MYSQL高级——索引上篇
1、为什么使用索引?
索引的本质就是一种数据结构,帮助我们以高效的查找算法来找到数据。
在MySQL中,索引是在存储引擎中实现的,不同的存储引擎对于索引有着不同的实现方式。存储引擎可以定义每个表的 最大索引数和 最大索引长度。
使用索引有以下的优点:
- 减少磁盘的I/O次数,提高查询速率;
- 通过唯一索引保证字段的唯一性;
- 显著减少查询中分组和排序的时间;
- 加速表和表之间的连接 ;
当然,增加索引也有一些缺点:
- 创建索引和维护索引要耗费时间;
- 索引需要占磁盘空间 ,除了数据表占数据空间之 外,每一个索引还要占一定的物理空间, 存储在磁盘上;
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度;
2、InnoDB中索引的推演过程
对于一个表,有c1,c2,c3三个字段,设置c1为主键:
mysql> CREATE TABLE index_demo(
-> c1 INT,
-> c2 INT,
-> c3 CHAR(1),
-> PRIMARY KEY(c1)
-> ) ROW_FORMAT = Compact;则对于一条记录的示意图可以为:
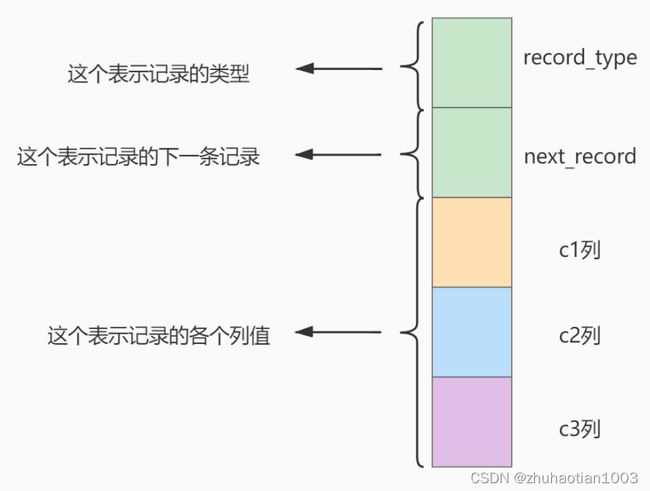
InnoDB怎么区分一条记录是普通的 用户记录 还是 目录项记录 呢?使用记录头信息里的 record_type 属性,它的各自取值代表的意思如下:
-
0:普通的用户记录
-
1:目录项记录
-
2:最小记录
-
3:最大记录
假设我们的数据页只能放三条记录,目录页只能放四条记录,则索引构建的逐步过程为:
1)在每个数据页中对于普通的用户记录按照主键有序来存放记录:

2)增加目录项记录的页,目录项记录只有 主键值和页的编号 两个列:

3)目录项记录页的目录页,大目录里嵌套小目录:
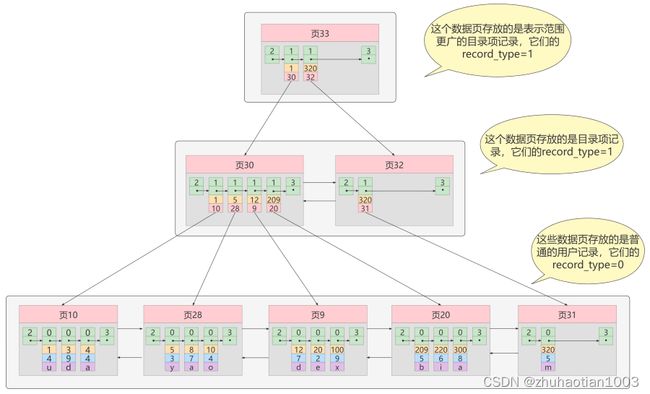
上图的数据结构,就被抽象成为了B+树的数据结构。
一般情况下,我们用到的 B+树都不会超过4层 ,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有所谓的 Page Directory (页目录),所以在页面内也可以通过 二分法 实现快速 定位记录。
3、聚簇索引与非聚簇索引
3.1 聚簇索引
聚簇索引是指,所有的用户记录都存在叶子节点的一种存储方式。也就是所谓的 "索引即数据,数据即索引" 的概念。
具体的来说,由上面的图,有以下几个特点:
- 在最底层的数据页和上层的目录页内,都是根据页中的主键大小顺序排成一个 单向链表 。
- 在同级的数据页或目录页之间,都是按照主键的大小顺序排成一个 双向链表 。
- 完整的用户记录储存在叶子节点 。
在MYSQL中,InnoDB 会 自动`的为我们创建聚簇索引。
优点
-
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快 -
聚簇索引对于主键的
排序查找和范围查找速度非常快 -
按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不用从多 个数据块中提取数据,所以
节省了大量的io操作。
缺点
-
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。 -
更新主键的代价很高,因为将会导致被更新的行移动。
3.2 非聚簇索引
非聚簇索引也称为二级索引或者辅助索引,以c2列构成的二级索引B+树示意图如下:

此时可以看到,与聚簇索引相比,非聚簇索引B+树的叶子节点存放的并不是完整的用户记录信息,而是数据的地址信息(c2列+主键),目录页中也变成了c2列+页号的组合(而不是主键+页号)。
因此,如果我们想根 据c2列的值查找到完整的用户记录的话,仍然需要到 聚簇索引 中再查一遍,这个过程称为 回表 。
3.3 聚簇 vs 非聚簇
-
聚簇索引的
叶子节点存储的就是我们的数据记录, 非聚簇索引的叶子节点存储的是数据位置。非聚簇索引不会影响数据表的物理存储顺序。 -
一个表
只能有一个聚簇索引,因为只能有一种排序存储的方式,但可以有多个非聚簇索引,也就是多个索引目录提供数据检索。 -
使用聚簇索引的时候,数据的
查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚簇索引低。
4、MyISAM 与 InnoDB引擎在索引方面的对比
在MyISAM 与 InnoDB中,都支持B+树索引。
回顾引擎篇讲的MyISAM 与 InnoDB的数据文件的格式差别:

InooDB是ibd文件同时存储数据和索引,MyISAM是myi和myd文件,数据和索引分开存储
在MyISAM中,可以设置二级索引:

即MyISAM的索引方式都是“非聚簇”的,与InnoDB包含1个聚簇索引是不同的。
5、选择B+树的合理性(与其他的对比)
5.1 hash查询
hash索引更适合于判断等值查询的场景,对于范围查询,效率并不高。同时,hash无法解决排序问题,对于hash冲突也不好解决。
5.2 二叉搜索树(BST)
在有些情况下BST的深度会非常大,会退化为单链表的形式,复杂度退化为为o(n)。
5.3 平衡二叉树(AVL)


我们可以将2叉树改为m叉树,就可以减小树的深度,减小磁盘I/O次数 。
5.4 B树
B树,即 多路平衡查找树 。它的高度远小于平衡二叉树的高度。

5.5 B+树
B+树也是一种多路搜索树,是在B树的基础上做出的改进。B+树更适合文件系统:
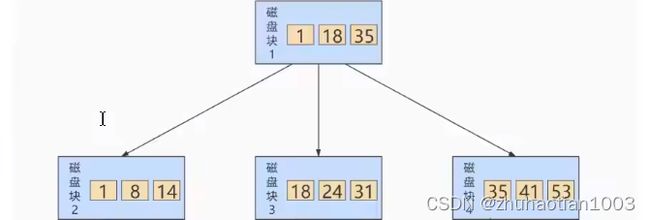
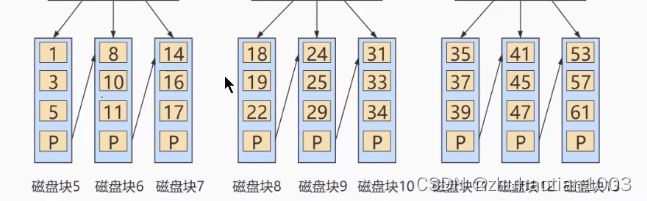
对比B树, B+树有个鲜明特点,就是B+树的中间节点并不直接存储数据,为什么要这样设计呢?
- 首先,B+树查询效率更稳定。因为B+树每次只有访问到叶子节点才能找到对应的数据,而在B树中,非叶子也会存数据,就会造成查询效率不稳定的情况。
- 其次,B+树查询效率更高。因为通常B+树比B树更加矮胖,即深度更低,查询所需的I/O也会更少。
- 在范围查询上,B+树也比B树效率高。
思考题:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?

