深入浅出Prometheus架构原理
目录
1 Prometheus简介
2 Prometheus 的优势
2.1 Prometheus 适用于什么场景
2.2 Prometheus 不适合什么场景
3 Prometheus 的架构
4 Prometheus 的组件
4.1 组件介绍
4.1.1 Prometheus Server
4.1.2 Exporter
4.1.3 Push Gateway
4.1.4 Grafana
4.1.5 AlertManager
4.1.6 Client Library
5 Prometheus工作流程
6 Prometheus四种指标分类
7 数据模型
7.1 指标名称和标签
7.2 样本
7.3 表示方式
8 prometheus的数据存储
8.1 本地存储
8.2 远程存储
1 Prometheus简介
Prometheus 是由前 Google 工程师从 2012 年开始在 Soundcloud 以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入 CNCF 基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目。
2 Prometheus 的优势
Prometheus 的主要优势有:
- 由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
- 强大的查询语言 PromQL。
- 不依赖分布式存储;单个服务节点具有自治能力。
- 时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
- 也可以通过中间网关来推送时间序列数据。
- 可以通过静态配置文件或服务发现来获取监控目标。
- 支持多种类型的图表和仪表盘。
2.1 Prometheus 适用于什么场景
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
2.2 Prometheus 不适合什么场景
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
3 Prometheus 的架构
Prometheus 的整体架构以及生态系统组件如下图所示:
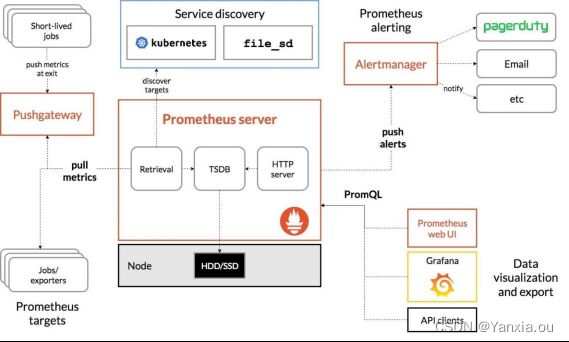
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
4 Prometheus 的组件
Prometheus 生态系统由多个组件组成,其中有许多组件是可选的:
4.1 组件介绍
4.1.1 Prometheus Server
用于收集和存储时间序列数据。Prometheus Server 是 Prometheus 组件中的核心部分,负责实现对监控数据的获取,存储以及查询。 Prometheus Server 可以通过静态配置管理监控目标,也可以配合使用 Service Discovery 的方式动态管理监控目标,并从这些监控目标中获取数据。其次 Prometheus Server 需要对采集到的监控数据进行存储,Prometheus Server 本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中。最后Prometheus Server 对外提供了自定义的 PromQL 语言,实现对数据的查询以及分析。
4.1.2 Exporter
用于暴露已有的第三方服务的 metrics 给 Prometheus。Exporter 将监控数据采集的端点通过 HTTP 服务的形式暴露给 Prometheus Server,Prometheus Server 通过访问该 Exporter 提供的 Endpoint 端点,即可获取到需要采集的监控数据。
4.1.3 Push Gateway
主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这些 jobs 可以直接向 Prometheus server 端推送它们的 metrics。
4.1.4 Grafana
第三方展示工具,可以编写 PromQL 查询语句,通过 http 协议与 prometheus 集成。
4.1.5 AlertManager
从 Prometheus Server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对方的接受方式,发出报警。常见的接收方式有:电子邮件,钉钉、企业微信,pagerduty等。
4.1.6 Client Library
客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus Server。当 Prometheus Server 来 pull 时,直接返回实时状态的 metrics。
5 Prometheus工作流程
指标采集:prometheus server 通过 pull 形式采集监控指标,可以直接拉取监控指标,也可以通过 pushgateway 做中间环节,监控目标先 push 形式上报数据到 pushgateway;
指标处理:prometheus server 将采集的数据存储在自身 db 或者第三方 db;
指标展示:prometheus server 通过提供 http 接口,提供自带或者第三方展示系统;
指标告警:prometheus server 通过 push 告警信息到 alert-manager,alert-manager 通过"静默-抑制-整合-下发"4个阶段处理通知到观察者。
6 Prometheus四种指标分类
Counter
计数器类型,只增不减,如机器的启动时间,HTTP 访问量等。机器重启不会置零,在使用这种指标类型时,通常会结合rate()方法获取该指标在某个时间段的变化率。
Gauge
仪表盘,可增可减,如CPU使用率,大部分监控数据都是这种类型的。
Summary
客户端定义;Summary,Histogram 都属于高级指标,用于凸显数据的分布情况。
Histogram
服务端定义,相比 Summary 性能更好,反应了某个区间内的样本数。
7 数据模型
Prometheus 所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB):属于同一指标名称,同一标签集合的、有时间戳标记的数据流。除了存储的时间序列,Prometheus 还可以根据查询请求产生临时的、衍生的时间序列作为返回结果。
7.1 指标名称和标签
每一条时间序列由指标名称(Metrics Name)以及一组标签(键值对)唯一标识。其中指标的名称(metric name)可以反映被监控样本的含义(例如,http_requests_total — 表示当前系统接收到的 HTTP 请求总量),指标名称只能由 ASCII 字符、数字、下划线以及冒号组成,同时必须匹配正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*。
通过使用标签,Prometheus 开启了强大的多维数据模型:对于相同的指标名称,通过不同标签列表的集合,会形成特定的度量维度实例(例如:所有包含度量名称为 /api/tracks 的 http 请求,打上 method=POST 的标签,就会形成具体的 http 请求)。该查询语言在这些指标和标签列表的基础上进行过滤和聚合。改变任何度量指标上的任何标签值(包括添加或删除指标),都会创建新的时间序列。
标签的名称只能由 ASCII 字符、数字以及下划线组成并满足正则表达式 [a-zA-Z_][a-zA-Z0-9_]*。其中以 __ 作为前缀的标签,是系统保留的关键字,只能在系统内部使用。标签的值则可以包含任何 Unicode 编码的字符。
7.2 样本
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(metric):指标名称和描述当前样本特征的 labelsets;
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。
7.3 表示方式
通过如下表达方式表示指定指标名称和指定标签集合的时间序列:
<metric name>{<label name>=<label value>, ...}
例如,指标名称为 api_http_requests_total,标签为 method="POST" 和 handler="/messages" 的时间序列可以表示为:
api_http_requests_total{method="POST", handler="/messages"}
8 prometheus的数据存储
时序数据的特点:
1、相邻数据点时间戳差值相对固定,即使有变化,也仅在一个很小的范围内浮动。
2、相邻数据点的值变化幅度很小,甚至无变化。
3、 对热数据的查询频率远远超出对非热点数据的查询频率,并且数据距离现在越近,热度越高。
压缩算法:
可以将16字节的样本数据压缩到1.37字节,并且通过块(block)保存。
8.1 本地存储
prometheus本地存储被称为Prometheus TSDB。TSDB的设计有两个核心:block和WAL,而block又包含chunk、index、meta.json、tombtones。
Prometheus 2.x采用自定义的存储格式将样本数据保存到本地磁盘当中。如下所示,按照两小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每一个块中包含该时间窗口内的所有样本数据(chunks)、元数据文件(meta.json)以及索引文件(index)。
1. block
TSDB将存储的监控数据按照时间分隔成block,block的大小并不固定,按照设定的步长倍数递增。默认最小的block保存2h的监控数据。如果步数为3,步长为3,则block的大小依次为2h、6h、18h。每个块最大支持512MB.
t0 t1 t2 now
┌───────────┐ ┌───────────┐ ┌───────────┐
│ │ │ │ │ │ ┌────────────┐
│ │ │ │ │ mutable │ <─── write ──── ┤ Prometheus │
│ │ │ │ │ │ └────────────┘
└───────────┘ └───────────┘ └───────────┘ ^
└──────────────┴───────┬──────┘ │
│ query
│ │
merge ──────────────────────────────────┘
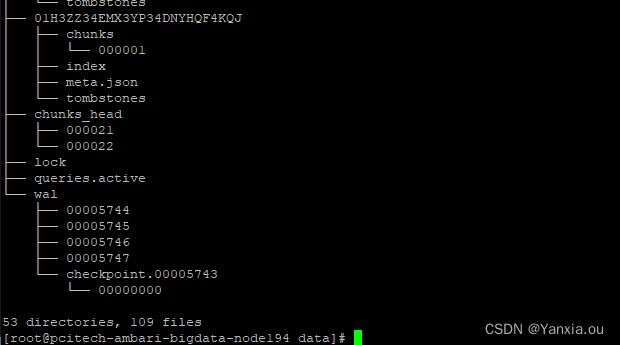
├── 01H2VFSKMVCKYJAV6BKTSM77NK
│ ├── chunks # 保存压缩后的时序数据,每个chunks大小为512M,超过会生成新的chunks
│ │ └── 000001
│ ├── index # 记录索引,chunks中时序的偏移位置
│ ├── meta.json # 记录block的元数据信息,包括样本的起始时间(minTime)、截止时间(maxTime)、样本数、时序数和数据源等信息
│ └── tombstones # 用于对数据进行软删除,TSDB在删除block数据块时会将整个目录删除,但如果只删除一部分数据块的内容,则可以通过tombstones进行软删除。
├── lock
├── queries.active
└── wal #监控数据的WAL(Write-ahead logging,预写日志),防止数据丢失,引入WAL(数据收集上来暂时是存放在内存中,wal记录了这些信息)
├── 00000366 #每个数据段最大为128M,存储默认存储两个小时的数据量。(2) index
(3) meta.json
(4) tombstones
2. wal
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample8.2 远程存储
prometheus在1.6版本后支持远程存储,Adapter需要实现prometheus的read和write接口,并将read和write转化为每种数据库各自的协议。

目前已经实现Adapter的远程存储主要包括:InfluxDB、OpenTSDB、CreateDB、TiKV、Cortex、M3DB等。