linux高级管理——shell脚本应用(四)
一、正则表达式:
1.1正则表达式的定义:
正则表达式又称正规表达式.常规表达式。在代码中常简写为regex,regexp或RE。正则表达式是使用单个字符串来描述.匹配一系列符合某个句法规则的字符串,简单来说,是--种匹配字符串的方法,通过一些特殊符号.实现快速查找.删除.替换某个特定字符串。
正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为-个模板.将某个字符模式与所搜索的字符串进行匹配。其中普通字符包括大小写字母.数字.标点符号及一些其他符号,元字符则是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符〈即位于元字符前面的字符)在目标对象中的出现模式。
1.2 正则表达式的用途:
正则表达式对十系统管理员来说是非常重罢的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的.有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便
1.3基础正则表达式示例:
提前准备一个叫test.txt的测试文件:
he was short and fat.
He was wearing a blue polo shirt with black pants.
The home of Football on BBC Sport online.
the tongue is boneless but it breaks bones.12!
google is the best tools for search keyword.
The year ahead will test our political establishment to the limit.
PI=3.141592653589793238462643383249901429
a wood cross!
Actions speak louder than words
#woood #
#woooooood #
AxyzxyzxyzxyzC
I bet this place is really spooky late at night!
Misfortunes never come alone/single.
I shouldn't have lett so tast.

1)查找特定字符
查找特定字符非常简单.如执行以下命令即可从test , txt文件中查找出特定字符“the”所在位置,其中“-n”表示显示行号、“-i”表示不区分大小写。命令执行后.符合匹配标准的字符,字体颜色会变为红色。
[root@xiao ~]# grep -n 'the' test.txt

若反向选择.如查找不包含“the”字符的行.则需要通过grep命令的“一vn”选项实现。
[root@xiao ~]# grep -vn 'the' test.txt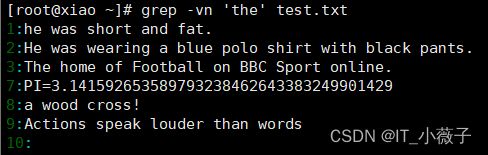
2)利用中括号“”来查找集合字符
想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh”与“rt”。此时执行以下命令即可同时查找到“shirt”与“short”这两个字符串。"[”中无论有几个字符,都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”。
[root@xiao ~]# grep -n 'sh[io]rt' test.txt
若要查找包含重复单个字符“oo”时,只需要执行以下命令即可。
[root@xiao ~]# grep -n 'oo' test.txt

3)查找行首“^”与行尾字符“s”
基础正则表达式包含两个定位元字符:"^”(行首)与“$”(行尾)。在上面的示例中.查询“the"字符串时出现了很多包含“the”的行.如果想要查询以“the”字符串为行首的行,则可以通过“^"元字符来实现。
[root@xiao ~]# grep -n '^the' test.txt
4:the tongue is boneless but it breaks bones.12!
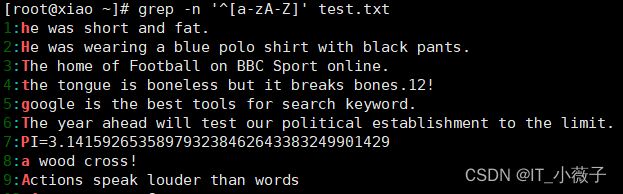
查询以小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行则使用“1[A-Z]"规则.若查询不以字母开头的行则使用“^[^a-zA-Z]”规则。
[root@xiao ~]# grep -n '^[a-zA-Z]' test.txt
"^”符号在元字符集合“门”符号内外的作用是不一样的.在“[]”符号内表示反向选择,在“门”符号外则代表定位行首。反之,若想查找以某一特定字符结尾的行则可以使用“$”定位符。例如.执行以下命令即可实现查询以小数点(.)结尾的行。因为小数点(.)在正则表达式中也是一个元字符,所以在这里需要用转义字符“\”将具有特殊意义的字符转化成普通字符。
二、扩展正则表达式:
·通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令.需要使用范围更广的扩展正则表达式。例如,使用基础正则表达式查询除文件中空白行与行首为“#”之外的行〈通常用于查看生效的配置文件).执行“grep -v '^s’ test ,txt / grep -v^#”即可实现。这里需要使用管道命令来搜索两次。如果使用扩展正则表达式,可以简化为“egrep -v‘s]#’test ,txt”其中,单引号内的管道符号表示或者(or )。

三、文本处理器:
在Linux/UNX系统中包含很多种文本处理器或文本编辑器,其中包括我们之前学习过的VM编辑器与grep等。而grep , sed , awk更是shell编程中经常用到的文本处理工具,被称之为Shell编程三剑客。
3.1 sed 工具:
sed (Stream EDitar)是一个强大而简单的文本解析转换工具,可以读取文本.并根据指定的条件对文本内容进行编辑〈删除.替换.添加、移动等),最后输出所有行或者仅输出处理的某些行。sed 也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于Shell脚本中,用以完成各种自动化处理任务。
sed的工作流程主要包括读取.执行和显示三个过程。
读取:sed从输入流〈文件.管道.标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
执行:默认情况下,所有的sed命令都在模式空间中顺序地执行.除非指定了行的地址.否则sed命令将会在所有的行上依次执行。
显示:发送修改后的内容到输出流。再发送数据后,模式空间将会被清空。
默认情况下,所有的sed命令都是在模式空间内执行的,因此输入的文件并不会发生任何变化,除非是用重定向存储输出。
3.2 sed 命令常见用法:
通常情况下调用sed命令有两种格式,如下所示。其中,“参数”是指操作的目标文件,当存在多个操作对象时用,文件之间用逗号“,”分隔;而scriptfile表示脚本文件.需要用“-f”选项指定.当脚本文件出现在目标文件之前时.表示通过指定的脚本文件来处理输入的目标文件。

