【人工智能风格迁移】人工智能图像风格迁移尝试学习
文章目录
-
- 一、实验目的
- 二、实验内容和要求
- 三、实验结果(结果描述、结果截图、代码截图等)
- 损失函数
- 内容损失函数
- 风格损失函数
- 神经网络模型
- VGG19
- 风格迁移的网络模型
一、实验目的
图像的风格迁移其实就是利用相关算法对一些著名画作的风格进行学习,然后再把这种风格应用到我们熟悉的图片中。并且该技术已经成为人工智能领域内的一个热门的研究主题。本课程将对传统的图像风格迁移算法进行讲解,并且利用 Pytorch 对其进行实现,完成任意两张图片的风格迁移。
二、实验内容和要求
分割损失
内容损失
VGG19
模型的训练
三、实验结果(结果描述、结果截图、代码截图等)
图像风格迁移
图像的风格迁移其实就是利用相关算法对一些著名画作的风格进行学习,然后再把这种风格应用到我们熟悉的图片中。该技术最早由 Gatys 等人 提出,并且将算法应用于他们所发布的软件 Prisma 中。由于该技术不像传统的图像处理软件一般,直接对像素进行操作,而是采用神经网络相关算法模拟名家的绘画风格。因此,在软件发布之初,就吸引了上千万的融资。本实验将对该篇论文中的风格迁移技术进行详细的讲解,并且利用 Pytorch 对其进行实现。
下图为本实验最终的结果展示图:

数据的加载
在实验前,还是让我们先来加载所需要的数据集合。在一般的神经网络课程中,需要大量的数据来保证模型的泛化性。而在图像的风格迁移中,只需要两张图片(即内容图像和风格图像)即可。加载这两张图片:

利用 OpenCV 来对这两张图片进行展示:

由于这两张图片的原始大小不同,且为了保证后面放入任何图片都可以对其进行迁移。需要对图片进行预处理操作:
将图片大小缩放为 512×512 512×512。
将其类型转为 Tensor。
代码如下:

来测试一下上面的函数。加载这两张图片,并将其处理成神经网络能够使用的类型:

图像风格迁移算法
该算法主要使用三张图片,一张输入图片 G ,一张内容图片 C 和一张风格图片 S。
为了衡量任意两张图片的差距,还需要定义两个函数式,如下:
计算两张图片内容之间的差距 D_C(即内容损失函数)。
计算两张图片风格的差距 D_S(即风格损失函数)。
图像风格迁移的核心思想:输入图片 G,并且改变这张图片。使输入图片 G 与内容图片 C 之间的内容间距 D_C 最小,进而达到新图片 与内容图片 的内容一致的目的。使输入图片 G 与风格图片 S 之间的风格间距 D_S 最小,进而达到图片 G 与图片 S 风格一致的目的。
先对这两个损失函数进行讲解,之后再来阐述具体的神经网络模型和训练步骤。
各个损失的计算步骤如下所示:

损失函数
模型的总损失由内容损失和风格损失加权而成,定义总损失如下:
(,,)=⋅(,)+⋅(,)
其中两个损失的权重 和 可以自行设定。不同的设定方式表示了对内容和风格的看重程度。
内容损失函数
内容损失函数采用的是最传统的交叉熵损失:

其中 表示图片 经过了 层的神经网络模型后,输出的内容特征。同理 表示图片 经过了 的神经网络模型后,输出的内容特征。
由于 Pytorch 提供了完整的交叉熵损失函数。因此,能够很容易的定义内容损失函数,如下:
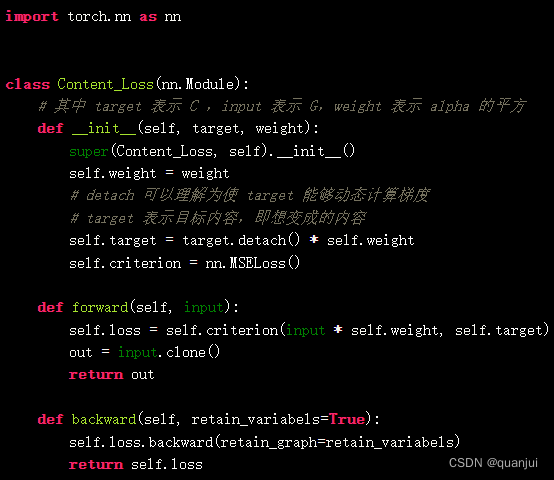
上述代码其实就是简单的交叉熵损失。而其中的 ℎ参数其实就是将公式中的 放到了括号里面,即:
⋅(,)=12∑,(ℎ⋅−ℎ⋅)2
其中 =ℎ^2
为了测试上面代码,构造一个以 content_img 为目标的损失函数,该函数可以计算任意一张图像与目标 content_img 之间的内容损失:

风格损失函数
风格是一种很难说清楚的概念,假设我们通过一个神经网络模型,对图片的特征进行了提取。那么我们又应该如何比较这些特征之间的风格呢?
在计算风格损失之前,首先需要提取图片的风格,然后再利用一些常用的损失函数,计算两种风格之间的差距与损失。那么应该怎样去获得图片的风格呢?
对于风格的提取,需要用到 Gram 矩阵。Gram 矩阵由 通道的特征图与 通道的特征图的内积计算而成。这个值可以表示为 通道的特征图 与 通道的特征图的互相关程度。具体如下:
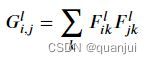
如果特征图 的通道数为 ,则计算得到的 Gram 矩阵的大小则为 ×。且该矩阵的第 行第 列的值可以表示为第 个特征图和第 个特征图之间的互相关程度。

提取我们的风格图片 S 的风格:

在得到风格后,就需要计算风格损失了。这里可以采用交叉熵损失来计算任意两张图层的风格损失。风格损失函数的代码如下:
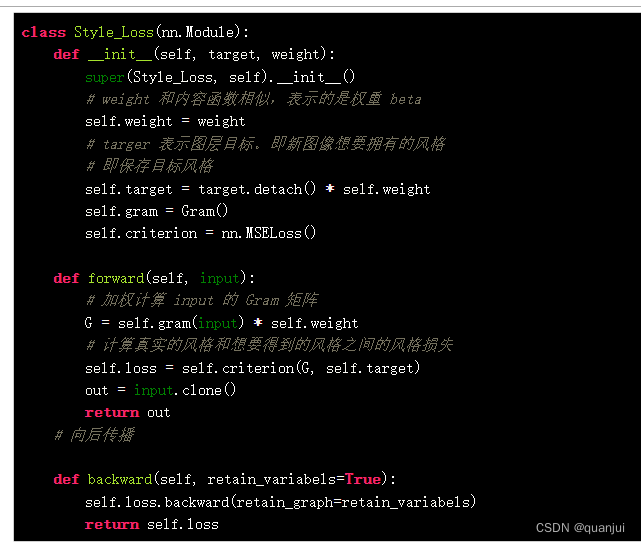
同样,传入风格目标 target,得到一个可以计算任何图像与 target 之间的风格差异的损失函数:

由于这里对风格损失赋予的权重是 1000 ,所以得到的风格损失较大。
至此,已经得到了风格损失和内容损失的具体表现形式。接下来,将会建立合适的神经网络模型并且阐述风格迁移的具体实现算法。
神经网络模型
VGG19
迁移算法主要依靠的网络结构是 VGG19 网络,这种网络结构和 VGG16 类似,也是神经网络中使用较为广泛的网络结构之一。
PyTorch 官方工具包不仅为我们提供了 VGG19 的网络结构接口,还提供了相应的预训练模型。可以通过 models.vgg19(pretrained=True).features 获得 VGG19 的所有池化层和卷积层的结构以及权重值。当 pretrained=True 时,计算机会先在本地的默认文件夹中寻找预训练模型并加载。如果没有找到,就会从身在遥远的大洋彼岸的服务器上下载该预训练模型。因此,在第一次加载 VGG19 时会非常非常非常慢(因为从外网下载东西的速度很慢)。
为了解决这一问题,预训练模型上传到了课程的云存储中,并通过对 torch.utils.model_zoo.load_url 参数的设置,来让 Pytorch 不去遥远的彼岸下载预训练模型,而是通过指定的网址下载:

接下来,加载 VGG19 的网络结构和所对应的权重:

风格迁移的网络模型
接下来,使用 VGG19 的网络结构、风格损失函数以及内容损失函数来构造一个用于图像风格迁移的神经网络模型。该网络模型只用到了 VGG19 的前 5 个卷积层。当然,也可以根据自己的实际情况对模型结构进行优化,结构如下:

如上图所示,每个网络层的输出都进行了一次风格提取,然后计算风格损失 Style_Loss(缩写为 SL),一共计算了 5 次风格损失。然后,利用 conv 4 的输出计算了一次内容损失(缩写为 CL)。而训练的最终目标就是让这些损失的加权和(即总损失)最小。
接下来用代码来构造上面的网络结构:
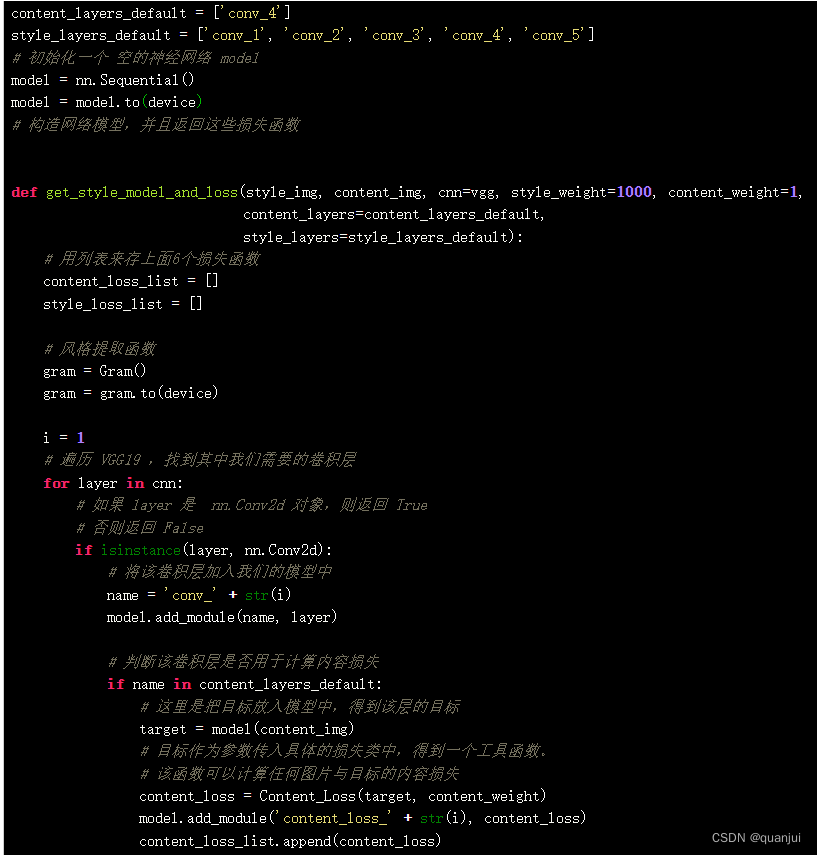

上面的代码构造了我们需要的网络模型并且对不同损失函数进行了归类。
同一类的损失函数可能也存在多组目标(这些目标是同一张图片在神经网络的不同层的表现形式)。由于不同网络层的感受野不同,它们识别到的特征也不同。因此对每一层的风格都进行了提取,进而得到了 5 个目标风格不同的损失函数(可以理解为 5 个不同的人对同一张图片的风格的见解)。
可以传入风格图片和内容图片进行测试:
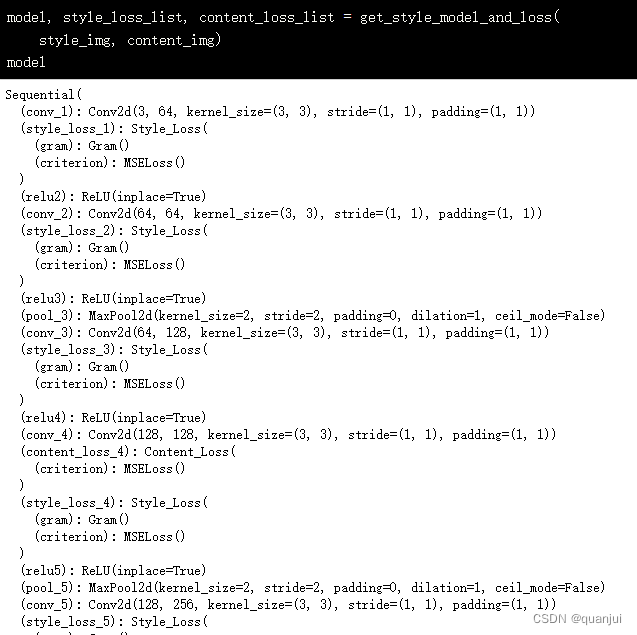
上面结果可以看出,前 5 个卷积层受到了改造,且后面的模型训练也只会用到前 5 个卷积层。
但是,不直接把 VGG19 的其它部分(即后面部分)删除掉,这样做的目的是为了可以更加简单的,通过修改 content_layers 和 style_layers 参数来修改整个模型的结构,增加更多的风格损失和内容损失,进而还原图片的更多细节。
该网络结构的输入其实是有三个,即风格图像 S 、内容图像 C 和随机图像 G 。其中,随机图像可以理解为我们使用随机数产生的一个没有任何意义的噪点图像。
传统深度学习任务的网络结构输出即为所求,但是本任务不同。该网络结构的输出其实就是一些特征,这些特征仅仅是用来计算损失的,无法称之为真正的图像(上图可知,有 5+1 个输出)。
上图可以很好的阐述该模型一次正向传播的过程了,我们将 S,G,C 都放入上面的模型中进行计算。通过 S 和 G 计算出风格总损失,通过 G 和 C 计算内容总损失,进而得到模型的总损失。然后再利用总损失进行反向传播,并且利用梯度下降算法调节G中的值。
我们将模型进行训练,调节的不是神经网络层的权重,网络结构的权重至始至终没有发生变化,调节的是 G 中的值。
事实是,模型所调节的参数才是新图像(参数即图像)。通过神经网络的后向传播,直接対新图像 G 的每个像素点的值进行调节,进而得到最符合期望的新图像 G。
换句话说,对于这种传统的图像风格迁移算法,保存模型是没有意义的,神经网络层中的参数在训练前和训练后并未发生变化。因为整个模型训练中,我们调节的都是 G ,而非模型中的参数。
因此,在定义优化器时,我们不能像传统深度学习一样,传入 model.params 。这里我们传入的应该是 G ,代码如下:

接下来,就是模型的训练函数了。让我们按照上面的思路,对模型的训练函数进行编写:
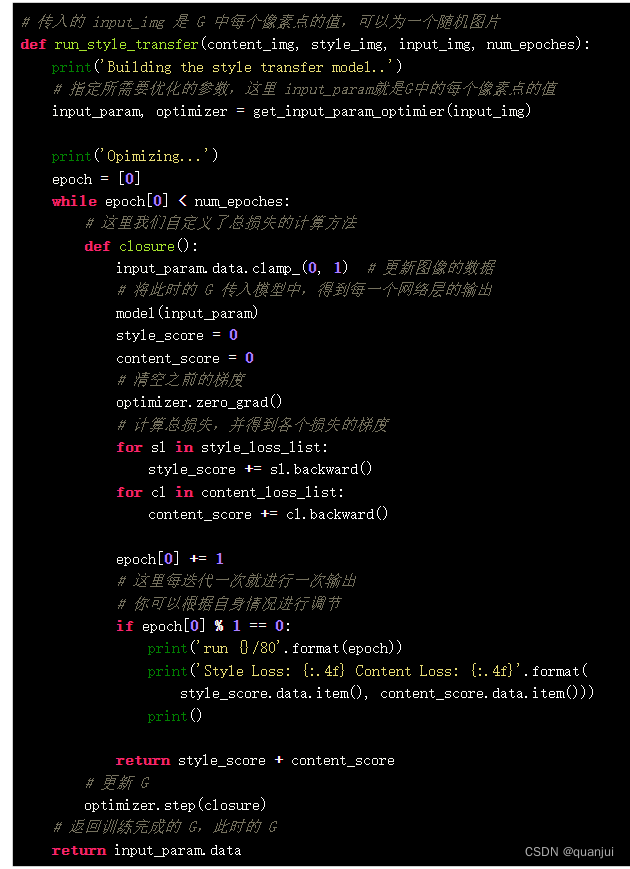
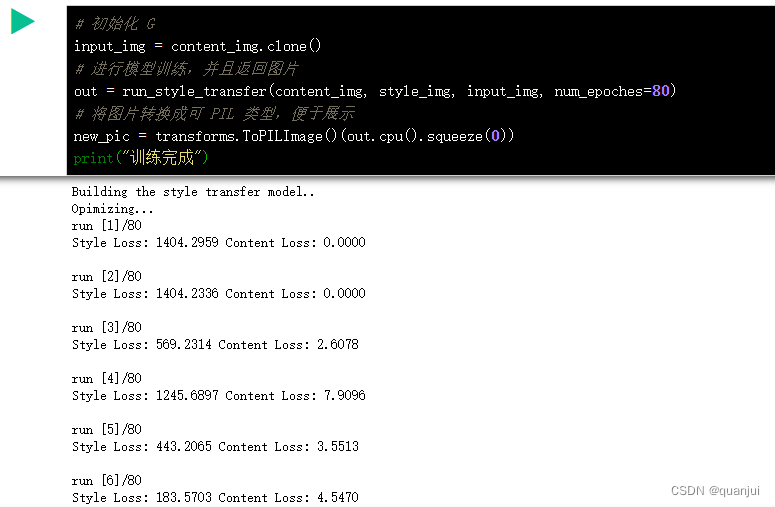
最后,调用上面的函数,正式开始进行模型的训练。由于内容图片 C 和风格图片 S 已经在上面定义好了。因此,只需要以随机噪点的方式初始化图像 G 即可。当然,除了直接以随机化的方式初始化图像 G,还有一种较为好的方式初始化 G。
这种方式就是将内容图像 C 中的每个像素点的值全部复制给图像 G。也就是说,新图像 G 中的每个像素点的初始值和 C 一致。这样有一个好处,就是可以减少模型的迭代次数。也就是说,模型训练开始时,图片 G 和内容图片 C 完全一致,只需要在尽量保留 G 的原内容的情况下,修改 G 的风格即可。代码如下: