Java进阶之深入理解泛型的实现机制
1 Java泛型的实现机制是怎样的?
答:1.为什么要使用泛型程序设计?泛型就是类型参数化,处理的数据类型不是固定的,而是可以作为参数传入。意味着编写的代码可以对多种不同的类型的对象重用。类型参数的好处有:(1)调用get()的时候,我们不需要进行强制类型转换;(2)编译器会检查插入类型,防止插入错误类型的对象;(3)让程序更易读,也更安全。
2.Java采用类型擦除,这里我通过三个点来说明哈:什么是类型擦除、类型擦除有什么好处、类型擦除存在什么问题?
(1)举例说什么是类型擦除?class Node { T getNode() { return node;} }:因为T是一个无限定的变量,所以直接用Object替代;可以包含不同类型的Node,例如:Node< String >、Node< Double >,但是它们在擦除类型后,都会变成原始的Node。
(2)类型擦除有什么好处呢?①减小运行时内存的负担。例如:存在类似List< Integer >,List< Double >等这样的类型,真正被加载进方法区存储的只有List类型,类型擦除后减少了内存的负担。②向前兼容性好。Java在1.5版本才推出泛型这个概念,当时Java语言的用户群已经是一个相当庞大的数量了,所向前兼容也是当时Java开发者着重考虑的一个点。
(3)类型擦除存在什么问题?①基本类型无法作为泛型实参:在使用过程中就意味着会有装箱和拆箱的开销:为此,谷歌也推出了SpareArray的数据结构来提高执行效率。②泛型类型无法用作方法重载,因为类型擦除意味着List< Integer >和List< String>编译后其类型都是List,也就是属于同个方法。③泛型类型无法当做真实类型使用,由于类型擦除后像new T()这样的类型是不存在的,所以也就无法直接当成真实类型使用。这也是为什么Gson.fromJson需要传入Class?因为返回值T被类型擦除成Object,在定义时不知道返回什么具体对象,所以需要传入Class。④静态方法无法引用类泛型参数:类的泛型参数只有在类实例化的时候才知道,而静态方法的执行不需要有类的示例存在,所以静态方法无法引用类泛型参数。⑤泛型类型会带来类型强转的运行时开销。
3.针对类型擦除存在的问题,补救方案是“类型通配符和边界”。
(1)先说PECS规则,分为:①上界通配符,频繁往外读取数据:Producer = output = out(协变);和②下界通配符< ? super T>,频繁往里面插入数据:Comsumer = input = in(型变)。
(2)然后上下界通配符存在副作用。
当存入时:依赖泛型类型,可知类型子类可存:
①? extends / out Fruit:虽然知道最大类型是Frult,但具体什么类型不知道,所以不可存;
②? super / in Fruit:知道了类型一定是Fruit的自己或父类,所以只要是Fruit的子类都可存入;
当获取时:依赖承接类型,可知类型的最大类型作为承接者:
①? extends / out Fruit:虽然知道最大类型是Frult,所以可用Fruit或父类Food来承接获取;
②? super / in Fruit:不知道最大类型是什么,只能选万物基类Object来承接,也快丢掉所有数据了,不适合读取;
4.类型擦除后怎么获取泛型参数?
(1)为什么可以获取泛型参数?泛型类型虽然被擦除了,但是被擦除的类型信息还是会以某种形式存储下来,并支持在运行时获取。这种形式就是指元素附加的签名信息(Signatures),查看字节码时可以看到泛型对应的Signatures标记;
(2)可以通过getGenericReturnType()等反射获取方法元素泛型;
(3)Gson是如何通过借助TypeToken获取泛型参数的类型的方法?Gson构建泛型Type,实际上调用的就是getGenericReturnTypes方法。获得了匿名内部类的Class类型genericType,但是并没有直接将泛型参数T的Class类型传进来,那又是如何获得泛型参数的类型的呢?通过匿名内部类型genericType,可以访问到它父类TypeToken的构造方法,再获取Class字节码中保存的泛型签名信息,即可获取类型List< Integer >等。

1.1 这道题想考察什么?
答:(1)考察要点
●对Java泛型使用是否仅停留在集合框架的使用(初级)
●对Java泛型的实现机制的认知和理解、是否有足够的项目开发实战和“踩坑”经验(中级)
●对泛型(或模板)编程是否有深入的对比研究、对常见的框架原理是否有过深入剖析(高级)
(2)题目剖析
●题目区分度非常大
●回答需要提及以下几点才能显得有亮点:①类型擦除从编译角度的细节;②类型擦除对运行时的影响;③类型擦除对反射的影响;④对比类型不擦除的语言;⑤为什么Java选择类型擦除;
●可从类型擦除的优劣来着手分析回答。
2 为什么要使用泛型程序设计?
答:泛型就是类型参数化,处理的数据类型不是固定的,而是可以作为参数传入。意味着编写的代码可以对多种不同的类型的对象重用。类型参数的好处有:(1)调用get()的时候,我们不需要进行强制类型转换;(2)编译器会检查插入类型,防止插入错误类型的对象;(3)让程序更易读,也更安全。如下面的例子:
ArrayList files = new ArrayList<String>();
String fileName = files.get(0); // (1)
files.add(new File("")); // 只能插入String,如果插入File(),提示:编译错误 (2)
// 定义一个接口
interface Money<T> {
T get(intindex);
boolean add(T e);
}
// 定义一个类
public class Apple<T>{
private T info;
public Apple(T info) {
this.info = info;
}
3 什么是类型擦除?
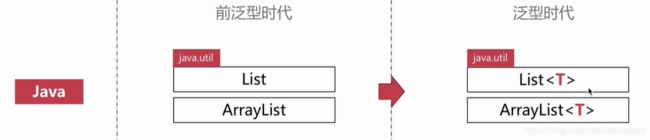
答:虚拟机没有泛型类型对象——所有对象都属于普通类。无论何时定义一个泛型类型,都会自动提供一个相应的原始类型(raw type)。这个原始类型的名字就是去掉类型参数后的泛型类型名,类型变量会被擦除,并替换为其限定类型(或者对于无限定的变量则替换为Object)。
3.1 如何验证类型擦除?
答:因为T是一个无限定的变量,所以直接用Object替代;Pair pair = getNode()会将返回的Object类型强制转换为Pair类型;可以包含不同类型的Node,例如:Node< String >、Node< Double >,但是它们在擦除类型后,都会变成原始的Node。
(1)类型擦除前
class Node<T> {
T node;
public Node() {
this.node = null;
}
public T getNode() {
return node;
}
}
(2)类型擦除后
class Node {
Object node;
public Node() {
this.node = null;
}
public Object getNode() {
return node;
}
}
(3)选取getNode()方法的字节码分析
// @groovyx.ast.bytecode.Bytecode
// public Object getNode() {
// aload 0
// getfield com.read.kotlinlib.generic.GenericClass$Node.node >> Object
// areturn
// }
// // access flags 0x1
// // signature ()TT;
// // declaration: T getNode()
// public getNode()Ljava/lang/Object;
// L0
// LINENUMBER 35 L0
// ALOAD 0
// GETFIELD com/read/kotlinlib/generic/GenericClass$Node.node : Ljava/lang/Object;
// ARETURN
// L1
// LOCALVARIABLE this Lcom/read/kotlinlib/generic/GenericClass$Node; L0 L1 0
// // signature Lcom/read/kotlinlib/generic/GenericClass.Node;
// // declaration: com.read.kotlinlib.generic.GenericClass.Node
// MAXSTACK = 1
// MAXLOCALS = 1
4 类型擦除有什么好处?
答:(1)减小运行时内存的负担。例如:存在类似List< Integer >,List< Double >等这样的类型,真正被加载进方法区存储的只有List类型,类型擦除后减少了内存的负担。
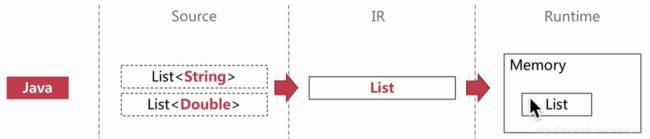
(2)向前兼容性好。Java在1.5版本才推出泛型这个概念,当时Java语言的用户群已经是一个相当庞大的数量了,所以向前兼容也是当时Java开发者着重考虑的一个点。不管在前泛型时代还是泛型时代,以下的写法都是被允许的,它们的泛型元素都是Raw类型:
List list;
ArrayList array;
5 类型擦除存在什么问题?
答:
(1)基本类型无法作为泛型实参