常见的sed命令选项主要包含以下几种。
-e或--expression=:表示用指定命令或者脚本来处理输入的文本文件。
-f 或-file=:表示用指定的脚本文件来处理输入的文本文件。
-h或--help:显示帮助。
-n、--quiet或 silent:表示仅显示处理后的结果。一i:直接编辑文本文件.
“操作”用于指定对文件操作的动作行为,也就是sed的命令。
a:增加,在当前行下面增加一行指定内容。
c:替换,将选定行替换为指定内容。
d:删除,删除选定的行.
i:插入,在选定行上面插入一行指定内容。
p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCIl码输出。其通常与“-n”选项起使用。
s:替换,替换指定字符.
y:字符转换。
3.3 sed命令用法示例:
[root@xiao ~]# sed -n 'p' test.txt ##打印所有内容
[root@xiao ~]# sed -n '3p' test.txt ##打印第3行
[root@xiao ~]# sed -n '3,5p' test.txt ##打印3~5行
[root@xiao ~]# sed -n 'p;n' test.txt ##打印所有奇数行
[root@xiao ~]# sed -n 'n;p' test.txt ##打印所有偶数行
[root@xiao ~]# sed -n '1,5{p;n}' test.txt ##打印第一至五之间的奇数行
[root@xiao ~]# sed -n '10,${n;p}' test.txt ##打印第10行到最后一行的偶数行sed命令结合正则表达式时.格式略有不同:例如:
[root@xiao ~]# sed -n '/the/p' test.txt ##输出包含the的行

##输出以PI开头的行:
[root@xiao ~]# sed -n '/^PI/p' test.txt


## 输出包含单词wood的行,\<、\>代表单词边界:
[root@xiao ~]# sed -n '/\/p' test.txt

删除符合条件的文本(d)
因为后面的示例还需要使用测试文件test , txt ,所以在执行删除操作之前需要先将测试文件备份.以下示例分别演示了sed命令的几种常用删除用法。
##删除第3行
[root@xiao ~]# nl test.txt | sed '3d' 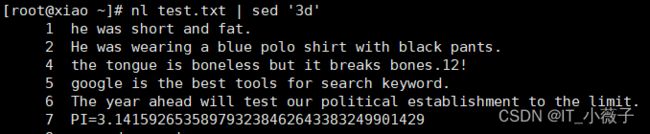
##删除包含cross的行
[root@xiao ~]# nl test.txt | sed '/cross/d'

原本的第8行不见了,被删除了。
若是删除重复的空行,即连续的空行只保留一个,执行“sed -e '/^S/ {n;/^S/d}' test.txt”命令即可实现。其效果与“cat -s test.txt”相同,n表示读下一行数据。
替换符合条件的文本
在使用sed命令进行替换操作时需要用到s (字符串替换).c(整行/整块替换).y (字符转换)

迁移符合条件的文本
其中,H.复制到剪贴板;g、G,将剪贴板中的数据覆盖/追加至指定行;w,保存为文件:r,读取指定文件:a,追加指定内容。

使用脚本编辑文件
使用sed脚本,将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调用。
将第1~5行内容转移至第17行后:
sed '1,5{H;d}; 17G' test.txt改为脚本模式为:
[root@xiao ~]# vim opt.list ##编辑脚本
1,5H
1,5d
17G
[root@xiao ~]# sed -f opt.list test.txt ##使用脚本opt.list查看test.txt文本
四、awk工具:
在Linux/UNX系统中,awk是一个功能强大的编辑工具,逐行读取输入文本.并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理.可以在无交互的情况下实现相当复杂的文本操作,被广泛应用于Shell脚本.完成各种自动化配置任务。
4.1 awk常见用法
通常情况下awk所使用的命令格式如下所示,其中,单引号加上大括号“半”用于设置对数据进行的处理动作。awk可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进行处理

##查找出/etc/passwd 的用户名.用户ID、组ID等列.执行以下awk命令即可.
[root@xiao ~]# awk -F ':' '{print $1,$3,$4}' /etc/passwd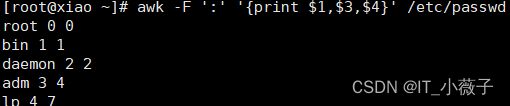
awk 从输入文件或者标准输入中读入信息,与sed一样,信息的读入也是逐行读取的。不同的是aw将文本文件中的一行视为一个记录,而将一行中的某一部分〈列)作为记录中的一个字段(域).
awk包含几个特殊的内建变量(可直接用)如下所示:
FS:指定每行文本的字段分隔符,默认为空格或制表位。
NF:当前处理的行的字段个数。
NR:当前处理的行的行号(序数)。
$0:当前处理的行的整行内容。
$n:当前处理行的第n个字段{第n列).
LENAME:被处理的文件名。
RS:数据记录分隔,默认为\n,即每行为一条记录.
4.2用法示例:
##按行输出文本:

##按字段输出文本:

##通过管道、双引号调用Shlle命令:
