Elasticsearch:如何使用 Elasticsearch 进行排序

虽然你在唱这首歌时可能会想象圣诞老人,但欧洲民间传说,尤其是阿尔卑斯地区的民间传说,有两个传奇人物圣尼古拉斯和坎普斯。 象征着慷慨和善良的圣尼古拉斯,在 12 月 6 日 为乖巧的孩子们带来礼物和欢乐! 相比之下,坎普斯是一种有角且具有威胁性的生物,它可以在前一天晚上对行为不端的孩子发出警告。 他们共同创造了独特而持久的传统,鼓励节日期间的慷慨和良好行为。

当然,他们正在使用 Elasticsearch 来追踪行为不端和行为良好的孩子。 但他们如何确定访问的优先顺序呢? 本文深入探讨了 Elasticsearch 的一些更有趣的排序选项 - 有关所有选项,请参阅官方文档。 虽然该示例使用圣尼古拉斯和坎普斯主题,但这些概念适用于许多其他场景。
示例数据集
ChatGPT 可以使用提示为我们生成映射和数据集:
generate an elasticsearch mapping and bulk query with 10 christmas themed characters (like the grinch) containing the fields: name, date of birth, geolocation, timezone, behavior (can be good, bad, or mixed), and points (an array of mixed +1 or -1 values)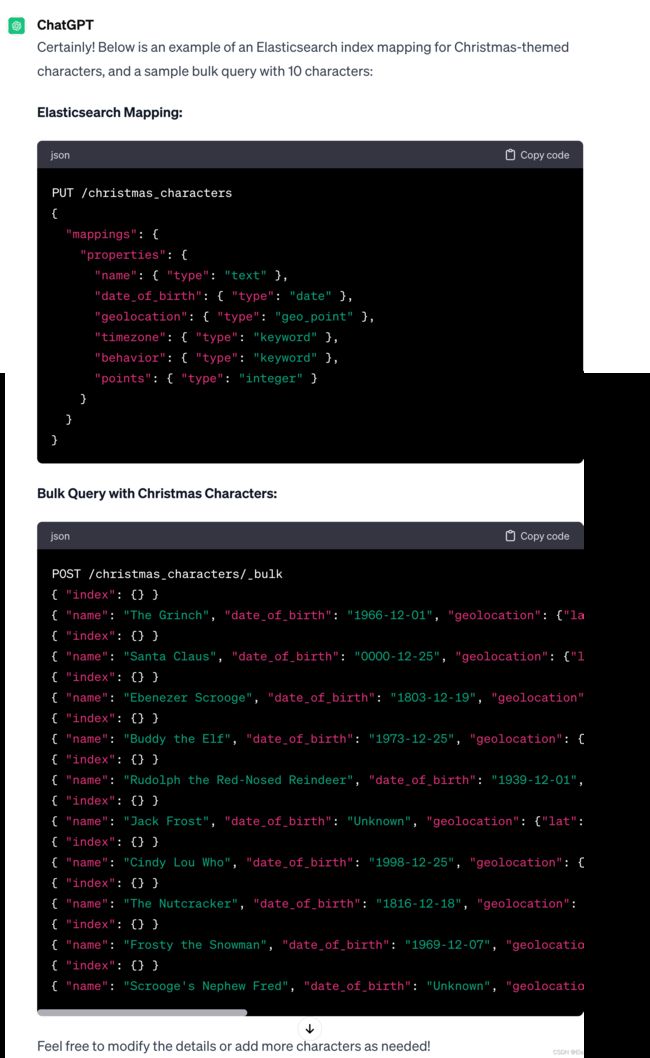
mappings
PUT /christmas_characters
{
"mappings": {
"properties": {
"name": { "type": "text" },
"date_of_birth": { "type": "date" },
"geolocation": { "type": "geo_point" },
"timezone": { "type": "keyword" },
"behavior": { "type": "keyword" },
"points": { "type": "integer" }
}
}
}Bulk Query
POST /christmas_characters/_bulk
{ "index": {} }
{ "name": "The Grinch", "date_of_birth": "1966-12-01", "geolocation": {"lat": 48.8566, "lon": 2.3522}, "timezone": "UTC", "behavior": "bad", "points": [ -1, -1, -1, -1, -1 ] }
{ "index": {} }
{ "name": "Santa Claus", "date_of_birth": "0000-12-25", "geolocation": {"lat": 90, "lon": 0}, "timezone": "UTC", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Ebenezer Scrooge", "date_of_birth": "1803-12-19", "geolocation": {"lat": 51.509865, "lon": -0.118092}, "timezone": "GMT", "behavior": "mixed", "points": [ -1, 1, -1, 1, -1 ] }
{ "index": {} }
{ "name": "Buddy the Elf", "date_of_birth": "1973-12-25", "geolocation": {"lat": 40.7128, "lon": -74.0060}, "timezone": "EST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Rudolph the Red-Nosed Reindeer", "date_of_birth": "1939-12-01", "geolocation": {"lat": 61.016, "lon": -149.737}, "timezone": "AKST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Jack Frost", "date_of_birth": "Unknown", "geolocation": {"lat": 44.9778, "lon": -93.2650}, "timezone": "CST", "behavior": "mixed", "points": [ -1, 1, -1, 1, -1 ] }
{ "index": {} }
{ "name": "Cindy Lou Who", "date_of_birth": "1998-12-25", "geolocation": {"lat": 41.8781, "lon": -87.6298}, "timezone": "CST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "The Nutcracker", "date_of_birth": "1816-12-18", "geolocation": {"lat": 55.7558, "lon": 37.6176}, "timezone": "MSK", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Frosty the Snowman", "date_of_birth": "1969-12-07", "geolocation": {"lat": 34.0522, "lon": -118.2437}, "timezone": "PST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Scrooge's Nephew Fred", "date_of_birth": "Unknown", "geolocation": {"lat": 51.509865, "lon": -0.118092}, "timezone": "GMT", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }从上面的输出中我们可以看到有两个文档中的 date_of_birth 字段值为 "Unknow"。我们需要对它进行修正。修正后的文档为:
POST /christmas_characters/_bulk
{ "index": {} }
{ "name": "The Grinch", "date_of_birth": "1966-12-01", "geolocation": {"lat": 48.8566, "lon": 2.3522}, "timezone": "UTC", "behavior": "bad", "points": [ -1, -1, -1, -1, -1 ] }
{ "index": {} }
{ "name": "Santa Claus", "date_of_birth": "0000-12-25", "geolocation": {"lat": 90, "lon": 0}, "timezone": "UTC", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Ebenezer Scrooge", "date_of_birth": "1803-12-19", "geolocation": {"lat": 51.509865, "lon": -0.118092}, "timezone": "GMT", "behavior": "mixed", "points": [ -1, 1, -1, 1, -1 ] }
{ "index": {} }
{ "name": "Buddy the Elf", "date_of_birth": "1973-12-25", "geolocation": {"lat": 40.7128, "lon": -74.0060}, "timezone": "EST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Rudolph the Red-Nosed Reindeer", "date_of_birth": "1939-12-01", "geolocation": {"lat": 61.016, "lon": -149.737}, "timezone": "AKST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Jack Frost", "date_of_birth": "1539-11-01", "geolocation": {"lat": 44.9778, "lon": -93.2650}, "timezone": "CST", "behavior": "mixed", "points": [ -1, 1, -1, 1, -1 ] }
{ "index": {} }
{ "name": "Cindy Lou Who", "date_of_birth": "1998-12-25", "geolocation": {"lat": 41.8781, "lon": -87.6298}, "timezone": "CST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "The Nutcracker", "date_of_birth": "1816-12-18", "geolocation": {"lat": 55.7558, "lon": 37.6176}, "timezone": "MSK", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Frosty the Snowman", "date_of_birth": "1969-12-07", "geolocation": {"lat": 34.0522, "lon": -118.2437}, "timezone": "PST", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }
{ "index": {} }
{ "name": "Scrooge's Nephew Fred", "date_of_birth": "1970-05-07", "geolocation": {"lat": 51.509865, "lon": -0.118092}, "timezone": "GMT", "behavior": "good", "points": [ 1, 1, 1, 1, 1 ] }再次运行上面的命令,我们可以得到输入正确的 Elasticsearch 索引。在下面,我们针对这个数据集来进行排序。
针对 visits 来进行排序
让我们看看如何对圣尼古拉斯和坎普斯的来访进行排序,看看你是否值得一份礼物或一块煤炭 —— 这是坎普斯送给行为不端的孩子的传统礼物。

根据年龄 age
或许年纪越小,等待的耐心就越少。 或者你需要早点睡觉。 因此,让我们使用 match_all 来匹配所有文档,并按 date_of_birth 字段降序排序。
GET /christmas_characters/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"date_of_birth": {
"order": "desc"
}
}
]
}上面显示的结果为:

为了能够得到更为精简的搜索结果,我们可以改写上面的搜索为:
GET /christmas_characters/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"date_of_birth": {
"order": "desc"
}
}
],
"_source": false,
"fields": [