在使用过程中就意味着会有装箱和拆箱的开销:为此,谷歌也推出了SpareArray的数据结构来提高执行效率,如使用SparseIntArray用来取代Integer做为key类型的时候用HashMap
private int[] mKeys;
private Object[] mValues;
Android内存优化(使用SparseArray和ArrayMap代替HashMap)
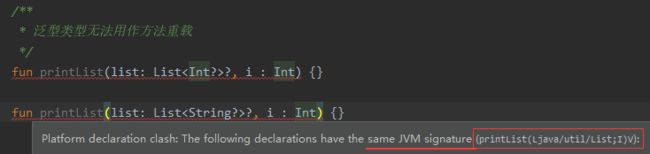
(2)泛型类型无法用作方法重载
类型擦除意味着List< Integer >和List< String>编译后其类型都是List,也就是属于同个方法:
(3)泛型类型无法当做真实类型使用
由于类型擦除后像new T()这样的类型是不存在的,所以也就无法直接当成真实类型使用:

这也是为什么Gson.fromJson需要传入Class类型?

答:因为返回值T被类型擦除成Object,在定义时不知道返回什么具体对象,所以需要传入Class。后面说到通过字节码里面附加的签名信息拿到返回对象具体类型。为什么有不同的方法?因为反射得解析签名信息,而且只有在调用的时候才有这个信息,而fromJson在定义的时候是没有这个信息的。
(4)静态方法无法引用类泛型参数
类的泛型参数只有在类实例化的时候才知道,而静态方法的执行不需要有类的示例存在,所以静态方法无法引用类泛型参数。但是,静态方法可以自己定义泛型类型,然后引用泛型参数。

(5)泛型类型会带来类型强转的运行时开销
List<String> strList = new ArrayList<String>();
String value = strList.get(0);
实际字节码指令执行strList.get()方法时,经过类型擦除后,还是需要做类型强转:
// INVOKEINTERFACE java/util/List.get (I)Ljava/lang/Object;
// CHECKCAST java/lang/String
在1.5以下版本,需要额外强转;在1.5+版本,不需要额外强转,但是ArrayList内部本质会进行强转:

6 类型擦除的补救方案“类型通配符和边界”的原理?
答:和< ? super T >是Java泛型中的“通配符(Wildcards)”和“边界(Bounds)”的概念:
< ? extends T >:是指 “上界通配符(Upper Bounds Wildcards)”;< ? super T >:是指 “下界通配符(Lower Bounds Wildcards)”。
6.1 为什么要用通配符和边界?
答:我们有Fruit类,和它的派生类Apple类:
internal open inner class Fruit
internal open inner class Apple : Fruit()
还有一个最简单的容器:Plate类,盘子里可以放一个泛型的“东西”。我们对这个东西做最简单的“放”和“取”的动作:set()和get()方法
internal class Plate<T>(private var item: T) {
fun set(t: T) {
item = t
}
fun get(): T {
return item
}
}
定义一个“水果盘子”,逻辑上水果盘子当然可以装苹果。但实际上Java编译器不允许这个操作,会报错,“装苹果的盘子”无法转换成“装水果的盘子”。
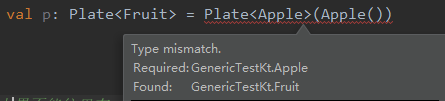
所以,就算容器里装的东西之间有继承关系,但容器之间是没有继承关系的。为了让泛型用起来更舒服,Sun的大佬就想出了和的办法,来让”水果盘子“和”苹果盘子“之间发生关系。
6.2 什么是 上界 通配符()?对应Kotlin的 协变?
答:
// Java
Plate<? extends Fruit>
// kotlin
Plate<out Fruit>
翻译成人话就是:一个能放水果以及一切是水果派生(子)类的盘子。再直白点就是:啥水果都能放的盘子。Plate和Plate< Apple>最大的区别就是:Plate是Plate< Fruit>以及Plate< Apple>的基类。直接的好处就是,可以用“苹果盘子”给“水果盘子”赋值了。
val p1: Plate<out Fruit> = Plate<Fruit>(Apple())
val p2: Plate<out Fruit> = Plate<Apple>(RedApple())
把Fruit和Apple的例子再扩展一下,食物分成水果和肉类,水果有苹果和香蕉,肉类有猪肉和牛肉,苹果还有两种青苹果和红苹果
// Lev 1
internal open inner class Food
// Lev 2
internal open inner class Fruit : Food()
internal open inner class Meat : Food()
// Lev 3
internal open inner class Apple : Fruit()
internal inner class Banana : Fruit()
internal inner class Pork : Meat()
internal inner class Beef : Meat()
// Lev 4
internal inner class RedApple : Apple()
internal inner class GreenApple : Apple()
在这个体系中,下界通配符 Plate 覆盖下图中蓝色的区域。

6.3 什么是 下界 通配符()?对应Kotlin的 逆变?
答:
// Java
Plate<? super Fruit>
// Kotlin
Plate<in Fruit>
表达的就是相反的概念:一个能放水果以及一切水果父类的盘子。Plate是Plate< Fruit>的基类,但不是Plate< Apple>的基类。对应刚才那个例子,Plate覆盖下图中红色的区域。

6.4 怎么容易记忆 PECS(Producer Extends Consumer Super) + (in & out )?
答:(1)上界通配符,频繁往外读取数据:Producer = output = out(协变);
(2)下界通配符< ? super T>,频繁往里面插入数据:Comsumer = input = in(型变)。

Kotlin 泛型中的 in 和 out 怎么记?
6.5 上下界通配符的副作用?
答:1、存入:依赖泛型类型,可知类型子类可存:
(1)? extends / out Fruit:虽然知道最大类型是Frult,但具体什么类型不知道,所以不可存;
(2)? super / in Fruit:知道了类型一定是Fruit的自己或父类,所以只要是Fruit的子类都可存入;
2、获取:依赖承接类型,可知类型的最大类型作为承接者:
(1)? extends / out Fruit:虽然知道最大类型是Frult,所以可用Fruit或父类Food来承接获取;
(2)? super / in Fruit:不知道最大类型是什么,只能选万物基类Object来承接,也快丢掉所有数据了,不适合读取;

