【论文阅读笔记】Dichotomous Image Segmentation with Frequency Priors
1. 论文介绍
Dichotomous Image Segmentation with Frequency Priors
基于频率先验的二分图像分割
2023年发表在IJCAI
Paper Code
2. 摘要
二分图像分割(DIS)具有广泛的实际应用,近年来得到了越来越多的研究关注。本文提出了解决DIS与信息的频率先验。模型称为FP-DIS,它源于这样一个事实,即在频域的先验知识可以提供有价值的线索,以确定细粒度的对象边界。具体来说,提出了一个频率先验发生器,共同利用一个固定的过滤器和可学习的过滤器来提取信息丰富的频率先验。在将频率先验嵌入网络之前,首先协调多尺度侧出特征以减少它们的异质性。这是通过功能协调模块来实现的,该模块基于门控机制来协调分组功能。最后,提出了一个频率先验嵌入模块,通过自适应调制策略将频率先验嵌入多尺度特征。在基准数据集DIS 5 K上进行的大量实验表明,FP-DIS在关键评估指标方面大大优于最先进的方法。
KeyWords: 二分图像分割,频域先验,边界
二分图像分割指分割成前景与背景,二个集合,分割出高精度效果
3. Introduction
图像分割是计算机视觉中一个长期存在的话题,随着深度学习技术的发展取得了重大进展。IS-Net 采用中间监督策略来改进DIS的网络训练。现有的工作通常依赖于从图像中提取的特征,而没有考虑有价值的频率先验。在实践中,许多工作已经证明,来自频域的先验知识可以有效地提高各种计算机视觉任务的性能。①F3Net利用频率信息来感知伪造线索;②设计了一个频率增强模块,引入频域作为额外的线索,弥补了单一RGB域的不足,更好地检测被遮挡物体。
然而,将频率先验纳入DIS面临着许多挑战,包括(i)如何从图像中提取信息丰富的频率先验,(ii)如何将频率先验嵌入到骨干的多尺度侧出特征中,以及(iii)如何在频率先验嵌入之前解决多尺度特征的异质性。
本文使用频率先验来改进DIS,并设计一种称为FPDIS的新型深度学习模型来解决上述挑战。具体来说,提出了一个频率先验发生器提取信息的频率先验与固定和学习过滤器。然后将所得的频率先验嵌入到协调的多尺度特征中,以获得准确的DIS,如下图所示。在这里,提出了一个特征协调模块(FHM),以协调多尺度侧出功能的骨干基于金字塔特征提取器。FHM协调的分组功能,以减少多尺度功能的异质性。为了有效地嵌入这些频率先验,提出了一个频率先验嵌入模块(FPEM),其中两个特征嵌入组件以级联方式集成。FP-DIS充分利用频率先验来改进DIS,并解决了与频率先验提取和嵌入专门设计的模块相关的挑战。

对于一般的图像分割任务,数据集的标注过于粗糙,还具有突出的轮廓和颜色。
频域信号已广泛用于计算机视觉任务,例如图像分类,超分辨率,以及虚假面部检测。①使用高通滤波器来提取有用的详细特征;②使用离散傅立叶变换将图像转换为频域以探索底层信息;③提取重要的频率分量并过滤频率,这有利于增强语义信息;④分别处理不同的视频带以促进对象内的相似性;⑤采用知识蒸馏来减少频域和图像域之间的域间隙。
与这些方法不同的是,FP-DIS通过DCT变换和逆变换,结合频率滤波器来获得图像的频率先验。频率先验包含了RGB图像颜色空间中难以检测的细节信息。此外,图像和频域特征之间存在很大的差距。设计了一个频率先验嵌入模块,通过调制它们的分布来消除频率先验和图像特征之间的语义鸿沟,以获得更精细的分割效果。
3. 网络结构详解

FP-DIS主要由四个部分组成:金字塔特征提取器、频率先验生成器、特征协调模块和频率先验嵌入模块。如图所示,首先使用金字塔特征提取器捕获输入图像的多尺度特征,该金字塔特征提取器由基于CNN的主干和基于transformer的组件组成。采用特征协调模块协调不同尺度下相邻语义的特征。同时,将输入图像放入频率先验生成器以计算频率先验。最后,利用频率先验嵌入模块将频率先验嵌入到协调后的多尺度特征中。多尺度频率嵌入特征Ej自上而下传播。最后,最终预测E0被上采样到原始图像尺寸。
金字塔特征提取器
在DIS任务中,输入图像的尺寸通常很大,目标物体具有丰富的细节。浅层网络很难学习丰富的语义并细化大输入的特征,因为它们更多地关注局部信息。为了在多尺度上获得更多的语义信息,本文基于金字塔特征提取器中的卷积层和Vision Transformer。
使用基于CNN的ResNet-50作为主干,从输入图像 I ∈ R H × W × 3 I ∈ R^{H×W×3} I∈RH×W×3 提取多尺度特征 { X i } i = 1 4 ∈ R H 2 i × W 2 i × C i \{X_i\}^4_{i=1} ∈ R^{\frac{H}{2^i} ×\frac{W}{2^i} ×C_i} {Xi}i=14∈R2iH×2iW×Ci,其中H和W表示高度和宽度, C i ∈ { 256 , 512 , 1024 , 2048 } Ci ∈ \{256,512,1024,2048\} Ci∈{256,512,1024,2048} 是通道的数量。然后,特征 X 4 X_4 X4由步长为2的3 × 3卷积层下采样,送到Transformer块【Shunted self-attention via multi-scale token aggregation】获得 X 5 X_5 X5。对 X 5 X_5 X5用同样的操作得到 X 6 X_6 X6。X5和X6的通道是256。为了便于后续处理,将所有这些特征的通道 { X i } i = 1 6 \{X_i\}^6_{i=1} {Xi}i=16转换为96。
特征协调模块

使用特征分组来聚类不同尺度之间的相似语义和不同语义。分别在组间和组内对获得的分组特征进行协调,FHM包括两个主要部分,即分组部分和协调部分,如上图所示。
分组组件。在该组件中,给定来自金字塔特征提取器的特征Xi和Xi+1,将通道扩展N倍,然后将它们分成N组(这里每组就是一个原输入特征)。这样来自相同输入的层内组包含相似的特征,而来自不同输入的层间组包含具有较大变化的特征。最后,得到了2N组特征。每个分组特征沿通道维度进一步分为三个子组(彩色图像为3:R、G、B;灰度图为1)。
协调组件。对给定的输入Xi和Xi+1进行分组后,每组层内的语义紧密,不同尺度的组之间的语义差异明显。因此,需要实现特征的协调,而协调机制的核心是使用一个门单元进行过滤。有两种协调机制,即组内协调和组间协调。对于组间协调,如上图所示,绿色块收集所有组的拆分子组。所以它有2N个不同比例的输入。对于组内协调,蓝色块收集具有相同比例的拆分子组,所以它有N个相同比例的输入。因此,对于每个尺度,它都有两个协调部分。
使用组间协调作为示例,将分组特征表示为 { G n } n = 1 N \{G_n\}^N_{n=1} {Gn}n=1N,设置N = 4。如图的最右边所示,首先通过添加所有输入特征来获得聚合特征。(对于组间协调,将Xi插值到与Xi+1相同的尺度)然后将这些子组送到门单元,该门单元计算调制权重矩阵A。在数学上,门单元定义如下:
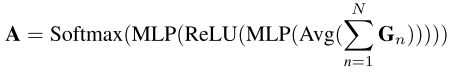
Avg(·)表示在特征的空间维度上进行的自适应的平均池化操作;MLP(·)代表多层感知,ReLU(·)表示ReLU激活函数,Softmax(·)表示softmax函数。
将调制权重与原始特征相乘以获得协调的特征图,即,

最后,将组间协调的输出插值到每个分支的相同大小中。将来自同一分支的协调特征连接起来,将它们通过卷积层进行平滑,并将它们与输入特征相加,以获得特征协调模块的输出特征![]()
。
频率先验发生器
为了生成频率先验,首先使用离散余弦变换(DCT)将图像I变换到频域以生成频率分布图M,即,M = DCT(I)。接下来,固定滤波器和可学习滤波器提取不同且有效的频率分量。特别是,固定滤波器将频率分量划分为不同的频带(低频,中频,高频和所有频率),而可学习滤波器提供更丰富的信息, σ = 1 − e x p ( − x ) 1 + e x p ( − x ) σ = \frac{1−exp(−x)}{1+exp(−x)} σ=1+exp(−x)1−exp(−x) 用于将x归一化到−1和+1之间的范围。最后,使用逆离散余弦变换(iDCT)生成频率先验 X F P X_{FP} XFP: X F P = i D C T ( M ⊗ ( F f + σ ( F l ) ) ) X_{FP} = iDCT(M⊗ (F_f + σ(F_l))) XFP=iDCT(M⊗(Ff+σ(Fl)))。其中iDCT(·)表示逆离散余弦变换,iDCT是Hadamard乘积, F f F_f Ff和 F l F_l Fl分别是固定滤波器和可学习滤波器。