"name",
"date_of_birth"
]
}在上面,我们仅显示 name 及 date_of_birth:

安装 Points 及 age 来进行排序
也许你想从表现最好的人开始,由具有良好 (1) 和不良 (-1) 行为的点数组表示。 这里,我们可以按照数组的值的总和进行排序,如果多个总和的值相等,则再次添加基于年龄的辅助排序条件。
GET /christmas_characters/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"points": {
"order": "desc",
"mode": "sum"
},
"date_of_birth": {
"order": "desc"
}
}
],
"_source": false,
"fields": [
"name",
"points",
"date_of_birth"
]
}
按照远近来进行排名
出于实际原因,按邻近程度排序可能是最简单的。 据说圣尼古拉斯住在北极 —— 北纬 90 度和东经 0 度,作为他 “家” 的象征性地理点:
GET /christmas_characters/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"geolocation": [
0,
90
],
"order": "asc",
"unit": "km",
"distance_type": "arc"
}
}
],
"_source": false,
"fields": [
"name"
]
}
注意 geolocation 中经度和纬度的顺序(我第一次尝试时总是会出错),然后我们希望根据更精确但较慢的 arc(而不是 plane)距离。从上面的结果中可以看出来,Santa Claus 是离搜索距离最近的文档。
通过脚本
为了获得最大的灵活性,Elasticsearch 的脚本语言 Painless 为您提供了你想要的所有选项。 例如,如果你按属性 “good”、“mixed”、“bad”(按此顺序)排序,则没有任何现有字段可以让你这样做。 但使用脚本,你可以为每个属性分配一个数值(在查询时),然后基于该值进行排序。 并再次添加年龄决胜条件。你可以通过学习 “Elastic:开发者上手指南” 中的 “Painless 编程” 来了解更多的关于 Painless 的编程。
GET /christmas_characters/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"sort": [
{
"_script": {
"type": "number",
"script": {
"lang": "painless",
"source": """
if(doc['behavior'].value == 'good'){
return 1;
} else if(doc['behavior'].value == 'mixed'){
return 2;
} else {
return 3;
}
"""
},
"order": "asc"
}
},
{
"date_of_birth": {
"order": "desc"
}
}
]
}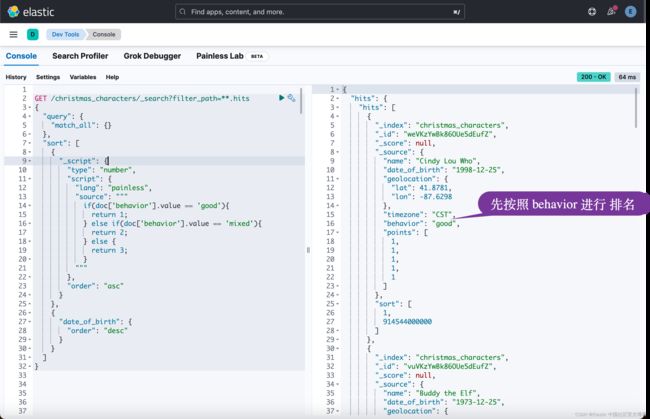
在上面,我们使用 Painless 脚本来计算一个 script field。它是一个 number 类型的数据。具体它的名字是什么,我们无需知道它的名字。我们可以在 sort 里对它进行排名。
不过,只有在必要时才这样做 —— 按脚本排序比按索引字段排序要慢,而且使用 Painless 常常给人与它的名字相反的感觉。 如果你想经常这样排序,请在摄取时显式添加该字段。
使用 runtime field 来进行排序
你可以再次使用 Painless 对(查询时)运行时字段执行与上一个示例相同的操作 - 尽管此示例按时区排序,以便每个人都可以在晚上进行访问。 此代码片段还引入了 missing 的概念,通常使用魔术值 _first 或 _last,但它也可以是静态值,如本例所示。
GET /christmas_characters/_search?filter_path=**.hits
{
"query": {
"match_all": {}
},
"runtime_mappings": {
"numeric_timezone": {
"type": "double",
"script": {
"source": """
if(doc['timezone'].value == 'GMT'){
emit(-5);
} else if(doc['timezone'].value == 'UTC' || doc['timezone'].value == 'Europe/London'){
emit(0);
} else if(doc['timezone'].value == 'CST'){
emit(5.5)
} else if(doc['timezone'].value == 'EST'){
emit(4)
} else if(doc['timezone'].value == 'AKST'){
emit(3)
} else if(doc['timezone'].value == 'PST'){
emit(1)
} else if(doc['timezone'].value == 'MSK'){
emit(-2)
}
"""
}
}
},
"sort": [
{
"numeric_timezone": {
"order": "desc",
"missing": -0.1
}
},
{
"date_of_birth": {
"order": "desc"
}
}
]
}
使用 ES|QL
在结束之前,Elasticsearch 中有一种新的查询语言:Elasticsearch 查询语言 (ES|QL)。它有一个新端点 (_query)、一种新的且希望更紧凑的语法来编写查询,以及不同的输出选项。
注意:你需要至少安装 Elastic Stack 8.11.0 及以上的版本才可以体验这个功能!
