web如何实现录制音频,满满干货(上篇)
最近的需求,要求web端实现录制音频,包括开始录制,重录,暂停录制,继续录制,结束录制;当然除了录制,还要解决播放问题,开始播放,暂停播放,继续播放,结束播放;然后还要能够上传文件到腾讯云或阿里云;最后还需要有下载操作,下载格式选择;
接下来就一一探讨一下,如何实现这些功能吧~
先说明,我知道能够直接在GitHub上找已经实现的demo和成熟的SDK,但是这里想一起看看如何用JavaScript实现。
获取录制权限
录制之前,肯定要检查一下电脑上是否有麦克风权限,是否已经授权,没有授权,或者没有麦克风设备,是不能进行录制的。
就是会要下面这样一个网页提示

安卓移动端的提示

Ipad的提示

获取麦克风设备,可以看下面
Navigator.mediaDevices 只读属性返回一个 MediaDevices 对象,该对象可提供对相机和麦克风等媒体输入设备以及屏幕共享的连接访问
https://developer.mozilla.org/zh-CN/docs/Web/API/Navigator/mediaDevices
然后它的原型链上面,是有一个getUserMedia来获取媒体

https://developer.mozilla.org/zh-CN/docs/Web/API/MediaDevices/getUserMedia
它返回一个 Promise 对象,成功后会resolve回调一个 MediaStream 对象。若用户拒绝了使用权限,或者需要的媒体源不可用,promise会reject回调一个 PermissionDeniedError 或者 NotFoundError。