频率优先嵌入模块
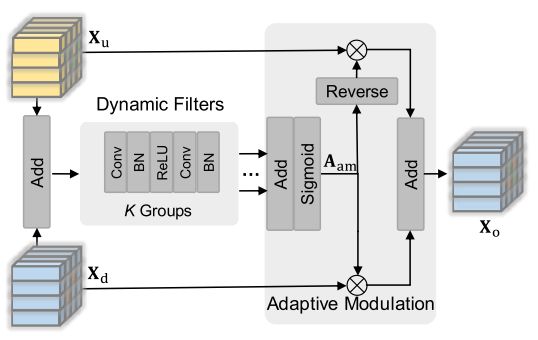
在图像特征中加入频率先验信息使输出包含更详细的信息。然而,由于频域和图像域之间的语义鸿沟,直接融合的性能较差。所以在频率先验嵌入模块(FPEM)中,设计了特征嵌入组件,该组件由K组动态滤波器和一个自适应调制组成。为了充分利用频率先验信息,采用了级联特征传播机制。
功能嵌入组件。将特征嵌入组件的输入表示为上下分支的配对特征 ( X u , X d ) (X_u,X_d) (Xu,Xd),并将输出表示为特征 X o X_o Xo。如上图所示,首先将两个分支上的特征相加,以获得聚合特征。然后,聚合特征通过K个动态过滤器分支来学习来自不同表示域的不同信息。每个分支包括用于将信道维度降低到用于信息压缩的原始的四分之一的卷积运算,用于选择重要部分的BatchNorm层和RELU层,以及用于恢复信道维度的另一个卷积层和BatchNorm层。每个分支的输出 X d f ( K ) X_{df}(K) Xdf(K)用以下公式计算:![]()
其中DynFilterk(·)表示第k个动态滤波器。然后将 { X d f ( k ) } k = 1 K \{X_{df}(k)\}^K_{k=1} {Xdf(k)}k=1K送到自适应调制单元中以计算注意力系数矩阵 A a m A_{am} Aam: A a m = ω S i g m o i d ( ∑ k = 1 K X d f ( k ) ) A_{am} = ωSigmoid(\sum^K_{k=1} X_{df}(k)) Aam=ωSigmoid(∑k=1KXdf(k)),其中Sigmoid(·)表示sigmoid运算,并且ω为2。最后,输出特征Xo定义如下: X o = X u ⊗ R e v e r s e ( A a m ) + X d ⊗ A a m X_o = X_u\otimes Reverse(A_{am})+X_d \otimes A_{am} Xo=Xu⊗Reverse(Aam)+Xd⊗Aam。Reverse(·)是一种反向运算[Reverse attention for salient object detection]
级联功能传播。利用频率先验特征的优点,首先将频率先验信息嵌入到协调后的特征中。由于嵌入在频率先验中的特征信息具有很强的表示能力,为了进一步充分利用这些信息,采用了级联的方法将信息从低分辨率的深层语义传播到浅层的高分辨率特征空间。因此,在FPEM中,有两个级联的频率嵌入组件。第一频率嵌入组件使用嵌入到协调特征中的频率先验作为输入,以获得频率嵌入的协调特征。然后,第二频率嵌入组件将第一频率嵌入组件的输出和上层FPEM的输出作为输入,实现从深层语义到浅层语义的转换。考虑到最深层的特征丢失了上一层的输出,通过使用转换块来丰富全局语义,从X6获得了E6。最后得到E0,为最终结果。
损失函数
地面实况用相同的损失函数L监督六个FPEM和E6的预测,损失函数L由加权的交集大于并集(IoU)损失Lω IoU组成[F3net: fusion, feedback and focus for salient object detection]和加权二元交叉熵(BCE)损失Lω BCE [F3net: fusion, feedback and focus for salient object detection]定义如下:
![]()
其中P和G表示预测和真值图。
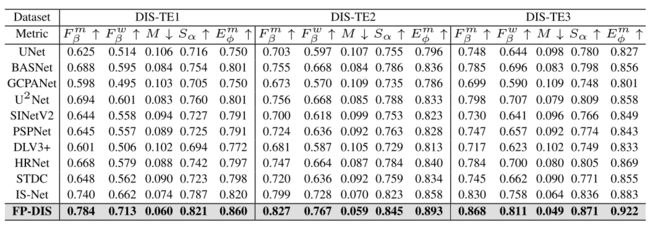
4. 实验与结果
在基准数据集DIS 5 K上进行实验:整个数据集分为三个子集:DIS-TR,DIS-VD和DIS-TE。DIS-TR和DIS-VD分别包含3,000张训练图像和470张验证图像。DIS-TE被进一步分成四个子集(DIS-TE 1,2,3,4)与上升的形状复杂性,每个包含500个图像。