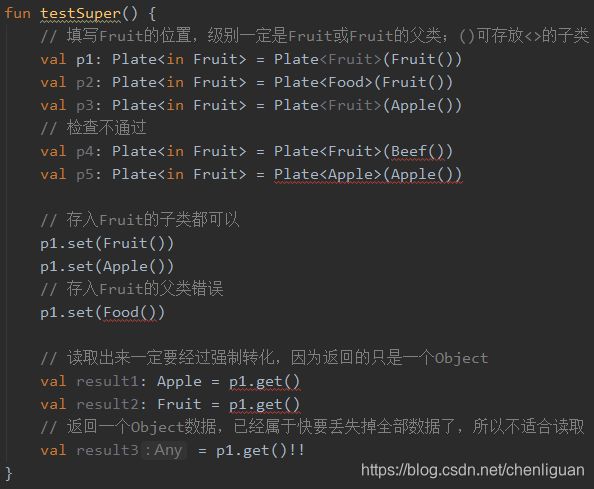
6.6 无限定通配符,没有约束
答:通配符和类型参数的区别就在于,对编译器来说所有的T都代表同一种类型。比如下面这个泛型方法里,三个T都指代同一个类型,要么都是String,要么都是Integer。
public <T> List<T> gsonToList(T str)
但通配符没有这种约束,Plate单纯的就表示:盘子里放了一个东西,是什么我不知道。
6.7 学习链接?
Java泛型中extends和super的区别?
面试官问我:“泛型擦除是什么,会带来什么问题?”
几个搞不太懂的术语:逆变、协变、不变
Java泛型中的PECS原则
《Java核心技术 I》第八章、《Java编程的逻辑-第八章》
7 类型擦除后怎么获取泛型参数?
答:
7.1 什么是方法签名?
答:在虚拟机中,内部类型签名在字节码层面用来识别函数或者类。在Java中,函数签名包括:函数名,参数的数量、类型和顺序;返回值和函数上声明的异常并不属于函数签名的构成部分。
List<String> list // Ljava/util/List;
// 字节码:com.read.kotlinlib.generic/Main/main:(Ljava/lang/String;Ljava/lang/Integer;)Ljava/lang/String;
// 方法签名:com.read.kotlinlib.generic/Main/main:(Ljava/lang/String;Ljava/lang/Integer;)
fun main(a: String?, b: Int?) : String {
return ""
}
(1)下两个函数签名不同:因为他们虽然函数名相同,但是参数类型不同
doSomething(String[] y);
doSomething(String y);
(2)下面三个函数的签名相同:因为他们的函数名相同,参数数量,类型和顺序也一致。
int doSomething(int y)
String doSomething(int x)
int doSomething(int z) throws java.lang.Exception
Java中的方法签名解读
7.2 类型擦除后怎么获取泛型参数?
答:在Java中,泛型类型虽然被擦除了,但是被擦除的类型信息还是会以某种形式存储下来,并支持在运行时获取。这种形式就是指元素附加的签名信息(Signatures),谷歌是这么定义Signatures:
签名对使用Java编程语言编写的声明进行编码,这些声明使用Java虚拟机的类型系统之外的类型。 它们仅支持类文件的反射和调试以及编译。
获取Signatures的方法如下:
public abstract class GenericClass<T> {
Class<T> type;
public GenericClass() {
this.type = (Class<T>) getClass();
}
public List<Map<T, T>> getValue() {
return null;
}
}
private void getGenericsArguments() {
// 匿名内部类
GenericClass<String> genericClass = new GenericClass<String>() {
@Override
public List<Map<String, String>> getValue() { return null;}
};
// 获取类元素泛型
ParameterizedType superType =
(ParameterizedType) genericClass.getClass().getGenericSuperclass();
for (Type actualTypeArgument : superType.getActualTypeArguments()) {
System.out.println("Superclass + actualTypeArgument: " + actualTypeArgument);
// Superclass + actualTypeArgument: class java.lang.String
}
// 获取方法元素泛型
ParameterizedType methodType =
(ParameterizedType) genericClass.getClass().getMethod("getValue").getGenericReturnType();
for (Type actualTypeArgument : methodType.getActualTypeArguments()) {
System.out.println("Method + actualTypeArgument: " + actualTypeArgument);
// Method + actualTypeArgument: java.util.Map所以,在混淆时需要保留签名信息:
-keepattributes Signature
7.3 如何保存 泛型类型签名信息?
答:(1)对比List是否加泛型

通用类型存储在Java类文件中的什么位置?
(2)通过ASM查看的字节码是如何保存 泛型类型签名信息的
private void genericErasure() {
List<String> list = new ArrayList<String>(); // Ljava/util/List ;
}

