Gradle构建工具的学习
Gradle 简介:
Gradle 是一款Google 推出的基于 JVM、通用灵活的项目构建工具,支持 Maven,JCenter 多种第三方仓库,支持传递性依赖管理、废弃了繁杂的xml 文件,转而使用简洁的、支持多种语言(例如:java、groovy 等)的 build 脚本文件
学习地址:https://www.bilibili.com/video/BV1yT41137Y7/?spm_id_from=333.337.search-card.all.click&vd_source=5ea24d17d411aaa69d753a5f20d6e0a2
文档:https://www.yuque.com/docs/share/f7487dc8-743d-43ba-8585-a0f85f12d826
官网地址: https://gradle.org/
之所以需要Gradle,是因为目前已经有相当一部分公司在逐渐使用Gradle作为项目构建工具了,并且作为Java开发程序员,学习的Spring、SpringBoot等Spring家族的源码,基本上都是基于Gradle构建的
虽然市面上有很多项目构建工具,但是maven几乎还是主流,只是未来趋势是Gradle,当然,无论那种,他们几乎都有各自的优势
Gradle的安装在网上一般可以搜索到,但是还需要注意,Gradle通常会与框架,以及idea等等开发工具存在兼容性,也就是说,你下载的版本的Gradle可能并不适用与当前的框架版本以及idea版本,这里我们给出主流的Gradle版本,下载地址如下:
链接:https://pan.baidu.com/s/1Ws1Em5CW11WN9GEFo1irNw
提取码:alsk
一般来说,Gradle在6.8版本以上,包括6.8时,通常就能满足当前的spring家族(springboot,spring,springmvc),当然,idea的兼容一般也可以,具体可以百度搜索
通常Gradle的安装需要jdk1.8或者其以上的版本的jdk,jdk的安装就不多说了
拿取上面的Gradle后,我们配置环境变量(一般我们配置在系统变量里面):
变量名:GRADLE_HOME
变量值(我这里是):F:\gradle-7.4.1-all\gradle-7.4.1
配置Path:%GRADLE_HOME%\bin
可以在cmd中执行gradle -v查看是否可以出现版本,如果出现,配置成功
一般这个以后可以随便换(当然,对应补充的init.gradle也记得加上哦,这在后面会说明的,先记住),因为仓库是固定的,与版本无关,所以以后换gradle,只需要调一下这个即可,但是麻烦(所以存在Wrapper 包装器,在后面会说明的)
变量名:GRADLE_USER_HOME
变量值(我这里是):F:\zuoye\maven\repository
这个一般并不需要配置Path,因为有些配置可能只会看变量名,而不只是看Path(但是操作需要看他),Path只是一个可以通用处理的操作,比如上面的%GRADLE_HOME%\bin,否则你只能在对应的目录下操作gradle -v了
一般来说GRADLE_USER_HOME代表了gradle的仓库,与maven的仓库是同样的效果,但也要注意gradle的仓库可以设置在maven的仓库中,即Gradle本地仓库可以和Maven本地仓库目录一致(当然,也需要看gradle版本来说,现在的版本几乎可以这样做,其他或者以后的版本不确定了)
Gradle 项目目录结构:
Gradle 项目默认目录结构和Maven 项目的目录结构基本一致,都是基于约定大于配置
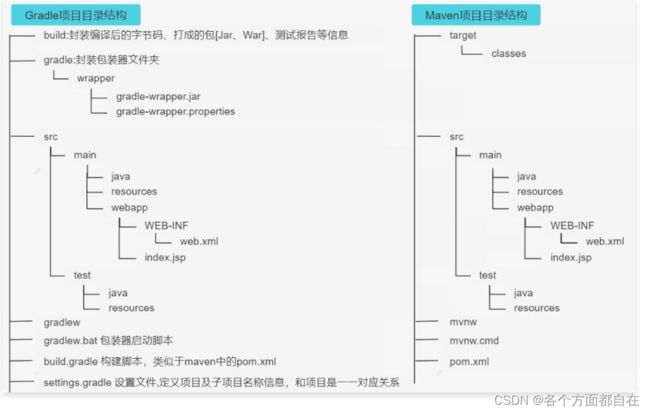
注意:一般只有war工程才有webapp目录,这在maven中也是如此,且gradlew与gradlew.bat的对应的指令,一般并不是本地安装的gradle指令,可以说是生成的,或者自带的
Gradle 中的常用指令:
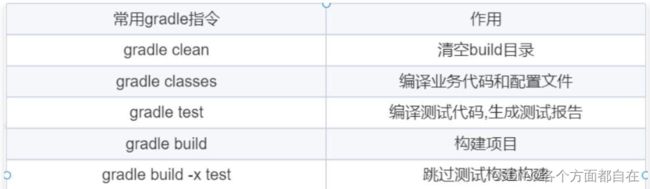
需要注意的是:gradle 的指令要在含有build.gradle 的目录执行(一般是内部底层代码导致需要这样做,否则可能报错,或者什么都不处理,看gradle版本而定,具体可以百度(百度是最常用的,所以这样说))
接下来我们先使用这个网站的工具来创建项目:https://start.spring.io/
操作如下:
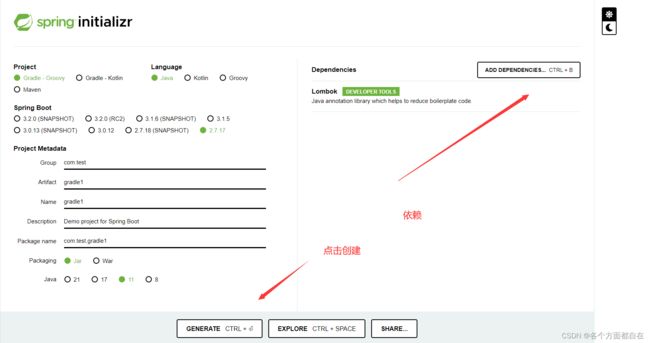
点击后,会进行下载,然后我们解压打开后,顺便调整一下目录,就会到如下(我这里是的):

在build,gradle,src,gradlew,gradlew.bat,build.gradle,settings.gradle这些目录或者文件中,只是少了build目录,至于md结尾,还有"."开头的git文件,可以删除,现在我们使用命令来操作一下:
一般存在如下命令:gradle classes,gradle clean,gradle test,gradle build,gradle build -x test(-x可以选择不执行某个任务,一般后面的关键字代表是任务名称,比如test,classes都是任务名称),首先我们在对应的命令行中(cmd)来操作gradle classes(当然,如果版本不兼容,可能是执行成功不了的):
进入该目录的cmd中,执行该命令,后面看看目录(注意,如果太慢,可以选择在后面配置下载源,因为一般现在都会自带一些依赖,全局搜索:"修改gradle 或者说maven下载源"即可)
一般就会出现如下了:

里面多出了build,以及.gradle(gradle是编译后出现的),build里面就存在了对应的字节码文件,记得删除一下md结尾的和"."开头的(除了.gradle),然后我们执行gradle clean,清除build目录,然后执行gradle test,然后可以在build\reports中找到对应的html,打开就能知道执行了测试代码的哪一个了,这个时候可以选择在src中自己看看结构是否对应与创建时的配置了
然后执行gradle clean清空,直接执行gradle classes看看有没有这个目录reports,发现没有,也就是说,他的确是测试使得出现的
然后我们执行gradle build,他相当于同时操作了gradle classes和gradle test,执行看看吧,一般情况下,若执行的命令中存在冲突的文件,那么是操作覆盖的,对应的gradle classes的build目录:
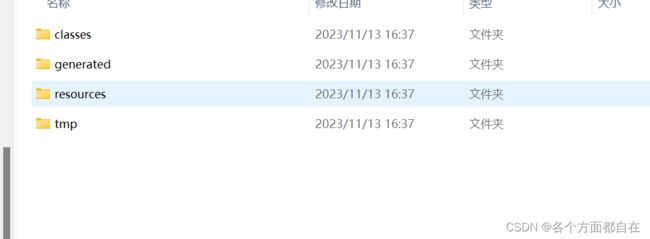
执行了gradle test后的目录(单独执行,操作覆盖的,当然这里类似于maven中的对应的命令顺序,所以注意即可):

单独执行gradle build后的目录(既然上面说到了顺序,所以说,其实后面的目录一般都是一个操作,只是在执行他时,会默认将前面的也进行操作了(因为顺序,所以覆盖其实就是重新生成一个一样的覆盖),这里他也是如此,当然,他自身也存在操作,所以目录如下):

多出了几个文件,其中libs就是打包后的文件,可以进入看看,发现存在了jar包
然后我们可以不选择执行测试操作,也就是执行gradle build -x test:

少了两个,正好是测试的那两个,自己对比就知道了
接下来我们使用命令来创建项目:
首先我们到一个文件夹下,比如我就到:E:\gradle
进入这个目录的命令行,输入gradle init来进行构建项目:


这个时候你看看这个目录:

通过前面我们知道了上面大致的结构,只是这里一开始就存在了.gradle(其实是因为子模块的原因,也算是处理了一下,一般处理一下就会出现这个)
这里对比前面多个git文件,省略删除即可(md没有了)
我们可以执行对应的命令,操作好后,可以在app(这个一般是固定的名称)中看到build(那么由于其他的命令都是在该目录下生成文件的,所以就不说明了,与前面是一样的),那么很明显,.gradle的出现就是操作了子模块,也就是将对应的代码放在子模块中,所以在子模块中出现
至此,我们操作的命令行的创建项目处理完毕,我们继续往后面进行学习
修改gradle 或者说maven下载源:
Gradle 自带的Maven 源地址是国外的(gradle与maven都是操作对应的同一个仓库操作,也都是maven,当然构建工具是一般支持多个仓库的,也并非需要是maven,只是maven我们使用的多),该Maven 源在国内的访问速度是很慢的,除非使用了特别的手段(翻qiang),一般情况下,我们建议使用国内的第三方开放的Maven 源或企业内部自建Maven 源,操作如下:
我们可以在下载好的gradle 的init.d 目录(可以找到的)下创建以.gradle 结尾的文件,.gradle 文件可以实现在build 开始之前执行,所以你可以在这个文件配置一些你想预先加载的操作,比如我们创建init.gradle,内容加上如下:
allprojects {
repositories {
mavenLocal()
maven { name "Alibaba" ; url "https://maven.aliyun.com/repository/public" }
maven { name "Bstek" ; url "https://nexus.bsdn.org/content/groups/public/" }
mavenCentral()
}
buildscript {
repositories {
maven { name "Alibaba" ; url 'https://maven.aliyun.com/repository/public' }
maven { name "Bstek" ; url 'https://nexus.bsdn.org/content/groups/public/' }
maven { name "M2" ; url 'https://plugins.gradle.org/m2/' }
}
}
}
上面的处理是从上往下开始找的,如果都没有找到,那么就会报错,注意了,由于我们配置了环境变量,所以我们使用的gradle就是对应的下载的gradle,否则在以后如果你使用的gradle不是这个,那么自然这个源的配置不会被你使用,比如idea中需要进行选择来增加速度
mavenLocal():指定使用maven本地仓库,而本地仓库在配置maven时settings文件指定的仓库位置,如E:/repository,gradle 查找jar包顺序如下:USER_HOME/.m2/settings.xml(代表是里面配置的仓库) >> M2_HOME/conf/settings.xml (一般是这个起作用)>> USER_HOME/.m2/repository(USER_HOME一般代表是在c盘的用户地址,M2_HOME是maven的配置的环境变量,所以有些环境变量使用对应的名称是有道理的,当然,大多数并不看名字,只看路径,所以这里最好知道对应的名称代表什么路径的),只要找到了,那么就不会操作后面的位置,而不是依次处理的,所以,如果USER_HOME/.m2/settings.xm中存在,那么就会使用他,在maven差不多也是如此,这也是为什么idea中有时候我们明明配置了M2_HOME/conf/settings.xml,但是总是默认使用USER_HOME/.m2/settings.xml的配置的原因(你是否也修改了很多次呢)
maven {name,url},指定maven仓库,一般用私有仓库地址或其它的第三方库,比如阿里镜像仓库地址(name只是一个描述,并不是必须,所以可以去掉)
mavenCentral():这是Maven的中央仓库(也就是远程仓库),无需配置,直接声明就可以使用
gradle可以通过指定仓库地址为本地maven仓库地址和远程仓库地址相结合的方式,避免每次都会去远程仓库下载依赖库,这种方式也有一定的问题,如果本地maven仓库有这个依赖,就会直接加载本地依赖(注意是gradle可以识别的,在后面你会明白),如果本地仓库没有该依赖(也就是上面的mavenLocal()都不存在),那么还是会从远程下载,但是下载的jar不是存储在本地maven仓库中(问题所在),而是放在自己的缓存目录中,默认在USER_HOME/.gradle/caches目录(这样不就相当于没有下载吗,因为对应的mavenLocal()并没有指定这个路径,基本都是maven相关路径),当然如果我们配置过GRADLE_USER_HOME环境变量,则会放在GRADLE_USER_HOME/caches目录,具体一点,一般下载的依赖可能在他里面的modules-2\files-2.1目录中(一般caches这个目录没有,那么会创建的,解决默认的放在缓存目录的这个问题所在,也是为什么我们有时候会将该配置设置为maven仓库,使得mavenLocal()本地可以进行处理),注意:gradle默认操作对应的目录,而这个目录,也就是caches,也就是说,比如M2_HOME/conf/settings.xm中是这个仓库,那么gradle默认拿取里面的caches目录的依赖,其他的也是如此,所以虽然我们指定了仓库位置,但是并没有确定是直接在该仓库位置下,这里就是在caches目录下(maven是直接仓库位置下的),所以对gradle说,指定仓库位置,或者拿取仓库依赖,就是指定仓库里面的caches目录,或者拿取仓库里面的caches目录的jar包,只是我们也认为caches目录也是属于对应的一部分,所以操作仓库位置,而gradle的jar包存放形式并不与maven相同,所以也就引出了下面的问题:
那么可不可以将默认的gradle caches仓库指向maven repository,也就是gradle操作maven仓库,可以吗,一般来说这是不行的,caches下载文件不是按照maven仓库中存放的方式,所以就算你指向maven仓库,虽然该仓库存在很多的jar包,但是gradle并不能识别(反过来也是如此),也就不会进行下载
一般来说,如果需要其他的url下载源地址,可以到这个网站中拿取:https://developer.aliyun.com/mvn/guide(上面的maven { name “Alibaba” ; url “https://maven.aliyun.com/repository/public” }在里面就可以找到,可以全局搜索,找到group(Type)类型即可)
一般是仓库文件里面,通常带有plugin后缀的,也就是插件,我们建议放在对应的init.gradle的buildscript里面,其他的放在repositories里面,他们两个是同级别的,具体为什么,是因为buildscript一般是自身的gradle的插件处理,自然需要选择有插件的,否则可能找不到而报错
一般init.gradle可以被多次使用,在命令行指定文件,例如:gradle --init-script yourdir/init.gradle -q taskName,你可以多次输入此命令来指定多个init文件,–init-script yourdir/init.gradle这个选项用于指定一个初始化脚本,即init.gradle文件的路径,初始化脚本允许你在 Gradle 构建之前执行一些自定义的配置,而-q代表在输出中只显示任务的结果,而不显示额外的信息,而后面的taskName就是任务名称,任务名称在前面相当于test,classes,也就是说,如果你是这样的处理gradle --init-script yourdir/init.gradle -q classes,那么就是与gradle classes的区别就是,在执行之前,使用了指定文件的信息然后执行,很明显,如果没有默认的配置,那么前面的gradle classes自然会慢一点(前提是没有其他的处理存在,如后面的放在下载好的gradle 的init.d 目录),当然,还存在一种方式,把init.gradle文件放到 USER_HOME/.gradle/ 目录下,或者把该文件或者说把以.gradle结尾的文件放到USER_HOME/.gradle/init.d/目录下(没有创建即可),最后或者放在对应的下载好的gradle 的init.d 目录,当他们同时存在时,会按照命令行指定,USER_HOME/.gradle/,USER_HOME/.gradle/init.d/,下载好的gradle 的init.d 目录,进行依次处理,也就是说既然是依次处理,那么可以存在非常多的处理的,但是为什么不放在一起呢,所以我们建议都放在下载好的gradle 的init.d 目录中,还需要注意的是,这些操作,可能会随着版本而进行改变,也就是说,以后可能只会认命令行或者下载好的gradle 的init.d 目录了,所以这也是我们建议放在下载好的gradle 的init.d 目录中的原因,还有一点,如果存在多个gradle文件都在下载好的gradle 的init.d 目录下,应该怎么操作呢,一般会按照ascii来进行操作,谁小,那么谁先处理(如果第一个相同,那么看第二个数),即也是依次的,综上所述,为了更加严谨的处理,我们建议只在下载好的gradle 的init.d 目录中中创建一个init.gradle(这个名称可以改变,但是建议这样),还要注意:每个init脚本都存在一个对应的gradle实例,你在这个文件中调用的所有方法和属性,都会委托给这个gradle实例,每个init脚本都实现了Script接口(这里了解即可,具体可以参照前面我们指向任务后,出现的.gradle,即他就算实例(新的类,通常我们没有说明),这个Script接口再后面可能会提到,先了解,一般是后面的groovy脚本会提到一下)
Wrapper 包装器:
Gradle Wrapper 实际上就是对 Gradle 的一层包装(一般在前面的gradle文件(没有前缀"."),自己去看就知道了),用于解决实际开发中可能会遇到的不同的项目需要不同版本的 Gradle,因为gradle兼容性并不高
例如:把自己的代码共享给其他人使用,可能出现如下情况:
1:对方没有安装gradle
2:安装了,但是版本低或者不兼容
这时候,我们就可以考虑使用 Gradle Wrapper 了,这也是官方建议使用 Gradle Wrapper 的原因,实际上有了 Gradle Wrapper 之后,我们本地是可以不配置 Gradle 的,下载Gradle 项目后,使用 gradle 项目自带的wrapper 操作也是可以的(命令,具体的仓库有默认的,并非一定需要配置)
项目中的gradlew、gradlew.cmd脚本用的就是wrapper中规定的gradle版本,你可以找到gradlew,查看里面的文件,里面应该会存在这样的:CLASSPATH=$APP_HOME/gradle/wrapper/gradle-wrapper.jar
而我们上面提到的gradle指令用的是本地gradle(bin里面的),所以gradle指令和gradlew指令所使用的gradle版本有可能是不一样的。这里可以选择在wrapper里面的properties配置文件里查看
虽然没有配置时,gradlew、gradlew.cmd的使用方式与gradle使用方式完全一致,只不过把gradle指令换成了gradlew指令,也就是使用Wrapper ,你是否眼熟,在前面我们创建项目时,就存在这两个命令的,你现在就可以选择操作gradlew classes(gradle.bat classes也是可以的),或者gradlew clean来测试(当然,如果对应的gradlew文件为空了,建议重新处理项目)
这个时候,你可能会出现一个问题,他一直在下载对应的zip文件,最终超时,这是为什么,一般如果你拿取里面的配置,比如我的是(对应的远程下的,而不是init的,init自然是操作自身的版本,而不是下面的):
distributionBase=GRADLE_USER_HOME
distributionPath=wrapper/dists
distributionUrl=https\://services.gradle.org/distributions/gradle-8.4-bin.zip
networkTimeout=10000
validateDistributionUrl=true
zipStoreBase=GRADLE_USER_HOME
zipStorePath=wrapper/dists
访问https://services.gradle.org/distributions/gradle-8.4-bin.zip后,可以在浏览器下载(记得去掉前面的\),如果可以,那么应该是networkTimeout=10000太小,因为是ms,也就是说10000ms是10s,你可以选择加一个0,也就是100000,这个时候再来看一下,如果还不行,那么一般是源的问题,修改上面的url变成https://mirrors.cloud.tencent.com/gradle/gradle-8.4-bin.zip,现在来看一看,应该就可以下载了,但是为什么浏览器可以,而他却需要修改源呢,其实可能修改版本也会这样,那么这就应该是内部的原因以及对方的原因了,这就要受很多因素影响了,一般来说gradle内部可能代理了某些操作,或者说远程的对应的那个文件被这样的代理处理时,使得非常慢,或者说他可能也进行了代理而其他没有(一般idea可能比命令行中的要慢点,可能也是这些原因,虽然大多数是没有对应的wrapper文件造成的),当然,gradlew可能一开始会慢一些,这是因为第一次执行需要解释其代码,然后进行缓存,所以第二次基本上与gradle一样的,虽然他们可能存在版本的不同,但是他们通常是同源的,也就是互相兼容的,当然,也并非一定,比如人为进行修改,或者本来就不行,那么在我们不手动再次修改的情况下(如可以手动将上面的8.4修改成7.4.1),那么我们就需要如下了:
我们也可在终端执行 gradlew 指令时,指定指定一些参数,来控制 Wrapper 的生成(也就是gradle的生成,因为他是gradle的包装),比如依赖的版本等,如下
–gradle-version,用于指定使用的gradle版本,也就是
–gradle-distribution-url,用于指定现在gradle的发行版本的地址
具体操作如下所示 :
gradlew wrapper --gradle-version=7.4.1:升级wrapper版本号,只是修改对应的properties配置文件中wrapper版本(当然,如果事先没有下载过gradlew ,那么先不会进行改变,还是会先下载对应的zip,如果下载过,那么通常会有缓存,也基本都会存在的,通常会在.gradle\wrapper\dists里面,一般来说,没有任何配置时,如环境变量,基本都在.gradle里面),未实际下载,这个时候使用gradlew -v看看结果吧(这个时候开始操作zip,当然,对应的版本下载可能非常慢,前面的代理说明,比如7.4.1非常快,但是7.4.2非常慢),或者在这之前直接看对应的properties配置是否修改了
gradle wrapper --gradle-version 5.2.1 --distribution-type all:关联源码用,如果说上面是改变对应的properties配置文件,那么这个就是生成对应版本的gradlew的相关文件,比如gradlew,gradlew.bat,以及gradle文件,你可以选择删除,然后使用本地的来处理一下,所以这里是gradle wrapper,而不是gradlew wrapper,当然,如果存在,那么就是覆盖,这个时候存在的话可以使用gradlew wrapper
Gradle Wrapper 的执行流程:
1:当我们第一次执行 ./gradlew build 命令的时候,gradlew 会读取 gradle-wrapper.properties 文件的配置信息
2:准确的将指定版本的 gradle 下载并解压到指定仓库的对应位置(GRADLE_USER_HOME目录下的wrapper/dists目录中,如果配置了GRADLE_USER_HOME,那么就放在这里,如果没有对应目录,那么创建对应目录)
3:并构建本地缓存(GRADLE_USER_HOME目录下的caches目录中),下载再使用相同版本的gradle就不用下载了,直接从他那里拿取(也就是说,他会从对应的wrapper/dists找,如果没有,那么从本地下载,而不是远程了)
4:之后执行的 ./gradlew 所有命令都是使用指定的 下载的gradle 版本
注意:如果对应的gradle文件不存在,那么通常会从远程仓库中进行下载,一般是gradle官方仓库,当然,具体的版本可能会与默认的idea的gradle配置相关,而由于从远程来下载的,那么通常会慢一点
我们可以很明显的知道,按照我们配置的环境变量,下载的无论是jar(缓存也是如此)还是gradle几乎都在对应的maven仓库中,缓存和jar放在caches中(gradle下载的缓存也是),gradle放在wrapper/dists,否则他们几乎都默认在用户的.gradle下进行处理,而不是这个仓库
如图:

gradle-wrapper.properties 文件解读:

上面的zip操作,就说明在对应的目录下,存在文件夹(dis开头的配置的作用)和该文件夹的zip(zip开头的配置的作用)
注意:前面提到的 GRALE_USER_HOME 环境变量用于这里的Gradle Wrapper 下载的特定版本的gradle 存储目录,如果我们没有配置过GRALE_USER_HOME 环境变量,默认在当前用户家目录下的.gradle 文件夹中
那什么时候选择使用 gradle wrapper、什么时候选择使用本地gradle呢,下载别人的项目或者使用操作以前自己写的不同版本的gradle项目时:用Gradle wrapper,也即:gradlew,因为你的环境变量是不变的,但是你拿取的是改变的(其实就算操作自身的项目,也可以使用这个,只需要对应版本即可,或者直接对应环境变量的版本)
什么时候使用本地gradle,新建一个项目时:使用gradle指令即可
Groovy 简介:
在某种程度上,Groovy 可以被视为Java 的一种脚本化改良版,Groovy 也是运行在 JVM 上,它可以很好地与 Java 代码及其相关库进行交互操作,它是一种成熟的面向对象编程语言,既可以面向对象编程,又可以用作纯粹的脚本语言,大多数有效的 Java 代码也可以转换为有效的 Groovy 代码,Groovy 和 Java 语言的主要区别是:完成同样的任务所需的Groovy 代码比 Java 代码更少
其特点为:
1:功能强大,例如提供了动态类型转换、闭包和元编程(metaprogramming)支持
2:支持函数式编程,不需要main 函数
3:默认导入常用的包
4:类不支持 default 作用域,且默认作用域为public
5:Groovy 中基本类型也是对象,可以直接调用对象的方法
6:支持DSL(Domain Specific Languages 领域特定语言)和其它简洁的语法,让代码变得易于阅读和维护
Groovy 是基于Java 语言的,所以完全兼容Java 语法,所以对于java 程序员学习成本较低,详细了解请参考:http://www.groovy-lang.org/documentation.html
Groovy 安装:
下载地址:https://groovy.apache.org/download.html
当然,这里我们拿取这个:
链接:https://pan.baidu.com/s/1C8SgTdv3Igos4EAj-e1Gow
提取码:alsk
配置环境变量:
变量名:暂时不加,并非一定要加变量名的,就如前面所说大多数并不看名字,只看路径
变量值:也不加了
配置Path:F:\apache-groovy-sdk-4.0.15\groovy-4.0.15\bin
配置好后,在命令行中执行groovy -v,如果有结果,代表配置成功(大多数配置的环境变量或者操作其对应的bin时,一般都会有查询版本的命令,所以groovy -v通常存在)
idea使用Gradle 创建第一个项目,一般idea也可以创建gradle项目,只是创建gradle时是需要groovy的,因为gradle存在两个情况:
自身形成,和自身项目构建
一般自身形成由Java和groovy所写,而自身项目构建或者生成的文件以及目录,以及groovy的代码,都由groovy所完成(在gradle中,任务除了编写代码,基本也是如此,虽然任务是groovy的一部分),但无论如何,底层都是由Java所完成
Groovy 是一种独立的编程语言,只是语法与Java有点类似,所以如果需要操作项目,自然需要对应的groovy,要不然,他们之间的联系是处理不了的,通常gradle自带了groovy,所以前面我们可以进行初始化创建目录
语言自然还是Java,因为只是构建操作是groovy,其他的基本都是Java处理的,自然代码也是Java编写,特别的,虽然我们说groovy是独立的编程语言,但是任何的编程语言有其下层语言(汇编除外,当然,如果非要说汇编之前还存在,那也没有问题,只是最终都优化到了汇编而已),而groovy主要编写的下层语言是Java(对应底层到汇编),自然这个语言也要选择Java,所以无论是构建操作,还是语言都决定需要选择Java
那么我们操作如下:
选择了上面的groovy后,在对应的src目录下,就可以创建groovy class文件了,否则不行
创建一个test.groovy:

groovy语法:
由于Groovy 是基于Java 语言的,所以完全兼容Java 语法,所以一般来说学习了Java大多数应该非常熟悉,但是语法也并不完全相同,所以我们应该看成一个新的语言,我们首先在src中创建包com.test,然后创建名称是groovy的类(这里的类简称为groovy了):
package com.test
class groovy {
}
语法:
关于语法,我们在后面会进行说明了,现在开始学习:
由于兼容Java语法,所以可以这样:
package com.test
class groovy {
int name;
boolean tr;
String k;
}
也有他自身独有的语法(他可以是脚本语言,类似于js):
package com.test
def username="张三"
def pass = "1234"
可以不加";"分号,在class中也是如此,这是他的语法,所以:
boolean tr
String k
也可以,我只是兼容你,但是语法要按照我的规定来

注意:一般一个groovy中存在脚本和什么都不写时,显示的目录中会出现后缀,否则就是没有后缀(也就是单纯的类)
对应的四个文件:
package com.test
def username="张三"
def pass = "1234"
println(username)
package com.test
class tes {
int a = 0
String j = 9;
boolean k = true;
}
class test {
}
package com.test;
public class y {
int l;
int jj;
}
我们运行groovy脚本,在对应的界面,右键即可:
运行后,会打印对应的"张三",并且这个时候进行了编译,我们看脚本和groovy和java的区别:
public class groovy extends Script {
public class tes implements GroovyObject {
public class y {
上面出现了Script类,其实他是类还不是接口,现在我们回到之前说的:还要注意:每个init脚本都存在一个对应的gradle实例,你在这个文件中调用的所有方法和属性,都会委托给这个gradle实例,每个init脚本都实现了Script接口(这里了解即可,具体可以参照前面我们指向任务后,出现的.gradle,即他就算实例,这个Script接口再后面可能会提到,先了解,一般是后面的groovy脚本会提到一下)
也可以混合定义:
package com.test
def username="张三";
println(username);
class test1 {
}
但是报错了,因为:

脚本和groovy后缀其实都是groovy,只是脚本会显示出来,那么在这样的情况下,由于只有一个文件,那么只能选择拿取一个名称,所以class这个名称需要改变,这样才不会报错,但是这样的情况下,java中则不相同,主要是java做过这样的处理,这里就不多说了(要不然哪里来的内部类的知识),其实就算不是内部类,而是同级别的类,java也不会报错,当然,同级的,那么groovy或者java在编译后都会出现多个文件的,只是这个在编译之前java不会报错,而groovy会而已,就如上面所说,java做过这样的处理,其实还有一个原因,是脚本没有具体的指定名称,而java的多个类都有,所以这也是groovy会报错的根本原因,当然,说成是java自身处理了也没有关系
当然,如果你没有写过任何的脚本,那么这个名称可以一样,因为只有一个了(在后面操作看字节码时就会明白)
而脚本没有直接的显示名词,所以修改名词交给class后面进行处理了
虽然groovy兼容java,但是我们还是建议都是以def来进行定义,无论是方法,还是变量都是如此,因为这样可以考虑一致操作文件
否则容易出现问题,而idea并没有提示:
package com.test
def f = "张三"
int j = 9;
j = f;
f = j;
println(j)
println(f)
当然,如果可以,或者需要严谨,你也可以选择操作具体类型,只是并不建议,因为麻烦
默认情况下,类,方法,变量基本都是public修饰的(也可以是protected,private(一般变量不能使用这个权限,否则报错,具体还是看版本吧(谁实际操作他的软件或者语言或者框架或者中间件,就是看谁的版本,这里自然就是groovy的版本了,而groovy可能也需要看Java的版本)),基本只有这三个,因为默认是public,而不是java的那个默认权限(只是默认,一般并没有对应的名称来表示)),并且也只有他
package com.test
println(1)
def fa() {
}
void fb() {
}
public void fc() {
println(4)
}
println(2)
class c {
}
fc()
我们学习新的语言时,对应的语法兼容另一方时,其实要看成新的语言,而不是进行对比,否则会比较混乱的,只是这个基于一方语言的,底层肯定与基于的一方语言的哪个语言有关,只是语法发生了改变而已
对象的属性操作:
package com.test
class cl{
def name;
def nAme
static void main(String[] args) {
def f = new cl()
f.name = "23"
f.nAme = "44"
println(f.name)
println(f.nAme)
f.setName("44")
println(f.name)
println(f["name"])
println(f.getName())
}
}
还要构造器的处理:
package com.test
class cl{
cl(){
}
}
在满足语法和兼容的情况下,就是可以这样的处理
方法的操作:
package com.test
class cl {
void fa(def n) {
}
def fb() {
println(1)
}
static void main(String[] args) {
Object v = new cl();
v.fb()
}
}
void hh() {
println(2)
}
hh()
再右键放在哪个区域,就会执行对应的脚本还是类,当然,其中一个报错,后面的自然不会处理了,他们的执行是独立的,当然,随着版本的更新或者你操作的版本不同,有些语法是会随时发生改变的,比如可能再以后,我们可能需要写上访问权限,或者需要规定位置了(如脚本必须在前面),具体情况还是需要看groovy的官网的:http://www.groovy-lang.org/documentation.html
当然,groovy自然也支持对应的结构,如果分支,循环等等,这里我们就不多少,这是非常基础的,在后面我们可能会使用到
还是,像一些运算符,这样只需要之傲def是随结果改变的,其他的都与java一样,包括结构(如分支,循环)
特别的操作:
package com.test
def name = int.name
println(name)
println("1")
println("1\n2")
println("1${name}" + name)
println('1' + name)
println('1${name}')
println('''
33
${name}
''')
字符串有单引号,双引号,三引号
单引号:单纯的作为字符串使用
双引号:除了单引号功能外,可以引用变量${},在里面可以进行计算,所以存在计算能力
三引号:除了单引号的功能外,单纯的作为模板来处理,所以可以直接上面的操作,也就是直接换行,在java中,一般并没有模板字符串(可能需要看版本,或者以后的版本),所以你是否在之前还没有意识到,好像,我们操作java的字符串时,都是在同一个行中的,在其他行时,我们通常操纵了换行符号,而不是直接的换行
def的类型在于返回值的这个值的类型,这里需要注意
类说明:如果在一个groovy 文件中没有任何类定义,它将被当做 script (翻译:脚本)来处理,也就意味着这个文件将被透明的转换为一个 Script 类型的类(前面的继承),这个自动转换得到的类将使用原始的 groovy 文件名作为类的名字,groovy 文件的内容被打包进run 方法,另外在新产生的类中被加入一个main 方法以进行外部执行该脚本,我们可以看看其内容,首先创建两个,一个脚本一个类,还有一个都存在(他们编译后都是字节码):
package com.test
def username = "张三"
int j = 9;
println(username);
println(j)
编译后的:
package com.test;
import groovy.lang.Binding;
import groovy.lang.Script;
import org.codehaus.groovy.runtime.InvokerHelper;
public class gr1 extends Script {
public gr1() {
}
public gr1(Binding context) {
super(context);
}
public static void main(String... args) {
InvokerHelper.class.invoke<invokedynamic>(InvokerHelper.class, gr1.class, args);
}
public Object run() {
Object username = "张三";
int j = 9;
this.invoke<invokedynamic>(this, username);
return this.invoke<invokedynamic>(this, j);
}
}
package com.test
class gr2 {
static void main(String[] args) {
def j = 0;
int h = 8;
println(j)
println(h)
}
}
编译后:
package com.test;
import groovy.lang.GroovyObject;
import groovy.lang.MetaClass;
import groovy.transform.Generated;
import groovy.transform.Internal;
import java.beans.Transient;
public class gr2 implements GroovyObject {
@Generated
public gr2() {
MetaClass var1 = this.$getStaticMetaClass();
this.metaClass = var1;
}
public static void main(String... args) {
Object j = 0;
int h = 8;
gr2.class.invoke<invokedynamic>(gr2.class, j);
gr2.class.invoke<invokedynamic>(gr2.class, h);
}
@Generated
@Internal
@Transient
public MetaClass getMetaClass() {
MetaClass var10000 = this.metaClass;
if (var10000 != null) {
return var10000;
} else {
this.metaClass = this.$getStaticMetaClass();
return this.metaClass;
}
}
@Generated
@Internal
public void setMetaClass(MetaClass var1) {
this.metaClass = var1;
}
}
package com.test
def userk = 9;
int g = 7;
println(userk)
println(g)
class gr4 {
static void main(String[] args) {
def j = 9;
int r = 6;
println(j)
println(r)
}
}
编译后(出现两个,这个在之前有过说明,这里就能解释之前的"当然,如果你没有写过任何的脚本,那么这个名称可以一样,因为只有一个了(在后面操作看字节码时就会明白)"):
package com.test;
import groovy.lang.Binding;
import groovy.lang.Script;
import org.codehaus.groovy.runtime.InvokerHelper;
public class gr3 extends Script {
public gr3() {
}
public gr3(Binding context) {
super(context);
}
public static void main(String... args) {
InvokerHelper.class.invoke<invokedynamic>(InvokerHelper.class, gr3.class, args);
}
public Object run() {
Object userk = 9;
int g = 7;
this.invoke<invokedynamic>(this, userk);
return this.invoke<invokedynamic>(this, g);
}
}
package com.test;
import groovy.lang.GroovyObject;
import groovy.lang.MetaClass;
import groovy.transform.Generated;
import groovy.transform.Internal;
import java.beans.Transient;
public class gr4 implements GroovyObject {
@Generated
public gr4() {
MetaClass var1 = this.$getStaticMetaClass();
this.metaClass = var1;
}
public static void main(String... args) {
Object j = 9;
int r = 6;
gr4.class.invoke<invokedynamic>(gr4.class, j);
gr4.class.invoke<invokedynamic>(gr4.class, r);
}
@Generated
@Internal
@Transient
public MetaClass getMetaClass() {
MetaClass var10000 = this.metaClass;
if (var10000 != null) {
return var10000;
} else {
this.metaClass = this.$getStaticMetaClass();
return this.metaClass;
}
}
@Generated
@Internal
public void setMetaClass(MetaClass var1) {
this.metaClass = var1;
}
}
上面我们在单纯的赋值和打印进行了分析,其实语法的分析也有很多,以及生成的其他代码也没有解释,这需要底层知识甚至更多的知识,这对我们单纯的只是使用这个groovy来说并不需要知道,所以对应的为什么最后可以变成上面的class,我们看看就行了,并不需要去了解
再方法上groovy也存在一种省略情况:
package com.test
def fa() {
return "2"
}
def fb() {
def f = 9;
"3"
}
def fc() {
def f = 9;
}
String fd() {
def f = "2";
}
println(fa())
println(fb())
println(fc())
println(fd())
return可以省略,并且省略后,默认最后一行数据作为返回值
当然,还有这样的:
package com.test
def num1 = 1;
def num2 = 2;
println "$num1 + $num2 = ${num1 + num2}"
package com.test
def num1 = 1;
def num2 = 2;
def str1 = "1d";
def str2 = 'dsd';
println "$num1 + $num2 = ${num1 + num2}"
println(num1.getClass().toString())
println(str1.getClass().toString())
println(str2.getClass().toString())
def str3 = "1${num1}"
println(str3.getClass().toString())
当然,具体的语句结构,太过繁琐,我们看官网吧:http://www.groovy-lang.org/documentation.html
具体参考这里:
http://www.groovy-lang.org/semantics.html#_conditional_structures
因为他是比较正规的(里面可与Java有非常大的不同哦),当然,无论他怎么变,其实只要接触过就会知道,那么现在我们来进行说明,首先是if和else:
def x = false
def y = false
if (!x) {
x = true
}
assert x == true
println(x)
if (x) {
x = false
} else if (true) {
y = true
} else {
println(1)
}
y = true
println(x)
println(y)
assert x == y
还有switch:
x = "foo"
switch (x) {
case "foo":
result = "found foo"
break
case "bar":
result = "bar"
break
case ~/fo*/:
result = "foo regex"
break
default:
result = "default"
}
println(result)
注意既然类似于js,那么对应的result的确可以这样,但是也要注意:groovy可能还存在其他的匹配,只是可能也由于版本而舍弃或者补充了,并且可能存在其他的语法,其实,这些只是对基础知识的修饰,我们掌握基础知识即可
还有for循环:
String message = ''
for (int i = 0; i < 5; i++) {
message += 'Hi '
}
println(message)
assert message == 'Hi Hi Hi Hi Hi '
def (String x, int y) = ['foo', 42]
println("$x $y")
assert "$x $y" == 'foo 42'
def x = 0
for (i in 0..9) {
x += i
}
println(x)
assert x == 45
x = 0
for (i in [0, 1, 2, 3, 4]) {
x += i
}
println(x)
assert x == 10
def array = (0..4).toArray()
x = 0
for (i in array) {
x += i
}
println(array)
assert x == 10
def map = ['abc': 1, 'def': 2, 'xyz': 3]
x = 0
for (e in map) {
x += e.value
}
println(x)
assert x == 6
x = 0
for (v in map.values()) {
x += v
}
println(x)
assert x == 6
def text = "abc"
def list = []
for (c in text) {
list.add(c)
}
println(list)
assert list == ["a", "b", "c"]
更加证明了脚本类似于js(js一般也可以这样),也可以说groovy是js和java的集合
对于js:
<script>
var x = ""
for (i in "etst") {
console.log(i)
if ("etst".hasOwnProperty(i)) {
x += "etst".charAt(i)
}
}
console.log(x)
script>
可以发现他们是不同的,我们继续回到groovy的说明,他是基于java的,注意,只是基于,并不代表相等,同样的,这里的脚本也是基于,所以不是同样的处理是正常的,并且他们都是基于java的,包括脚本,虽然脚本看起来类似于js
还有while:
def x = 0
def y = 5
while (y-- > 0) {
x++
}
println(x)
assert x == 5
还有do while:
def count = 5
def fact = 1
do {
fact *= count--
} while (count > 1)
println(fact)
assert fact == 120
对于的语句基本说明完毕,了解即可
Groovy 中的类型有:
类型及权限修饰符:
1:原生数据类型及包装类:

2:类、内部类、抽象类、接口
3:注解
4:Trait:可以看成是带有方法实现的接口
权限修饰符:public,protected,private,默认是public,所以并没有java的那个默认
上面的基本类似于Java,因为可以在对应的class中进行处理上面这些
那么我们可以认为Groovy 类与 Java 类之间的主要区别是:
1:默认可见性修饰符的类或方法自动是公共的(可以使用一个特殊的注释来实现包的私有可见性)
比如:
package com.bao1
class test {
void fa() {
println(1)
}
}
package com.bao2
class test {
static void main(String[] args) {
def a = new com.bao1.test();
a.fa();
}
}
很明显,在不同的包下,可以调用到,如果要操作私有,那么可以在类上加上@PackageScope,但是现在好像并不可以了,具体可以百度,还是需要看版本的
2:默认可见性修饰符的字段将自动转换为属性,不需要显式的 getter 和 setter 方法,比如:
package com.bao3
class test {
def g = "2"
static void main(String[] args) {
def a = new test()
a.setG("44")
println(a.getG())
}
}
3:如果属性声明为 final,则不会生成 setter
package com.bao3
class test {
final def g = "2"
static void main(String[] args) {
def a = new test()
a.setG("44")
println(a.getG())
}
}
因为不可以改变,也可以手动覆盖生成的:
package com.bao3
class test {
def g = "2"
void setG(def g) {
this.g = "55";
}
static void main(String[] args) {
def a = new test()
a.setG("44")
println(a.getG())
}
}
因为存在层级,先处理对应的子类
4:一个源文件可能包含一个或多个类(但是如果一个文件不包含类定义的代码,则将其视为脚本),脚本只是具有一些特殊约定的类,它们的名称与源文件相同(所以不要在脚本中包含与脚本源文件名相同的类定义),这在前面我们已经说明过了
当然,还有很多区别,比如循环中的区别,这里只是说明主要的区别,这里的区别了解即可
如果还需要知道一些区别,可以到这里看看:http://www.groovy-lang.org/objectorientation.html
集合操作:
Groovy 支持List、Map 集合操作,并且拓展了 Java 中的API,具体参考如下方法:
List:
add():添加某个元素
remove():删除指定下标的元素
removeElement():删除某个指定的元素
removeAll():移除某个集合中的元素
pop():弹出list 集合中最后一个元素
putAt():修改指定下标的元素
size():获取list 列表中元素的个数
contains():判断列表中是否包含指定的值,若是包含则返回 true
package com.bao3
def a = new ArrayList();
a.add("1")
a.add("2")
println(a)
a.remove(0);
println(a)
a.add("6")
a.add("6")
println(a)
a.removeElement("6")
println(a)
def b = new ArrayList()
b.add("2")
a.removeAll(b)
println(a)
a.add("7")
a.add("8")
println(a)
def v = a.pop();
println(a)
println(v)
a.putAt(0, "10")
println(a)
println(a.size())
println(a.contains("8"))
Map:
put():向map 中添加元素
remove():根据某个键做移除,或者移除某个键值对
+、-:支持 map 集合的加减操作
package com.bao3
def a = new HashMap();
a.put("a", "2")
a.put("b", "3")
println(a)
a.remove("a")
println(a)
def b = new HashMap();
b.put("b", "3");
a = a - b;
println(a)
集合里面可以存放不同类型的,这很常见
如果需要知道更多的api或者操作,可以看这个:http://www.groovy-lang.org/syntax.html
当然,前面(后面其实可能也是如此)给出的地址其实都是同样的,都是http://www.groovy-lang.org,而后面的只是在对应页面的选择,如果对应的页面选择给出的是错误的,重新点击便可(自己找吧)
当然,上面这些方法你可能是找不到的,因为文档可能也并不会都给出,或者说都给出细节操作,具体的话,可以百度
类导入:
Groovy 遵循 Java 允许 import 语句解析类引用的概念
package com.bao3
import groovy.xml.MarkupBuilder
def xml = new MarkupBuilder()
println(xml)
assert xml != null
具体为什么之前的操作我们没有导入呢,特别是集合呢,是因为groovy隐藏的导入了,也就是说,默认导入了一些java类,所以我们可以看到编码后的字节码中可以发现存在导入,但我们并没有在groovy中导入,特别是集合,所以是隐藏的导入了
那么groovy默认,或者说隐藏的导入是什么:
Groovy 语言默认提供的导入:
import java.lang.*
import java.util.*
import java.io.*
import java.net.*
import groovy.lang.*
import groovy.util.*
import java.math.BigInteger
import java.math.BigDecimal
这样做是因为这些包中的类最常用,通过导入这些样板代码减少了(可能在class中看不到,那么一般在其父类中,或者说,他虽然默认导入上面的,但是只有当你使用时,他才会选择导入,这一般是一种groovy的优化机制,当然,这可能也需要看版本(一般这样的说明,都是对对应的主体进行的版本,这里是groovy,当然,可能也包含关联他的,比如idea,所以版本是最终生成中,过程的所以的看版本))
参考官网地址:http://www.groovy-lang.org/structure.html#_imports
异常处理:
Groovy 中的异常处理和 java 中的异常处理是一样的
package com.bao2
class test {
static void main(String[] args) {
def z = 0;
try {
z = 9;
} catch (Exception e) {
e.printStackTrace()
}
}
}
参考官网地址: http://www.groovy-lang.org/semantics.html#_try_catch_finally
闭包:
这是给脚本的(类似js),所以他存在闭包,只不过前面我们说过,只是基于他们,所以这里的闭包概念可能并不等于js的闭包概念,我们看如下即可:
闭包:Groovy 中的闭包是一个开放的、匿名的代码块,它可以接受参数、也可以有返回值,闭包可以引用其周围作用域中声明的变量
语法:{ [closureParameters -> ] statements }
其中[ closureParameters-> ]是一个可选的逗号分隔的参数列表,参数后面是 Groovy 语句,参数类似于方法参数列表, 这些参数可以是类型化的,也可以是非类型化的,当指定参数列表时,需要使用-> 字符,用于将参数与闭包体分离
来一个案例:
package com.bao2
def code = { 123 }
println(code)
println(code.call())
闭包简单来说,对java来说就是一个实例而已,只是我们可以这样写,最后由语法进行解析(闭包有参数)
再来几个例子:
package com.bao2
def item = 10;
println({ (++item)++ }.call())
println({ item++ }.call())
println({ item++ }(1))
println({ { item } }(1))
println({ -> item++ }.call())
println({ -> }.call())
def g = { println it };
println({ -> println(123) })
println({ println(123) })
println({ println(123) }())
println(g)
println(6)
g(1)
println({ println it; it = 1; }.call())
println(2)
println 4;
println({ println it }(1))
println(3)
println({ it -> println it }(1))
println({ name -> println name }(2))
println({ name -> println name; it = 9 }.call())
println(9)
println({ String x, int y ->
println "hey ${x} the value is ${y}"
}("33", 3))
def j = 9;
println(80)
println({ name -> println name; it = 9 }.call())
println({ name ->
println name;
it = 9
}.call())
println({ i, u ->
println "hey the value is";
it = 1;
}(2, 3))
println({ it, u ->
println "hey the value is";
}(2, 3))
println({ reader ->
def line = reader
println(line)
}.call(new String("123")))
println({ println it }.call(1));
参考:http://www.groovy-lang.org/closures.html
我们可以直接的传递闭包:
package com.bao2
def a(Closure closure) {
println(1)
closure();
closure.call()
println(1)
}
a({ println(2) })
a(){ println(2) }
a{ println(2) }
前面我们操作的是Groovy,那么我们使用idea创建关于他的项目,也就是构建工具项目,就如java中存在maven来操作他,那么同样的groovy也有对应的构建工具(也由于他基于java),所以对应的构建也是操作java的,一般我们将这样的构建工具称为gradle,或者说Gradle 是一种基于 Groovy 的构建工具(同样的,在前面或多或少也有原因,如创建gradle时是需要groovy的)
我们进入idea,操作如下:
注意:上面的groovy可以不用选择(这里你别选择了吧),让idea单纯的操作java也可以,他只是一个语言替代,并非一定使用他,或者说他只是一种兼容方式,基本上他只是用来写一些东西,如gradle,并非用来开发
然后我们设置这样的:
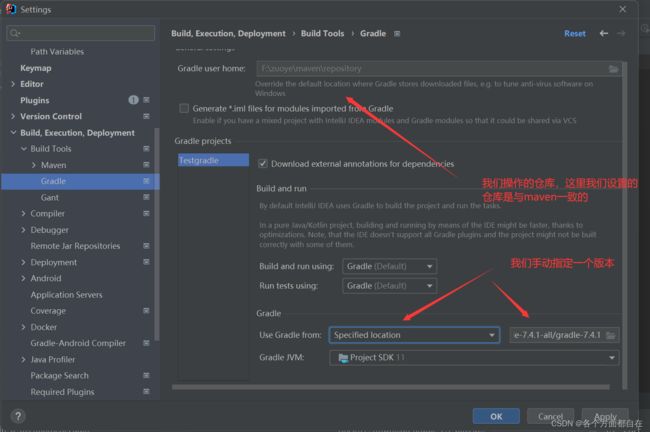
手动指定版本是为了拿取我们需要的版本,否则idea可能并不会通过环境变量来操作对应的gradle,这样也就导致了我们设置的源,可能并不会起作用
等等idea右下角初始化完毕吧(其实maven也是操作初始化的,这在后面会补充maven的相关知识),如果非常慢,并且没有wrapper文件,一般是从远程下载的,远程下载是会比较慢的,然后就会比较快,当然,如果可以,你可以创建对应的文件,因为idea中也是操作对应的前面的命令行操作的,只是他是一系列的处理的
正是由于可以手动选择,所以他可能与前面测试的版本不一样,当然,这里是一样的
当然,如果以后改变仓库,那么下载的并不会移动的,这是必然的
注意了,gradle只是一种构建工具,具体的情况与maven相同,只是目录结构和依赖处理方面不同而已,所以操作web几乎与maven中一样,或者说也需要手动的添加对应的目录文件
接下来我们了说明其他文件,一般在命令行中操作的东西,在依赖中可能也会进行处理(比如指定测试的排除或者包含,具体可以百度)
项目的生命周期:
Gradle 项目的生命周期分为三大阶段:Initialization -> Configuration -> Execution,每个阶段都有自己的职责,具体如下图所示:
Initialization -> Configuration -> Execution:初始化->配置->执行
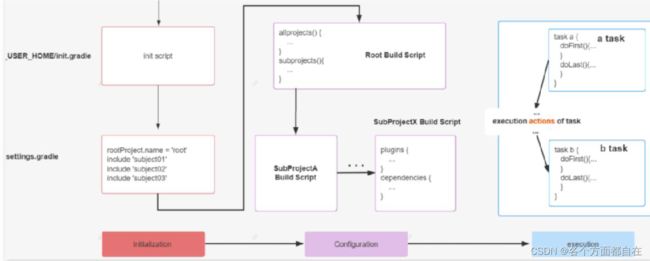
Initialization 阶段主要目的是初始化构建,它又分为两个子过程,一个是执行 Init Script(也可以解释前面的每个init脚本都实现了Script接口,gradle最后由class操作后时的接口),另一个是执行 Setting Script,其中Init Script在前面我们说明了,也就是init.gradle的操作,每次操作都需要这个,比如我们前面设置了源,提高的速度
init.gradle 文件会在每个项目 build 之前被调用,用于做一些初始化的操作,它主要有如下作用:
1:配置内部的仓库信息(如公司的 maven 仓库信息)
2:配置一些全局属性,特别的,如源(数据源)
3:配置用户名及密码信息(如公司仓库的用户名和密码信息)
Setting Script 则更重要,它初始化了一次构建所参与的所有模块,类似于maven中的父模块,虽然他一般是统一的
Configuration 阶段:这个阶段开始加载项目中所有模块的 Build Script,所谓 “加载” 就是执行 build.gradle 中的语句,或者说为下载依赖做准备,就如maven中的pom.xml(虽然他是直接下载,但他也是可以分阶段的,如果细化的话),根据脚本代码创建对应的 task,最终根据所有 task 生成由 Task 组成的有向无环图(Directed Acyclic Graphs),如下:
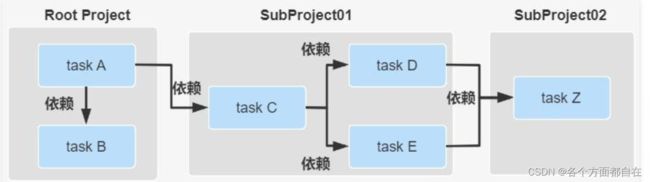
从而构成如下有向无环树:

Execution 阶段:这个阶段会根据上个阶段构建好的有向无环图,按着顺序执行 Task(Action 动作),根据上面的图来说,顺序一般是从上到下,从左到右的,主要是需要保证依赖后的数据是存在的,比如:A依赖B,如果先处理A,那么他如果需要B的信息的话,是获取不到的,所以应该是需要先处理B
settings 文件,也就是Setting Script,或者说settings.gradle文件:
首先对 settings 文件的几点说明:
1:作用:主要是在项目初始化阶段确定一下引入哪些工程需要加入到项目构建中,为构建项目工程树做准备
2:工程树:gradle 中有工程树的概念,类似于 maven 中的project 与module

3:内容:里面主要定义了当前 gradle 项目及子 project 的项目名称
4:位置:必须放在根工程目录下
5:名字:为settings.gradle文件,不能发生变化
6:对应实例:与 org.gradle.api.initialization.Settings 实例是对应的关系,每个项目只有一个settings 文件
7:关注:作为开发者我们只需要关注该文件中的include 方法即可,使用相对路径[:]引入子工程
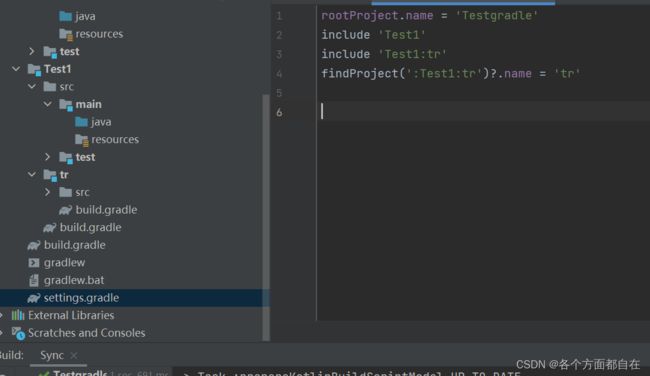
8:一个子工程只有在setting 文件中配置了才会被 gradle 识别(在maven中是自动加上的,否则也需要手动,虽然这里通常也会自动加上),这样在构建的时候才会被包含进去,案例如下所示:

这个时候,可以在父对应的settings文件中,可以找到:
rootProject.name = 'Testgradle'
include 'Test1'
比如include 'Test1’就是生成的,一般指定了groovy才可以创建groovy,当然,这一般是依赖的处理,只需要加上这个即可
也就是implementation ‘org.codehaus.groovy:groovy-all:3.0.5’
一般这是我们创建gradle时,给出的默认groovy,或者说,这是idea一开始的指定的gradle自带的groovy,当然,他是否被我们配置所改变,这就需要看idea具体如何操作了,且也要知道,依赖是可以影响idea的,因为idea就是主要操作java的,有关联也正常,比如热部署,和这里的groovy的创建
如果再创建子模块:
注意,创建时,需要确定路径哦(他并不像maven中一样可以指定子模块,都是指定父的,只是根据路径来判断是否是子模块的子模块)
在上面依赖中,项目名称中 “:” 代表项目的分隔符,类似路径中的 “/”,如果以 “:” 开头则表示相对于 root project,然后 Gradle 会为每个带有 build.gradle 脚本文件的工程构建一个与之对应的 Project 对象,即你看到后面的find开头的吗,就是":"开头,并且是找到的意思
Task(也称任务):
项目最后实质上是 Task 对象的集合,当然,只是代码处理代码,而非编写代码,一个 Task 表示一个逻辑上较为独立的执行过程,比如编译Java 源代码,拷贝文件, 打包Jar 文件,甚至可以是执行一个系统命令,另外,一个 Task 可以读取和设置Project 的Property 以完成特定的操作,简单来说,他就是读取你的代码的过程到项目的处理,除了编写代码,其他的基本都是一个一个的任务,这对maven中也可以说是这样
任务入门:
可参考官方文档:https://docs.gradle.org/current/userguide/tutorial_using_tasks.html
让我们来先看一个例子:
在这之前,我们先创建一个gradle项目:

对应的依赖说明,在后面会进行提到,现在了解即可
我们就在这个依赖文件中,在后面加上如下,这里其实也是由groovy来操作的,只是他可能先进行了其他的处理(因为groovy用来操作gradle的构建的):
比如我们在groovy可以这样:
package com.bao2
def f(String s, Closure closure) {
println(s)
closure()
}
f("a", { println(1) })
f("a") { println(1) }
但是上面报错的地方在下面的可以,这取决于他的后缀,也就是其他的处理,所以可以如下操作:
task A {
println "root taskA"
doFirst(){
println "root taskA doFirst"
}
doLast(){
println "root taskA doLast"
}
}
我们先知道这个,至于如何操作先不说明,提示一下:在前面说,每个init脚本都实现了Script接口,因为脚本最后操作的class,就是继承了对应的Script类,我们只是将这个类称为了接口而已,当然,更多情况下,他是一个新的类,只是没有具体说明
再上面的代码中,意思是如此:
在文件所在的目录执行命令:gradle A,前提先进行刷新来操作这个文件或者依赖
task 的配置段是在配置阶段完成,注意不是初始化阶段
提示 2:task 的doFirst、doLast 方法是执行阶段完成,并且doFirst 在doLast 执行之前执行
提示 3:区分任务的配置段和任务的行为,任务的配置段(配置项)在配置阶段执行,任务的行为在执行阶段执行,简单来说,也就是方法准备执行和方法执行,识别该文件只是方法准备执行
所以可以这样的认为,方法定义,也就是A,在初始化阶段,配置阶段是方法的准备执行,这里一般是上面的println "root taskA"进行打印,执行阶段是里面的方法执行
比如:现在你就刷新,在项目目录下,注意,需要与该build.gradle所在目录位置一致,执行gradle -i A,看看结果:
一般在idea中的对应目录的终端可以看到,先打印root taskA,也就是配置阶段,然后打印一些其他信息,最后连续打印root taskA doFirst和root taskA doLast,也就是执行阶段,当然,就算你交换上面的两个方法的位置,也同样如此,就算再单纯的打印之前写上方法也是如此,也就是说,其内部并不能看成一个方法,他是需要先处理,才会操作groovy(因为他的后缀可不是groovy,而是gradle),所以里面是一种规定,先操作单纯的打印,然后操作规定的方法,所以也就导致了,如果你随便写一个方法,那么就会报错,刷新,构建报错(编译是再执行后处理的),刷新最简单的说,就是生成或者构建项目,而非执行,只是单纯的操作文件或者加上代码的意思
任务的行为:
doFirst、doLast 两个方法可以在任务内部定义,也可以在任务外部定义,且由于gradle只是部分的与groovy不同,其他的基本也可以操作groovy,所以可以看如下:
task A {
println "root taskA"
doFirst(){
println "root taskA doFirst"
}
doLast(){
println "root taskA doLast"
}
}
A.doFirst{
println 11
}
A.doLast{
println 22
}
忽略其他的打印(因为是前面存在的,除非去掉),最终是这样的:
root taskA
11
root taskA doFirst
root taskA doLast
22
按照这样的说法,外面(有时候会粗心,将外面写成了我们,结合上下文意思,注意即可)的直接操作是先进行的,也就是gradle是先处理外面,再处理里面,只是外面的doLast却需要最终处理
这是因为doLast是再外面的后执行,外面的后执行,自然是最靠后的,即靠前也靠后
我们再来看一个案例:
def map=new HashMap<String,Object>();
map.put("action",{println "taskD.."})
task(map,"a"){
println map.get("action")()
description 'taskA description'
group "atguigu"
doFirst {
def name = 'doFirst..'
println name
}
doLast {
def name = 'doLast..'
println name
}
}
a.doFirst {
println it.description
}
a.doLast {
println it.group
}
打印:
taskD..
null
taskA description
doFirst..
taskD..
doLast..
atguigu
底层原理分析:无论是定义任务自身的 action(Task,也称为action动作,这里简称为action),还是添加的doLast、doFirst 方法,其实底层都被放入到一个Action 的List 中了,我简称为集合
他是一个顺序,最初这个集合是空的,当我们设置了 action的任务自身的行为,它先将action添加到列表中
此时列表中只有一个action,后续执行doFirst 的时候,doFirst 在action 前面添加,执行 doLast 的时候,doLast 在action 后面添加
doFirst 永远添加在集合的第一位,保证添加的action在现有的 集合元素的最前面,doLast 永远都是在集合末尾添加,保证其添加的action在现有的集合元素的最后面
一个往前面添加,一个往后面添加,最后这个集合就按顺序形成了doFirst、doSelf、doLast 三部分的 Actions,就达到 doFirst、doSelf、doLast 三部分的 Actions 顺序执行的目的,而doSelf也就是先将map添加到列表中的简称,所以我们解释这个代码:
task A {
println "root taskA"
doFirst(){
println "root taskA doFirst"
}
doLast(){
println "root taskA doLast"
}
}
A.doFirst{
println 11
}
A.doLast{
println 22
}
首先我们看如下:
[][][][][]
我们先将A也就是doSelf放入上面的列表中,A中操作的是配置阶段的处理(但是他是action的处理,所以放在这里,否则配置阶段是绝对先操作打印的),也就上面的map,简称为A
[][][A][][]
然后读取A里面的信息
doFirst(){
println "root taskA doFirst"
}
放在前面,简称为doFirst
[][doFirst][A][][]
读取A里面的信息
doLast(){
println "root taskA doLast"
}
放在后面,简称为doLast
[][doFirst][A][doLast][]
A信息读取完毕,然后读取外面的信息
A.doFirst{
println 11
}
放在前面,简称为A-doFirst注意,必须doFirst 永远添加在actions List(这个集合) 的第一位,所以是这样的
[A-doFirst][doFirst][A][doLast][]
继续读取外面的
A.doLast{
println 22
}
放在后面,简称为A-doLast,同理也是最后一位,所以是这样的
[A-doFirst][doFirst][A][doLast][A-doLast]
简化
[A-doFirst]
[doFirst]
[A]
[doLast]
[A-doLast]
对比这样的:
taskA description
doFirst..
taskD..
doLast..
atguigu
一般这个集合只是代码执行阶段,在配置阶段是优先于这个集合的,所以前面的案例中,对应的
taskD..
null
出现是合理的
按道理说,他们都是一个可以执行的东西,而不应该可以保存的,但是要记住,虽然有部分与groovy类似,但是他始终并不是groovy,很明显,他是在识别后,才进行保存的,最后由groovy操作这个list集合里面的信息(甚至可以认为用很多对象的方法来包括这些,而操作集合就是调用这些对象的方法,自然打印操作包括的内容,自然也就打印了上面的处理),从而完成前面的顺序的处理
当然了,可能存在其他的语法可以进行同样的操作,但是,一般也需要看版本来进行处理,groovy在不同版本中,存在的语法也是不同的,所以需要注意了
任务的依赖方式:
这里的任务,我们也可以明显的知道,是操作依赖的地方,在maven中可能并没有这样的灵活处理,gradle虽然够灵活,但是也比较繁琐,并且由于构建的问题(并不像maven需要全部构建),所以Gradle适用于需要更高性能和更为灵活的项目,否则我们建议使用maven(因为生态较好),这也是为什么大多数源码基本都会优先考虑gradle
Task 之间的依赖关系可以在以下几部分设置:
方式一:参数方式依赖
task A {
doLast {
println "TaskA.."
}
}
task 'B' {
doLast {
println "TaskB.."
}
}
task C(dependsOn: ['A', 'B']) {
doLast {
println "TaskC.."
}
}
很明显,这样操作是C依赖B和A,A和B是并行的,操作完后,然后操作C的,虽然我们这里是直接的操作认为,但是实际上gradle是以任务来操作依赖的,而非maven的坐标的依赖方式,他们是不同的处理,不要将他们强行融合的说明
但是经过大量的测试,我们可以发现,无论你怎么改变其参数的A和B顺序,还是task的编写顺序,基本都是A的操作先处理,这可能存在某些识别的问题,虽然理论上来说,我们认为是并行的,但是大量测试证明了可能有其他影响,或者说,并不能完全的认为是并行,我们将B修改成D,A修改成F,可以发现,D的操作一直先处理,基本说可以认为谁的ascii小,谁优先处理,当然了,不看测试的话,我们认为是并行的,但是说明并行也并无道理,因为打印可能受某些影响,虽然打印几乎是不受影响的,因为打印就是打印,基本是不会被影响的,就算受,那么我们交换顺序,那么不应该也会改变吗,但是打印结果还是一样的
方式二:内部依赖
task A {
doLast {
println "TaskA.."
}
}
task 'B' {
doLast {
println "TaskB.."
}
}
task 'C' {
dependsOn= [A,B]
doLast {
println "TaskC.."
}
}
方式三:外部依赖
task A {
doLast {
println "TaskA.."
}
}
task 'B' {
doLast {
println "TaskB.."
}
}
task 'C' {
println 2
doLast {
println "TaskC.."
}
}
println 1
C.dependsOn(B,A);
其实配置阶段,也存在外部,所以1也会在对应的集合之前打印,就因为他是配置阶段(虽然他也是后),那么为什么要说是配置阶段,因为他们最后是变成集合的,前面我们也解释了,会由对象方法接收,所以他们实际上必须在列表后执行,而其他的如我们说的配置阶段就会直接的处理,而不操作集合,并且由于解释的原因,他从上到下,是一路识别并且进行操作的,而不是保存任务后处理里面的内容,所以2先打印(识别造成,不看结构哦),再提醒一次,他的后缀是gradle,是需要识别解释的,而这种解释是这里的独一份,所以出现不与其他语言不一致的情况是正常的
当然:task 也支持跨项目依赖
我们在我们的gradleTask项目中,加上子项目(模块)gradleTask1
然后外面再gradleTask1的build.gradle 文件中定义:
task A {
doLast {
println "TaskA.."
}
}
然后再父项目中操作如下:
task B {
dependsOn(":gradleTask1:A")
doLast {
println "TaskB.."
}
}
外面回到之前说明的:项目名称中 “:” 代表项目的分隔符,类似路径中的 “/”,如果以 “:” 开头则表示相对于 root project(最终的父项目),然后 Gradle 会为每个带有 build.gradle 脚本文件的工程构建一个与之对应的 Project 对象
注意:重复的依赖只会执行一次,因为执行的初心,就是为了保证可以被依赖使用,所以只需要一次即可,比如外面可以这样处理:
task A {
doLast {
println "TaskA.."
}
}
task 'B' {
doLast {
println "TaskB.."
}
}
task C(dependsOn: ['A', 'B']) {
doLast {
println "TaskC.."
}
}
task D(dependsOn: ['A', 'B', 'C']) {
doLast {
println "TaskD.."
}
}
其中A和B只会执行一次,并且由于顺序,A和B先处理,C再依赖时,由于重复,就不需要再次的依赖A和B了,自然也就不会打印了
依赖关系,相当于操作对应的任务,自然就会操作其内部的处理,当然,配置阶段的处理是对应的执行的任务一人处理,所以如果你在外部加上打印,但是也只会操作一次,因为你的任务是执行一个
任务执行(后面的可以测试一下,一般会给出部分的测试,具体百度了解吧):
常见的任务,或者任务执行:
可以测试一下gradle run,首先在这里加上如下::
plugins {
id 'java'
id 'application'
}
创建一个类:
package com;
public class test1 {
public static void main(String[] args) {
System.out.println(1);
}
}
然后补充这个:
plugins {
id 'java'
id 'application'
}
mainClassName = "com.test1"
println 22
这样点击run会执行里面的test1方法,也就是mainClassName指定的地址(没有这个,run执行会报错),当然,我们并没有操作任务,所以如果存在其他的打印,也会出现的,并且上面的22先打印,因为需要先操作配置项,他是外部的配置项(内部的是任务里面的,如直接表达式,如也是同样的这样的打印)
项目报告相关任务(一般代表右边显示的东西):
task A {
group 'org.example'
doLast {
println "TaskA.."
}
}
调试相关选项:
性能选项(在gradle.properties 中指定这些选项中的许多选项,因此不需要命令行标志,如果项目里面没有gradle.properties(他是一个整体,而不是gradle里面的properties 文件) 文件,可以选择创建,具体内容可以百度,一般他的配置是全局的,且是当前项目):
这些文件的处理都是groovy在构建时进行的,识别build.gradle也是他,最后编译变成字节码文件,在maven中其实也是被这样的识别,虽然他是Java来识别,最后编译变成字节码文件,其依赖也相当于我们的任务
守护进程选项:
日志选项:
其他的:
具体可以看文档:https://docs.gradle.org/current/userguide/command_line_interface.html#sec:command_line_executing_tasks
gradle的任务名可以是缩写,任务名支持驼峰式命名风格的任务名缩写,如:connectTask 简写为:cT,执行任务就是 gradle cT,当然,并非都可以,因为存在相同驼峰,单词不同的情况,哪个时候可能会报错,或者依赖ascii等或者相关的顺序处理(一般我们说明ascii时,默认是包括相关的顺序处理的,只是没有提示而已)
前面提到的Gradle 指令本质是一个个的task任务,可以说Gradle 中所有操作都是基于任务完成的,虽然maven中依赖与执行直接并没有关联,而不是gradle的一样的统一,gradle在执行项目之前,操作的都是任务,而maven在执行任务之前,可以说是maven依赖处理和maven编译,打包等等的处理,而非一个东西
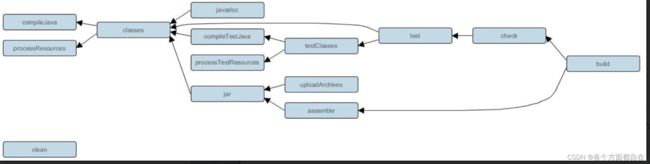
gradle 默认各指令之间相互的依赖关系:

任务定义方式:
任务定义方式,总体分为两大类:一种是通过 Project 中的task()方法,另一种是通过tasks 对象的 create 或者register 方法
比如说:
task qianmian {
doLast {
println "qianmian"
}
}
task('A',{
println "taskA..."
})
task('B'){
println "taskB..."
}
task C{
println "taskC..."
}
def map=new HashMap<String,Object>();
map.put("action",{println "taskD.."})
tasks.create('E'){
println "taskE.."
}
tasks.register('f'){
println "taskF "
}
除了D(他必须手动的给出对应的处理,否则自然不会加上在这里),其他的基本都会按照顺序来操作(当然,也只是对配置项来说的,否则只能操作对应任务指定的方法,配置阶段是根据顺序的,这里需要明确注意(因为上面的都是配置阶段的打印)),当只有一个A或者a时,A和a都可以操作他,如果存在,那么A操作A,a操作a
也就是说,只要你被识别是一个可以执行的任务,那么就会处理(虽然这个时候会操作顺序)
当然:我们也可以在定义任务的同时指定任务的属性,具体属性有:

在定义任务时也可以给任务分配属性:定义任务的时候可以直接指定任务属性,也可以给已有的任务动态分配属性:
plugins {
id 'java'
}
task(group: "atguigu",description: "this is task B","F")
task("H") {
group("atguigu")
description("this is the task H")
}
task "y"{}
y.group="atguigu"
clean.group("atguigu")
注意事项:一般情况下,clean是默认构建的任务,而这个默认构建一般需要:
plugins {
id 'java'
}
他必须写在最前面,这是规定,写上后,才会默认构建任务(比如,只有写上他时,右边才会出现build的组),这个时候才会存在clean,否则操作clean是找不到并且报错的
这个时候,可以在右边看到atguigu组了,并且看看里面是否是我们定义的任务吧
任务类型:
前面我们定义的task 都是DefaultTask 类型的(或者说,是在java中的一个对象而已),如果要完成某些具体的操作,完全需要我们自己去编写gradle 脚本,势必有些麻烦,那有没有一些现成的任务类型可以使用呢,有的,Gradle 官网给出了一些现成的任务类型帮助我们快速完成想要的任务,我们只需要在创建任务的时候,指定当前任务的类型即可,然后即可使用这种类型中的属性和API 方法了
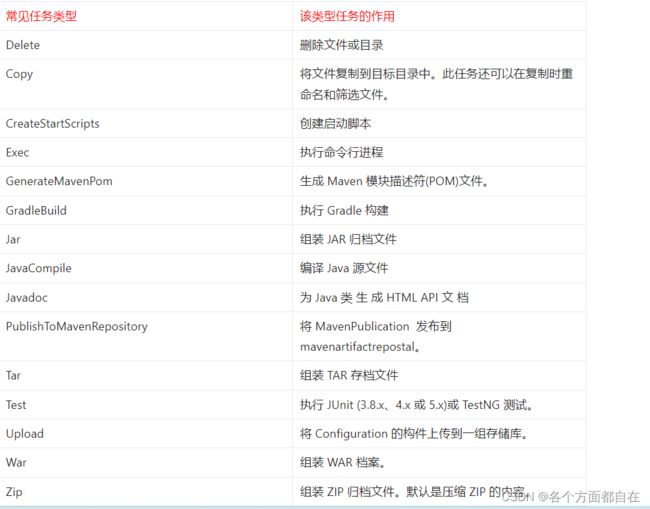
如果想看更详细的gradle 自带Task 类型,请参考官方文档:https://docs.gradle.org/current/dsl/index.html
我们可以选择操作一下案例:
plugins {
id 'java'
}
tasks.register('myClean',Delete){
delete buildDir
}
这样会删掉build的目录的,其中Delete就是指定类型,一般指定的操作通常只能在register中进行处理
实际上分组有个好处,就是可以不用我们在命令行中操作命令来执行,而是可以直接的在右边点击执行,所以我们可以这样的处理:
tasks.register('myClean',Delete){
group("atguigu")
delete buildDir
}
注意了,他还是任务,只是补充了类型而已,使得可以操作对应的操作,或者识别了对应的操作,如delete buildDir,否则delete buildDir是报错的或者是忽略的,当然,gradle存在内置的类型或者说是自带的类型,或者说是默认的类型,比如Delete就是,所以这里删除并不会报错或者忽略(或者说自带的)
自定义task类型:
def myTask = task MyDefinitionTask(type: CustomTask)
myTask.doFirst() {
println "task 执行之前 执行的 doFirst方法"
}
myTask.doLast() {
println "task 执行之后 执行的 doLast方法"
}
class CustomTask extends DefaultTask {
@TaskAction
def doSelf() {
println "Task 自身 在执行的in doSelf"
}
}
任务的执行顺序:
在 Gradle 中,有三种方式可以指定 Task 执行顺序:
1、dependsOn 强依赖方式
2、通过 Task 输入输出
3、通过 API 指定执行顺序
详细请参考官网:https://docs.gradle.org/current/dsl/org.gradle.api.Task.html
动态分配任务:
gradle 的强大功能不仅仅用于定义任务的功能,例如,可以使用它在循环中注册同一类型的多个任务
这里也不得不说一下任务与maven中依赖在代码中的作用,首先是任务,我们可以发现,他其实也是代码的处理,只不过,其gradle识别后,groovy识别后,变成java字节码后,对这些代码进一步处理,这个时候,才会考虑对应的jar包的处理,也就引出一个问题,我们可以在java中手动的加载jar包吗,其实是可以的(可以使用类加载器),那么任务是合理的,因为他极大的简化了这样的操作,那么maven呢,他是一系列的下标组成,其实maven中xml其实也是被java所读取,根据下标和配置的仓库位置,gralde同样的也是如此,如果有就拿取,没有就下载,这在gralde和maven中都是如此,最后由类加载器进行加载,所以无论是gradle还是maven,其本质上都是根据下标来使得加载jar包(因为要手动加载是需要具体(磁盘)路径的),但是gradle之所以快,是因为他的识别快,一级其代码在一定程度上可以使用java语法来处理,而不是单纯的xml,更加灵活,所以其可以在构建时,就可以选择指定路径(因为存在代码),而不是通过配置的解析,然后操作,所以其构建速度,就是因为xml存在解析,而gradle只存在识别转换的区别,但是gradle通常被认为在编译方面更灵活且具有更好的性能,并且并不只有这一点,比如gradle比maven快,可能还存在如下:
1:增量构建:Gradle 支持增量构建,只重新构建发生变化的部分,这意味着在一次构建中,如果没有文件发生变化,Gradle 可以避免不必要的重新编译和重新处理(而maven可能会全部重新编译或者处理)
2:并行构建:Gradle 默认支持并行构建,可以同时处理多个任务,这使得在多核机器上构建速度更快,特别是对于大型项目
3:DSL 的灵活性:Gradle 使用 Groovy 或 Kotlin 作为 DSL(领域特定语言),使得构建脚本更为灵活、易读且易写,相比之下,Maven 使用 XML,其语法相对繁琐
4:自动化任务:Gradle 提供了丰富的任务生命周期和钩子,可以用于执行各种定制的构建和任务,这使得 Gradle 更容易适应不同项目的需求
5:灵活的依赖管理:Gradle 允许使用各种方式声明和管理依赖关系,包括使用 Maven Central、本地文件系统、其他项目等,这种灵活性有助于优化依赖解析的速度
6:缓存机制:Gradle 使用了强大的缓存机制,包括任务输出缓存、构建缓存等,这可以避免在相同配置下的重复工作,提高了构建的效率
回归正题,可以使用gradle在循环中注册同一类型的多个任务
4.times { counter ->
tasks.register("task$counter") {
doLast {
println "I'm task number $counter"
}
}
}
tasks.named('task0') { dependsOn('task2', 'task3') }
任务的关闭与开启:
每个任务都有一个 enabled,默认为的标志 true,将一个任务的enabled设置为 false ,那么将阻止他执行任何任务动作,那么该禁用的任务相当于将标记为"跳过"的意思
task disableMe {
doLast {
println 'This task is Executing...'
}
enabled(true)
}
disableMe.enabled = false
可以选择注释掉disableMe.enabled = false,这样可以看到不同点了
任务的超时:
1:每个任务都有一个 timeout 属性:Gradle 中的每个任务都可以设置一个 timeout 属性,用于限制任务的执行时间,timeout 属性指定任务在多长时间内应该完成
2:任务达到超时时,执行线程将被中断:如果任务执行时间超过了设定的 timeout,Gradle 会中断该任务的执行线程,这意味着任务的代码将被强制停止
3:任务标记为失败:超时发生后,Gradle 将标记该任务为失败,这表示任务由于超时而未能正常完成
4:终结器任务仍将运行:如果有配置了终结器任务(finalizer task),这些任务将仍然运行(因为并不是对应的线程),终结器任务通常用于清理或执行其他必要的操作
5:–continue 参数的影响:如果使用了 --continue 参数,表示 Gradle 在遇到失败任务时会继续执行后续的任务,这意味着即使某个任务超时失败,其他任务仍然会被执行,也就是线程没有被停止,只是对应的任务停止了
6:其他任务可以在此之后继续运行:如果 --continue 被使用,那么即使某个任务超时失败,后续的任务仍然会被执行,而不会因为前面的任务失败而中止整个构建过程,也就是线程没有被停止
7:不响应中断的任务无法超时:如果某个任务的代码逻辑不响应中断(例如忽略了 InterruptedException 异常),那么即使设置了超时,该任务可能无法在超时时停止执行,也就是说,超时需要这个异常,更加具体的说,超时就会操作中断,而中断要报错,就需要这个异常,自然就会导致后面的解释,否则,不报错,后面的会继续处理,因为这个时候,你只是改变状态而已,具体情况如下:
在一个任务在执行时,在执行之前,我们设置了这个超时配置,那么他就会根据时间来最终操作中断,而停止,如果没有对应的异常,那么他也就是根据这个超时时间改变中断状态而已,所以这也是为什么没有这个异常,那么他可能不会停止,中断的状态是可以在睡眠中的内部进行自动得到的,因为线程的关系,这里需要去101章博客去学习
8:Gradle 的所有内置任务均会及时响应超时:Gradle 保证其内置任务会及时响应超时(因为有对应的异常),即使任务内部使用了耗时较长的操作
task a() {
doLast {
Thread.sleep(1000)
println "当前任务a执行了"
}
timeout = Duration.ofMillis(500)
}
task b() {
doLast {
println "当前任务b执行了"
}
}
这个时候如果操作a的任务执行,是会报错的,当然,如果去掉对应的方法,自然就是先等待(sleep先操作的),然后设置,而不是先设置了(配置阶段),这个时候自然正常打印,所以可以选择注释掉对应的doLast方法来看看不同的结果
当然,我们可以验证报错所造成的影响,我们可以操作gradle a b,这个时候看看去掉注释与没有去掉的区别,没有去掉,由于a报错,b自然不会执行,去掉后,a执行后,b也会执行
任务的查找:
常用的任务查找方法有:
task atguigu {
doLast {
println "哈哈"
}
}
tasks.findByName("atguigu").doFirst({
println "哈哈1"
})
tasks.getByName("atguigu").doFirst({
println "哈哈2"
})
tasks.findByPath(":atguigu").doFirst({
println "哈哈3"
})
tasks.getByPath(":atguigu").doFirst({
println "哈哈4"
})
任务的规则:
当我们执行、依赖一个不存在的任务时,Gradle 会执行失败,报错误信息,比如gradle sahsasasdadada(也可以这样,gradle aa bb,aa报错,那么bb就不会执行了),这一般没有定义的话,就是失败的,那我们能否对其进行改进,当执行一个不存在的任务时,不是报错而是打印提示信息呢
task hello {
doLast {
println '哈哈1'
}
}
tasks.addRule("对该规则的一个描述,便于调试、查看等") { String taskName ->
task(taskName) {
doLast {
println "该${taskName}任务不存在,请查证后再执行"
}
}
}
任务的onlyIf断言:
断言就是一个条件表达式,Task 有一个onlyIf 方法,它接受一个闭包作为参数,如果该闭包返回 true 则该任务执行, 否则跳过(任务的执行是可以操作很多的,比如打包,测试,网络测试,就如maven中,也可以操作tomcat),这有很多用途,比如控制程序哪些情况下打什么包,什么时候执行单元测试,什么情况下执行单元测试的时候不执行网络测试等,具体案例如下所示:
task hello {
doLast {
println '哈哈'
}
}
hello.onlyIf {
!project.hasProperty('fensi')
}
只有对应的返回true,我们才会打印"哈哈",当然,如果返回false,那么不会进行打印,并且,如果是返回null(操作println,那么操作默认参数it,这个时候值是null)
默认任务:
Gradle 允许您定义一个或多个在没有指定其他任务时执行的默认任务,代码如下所示:
defaultTasks 'myClean', 'myRun'