编写与第一个 Painless 示例类似的查询如下所示 — 在 EVAL 中使用 CASE 语句。 这里不讨论太多细节,这是一种将结果传递到下一个语句的过程语言。
POST _query?format=txt
{
"query": """
FROM christmas_characters
| EVAL numeric_behavior = CASE(
behavior == "good", 1,
behavior == "mixed", 2,
3
)
| SORT numeric_behavior ASC, date_of_birth DESC
| KEEP name, behavior, numeric_behavior, date_of_birth
| LIMIT 10
"""
}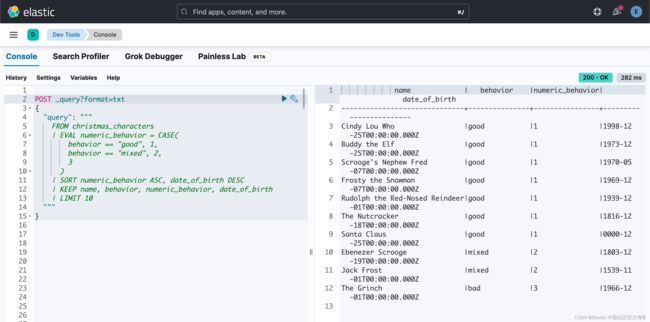
(可配置的)输出格式可以比漂亮打印的 JSON 更加简洁。
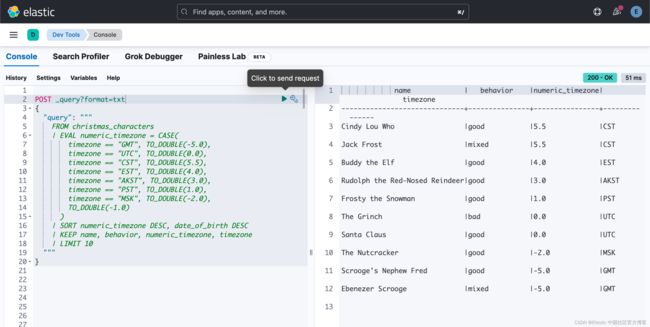
这就是第二个 Painless 查询在 ES|QL 中的样子 —— 这个有点棘手,因为它需要转换 TO_DOUBLE() 并且结果有点长。 不过,它应该仍然比在 Painless 中写这个更容易理解。
POST _query?format=txt
{
"query": """
FROM christmas_characters
| EVAL numeric_timezone = CASE(
timezone == "GMT", TO_DOUBLE(-5.0),
timezone == "UTC", TO_DOUBLE(0.0),
timezone == "CST", TO_DOUBLE(5.5),
timezone == "EST", TO_DOUBLE(4.0),
timezone == "AKST", TO_DOUBLE(3.0),
timezone == "PST", TO_DOUBLE(1.0),
timezone == "MSK", TO_DOUBLE(-2.0),
TO_DOUBLE(-1.0)
)
| SORT numeric_timezone DESC, date_of_birth DESC
| KEEP name, behavior, numeric_timezone, timezone
| LIMIT 10
"""
}
结论
现在所有的分类都完成了,他们就去送礼物了。

更多关于排序的文章,请阅读
- Elasticsearch:对搜索结果排序 - Sort
-
Elasticsearch:在 Elasticsearch 中按距离有效地对地理点进行排序