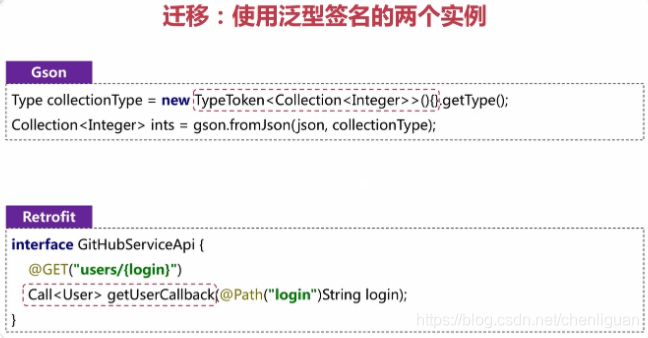
7.4 Gson是如何通过借助TypeToken获取泛型参数的类型的方法?
答:Gson构建泛型Type,实际上调用的就是getGenericReturnTypes方法。获得了匿名内部类的Class类型genericType,但是并没有直接将泛型参数T的Class类型传进来,那又是如何获得泛型参数的类型的呢?通过匿名内部类型genericType,可以访问到它父类TypeToken的构造方法,再获取Class字节码中保存的泛型签名信息,即可获取类型List< Integer >等。
Type genericType = new TypeToken<List<Integer>>(){ }.getType(); // 匿名内部类
public class TypeToken<T> {
final Class<? super T> rawType;
final Type type;
final int hashCode;
protected TypeToken() {
this.type = getSuperclassTypeParameter(getClass());
this.rawType = (Class<? super T>) $Gson$Types.getRawType(type);
this.hashCode = type.hashCode();
}
static Type getSuperclassTypeParameter(Class<?> subclass) {
Type superclass = subclass.getGenericSuperclass();
if (superclass instanceof Class) {
throw new RuntimeException("Missing type parameter.");
}
ParameterizedType parameterized = (ParameterizedType) superclass;
return $Gson$Types.canonicalize(parameterized.getActualTypeArguments()[0]);
}
public final Type getType() {
return type;
}
}
Android:Gson通过借助TypeToken获取泛型参数的类型的方法
Gson解析泛型对象时TypeToken的使用方法
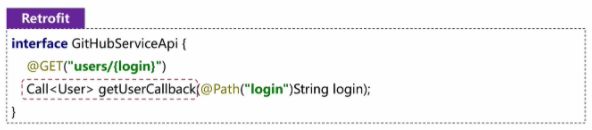
7.4.1 Retrofit是如何使用泛型签名的?
答:
8 Kotlin反射的实现原理?
答:(1)Kotlin每个类编译完后,都会有注解Metadata,保存了类的很多信息。可以通过反射获取当前类的信息,如:名字,都是从注解中获取。所以,如果使用kotlin的反射,需要添加混淆-keep class kotlin.Metadata{*;}避免注解被混淆了。
(2)Kotlin的特性比Java多很多,而它又是运行在Java虚拟机上的。如果Kotlin通过反射需要获取那么多的特性,而这时候Java虚拟机不知道这些新特性。那是虚拟机怎么做到的?Kotlin是通过注解来实现的,注解叫metadata,注解在每个类上。

Java高级面试 —— Java的泛型实现机制是怎么样的?
9 如何继承泛型
9.1 泛型
public class ServiceImpl<M, T> {
public void test(M, T) {
// do something
}
}
子类继承父类分两种情况:
// 1、保持子类的泛型化
public TestServiceImpl<M, T> extends ServiceImpl<M, T> {
@Override
public void test(M, T) {
}
}
// 2、子类不再泛型化
public TestServiceImpl extends ServiceImpl<String, Integer> {
@Override
public void test(String, Integer) {
}
}
9.2 泛型< V extends IMvpBaseView>
public abstract class AbstractMvpPresenter<V extends IMvpBaseView> {
}
子类继承父类分两种情况:
// 1、保持子类的泛型化
public class BaseLoadMorePresenter<IV extends ILoadMoreView> extends AbstractMvpPresenter<IV> {
}
public class RequestPresenter extends BaseLoadMorePresenter<RequestView> {
}
// 2、子类不再泛型化
public class BaseLoadMorePresenter extends AbstractMvpPresenter<ILoadMoreView> {
}