YOLOv8改进 更换轻量化模型MobileNetV3

一、MobileNetV3论文

论文地址:1905.02244.pdf (arxiv.org)
二、 MobileNetV3网络结构
MobileNetV3引入了一种新的操作单元,称为"Mobile Inverted Residual Bottleneck",它由一个1x1卷积层和一个3x3深度可分离卷积层组成。这个操作单元通过使用非线性激活函数,如ReLU6,并且在残差连接中使用线性投影,来提高网络的特征表示能力。
MobileNetV3使用全局平均池化层来降低特征图的维度,并使用一个1x1卷积层将特征图的通道数压缩成最终的类别数量。最后,使用softmax函数对输出进行归一化,得到每个类别的概率分布。

MobileNetV3是一种高效轻量级的网络结构,可以在移动设备和资源受限的环境下进行实时图像分类和目标检测任务。它在准确性和计算效率之间取得了良好的平衡。
三、代码实现
1、在ultralytics\ultralytics\nn路径下新建一个文件夹命名为backbone,用于存放网络结构修改的代码。

并在该 backbone文件夹路径下新建py文件MobileNetV3.py,并在该文件里添加MobileNetV3相关的结构的代码:
from torch import nn
# ###### Mobilenetv3
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class conv_bn_hswish(nn.Module):
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
# self.act = h_swish()
self.act = nn.Hardswish(inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNetV3_InvertedResidual(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
super(MobileNetV3_InvertedResidual, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
# h_swish() if use_hs else nn.ReLU(inplace=True),
nn.Hardswish(inplace=True) if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
# h_swish() if use_hs else nn.ReLU(inplace=True),
nn.Hardswish(inplace=True) if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# h_swish() if use_hs else nn.ReLU(inplace=True),
nn.Hardswish(inplace=True) if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y2、在ultralytics\ultralytics\nn\tasks.py文件中加入MobileNetV3模块
开头先从新建的文件夹引入MobileNetV3的包:
from ultralytics.nn.backbone.MobileNetV3 import *并且文件的def _predict_once函数模块要替换为更换网络结构后的预测模块:

替换为:
def _predict_once(self, x, profile=False, visualize=False):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
# for i in x:
# if i is not None:
# print(i.size())
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x然后在def parse_model函数模块中加入MobileNetV3:
elif m in {conv_bn_hswish, MobileNetV3_InvertedResidual}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]3、创建yolov8+MobileNetV3.yaml文件:
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.50, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
backbone:
# [from, repeats, module, args]
- [-1, 1, conv_bn_hswish, [16, 2]] # 0-P1/2
- [-1, 1, MobileNetV3_InvertedResidual, [16, 16, 3, 2, 1, 0]] # 1-p2/4
- [-1, 1, MobileNetV3_InvertedResidual, [24, 72, 3, 2, 0, 0]] # 2-p3/8
- [-1, 1, MobileNetV3_InvertedResidual, [24, 88, 3, 1, 0, 0]]
- [-1, 1, MobileNetV3_InvertedResidual, [40, 96, 5, 2, 1, 1]] # 4-p4/16
- [-1, 1, MobileNetV3_InvertedResidual, [40, 240, 5, 1, 1, 1]]
- [-1, 1, MobileNetV3_InvertedResidual, [40, 240, 5, 1, 1, 1]]
- [-1, 1, MobileNetV3_InvertedResidual, [48, 120, 5, 1, 1, 1]]
- [-1, 1, MobileNetV3_InvertedResidual, [48, 144, 5, 1, 1, 1]]
- [-1, 1, MobileNetV3_InvertedResidual, [96, 288, 5, 2, 1, 1]] # 9-p5/32
- [-1, 1, MobileNetV3_InvertedResidual, [96, 576, 5, 1, 1, 1]]
- [-1, 1, MobileNetV3_InvertedResidual, [96, 576, 5, 1, 1, 1]]
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 8], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [256]] # 14
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 3], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [128]] # 17 (P3/8-small)
- [-1, 1, Conv, [128, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [256]] # 20 (P4/16-medium)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [512]] # 23 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)四、运行验证
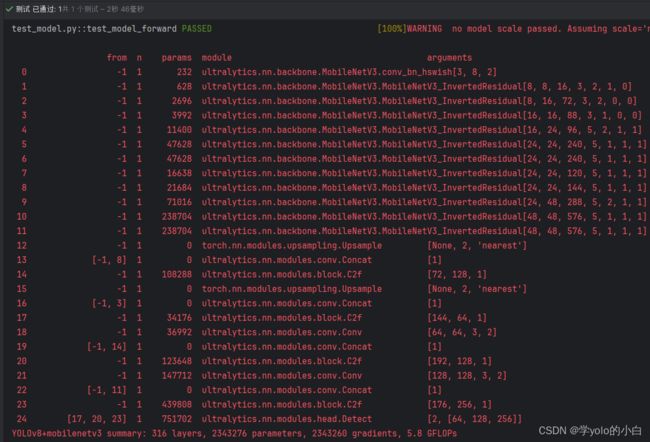
可以看出模型结构已经变成MobileNetV3的主干网络。