论文阅读--Behavior Proximal Policy Optimization
作者:Zifeng Zhuang ,Kun Lei ,Jinxin Liu ,Donglin Wang ,Yilang Guo
论文链接:http://arxiv.org/abs/2302.11312
arXiv 2023-02-22
代码链接:https://github.com/Dragon-Zhuang/BPPO
摘要
离线强化学习( RL )是一个具有挑战性的场景,现有的非策略行动者-评论家方法由于高估了分布外的状态-动作对而表现不佳。因此,提出了各种额外的增强来保持学习到的策略接近离线数据集(或行为政策)。在这项工作中,从分析离线单调策略改进出发,我们得到了一个令人惊讶的发现,一些在线在策略算法自然能够解决离线RL。具体来说,这些在策略算法固有的保守性正是离线RL方法需要克服高估的地方。基于此,我们提出了行为近似策略优化( Behavior Proximal Policy Optimization,BPPO ),在不引入任何额外约束或正则化的情况下求解离线RL。在D4RL基准测试集上的大量实验表明,该方法优于当前最先进的离线RL算法。
BPPO
BPPO(Behavior Proximal Policy Optimization)算法用于解决离线强化学习中的策略优化问题。在离线强化学习中,由于数据集的局限性,传统的在线离策略方法可能无法直接应用。BPPO通过限制学习策略与行为策略之间的差距,实现了在离线数据集上的策略优化,从而解决了离线强化学习中的策略优化问题。
论文概述
本文主要介绍了一种名为Behavior Proximal Policy Optimization (BPPO)的算法,用于解决离线强化学习策略优化问题。文章首先介绍了强化学习的基本框架和目标,然后详细阐述了BPPO算法的推导过程,包括理论基础、实验设计和算法原理。文章指出,BPPO算法可以通过最大化特定目标函数来实现从行为策略到改进策略的单调性改进,同时限制它们之间的变化程度,从而解决了离线强化学习中的过度估计问题。此外,文章还对BPPO算法的性能和设计选择进行了实验评估。
贡献
- 提出了一种基于理论结果的实用算法——行为近端策略优化(Behavior Proximal Policy Optimization,简称BPPO),该算法的损失函数与在线策略优化方法Proximal Policy Optimization(PPO)相同。
- 通过限制学习策略与行为策略之间的差异,BPPO能够在离线数据集上实现策略的单调改进,从而解决离线强化学习问题。
- 在D4RL基准测试中,BPPO表现出优越的性能,超过了现有的离线强化学习算法。
展示了行为近端策略优化(BPPO)方法在离线强化学习问题上的有效性和优越性能。
OFFLINE MONOTONIC IMPROVEMENT OVER BEHAVIOR POLICY
讨论了如何在离线数据集上实现单调策略改进:
这一部分首先介绍了性能差异定理,该定理表明,从在线单调策略改进(如近端策略优化)可以得出离线单调策略改进。然后,作者提出了一种名为行为近端策略优化(Behavior Proximal Policy Optimization,简称BPPO)的算法,该算法基于在线单调策略改进的理论结果,并通过限制学习策略与行为策略之间的差异来实现离线单调策略改进。
BPPO的核心思想是通过限制每个策略更新的散度来正则化每个策略更新。尽管BPPO与在线近端策略优化(PPO)的损失函数相同,但BPPO的状态分布有所不同。BPPO使用离线数据集恢复的状态分布ρD(s)替换在线方法中使用的旧状态分布ρπβ(s)。通过这种方法,BPPO可以在不引入任何额外约束或正则化的情况下,优雅地解决离线强化学习问题。
实验结果表明,BPPO在D4RL数据集上表现出优越的性能,且与之前的一步方法和迭代方法相比,具有更好的性能。
BEHAVIOR PROXIMAL POLICY OPTIMIZATION
主要研究了一种实际的算法,即基于理论结果的行为近端策略优化(Behavior Proximal Policy Optimization,简称BPPO)。BPPO的损失函数与在线策略优化方法Proximal Policy Optimization(PPO)相同。由于BPPO高度依赖于行为策略,因此将其命名为行为近端策略优化。根据结论2,要逐步改进策略π_k,应共同优化:
- 最大化J_∆(π, π_k),其中k = 0, 1, 2, …
- 约束散度:D_KL(π || π_k) ≤ δ
该部分还讨论了BPPO如何解决离线强化学习问题,以及与先前的OneStep和迭代方法之间的关系。此外,实验部分展示了BPPO在D4RL基准上的性能以及与其他算法的比较。总之,第四部分主要关注了行为近端策略优化算法的设计、实现和性能评估。
DISCUSSIONS AND IMPLEMENTATION DETAILS
Why BPPO can solve offline RL?
BPPO 可以解决离线 RL 的原因如下:
损失函数与 PPO 相同:BPPO 的损失函数与在线策略优化方法 PPO(Proximal Policy Optimization)相同。由于 PPO 的内在保守性,BPPO 限制了学习策略与行为策略之间的差距,这与离线 RL 方法相似,后者使学习策略接近行为策略。
监督策略优化:BPPO 从离线单调策略改进的角度出发,使用 PPO 的损失函数优雅地解决了离线 RL 问题,而无需引入任何额外的约束或正则化。这意味着一些在线策略优化方法(如 PPO)可以实现离线策略优化,这进一步表明 PPO 可以解决离线 RL。
应对过度估计问题:通过限制策略更新的整体变分散度,BPPO 可以在离线情况下实现单调策略改进。这使得 BPPO 能够克服离线 RL 中的过度估计问题。
简单易实现:BPPO 非常简单且易于实现。在 D4RL 数据集上,BPPO 实现了优越的性能。
How to approximate the advantage?
在离线强化学习中,由于无法与环境进行交互,因此在计算损失函数时,我们需要对优势函数(Advantage Function)进行近似。在Behavior Proximal Policy Optimization(BPPO)中,我们直接根据定义估计优势函数,而不是使用在线情况下的通用优势估计(GAE)方法。具体来说,我们将Q函数估计通过SARSA进行,而值函数通过拟合返回![]()
与MSE损失进行。这种函数逼近方法可以推广到(st , ãt )的优势。
BPPO如何解决离线强化学习问题,以及与先前的OneStep和迭代方法之间的关系
BPPO(Behavior Proximal Policy Optimization)通过以下方式解决离线强化学习问题:
- 使用与在线策略优化方法(如PPO)相同的损失函数,以便在离线设置中实现策略改进。
- 通过限制学习策略与行为策略之间的差距,使学习策略接近行为策略。
- 使用剪切比率衰减技术,逐渐松弛对学习策略与行为策略之间差距的限制,以确保最终学习策略与行为策略之间的接近性。
与先前的OneStep和迭代方法的关系:
- BPPO与OneStep RL有关,因为BPPO仅改进行为策略πβ,而OneStep RL解决离线RL问题而无需进行离策略评估。然而,BPPO还改进了π k ,这是在πβ 之上的改进策略。
- BPPO与迭代方法的关系:BPPO在某种程度上位于OneStep和迭代之间。BPPO的Onestep版本严格要求新策略接近πβ,而BPPO适度放宽了这种限制。
RELATED WORK
迭代方法(Iterative Methods):迭代方法是一类离线强化学习方法,它们通过多次迭代来更新策略。这些方法通过计算Q函数并根据计算结果更新相应的策略。迭代方法的一个关键优势是它们可以在训练过程中不断改进策略。
行为近端策略优化(Behavior Proximal Policy Optimization, BPPO):BPPO是一种离线强化学习算法,它通过限制新策略与行为策略之间的差距来实现策略的单调改进。BPPO的损失函数与在线策略优化方法PPO(Proximal Policy Optimization)相同,但状态分布有所不同。BPPO通过对行为策略进行迭代优化,实现了在离线数据集上的策略单调改进。
Offline Reinforcement Learning
离线强化学习(Offline Reinforcement Learning):离线强化学习与在线强化学习相比,其主要区别在于训练数据是事先收集好的,而不是通过与环境交互收集的。离线强化学习面临的挑战是如何在不与环境交互的情况下推断出好的策略。
主要讨论了在离线场景下如何从固定数据集中推断出良好的策略。
在这种情况下,智能体仅有一个包含状态转换的固定数据集,而无法与环境进行交互。这使得离线强化学习面临诸多挑战,例如过拟合、分布漂移和稀疏奖励等问题。为了解决这些问题,研究者提出了许多方法,如批量约束、KL控制、行为正则化和策略限制等。这些方法通过限制策略与离线数据(或行为策略)之间的差异来避免过拟合和分布漂移。
Monotonic Policy Improvement
单步强化学习(One-step Reinforcement Learning):One-step RL 是一种离线强化学习方法,它通过仅改进行为策略来解决离线强化学习问题,而不需要进行离策略评估。这种方法可以避免在离线强化学习中出现的过度估计问题。
主要讨论了如何在强化学习中通过限制策略更新的散度来实现稳定的策略改进。
这种方法源自在线强化学习中的 Proximal Policy Optimization(PPO)算法,并将其应用于离线强化学习。通过在离线数据集上实现单调策略改进,可以在不引入任何额外约束或正则化的情况下有效地解决离线强化学习问题。这种方法被称为 Behavior Proximal Policy Optimization(BPPO),实验证明它在 D4RL 基准数据集上具有优越的性能。
EXPERIMENTS
作者通过一系列实验来评估行为近端策略优化(Behavior Proximal Policy Optimization,BPPO)的性能,并分析了其设计选择。具体而言,实验旨在回答以下问题:
1)BPPO与先前的One-step和迭代方法相比如何;
2)BPPO相较于其One-step和迭代版本的优越性;
3)超参数clip ratio和clip ratio decay σ的影响。
RESULTS ON D4RL BENCHMARKS
在D4RL基准上,Behavior Proximal Policy Optimization(BPPO)表现出色,超过了其他离线RL算法。在Gym任务中,BPPO的性能略微优于其他方法。对于Adroit和Kitchen任务,BPPO明显优于其他方法。与BC相比,BPPO在所有D4RL任务中实现了51%的性能提升。在Antmaze任务中,BPPO与Decision Transformer(DT)、RvS-G和RvS-R进行了比较。BPPO在大部分任务上可以达到与其他算法相当的性能,并在所有任务的总体性能上明显优于其他算法。
总之,BPPO在D4RL基准上表现出优越的性能,证明了其在离线RL问题上的有效性和优越性。