能看到,这样就获取到我电脑上连接的麦克风一个设备了,全部的代码如下:
// getUserMedia 版本兼容
static initUserMedia() {
if (navigator.mediaDevices === undefined) {
navigator.mediaDevices = {};
}
if (navigator.mediaDevices.getUserMedia === undefined) {
navigator.mediaDevices.getUserMedia = function (constraints) {
let getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia;
if (!getUserMedia) {
return Promise.reject(new Error('浏览器不支持 getUserMedia !'));
}
return new Promise((resolve, reject) => {
getUserMedia.call(navigator, constraints, resolve, reject);
});
}
}
}
static getPermission() {
this.initUserMedia();
return navigator.mediaDevices.getUserMedia({
audio: true
}).then(stream => {
if (stream) {
stream.getTracks().forEach(track => track.stop());
}
});
}
调用就直接使用getPermission方法就可以了
window.onload = () => {
Recorder.getPermission().then(() => {
console.log('给权限了');
}, (error) => {
console.log(`${error.name} : ${error.message}`);
});
}
如果没有找到声音输入设备,直接调用是会报错的
NotFoundError : Requested device not found
录制
初始化录音实例
音频上下文控制它包含的节点的创建和音频处理或解码的执行。
this.context = new (window.AudioContext || window.webkitAudioContext)();
https://developer.mozilla.org/zh-CN/docs/Web/API/AudioContext
可以使用这个对象来控制音频的处理,从文档中,我们可以知道,它继承自BaseAudioCentext,那么就可以使用父类的方法。
全部动态分贝
动态分贝的获取,就需要使用父类的createAnalyser方法,具体介绍,可以看MDN文档:
https://developer.mozilla.org/zh-CN/docs/Web/API/BaseAudioContext/createAnalyser
createAnalyser() 它可以用来暴露音频时间和频率数据,以及创建数据可视,这就是获取动态分贝,然后进行绘制。
在后面绘制demo的提供了
const audioCtx = new (window.AudioContext || window.webkitAudioContext)();
const analyser = audioCtx.createAnalyser(); // 录音分析节点
// …
analyser.fftSize = 2048; // 表示存储频域的大小
const bufferLength = analyser.frequencyBinCount;
const dataArray = new Uint8Array(bufferLength);
analyser.getByteTimeDomainData(dataArray);
// 绘制当前音频源的波形图
function draw() {
drawVisual = requestAnimationFrame(draw);
analyser.getByteTimeDomainData(dataArray);
canvasCtx.fillStyle = "rgb(200, 200, 200)";
canvasCtx.fillRect(0, 0, WIDTH, HEIGHT);
canvasCtx.lineWidth = 2;
canvasCtx.strokeStyle = "rgb(0, 0, 0)";
canvasCtx.beginPath();
const sliceWidth = (WIDTH * 1.0) / bufferLength;
let x = 0;
for (let i = 0; i < bufferLength; i++) {
const v = dataArray[i] / 128.0;
const y = (v * HEIGHT) / 2;
if (i === 0) {
canvasCtx.moveTo(x, y);
} else {
canvasCtx.lineTo(x, y);
}
x += sliceWidth;
}
canvasCtx.lineTo(canvas.width, canvas.height / 2);
canvasCtx.stroke();
}
draw();
但是上面这个是录音完成获取全部的动态分贝,那录音中的过程中如何获取呢?
- AnalyserNode 接口的 fftSize 属性的值是一个无符号长整型的值, 表示(信号)样本的窗口大小。当执行快速傅里叶变换(Fast Fourier Transfor (FFT))时,这些(信号)样本被用来获取频域数据。
- fftSize 属性的值必须是从32到32768范围内的2的非零幂; 其默认值为2048。
录制开始
https://developer.mozilla.org/zh-CN/docs/Web/API/BaseAudioContext/createScriptProcessor
this.context = new (window.AudioContext || window.webkitAudioContext)();
// 第一个参数表示收集采样的大小,采集完这么多后会触发 onaudioprocess 接口一次,该值一般为1024,2048,4096等,一般就设置为4096
// 第二,三个参数分别是输入的声道数和输出的声道数,保持一致即可。
let createScript = this.context.createScriptProcessor || this.context.createJavaScriptNode;
// 创建一个bufferSize为4096的ScriptProcessorNode和一个单一的输入和输出通道
this.recorder = createScript.apply(this.context, [4096, this.config.numChannels, this.config.numChannels]);
createScriptProcessor() 方法创建一个ScriptProcessorNode 用于通过 JavaScript 直接处理音频。
可以看到这个方法已经弃用了,目前兼容的方法是createJavaScriptNode()
所以创建的时候,就是或的关系,如果一个由于兼容性问题,使用不了,那还要兜底方案。
config.numChannels是声道数,通常是1或者2,默认是1
通常情况下,在调用函数时,函数内部的 this 的值是访问该函数的对象。使用 apply(),你可以在调用现有函数时将任意值分配给 this,而无需先将函数作为属性附加到对象上。这使得你可以将一个对象的方法用作通用的实用函数。
录制开始需要绑定录制中的事件,然后获取audio媒体,连接扬声器。
startRecord() {
if (this.context) {
// 关闭先前的录音实例,因为前次的实例会缓存少量前次的录音数据
this.destroyRecord();
}
// 初始化
this.initRecorder(); // 绑定录制中的事件
return navigator.mediaDevices.getUserMedia({
audio: true
}).then(stream => {
// audioInput表示音频源节点
// stream是通过navigator.getUserMedia获取的外部(如麦克风)stream音频输出,对于这就是输入
this.audioInput = this.context.createMediaStreamSource(stream);
this.stream = stream;
}
).then(() => {
// audioInput 为声音源,连接到处理节点 recorder
this.audioInput.connect(this.analyser);
this.analyser.connect(this.recorder);
// this.audioInput.connect(this.recorder);
// 处理节点 recorder 连接到扬声器
this.recorder.connect(this.context.destination);
});
}
录制中
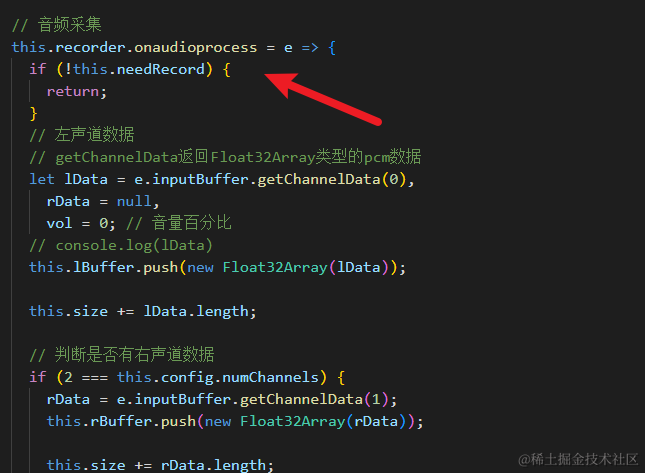
接着,我们监听ScriptProcessorNode的onaudioprocess事件就可以了,这个事件就算录制中的事件
// 音频采集,为节点提供一个处理音频事件的函数
this.recorder.onaudioprocess = e => {
// 左声道数据
// getChannelData返回Float32Array类型的pcm数据
let lData = e.inputBuffer.getChannelData(0),
rData = null,
vol = 0; // 音量百分比
this.lBuffer.push(new Float32Array(lData));
this.size += lData.length;
// 判断是否有右声道数据
if (this.config.numChannels === 2) {
rData = e.inputBuffer.getChannelData(1);
this.rBuffer.push(new Float32Array(rData));
this.size += rData.length;
}
// 计算录音大小
this.fileSize = Math.floor(this.size / Math.max( this.inputSampleRate / this.outputSampleRate, 1))
* (this.oututSampleBits / 8)
// 计算音量百分比
vol = Math.max.apply(Math, lData) * 100;
// 统计录音时长
this.duration += 4096 / this.inputSampleRate;
// 录音时长回调
this.onprocess && this.onprocess(this.duration);
// 录音时长及响度回调
this.onprogress && this.onprogress({
duration: this.duration,
fileSize: this.fileSize,
vol,
});
}
直接输出e.inputBuffer.getChannelData(0),控制台是这样的,那说明这是一个Float32Array数据
Float32Array介绍
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Float32Array
这就是浮点数组,长度就是上面默认的4096

