MongoDB 等 15 种数据源之间的数据交换,支持多集群、多云间的数据同步,支持配置化的全托管数据同步任务。
-
数据分析:数据分析师、运营同学在魔镜即席查询平台上提交SQL或配置数据指标查询,通过 Pilot 统一SQL网关调用 Spark SQL 服务进行查询分析。
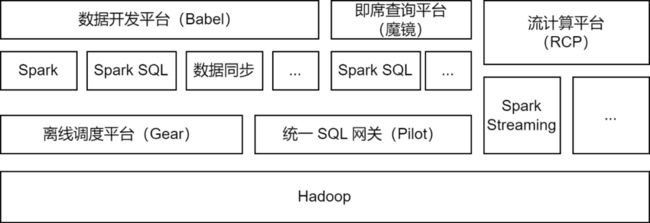
目前,爱奇艺Spark服务日均运行超过20万Spark任务,整体占用超过一半的大数据计算资源。
在爱奇艺大数据平台架构升级优化的过程中,对Spark 服务进行了版本迭代、服务优化、任务SQL 化和资源成本治理等改造,大幅提升了离线任务的计算效率和资源节省。
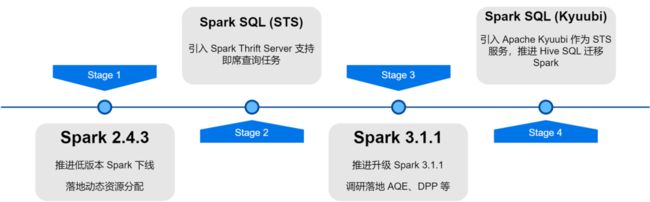
Spark计算框架应用优化
-
优秀特性的落地:随着内部 Spark 版本的迭代升级,我们对 Spark 新版本的一些优秀特性进行了调研和落地:动态资源分配、自适应查询优化、动态分区裁剪等。
-
动态资源分配(DRA):用户申请资源存在盲目性,并且 Spark 任务各个阶段的资源需求也不相同,不合理的资源配置导致任务资源浪费或执行过慢。我们在 Spark 2.4.3 开始上线了 External Shuffle Service,并开启了动态资源分配(DRA)。开启后,Spark会根据当前运行阶段的资源需求,动态地启动或释放Executor。DRA上线后,Spark任务的资源消耗降低了20%。
-
自适应查询优化(AQE):自适应查询优化(AQE)是在Spark 3.0中引入的优秀特性,根据前置阶段运行时的统计指标,动态优化后续阶段的执行计划,自动选择合适的Join策略、优化倾斜的Join、合并小分区、拆分大分区等。我们在升级Spark 3.1.1后,默认开启了AQE,很好地解决了小文件、数据倾斜等问题,并且极大地提升了Spark 的计算性能,整体性能提升了大约10%。
-
动态分区裁剪(DPP):SQL计算引擎中通常通过谓词下推的方式来减少从数据源读取的数据量,进而提升计算效率。在Spark3中引入了一种新的下推方式:动态分区裁剪和Runtime Filter,通过首先计算Join的小表,根据计算结果对Join的大表进行过滤,从而减少大表读取的数据量。我们对这两个特性进行调研测试,并默认开启DPP,在部分业务场景下性能提升了33倍。不过,我们发现在Spark 3.1.1中,开启DPP会导致含较多子查询的SQL解析特别慢。因此,我们实现了一个优化规则:计算子查询的数量,当超过5个时,关闭DPP优化。
-
计算框架增强:在使用 Spark 的过程中,我们也遇到了一些问题,通过跟进社区最新进展,发现并打入一些 Patch 进行解决。另外,我们也自行对Spark做了一些改进,以适用于各种应用场景,并增强计算框架的稳定性。
-
支持并发写入:由于Spark 3.1.1默认将Hive Parquet格式的表转换成Spark内置的Parquet Writer,使用InsertIntoHadoopFsRelationCommand算子写入数据(spark.sql.hive.convertMetastoreParquet=true)。静态分区写入时,会将临时目录直接建在表路径下。当多个静态分区写入的任务同时写同一个表的不同分区时,存在任务写入失败或者数据丢失的风险(一个任务commit时会清理整个临时目录,导致其他任务的数据丢失)。我们为InsertIntoHadoopFsRelationCommand算子加上一个forceUseStagingDir参数,使用任务专属的Staging目录作为临时目录。这样一来,不同的任务就使用了不同的临时目录,进而解决了并发写入的问题。我们已向社区提交了相关Issue【SPARK-37210】。
