使用python爬取豆瓣Top250排行榜数据
文章目录
-
-
- 目标网址
- 页面分析
- 代码编写
- 提取数据
- 保存数据
-
目标网址
https://movie.douban.com/top250

目标数据,爬取到电影名称,导演名字和年份,评分和评价人数
页面分析

通过F12可以直接搜索到目标数据,那么说明html结构和数据是一次性加载的,不需要二次记载
代码编写
首先导入模块
import requests
import re
接着编写代码
url="https://movie.douban.com/top250"
resp= requests.get(url)
resp.encoding="utf-8"
print(resp.text)

运行一下发现并没有拿到数据,那么可能要添加一下请求头
在页面上F12
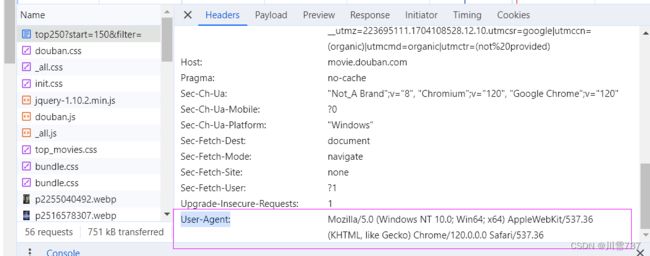
把User-Agent拿下来,然后填上header
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
resp= requests.get(url,headers=headers)
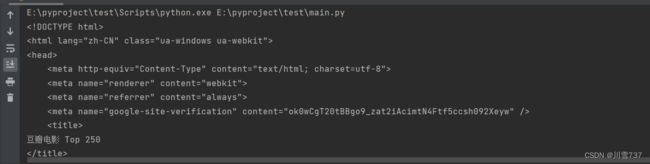
这个时候就拿到我们要的数据了
提取数据
接下来就只需要提取数据就可以了,可以用正则,也可以用xpath
obj=re.compile(r'.*?(?P.*?) .*?.*?导演: (?P.*?) .*?
(?P.*?) .*?.*?(?P.*?)人评价 ',re.S)
result=obj.finditer(resp.text)
我这里用正则匹配的方式进行提取
保存数据
接着,只需要将数据保存即可,效果如图:

完整代码如下:
import requests
import re
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
f = open("top250.csv", mode="w", encoding="utf-8")
for i in range(0,225,25):
url="https://movie.douban.com/top250?start="+str(i)+"&filter="
resp = requests.get(url, headers=headers)
resp.encoding = "utf-8"
# 正则匹配
obj = re.compile(
r'.*?(?P.*?) .*?.*?导演: (?P.*?) .*?
(?P.*?) .*?.*?(?P.*?)人评价 ',
re.S)
result = obj.finditer(resp.text)
# 提取数据
for item in result:
name = item.group("name")
daoyan = item.group("daoyan")
year = item.group("year").strip()
score = item.group("score")
num = item.group("num")
f.write(f"{name},{daoyan},{year},{score},{num}\n")
print(name, daoyan, year, score, num)
f.close()
resp.close()
aoyan},{year},{score},{num}\n")
print(name, daoyan, year, score, num)
f.close()
resp.close()