这样的数据也被成为PCM数据格式
下面这篇知乎文章介绍了PCM数据格式,不清楚的可以看看
https://zhuanlan.zhihu.com/p/396273481
采样率(Sample rate)每秒钟采样次数,单位 Hz. 根据场景的不同,采样率也会有所不同,采样率越高,那么采样的声音就更加的接近原始声音,声音的还原度就越高,质量越好,同时占用的空间也会越大。例如,通话时的采样率为 8000Hz,常用的媒体采样率为 44100Hz.
我这台电脑的采样率是48000赫兹
采样位数是16
inputSampleRate = 48000 // 输入采样率
outputSampleRate = 48000
inputSampleBits = 16 // 输入采样位数
outputSampleBits = 16
当前的音量就取,一个Float32Array中的最大值
// 计算音量百分比
vol = Math.max.apply(Math, lData) * 100;
录音的文件大小
this.size = 左声道 + 右声道
// 计算录音大小
this.fileSize = Math.floor(this.size / Math.max( this.inputSampleRate / this.outputSampleRate, 1))
* (this.outputSampleBits / 8)
录制的时长
// 统计录音时长,单位秒
this.duration += 4096 / this.inputSampleRate;
暂停录制
由于开始录制就绑定了录制中的事件,其实暂停录制就是把,输入音频数据全部抛弃掉,所以一个变量控制是否需要暂停录制就可以了
/**
* 暂停录音
*
* @memberof Recorder
*/
pauseRecord() {
this.needRecord = false;
}
恢复录制
/**
* 继续录音
*
* @memberof Recorder
*/
resumeRecord() {
this.needRecord = true;
}
结束录制
结束录制,由于前面开始录制了,连接了媒体
所以结束的时候,就需要断开媒体连接
录制事件停止
动态分贝获取停止
/**
* 停止录音
*
*/
stopRecord() {
if (this.audioInput) {
this.audioInput.disconnect();
}
this.recorder.disconnect();
this.analyser.disconnect();
this.needRecord = true;
}
录制的流程图如下:

由于篇幅太长,所以录制在这篇里面,如何实现录制的音频播放、下载和上传,在下一篇。
未完待续····