R语言——reshape2包、tidyr包、dplyr包(五)
目录
一、数据转换之reshape2包:melt与dcast函数
二、数据转换之tidyr包:gather与spread函数,separate与unite函数
三、据转换之dplyr包
四、参考
一、数据转换之reshape2包:melt与dcast函数
merge 函数
使用merge函数
x <- data.frame(k1=c(NA,NA,3,4,5),k2=c(1,NA,NA,4,5),data=1:5)
y <- data.frame(k1=c(NA,2,NA,4,5),k2=c(NA,NA,3,4,5),data=1:5)
【使用 cbind 或 rbind 无法区分哪部分来自 x , 哪部分来自 y 。】
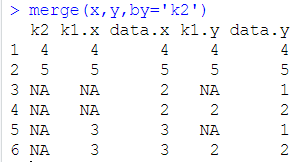
merge(x,y,by)合并函数:by表示根据x和y中的某一列进行合并。如:
merge(x,y,by=c(“k1”,“k2”))


reshape2 包
安装reshape2包:install.packages('reashape2')
加载reshape2包:library(reshape2)
(使用R中的airquality数据集做演示)
names(airquality) <- tolower(names(airquality))
aql <- melt(airquality,id.vars = c(“month”,“day”)) #将数据中的month和day作为id信息,宽数据变长数据。
aqw <- dcast(aql,month~variable,fun.aggregate=sum,na.rm=TRUE) #长数据变宽数据。
这里的~表示相关联,说明二者有关系,但不一定是相等;fun.aggregate表示给定一个函数指定如何重塑数据;na.rm表示移除na数据。



二、数据转换之tidyr包:gather与spread函数,separate与unite函数
安装tidyr包
tdata <- mtcars[1:10,1:3]
tdata <- data.frame(names=rownames(tdata),tdata)
gather(tdata,key=“Key”,value=“Value”,cyl,disp,mpg) #宽数据变长数据,类似于melt,tdata是数据框,key为标签,value为对应值。
gather(tdata,key=“Key”,value=“Value”,cyl,-disp) #disp单独放到一列中
gdata <- gather(tdata,key=“Key”,value=“Value”,2:4) #这里的2:4等于cyl,disp,mpg(或者cyl:mpg)
spread(gdata,key=“Key”,value=“Value”) #spread函数与gather函数作用相反,它是将长数据变为宽数据
df <- data.frame(x=c(NA,'a.b','a.d','b.c'))
separate(df,col=x,into=c('A','B')) #将df数据框中的x列,分割为A、B两列,默认识别分隔符为“.”
df <- data.frame(x=c(NA,'a.b-c','a-d','b-c'))
sepa <- separate(df,col=x,into=c('A','B'),sep="-") #将df数据框中的x列,分割为A、B两列,分隔符为“-”
unite(sepa,col='AB',A,B,sep="-") #unite函数与separate函数作用相反,将sepa中的A和B列,用连接符“-”连接,组成列AB







三、据转换之dplyr包
dplyr包不仅可以对单个表格进行操作,也可以对双表格进行操作。 功能强大,函数很多。
对单表格的操作
1)dplyr::filter(iris,Sepal.Length>7) #过滤函数。函数前面加上“包名::”是为了防止dplyr包中的函数名与其他函数产生冲突
dplyr::distinct(rbind(iris[1:10, ] , iris[1:15, ])) #去除重复
dplyr::slice(iris,10:15) #slice是切片的意思,可以用于取出数据任意行
dplyr::sample_n(iris,10) #随机取样10行
dplyr::sample_frac(iris,0.1) #按比例随机取样
dplyr::arrange(iris,Sepal.Length) #按照iris中的花萼长度Sepal.Length进行排序
dplyr::arrange(iris,desc(Sepal.Length)) #降序select函数:dplyr包中的数据框取子集功能,比R自带的subset函数更加强大。
dplyr::mutate(iris,new=Sepal.Length+Petal.Length) #添加新的变量new,其值是Sepal.Length+Petal.Length
2)dplyr包的统计函数
summarise函数:
summarise(iris,avg=mean(Sepal.Length))
summarise(iris,sum=sum(Sepal.Length))dplyr::group_by(iris,Species) #根据Species对iris进行分组
3)链式操作符%>%
两个百分号中间夹着一个大于号,称为链式操作符,它的功能是用于实现将一个函数的输出传递给下一个函数,作为下一个函数的输入。在RStudio中可以使用ctrl+shift+M快捷键输出来。
如:head(mtcars,20) %>% tail(10) #输出mtcars中的第10到20行iris %>% group_by(Species) %>% summarise(avg=mean(Sepal.Width)) %>% arrange(avg) #对iris数据集先进行分组,再求平均,最后排序

对双表格的操作
a <- data.frame(x1=c('A','B','C'),x2=c(1,2,3))
b <- data.frame(x1=c('A','B','D'),x3=c(T,F,T))
1)左连接
dplyr::left_join(a,b,by=“x1”)
2)右连接
dplyr::right_join(a,b,by=“x1”)
3)内连接:取x1的交集
dplyr::inner_join(a,b,by=“x1”)
4)全连接:取x1的并集5)半连接:a与b的交集,把b中有的a中没有的去掉
dplyr::semi_join(a,b,by=“x1”)6)反连接:a与b的补集,保留a中有而b中没有的观测
dplyr::anti_join(a,b,by=“x1”)数据集的合并:
mtcars <- mutate(mtcars,Model=rownames(mtcars))
first <- slice(mtcars,1:20)
second <- slice(mtcars,10:30)
1)取数据集交集:intersect(first,second)
2)取数据集并集:dplyr::union_all(first,second)
3)取非冗余的数据集并集:
dplyr::union(first,second)
4)取first的补集:setdiff(first,second)




四、参考
R语言入门与数据分析