在D4RL Gym、Adroit和Kitchen上的归一化结果。我们大胆地提出了最好的结果,BPPO是通过平均10个评估轨迹和5个随机种子的平均回报来计算的。符号*表示通过运行官方开源代码来复现结果。

表2:D4RL Antmaze任务的标准化结果。CQL和IQL的结果是从论文IQL中提取的,而其他的结果是从论文RvS中提取的。在BC列中,符号*指定了Filtered BC ( Emmons et al , 2021),它删除了失效轨迹,而不是标准BC。
THE SUPERIORITY OF BPPO OVER ONESTEP AND ITERATIVE VERSION
BPPO的优越性主要表现在以下几个方面:
性能提升:与OneStep和迭代方法相比,BPPO在多个任务上取得了更好的性能。这表明BPPO能够更有效地从行为策略中提取信息,并利用这些信息进行策略优化。
更强的稳定性:BPPO在训练过程中保持了较高的稳定性,这意味着它能够在不同的任务和环境中更可靠地找到优秀的策略。
更广泛的适用性:BPPO可以应用于多种离线强化学习场景,包括具有稀疏奖励的任务。这表明BPPO在处理复杂任务和环境时具有更强的适应能力。
更简单的实现:BPPO相对于其他离线强化学习算法实现更简单,且不需要引入额外的约束或正则化项。这使得BPPO易于理解和应用,同时具有较高的性能。

图2:Onestep BPPO (左)和BPPO (右)之间的差值,其中减小的圆对应于衰减。

图3:BPPO与Onestep BPPO的比较。两种方法的超参数都是通过网格搜索来调整的,然后我们以最佳的性能展示了它们的学习曲线。

图4:BPPO (绿色曲线)及其迭代版本的比较,其中我们更新Q网络来近似Q π k,而不是BPPO中使用的Q π β。特别地,我们用' BPPOoff = 5 '表示每个策略训练步更新5个梯度步的Q网络。
ABLATION STUDY OF DIFFERENT HYPERPARAMETERS
作者对不同的超参数进行了消融研究,主要关注了以下几个方面:
Clip Ratio:作者分析了五个值(0.05,0.1,0.2,0.25,0.3)。在大多数环境中,这些值之间没有显著差异,所以选择了 = 0.25。
Clip Ratio Decay (σ):作者展示了如何选择σ以实现稳定的策略改进。一个较低的衰减率(σ = 0.90)或没有衰减(σ = 1.00)可能在训练过程中导致崩溃。因此,作者选择了σ = 0.96。
Asymmetric Coefficient (ω):作者引入了一个不对称系数ω∈(0,1),以根据优势的正负调整基于优势的Āπβ。对于ω>0.5,它会降低小于其期望值(即Vπβ)的状态-动作值Qπβ的贡献,而给予较大Qπβ更多的权重。作者分析了这三个系数对BPPO性能的影响。
这些消融研究有助于了解各种超参数对BPPO性能的影响,从而为实际应用提供了有益的指导。
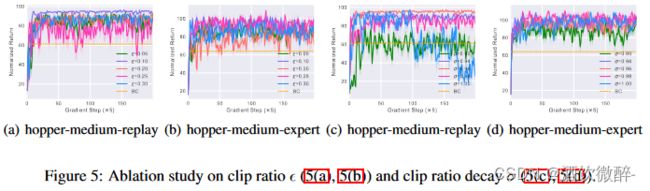
图5:对夹子比( 5 ( a ),5 ( b ) )和夹子比衰变σ ( 5 ( c ),5 ( d ) )的烧蚀研究。
实验结果表明,BPPO在多个任务上的表现与迭代方法(如CQL和TD3+BC)相当,略优于One-step方法(如Onestep RL和IQL)。此外,BPPO在使用不同超参数设置时的表现也进行了评估,以找出最佳配置。
CONCLUSION
Behavior Proximal Policy Optimization(BPPO)是一种基于离线单调策略改进的方法,它使用Proximal Policy Optimization(PPO)的损失函数来巧妙地解决离线强化学习问题,而无需引入任何额外的约束或正则化项。这是因为PPO的固有保守性使其能够克服离线强化学习中的过度估计问题。BPPO非常简单易于实现,并在D4RL数据集上取得了优越的性能。