-
支持查询子目录:Hive升级到3.x后,默认使用Tez引擎,当执行Union语句时会产生HIVE_UNION_SUBDIR子目录。由于Spark会忽略子目录的数据,因此读取不到数据。不过使用Spark内置Parquet Reader会有更好的性能,所以我们放弃了回退到Hive Reader的方案,而是对Spark进行改造。由于Spark已支持通过recursiveFileLookup参数读取非分区表。这个问题可以通过将Parquet/Orc Reader回退到Hive Reader 解决,添加以下参数:

-
JDBC 数据源增强:在数据同步应用中有大量的JDBC数据源的任务,为了提高运行效率并适用各种应用场景,我们对Spark内置的JDBC数据源进行了如下的一些改造:
- 分片条件下推:Spark对JDBC数据源分片后通过子查询方式插入分片条件,我们发现在MySQL 5.x中对于子查询条件无法进行下推,所以我们在数据同步节点中通过添加一个占位符表示条件位置,并且在Spark中插入分片条件时下推到子查询内部,进而实现分片条件下推的能力。
- 多种写入模式:我们在Spark中对于JDBC数据源实现了多种的写入模式。
Normal:普通模式,使用默认的INSERT INTO写入
Upsert:主键存在时更新,以INSERT INTO...ON DUPLICATE KEY UPDATE 方式写入
Ignore:主键存在时忽略,以INSERT IGNORE INTO方式写入
- 静默模式:JDBC写入发生异常时,仅打印异常日志不终止任务。
- 支持Map类型:我们使用JDBC数据源读写ClickHouse数据,ClickHouse中的Map类型在JDBC数据源中不支持,因此我们添加了对Map类型的支持。
-
本地磁盘写入大小限制:Spark中的Shuffle、Cache、Spill等操作会产生一些本地文件,当写入的本地文件过多时可能将计算节点的磁盘写满,进而影响集群的稳定性。对此,我们在Spark中添加了磁盘写入量的指标,当磁盘写入量达到阈值时抛出异常,并且在TaskScheduler中判断Task失败的异常,当捕获到磁盘写入限制的异常时调用DagScheduler 的cancelJob方法停止磁盘使用过大的任务。同时,我们还在ExecutorMetric中添加Executor Disk Usage的指标暴露Spark Executor当前的磁盘使用量,便于观察趋势和数据分析。
-
计算资源治理:Spark服务占用了大量的计算资源。我们开发了异常治理平台,针对Spark批处理任务和流计算任务,分别进行了计算资源审计和治理。
-
资源审计:在日常运维中,我们发现大量Spark任务存在内存浪费、CPU利用率低等问题。为了找到存在这些问题的任务,我们将Spark任务运行时的资源指标投递到Prometheus分析任务资源利用率,通过解析Spark EventLog获取资源配置和计算详情数据。
-
资源治理:通过优化任务的资源参数、开启动态资源分配等措施有效地提升了Spark任务的计算资源利用率,Spark版本升级也带来了大量资源节省。资源参数的优化分为内存和CPU优化,异常治理平台根据任务在过去七天内的资源使用率高峰值,为其推荐合理的资源参数设置,以此提高Spark任务的资源利用率。以内存优化为例,用户常常通过增加内存来解决内存溢出(OOM)的问题,而忽视深层次排查OOM的原因。这造成大量Spark任务内存参数设置过高,队列资源内存和CPU比例不均衡。我们通过获取Spark Executor内存指标并发送异常工单通知用户,引导他们合理配置内存参数和分区数量。
-
治理收益:经过近一年的资源审计治理,异常治理平台累计发出1600多个工单,共节省了约27% 计算资源。
Spark SQL 服务的落地与优化
-
Spark SQL 服务
在爱奇艺Spark SQL服务经历了多个阶段,从Spark原生的Thrift Server服务到 Kyuubi 0.7再到Apache Kyuubi 1.4 版本,为服务架构及稳定性带来了很大的改善。

目前,Spark SQL服务已经代替Hive成为了爱奇艺主要的离线数据处理引擎,日均运行15万左右的SQL任务。
-
Spark SQL 服务优化
-
优化存储和计算效率
我们在Spark SQL服务的探索过程中也遇到了一些问题,主要包括了产生大量的小文件、存储变大以及计算变慢等问题,对此我们也进行了一系列存储和计算效率的优化。
- 启用ZStandard压缩,提高压缩率
Zstd是Meta开源的压缩算法,相对于其他的压缩格式有较大的压缩率和解压缩效率提升。我们实测效果显示,Zstd压缩率与Gzip相当,解压缩速度优于Snappy。因此,我们在Spark升级的过程中使用Zstd压缩格式作为默认的数据压缩格式,并且将Shuffle数据也设置成Zstd压缩,为集群存储带来了很大的节省,在广告数据场景下应用,压缩率提升3.3倍,节省76%存储成本。
- 添加Rebalance阶段,避免产生小文件
小文件问题是Spark SQL比较重要的一个问题:小文件过多会对Hadoop NameNode造成较大压力,影响集群稳定性。原生的Spark计算框架并没有一个很好的自动化方案来解决小文件问题。对此,我们也调研了一些业界的解决方案,最终使用Kyuubi服务自带的小文件优化方案。
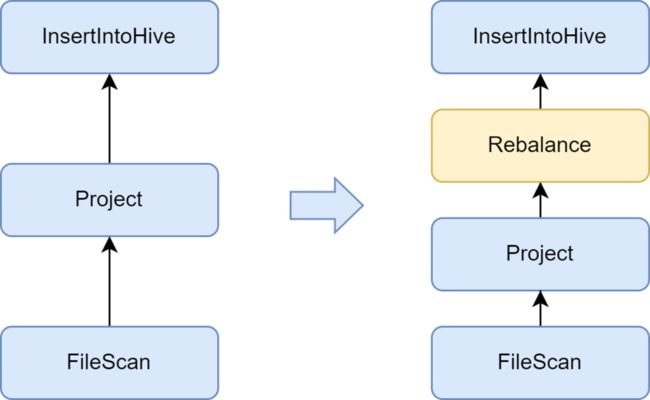
Kyuubi提供的insertRepartitionBeforeWrite优化器能在Insert算子前插入Rebalance算子,结合AQE自动合并小分区、拆分大分区的逻辑,实现了输出文件大小的控制,很好地解决了小文件问题。启用后,Spark SQL平均输出文件大小从10 MB优化到262 MB,避免了大量小文件的产生。
- 启用Repartition 排序推断,进一步提高压缩率
在开启小文件优化后,我们发现一些任务的数据存储变大很多。这是由于小文件优化中插入的Rebalance操作,使用的分区字段或者随机分区进行分区,数据被随机打散,导致Parquet格式对文件的编码效率降低,进而导致文件压缩率降低。

Kyuubi小文件优化的规则中,可通过spark.sql.optimizer.inferRebalanceAndSortOrders.enabled参数开启自动推断分区和排序字段,对于非动态分区写入,根据前置执行计划中的 Join、Aggregate、Sort 等算子的Keys推断出分区和排序字段,使用推断的分区字段进行Rebalance,或者在Rebalance前使用推断的排序字段进行Local Sort,使得最终插入的Rebalance算子的数据分布尽量与前置计划保持一致,避免写入数据被随机打散,从而有效提高压缩率。
- 启用Zorder 优化,提高压缩率和查询效率
Zorder 排序是一种多维的排序算法。对于Parquet等列式存储格式,有效的排序算法可以使得数据更加紧凑,进而提升数据压缩率。另外,由于相似的数据被聚集在相同的存储单元中,例如:min/max等统计范围更小,可以加大查询过程中Data Skipping的数据量,有效地提升查询效率。
Kyuubi中实现了Zorder聚类的排序优化,可以为表配置Zorder字段,在写入时会自动加入Zorder排序。对于存量的任务也支持Optimize命令进行存量数据的Zorder优化。我们内部对一些重点业务添加了Zorder优化,数据存储空间减少了13%,数据查询性能提升了15%。
- 引入最终阶段独立AQE配置,加大计算并行度
在一些Hive任务迁移Spark 的过程中,我们发现一些任务执行的速度竟然变慢了,分析发现由于通过在写入前插入Rebalance算子结合Spark AQE来控制小文件,我们将AQE的spark.sql.adaptive.advisoryPartitionSizeInBytes配置设为1024M,导致了中间Shuffle阶段的并行度变小了,进而使得任务执行变得比较慢。
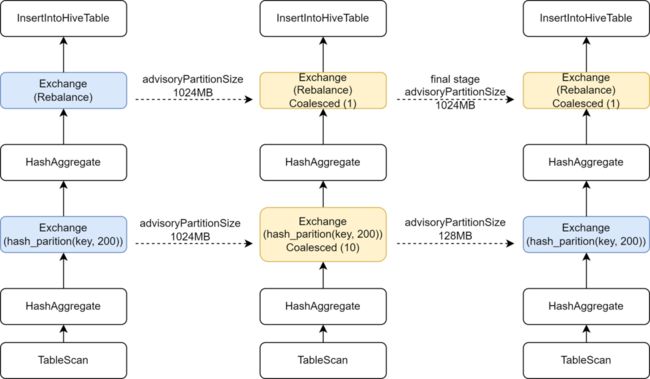
Kyuubi中提供了最终阶段配置的优化,允许为最终阶段单独添加一些配置,这样我们就可以为最终控制小文件的阶段添加更大的advisoryPartitionSizeInBytes,对于前面阶段使用较小的advisoryPartitionSizeInBytes来加大计算的并行度,并且减少了Shuffle阶段溢写磁盘,有效的提升计算效率,添加此配置后Spark SQL任务整体执行时间缩短25%,资源约节省9%。
- 推断动态写入单分区任务,避免过大Shuffle分区
对于动态分区写入,Kyuubi小文件优化会使用动态分区字段进行Rebalance。对于使用动态分区方式写入单个分区的任务,Shuffle数据会全都写入到同一个Shuffle分区中。爱奇艺内部使用Apache Uniffle作为Remote Shuffle Service,大分区会造成对Shuffle Server的单点压力,甚至触发限流导致写入降速。为此我们开发了一个优化规则,捕获写入的分区过滤条件,推断是否以动态分区方式写入单个分区的数据;对于此类任务,我们不再以动态分区字段进行Rebalance,而是使用随机Rebalance,这样就避免了生成一个较大的Shuffle分区,详细可见:【KYUUBI-5079】。
-
异常SQL检测拦截
数据质量存在问题或者用户对于数据分布不熟悉时容易提交一些异常的SQL,可能导致严重的资源浪费和计算效率低的情况。我们对Spark SQL服务添加了一些监控指标,并且对于一些异常的计算场景进行检测和拦截。
- 限制大查询
在爱奇艺,数据分析师通过魔镜即席查询平台提交SQL进行Ad-hoc查询分析,该平台为用户提供秒级查询能力。我们使用Kyuubi的共享引擎作为后端处理引擎,避免每次查询都启动新的引擎浪费启动时间和计算资源,共享引擎常驻后台可以为用户带来更快的交互体验。
对于共享引擎,多个请求会相互抢占资源,即使我们开启了动态资源分配,也存在资源被某些大查询占满的情况,导致其它查询被阻塞。对此,我们在Kyuubi的Spark插件中,实现了大查询拦截的功能,通过解析SQL执行计划中的Table Scan等操作,统计查询的分区数和扫描的数据量,如果超过了指定阈值,则判定为大查询并拦截执行。
魔镜平台根据判定结果,将大查询改用独立引擎执行。另外,魔镜中定义了分钟级的超时时间,对于使用共享引擎执行超时的任务将取消执行并且自动转换成独立引擎执行。整个过程对于用户无感,既有效地避免了普通查询被阻塞,又允许大查询使用独立的资源继续运行。
- 监测数据膨胀
Spark SQL中的一些Explode、Join、Count Distinct等操作会导致数据膨胀,如果数据膨胀得很大,可能会导致溢写磁盘、Full GC甚至OOM,并且也使得计算效率变差。我们可以在Spark UI的SQL Tab页的SQL执行计划图中,根据前后节点的number of output rows指标很容易的看出来是否发生了数据膨胀。

Spark SQL执行计划图中的指标是通过Task执行事件以及Executor Heartbeat事件上报给Driver,并在Driver中进行聚合。为了更加及时的采集到运行时的指标,我们对Kyuubi中SQLOperationListener进行扩展,监听SparkListenerSQLExecutionStart事件维护sparkPlanInfo,同时监听SparkListenerExecutorMetricsUpdate事件,捕获运行节点的SQL统计指标变化,并对比当前运行节点的number of output rows指标和前置子节点的number of output rows指标,计算数据膨胀率判断是否发生严重的数据膨胀,当发生数据膨胀时采集异常事件或拦截异常任务。
- 定位Join倾斜Key
数据倾斜问题是Spark SQL中比较常见并且影响性能问题,尽管Spark AQE中已经有了一些自动优化数据倾斜的规则,但是它们并不总是生效的,另外,数据倾斜问题很有可能是用户对于数据理解不够深入而编写了错误的分析逻辑,或者是数据本身就存在数据质量的问题,所以我们很有必要分析出数据倾斜的任务并定位倾斜的Key值。

我们可以容易的通过 Spark UI中Stage Tasks统计信息确定任务是否发生了数据倾斜,如上图中Task的Duration和Shuffle Read的Max值相对于75th percentile值超过很大,所以很明显的发生了数据倾斜。
然而计算倾斜任务中导致倾斜的Key值,通常是对SQL进行手动拆分,然后以Count Group By Keys 的方式计算各个阶段Keys的分布情况,来确定倾斜的Key值,这通常是一个比较耗时的过程。
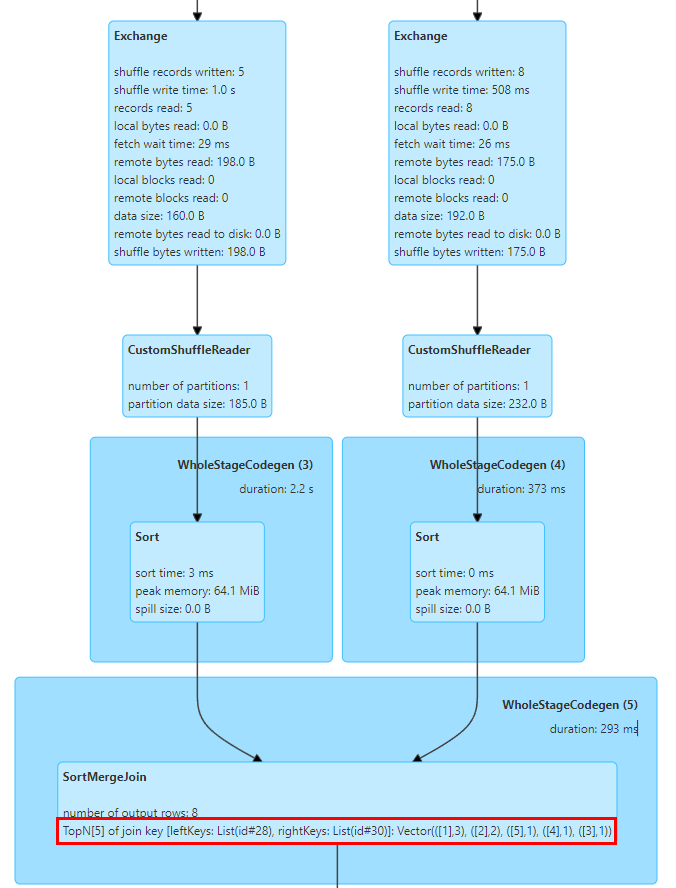
对此,我们在SortMergeJoinExec中实现了TopN的Keys统计。SortMergeJoin的实现是先对Key进行排序后再做Join操作,这样我们就可以很容易的通过累加的方式统计Key的TopN值。我们实现了一个TopNAccumulator累加器,内部维护一个Map[String, Long]类型的对象,使用Join的Key值作为Map的Key并维护该Key的Count值在Map的Value中,在SortMergeJoinExec中对于每行数据进行累加计算,由于数据是有序的我们只需要对插入的Key进行累加,并在插入新的Key时判断是否达到N值,淘汰掉最少的Key。另外,Spark只支持展示Long类型的统计指标,我们还对SQL统计指标的展示逻辑进行修改适配了Map类型的值。上图中展示了两个表进行Join的Top 5的Join Key值,其中key为id字段,并且id=1有3行。
-
Hive SQL 迁移 Spark兼容性改造
我们经过一系列的调研测试,发现Spark SQL相较于Hive,在性能和资源使用方面均有显著提升。然而,在将Hive SQL迁移到Spark的过程中,我们也遇到了许多问题。通过对Spark SQL服务进行一些兼容性改造和适配,我们成功地将大部分的Hive SQL任务迁移到Spark。
-
UDF兼容性
Spark SQL对Hive UDF的支持在实际使用中存在一些问题。例如,业务常使用reflect函数调用Java静态方法处理数据,当反射调用发生异常时,Hive会返回NULL值,而Spark SQL则会抛出异常导致任务失败。为此,我们对Spark的reflect函数进行改造,捕获反射调用异常返回NULL值,与Hive保持一致。
另一个问题是Spark SQL不支持Hive UDAF的私有化构造函数,这会导致部分业务的UDAF无法初始化。我们改造了Spark的函数注册逻辑,支持了Hive UDAF私有构造函数。
-
内置函数兼容性
Spark SQL与Hive 1.2版本的内置GROUPING_ID函数计算逻辑存在差异,导致双跑阶段出现数据不一致。在Hive 3.1版本中该函数计算逻辑变更后与Spark的逻辑一致,所以我们推进用户对SQL逻辑进行更新,适配Spark中该函数的逻辑,以保证计算逻辑的正确性。
此外,Spark SQL的哈希函数使用了Murmur3 Hash算法,与Hive的实现逻辑不同,我们建议用户通过手动注册Hive内置的哈希函数保证迁移前后数据的一致性。
-
类型转换兼容性
Spark SQL从3.0版本开始引入了ANSI SQL规范,相比于Hive SQL,其对类型一致性要求更加严格,比如:禁止String与数字类型的自动转换。为了避免业务中由于数据类型定义不规范导致的自动转换异常,我们建议用户自行在SQL中增加CAST进行显式转换,对于大量改造可暂时添加配置 spark.sql.storeAssignmentPolicy=LEGACY降低Spark SQL的类型检查等级,避免迁移发生异常。
Hive 中 str_to_map 函数对于重复的 Key 会自动保留最后一个的值,而Spark中则抛出异常导致任务失败。对此,我们建议用户对上游数据质量进行审计,或者添加spark.sql.mapKeyDedupPolicy=LAST_WIN配置,保留最后一个重复的值,与Hive保持一致。
-
其他语法兼容性
Spark SQL与Hive SQL的Hint语法有不兼容之处,迁移时需用户手动删除相关配置。常见的Hive Hint如广播小表,由于Spark AQE功能对于小表的广播和任务倾斜的优化更加智能,通常情况下无需用户进行额外配置。
Spark SQL和Hive的DDL语句也存在一些兼容性的问题,我们通常建议用户使用平台进行Hive表的DDL操作。对于一些分区操作的命令,如:删除不存在分区【KYUUBI-1583】、不等值的Alter Partition语句等兼容性问题,我们也通过扩展Spark插件进行了兼容。
总结与展望
目前,我们已将公司内绝大部分Hive任务迁移到Spark,因此Spark已经成为爱奇艺最主要的离线处理引擎。我们对Spark引擎完成了初步的资源审计和性能优化工作,为公司带来了可观的支出节省。后续,我们将持续优化Spark服务和计算框架的性能与稳定性。对剩余极少数的Hive任务,我们也将进一步推进迁移。
随着公司数据湖的落地,越来越多的业务正在迁移到Iceberg数据湖。由于Iceberg持续推进了Spark DataSourceV2的功能完善,Spark 3.1已经不能满足一些新的数据湖分析需求,因此我们即将推进Spark 3.4的升级。同时,也对一些新的特性,如Runtime Filter、Storage Partitioned Join等进行了调研,希望能够结合业务需求,进一步提升Spark计算框架的性能。
另外,为了推进大数据计算云原生化的进程,我们引入了Apache Uniffle这一远程Shuffle服务(RSS)。在使用过程中,我们发现其与Spark AQE结合存在性能问题,例如BroadcastHashJoin倾斜优化【SPARK-44065】、前面提到的大分区问题以及如何更好地进行AQE分区规划等,后续我们也会继续对此进行更加深入的研究和优化。