tasks.register('myClean') {
doLast {
println 'Default Cleaning!'
}
}
tasks.register('myRun') {
doLast {
println 'Default Running!'
}
}
tasks.register('other') {
doLast {
println "I'm not a default task!"
}
}
单纯的执行gradle,而不指定任务,就会操作对应的两个配置的默认任务
一般情况下,单纯的执行gradle是没有任何操作的,当然,只是任务而已(一般也只有任务),配置阶段的会处理的(在任务里的配置阶段自然操作)
当然,之所以会这样,是因为首先需要进行识别,而识别到groovy中就会操作位置的处理,最终由java执行时,就会执行打印出来
Gradle 中的文件操作:
几种常见的文件操作方式:
1:本地文件
2:文件集合
3:文件树
4:文件拷贝
5:归档文件
本地文件:
使用 Project.file(java.lang.Object)方法,通过指定文件的相对路径或绝对路径来对文件的操作(其实需要确定jar包,无论是对maven还是gradle,都需要操作文件,虽然maven是被java识别xml来得到文件,而gradle除了也指定位置外,还可以通过文件的处理来操作,所以gradle可以选择使用代码方面来处理,而不是单纯的坐标),其中相对路径为相对当前project[根project 或者子project]的目录,其实使用 Project.file(java.lang.Object)方法创建的 File 对象就是 Java 中的 File 对象,我们可以使用它就像在 Java 中使用一样,示例代码如下:
File configFile = file('src/conf.xml')
configFile.createNewFile();
configFile = file('D:\\conf.xml')
println(configFile.createNewFile())
configFile = new File('src/config.xml')
println 4
文件集合:
文件集合就是一组文件的列表,在 Gradle 中,文件集合用FileCollection接口表示,我们可以使用如下:
Project.files(java.lang.Object[])方法来获得一个文件集合对象,如下代码创建一个 FileCollection 实例:
def collection = files('src/test1.txt', new File('src/test2.txt'), ['src/test3.txt', 'src/test4.txt'])
collection.forEach() { File it ->
it.createNewFile()
println it.name
}
Set set1 = collection.files
println set1
Set set2 = collection as Set
println set2
List list = collection as List
println list
for (item in list) {
println item.name
}
def a = new ArrayList();
a.add("1")
a.add("2")
println(a)
def b = new ArrayList();
b.add("3");
def c = a + b;
println c
def union = collection + files('src/test5.txt')
def minus = collection - files('src/test3.txt')
union.forEach() { File it ->
println it.name
}
minus.forEach() { File it ->
println it.name
}
对于文件集合我们可以遍历它,也可以把它转换成java 类型,同时还能使用+来添加一个集合,或使用-来删除集合(这在前面我们也可能说明过)
这里可以粗略的说明一下,maven与gradle在最终处理的过程
maven:xml写上,刷新(java识别)拿取jar包,项目启动使用jar包
gradle:gradle写上,刷新(groovy识别)拿取jar包,项目启动使用jar包(可以是java代码,只是识别不是java),但是里面的代码操作,如任务,一般需要手动处理,如果可以,那么可以使用groovy来代替java进行编写代码,即同样的,gradle也可以写上具体代码来被识别(具体是groovy)
区别:gradle灵活,maven简单
当然,他们的启动,其实是操作了类似任务的启动而已(来帮忙启动的处理)
可以发现,maven和gradle在配置上的处理基本是一样的,只是结构不同,或者底层不同导致的区别,只是gradle更加的偏向底层的处理(也是速度更加快的原因,但也是麻烦的原因)
文件树:
文件树是有层级结构的文件集合,一个文件树它可以代表一个目录结构或一个ZIP 压缩包中的内容结构,文件树是从文件集合继承过来的,所以文件树具有文件集合所有的功能,我们可以使用 Project.fileTree(java.util.Map)方法来创建文件树对象, 还可以使用过虑条件来包含或排除相关文件,示例代码如下:
在这之前,我们首先创建这样的路径:

def tree = fileTree('src/main').include('**/*.java')
println 1
println tree
tree.each { File file ->
println file
println file.name
}
tree = fileTree('src/main') {
include '**/*.java'
}
println 2
println tree
tree.each { File file ->
println file
println file.name
}
tree = fileTree(dir: 'src/main', include: '**/*.java')
println 5
println tree
tree.each { File file ->
println file
println file.name
}
tree = fileTree(dir: 'src/main', includes: ['**/*.java', '**/*.xml', '**/*.txt'], exclude: '**/*test*/**')
println 6
tree.each { File file ->
println file
println file.name
}
文件拷贝:
我们可以使用 Copy 任务来拷贝文件,通过它可以过滤指定拷贝内容,还能对文件进行重命名操作等,Copy 任务必须指定一组需要拷贝的文件和拷贝到的目录,这里使用CopySpec.from(java.lang.Object[])方法指定原文件,使用CopySpec.into(java.lang.Object)方法指定目标目录,示例代码如下
task copyTask(type: Copy) {
println 1
from 'src/main/resources'
into 'build/config'
}
println 2
在拷贝文件的时候还可以添加过虑条件来指定包含或排除的文件,示例如下:
task copyTaskWithPatterns(type: Copy)
{
from 'src/main/webapp'
into 'build/explodedWar' include '**/*.html' include '**/*.jsp'
exclude {
details -> details.file.name.endsWith('.html')
}
}
这是任务,需要执行的,而不是刷新,而启动项目其实并不会执行任务,只是需要指定顺序而已(也就是操作指定的任务流程),所以在前面说,执行阶段中存在启动项目也并不是不可以
在拷贝文件的时候还可以对文件进行重命名操作,示例如下:
task rename(type: Copy) {
from 'src/main/webapp'
into 'build/explodedWar'
rename { String fileName -> fileName.replace('a', '123')
}
}
在拷贝过程中,将a字符变成123,所以如果你的名称是ab,那么到目标时,就是123b
前面操作的都是使用Copy任务(不是自定义,是自带的),其实可以不操作任务,在配置阶段进行处理,那就是Project.copy(org.gradle.api.Action)方法:
task copyMethod {
doLast {
copy {
from 'src/main/webapp'
into 'build/explodedWar'
include '**/*.html'
include '**/*.jsp'
}
}
}
上面是操作任务,我们继续看不操作任务的:
copy {
from file('src/main/resources/ddd.txt')
into this.buildDir.absolutePath
}
当然,刷新本质上也是一个编译,所以如果刷新不了(或者看不到日志),那么在前面加上如下:
plugins {
id 'java'
}
然后点击右边的build即可(也就是gradle build),build一般是可以完成刷新的(虽然右键执行刷新(其实相当于手动的刷新)也会),并顺便编译代码,以及出现一些打印日志,当然,也可以执行项目(因为是操作顺序的任务的,存在build)
归档文件:
通常一个项目会有很多的 Jar 包,我们希望把项目打包成一个 WAR,ZIP 或 TAR 包进行发布,这时我们就可以使用Zip,Tar,Jar,War 和Ear 任务来实现,不过它们的用法都一样,所以在这里我只介绍Zip 任务的示例,首先,创建一个 Zip 压缩文件,并指定压缩文件名称,如下代码所示:
apply plugin: 'java'
version = 1.0
task myZip(type: Zip) {
from 'src/main'
into 'build'
baseName = 'myGame'
}
println myZip.archiveName
我们可以使用 Project.zipTree(java.lang.Object)和 Project.tarTree(java.lang.Object)方法来创建访问 Zip 压缩包的文件树对象,示例代码如下:
FileTree zip = zipTree('someFile.zip')
FileTree tar = tarTree('someFile.tar')
对文件的操作,可以参考这里:
https://docs.gradle.org/current/userguide/working_with_files.html
比如我们创建一个zip,进行处理:
FileTree zip = zipTree('a.zip')
zip.each { println it }
Dependencies(操作闭包,其实他们底层都可以追溯到java代码的):
依赖的方式:
Gradle 中的依赖分别为直接依赖,项目依赖,本地jar 依赖,案例如下:
dependencies {
implementation project(':subject01')
implementation files('libs/foo.jar', 'libs/bar.jar')
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation 'org.apache.logging.log4j:log4j:2.17.2'
}
一般我们使用的是直接依赖,那么直接依赖我们怎么知道呢,我们看这个网站:
https://central.sonatype.com/?smo=true,在搜索框中输入log4j,随便选择一个,然后选择gradle的,就可以看到关于这个的直接依赖了,我们复制粘贴即可,当然,我们也可以访问这个网站:https://mvnrepository.com/,也是类似的处理,进去就会知道的
当然,上面的直接依赖其实只是一个简写,全名是这样的写法:
implementation group: 'org.apache.logging.log4j', name: 'log4j', version: '2.17.2'
当然,若要刷新成功,一般需要仓库地址(也需要java,因为需要用他里面的东西来操作,他们少一个,就会报错):
plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
implementation group: 'org.apache.logging.log4j', name: 'log4j', version: '2.17.2'
}
所以也的确是与maven中,对应的依赖是非常像的,比如:
<dependencies>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
<scope>compilescope>
dependency>
dependencies>
项目依赖:从项目的某个模块依赖另一个模块
implementation project(‘:subject01’)
这种依赖方式是直接依赖本工程中的libary module,这个 libary module 需要在setting.gradle 中配置(也就是自身,他都没有,自然是不可能的,他虽然是项目的关系,但是是操作子的,当前的写不写也并没有问题)
依赖的下载:
当执行 build 命令时(本质上是操作了刷新),gradle 就会去配置的依赖仓库中下载对应的 Jar,并应用到项目中
依赖的类型:
类似于 Maven 的 scope 标签,gradle 也提供了依赖的类型,具体如下所示:


官方文档参考:
https://docs.gradle.org/current/userguide/java_library_plugin.html#java_library_plugin
https://docs.gradle.org/current/userguide/upgrading_version_6.html#sec:configuration_removal
一般可以找到如下的情况:各个依赖范围的关系和说明,依赖范围升级和移除,API 和implemention 区别,执行java 命令时都使用了哪些依赖范围的依赖
一般来说:java 插件提供的功能,java-library 插件都提供,并且要使用插件,一般是需要指定的,比如前面我们指定的:
plugins {
id 'java'
}
这样就会补充一些配置,或者任务,并且可以操作java项目,当然,gradle并不是依靠插件来处理,他自身有功能,只是插件是一个补充
而java-library要想操作,自然是需要将上面的id 'java’变成id ‘java-library’,当然,可以直接操作的插件,是gradle自带的
api 与implementation 区别:
他们都是确定对应的jar包或者其他包是否在编译和运行期有效的

api是java-library的操作,所以需要加上插件,也就是:
plugins {
id 'java'
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
api group: 'org.apache.logging.log4j', name: 'log4j', version: '2.17.2'
implementation group: 'org.apache.logging.log4j', name: 'log4j', version: '2.17.2'
}
还有一个图:
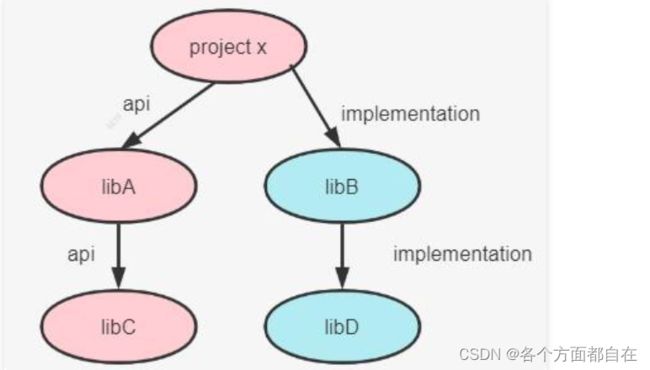
编译时:如果 libC 的内容发生变化,由于使用的是 api 依赖,依赖会传递,所以 libC、libA、projectX 都要发生变化,都需要重新编译,速度慢
运行时:libC、libA、projectX 中的class 都要被加载
编译时:如果libD 的内容发生变化,由于使用的是implemetation 依赖,依赖不会传递,只有libD、libB 要变化时,才会重新编译,速度快
运行时:libC、libA、projectX 中的class 都要被加载
当然,maven一般情况下,默认也是传递,一般这个默认与api几乎一样,只是在编译时的不同而已,虽然maven可能也会重新编译相关依赖,但是过程可能不同

api 的适用场景是多module 依赖,moduleA 工程依赖了 module B,同时module B 又需要依赖了 module C,modelA 工程也需要去依赖 module C,这个时候避免重复依赖module,可以使用 module B api 依赖的方式去依赖module C,modelA 工程只需要依赖 moduleB 即可,但是当其中一个改变,与之依赖的却需要重新编译,这是因为模块之间的jar包是需要给自身的,那么自然需要进行删除或者增加jar包(这里我们通常为jar包),在maven中基本也是如此,当然maven也存在其他情况,与gradle有相同的处理,如implemetation ,只是他们的默认处理可能不同而已,这里maven先了解即可,在以后具体学习maven时,会说明的
总之,除非涉及到多模块依赖,为了避免重复依赖,咱们会使用api,其它情况我们优先选择implementation,因为拥有大量的api 依赖项会显著增加构建时间,而maven默认如此,所以在效率方面gradle通常是优于maven的(虽然还存在很多原因)
依赖冲突及解决方案:
依赖冲突是指:在编译过程中,如果存在某个依赖的多个版本,构建系统应该选择哪个进行构建的问题,如下所示:

A、B、C 都是本地子项目 module,log4j 是远程依赖
编译时:B 用 1.4.2 版本的 log4j,C 用 2.2.4 版本的 log4j,B 和 C 之间没有冲突(当然,这些版本可能现在不存在了,这里只是例子,具体案例中,还是建议使用存在的版本)
打包时:只能有一个版本的代码最终打包进最终的A对应的jar |war包,对于 Gradle 来说这里就有冲突了(同样的,在maven中几乎也是如此)
首先为了进行演示,我们创建上面的三个gradle项目,其中名称分包是ProjectA,ProjectB,ProjectC,其中ProjectB和ProjectC是ProjectA的子项目
如图:
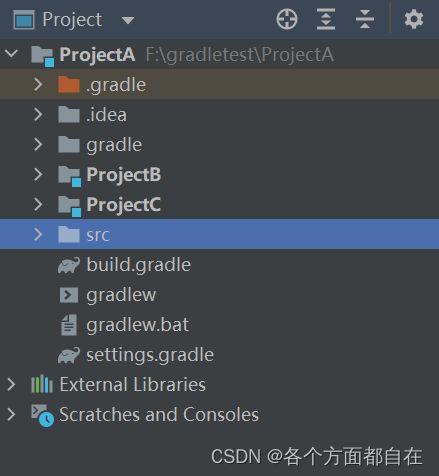
ProjectA的依赖:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation project(':ProjectB')
implementation project(':ProjectC')
}
test {
useJUnitPlatform()
}
ProjectB:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
api group: 'org.apache.logging.log4j', name: 'log4j', version: '2.17.2'
}
test {
useJUnitPlatform()
}
ProjectC:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
api group: 'org.apache.logging.log4j', name: 'log4j', version: '2.21.1'
}
test {
useJUnitPlatform()
}
我们刷新,在右边看看谁在使用(右边是预留的,是最终打包的前提):
我们可以发现,使用的是2.21.1,即高版本,也就是说默认情况下,Gradle 会使用最新版本的 jar 包(考虑到新版本的 jar 包一般都是向下兼容的)
当然,只是一般这样,为了更加的严谨,gradle,自然也提供了其他的处理:
比如排除依赖,不允许传递,以及强制使用某个依赖:
首先是排除依赖:
排除依赖一般只能排除对应的依赖里面的依赖,所以我们需要这样的处理,即单纯的操作ProjectA,对应的依赖如下:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'org.hibernate:hibernate-core:3.6.3.Final'
implementation 'org.slf4j:slf4j-api:1.4.0'
}
test {
useJUnitPlatform()
}
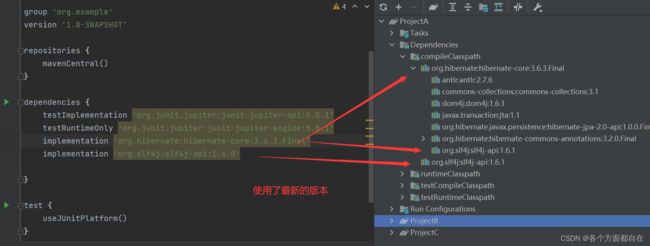
上面的最新是对当前项目来说,而不是真的最新
然后我们修改对应的依赖:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation('org.hibernate:hibernate-core:3.6.3.Final') {
exclude group: 'org.slf4j'
}
implementation 'org.slf4j:slf4j-api:1.4.0'
}
test {
useJUnitPlatform()
}
这个时候,刷新一下看看,是不是只有对应的1.4.0版本了吧
不允许依赖传递:
继续修改对的依赖:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation('org.hibernate:hibernate-core:3.6.3.Final') {
transitive(false)
}
implementation 'org.slf4j:slf4j-api:1.4.0'
}
test {
useJUnitPlatform()
}
强制使用一个依赖:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'org.hibernate:hibernate-core:3.6.3.Final'
implementation 'org.slf4j:slf4j-api:1.4.0!!'
}
test {
useJUnitPlatform()
}
这样就还是1.4.0,但是这个强制是强制使用他这个整体,但是我们其实还可以保留整体,而指定强制的一个版本:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'org.hibernate:hibernate-core:3.6.3.Final'
implementation('org.slf4j:slf4j-api:1.4.0!!') {
version {
strictly("1.6.0")
}
}
}
test {
useJUnitPlatform()
}
当这个处理与!!一起操作时(!!与他同级,而不是作为他的参数),那么会报错的
我们也可以先查看当前项目中到底有哪些依赖冲突:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'org.hibernate:hibernate-core:3.6.3.Final'
implementation 'org.slf4j:slf4j-api:1.4.0'
configurations.all() {
Configuration configuration ->
configuration.resolutionStrategy.failOnVersionConflict()
}
}
test {
useJUnitPlatform()
}
我们其实还可以这样:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'org.hibernate:hibernate-core:3.6.3.Final'
implementation 'org.slf4j:slf4j-api:+'
}
test {
useJUnitPlatform()
}
拿取mavenCentral()对应的最新的版本(当然,这里只有这个,如果有很多,那么遍历所有的仓库,选择其中最新的版本,如果多个仓库的最新是相同的,那么谁在前面,拿取谁的),当然,gradle与maven不同的是,对应相同的都会变成这个最新,而不是忽略,当然,也可以这样:
implementation 'org.slf4j:slf4j-api:latest.integration'
这个与上面的+基本是一样的效果,但是我们还是不建议这样,因为他们的版本会发生改变,而改变的版本对项目来说是不友好的,可能会导致执行不了(比如:这个版本可能移除了某个方法,但是你的代码中是使用这个方法的,这个时候,就会报错,即执行不了了,并且可能其他的依赖需要对应的版本(本质上也是被新版本改变了一些东西,如移除),同样的也会报错,即执行不了)
Gradle 插件:
使用插件的原因:
简单的说,通过应用插件我们可以:
1:促进代码重用、减少功能类似代码编写、提升工作效率
2:促进项目更高程度的模块化、自动化、便捷化
3:可插拔式的的扩展项目的功能
我们其实可以发现,插件类似于临时定义的操作(虽然在gradle中可以看成是一个方法,但是在maven其实也是如此),他们基本都是在中途进行处理的,具体如何补充,我们看后面吧
插件的作用:
在项目构建过程中做很多事情,把插件应用到项目中,通常可以完成:
1:可以添加任务(task)到项目中,从而帮助完成测试、编译、打包等
2:可以添加依赖配置到项目中
3:可以向项目中拓展新的扩展属性、方法等
4:可以对项目进行一些约定,如应用 Java 插件后,约定src/main/java 目录是我们的源代码存在位置,编译时编译这个目录下的Java 源代码文件(就如操作war时,对应的文件也会变样子,使得可以操作web项目)
在gradle中要操作web工程,需要这样的操作:
plugins {
id 'java'
id 'war'
}
插件的分类和使用:
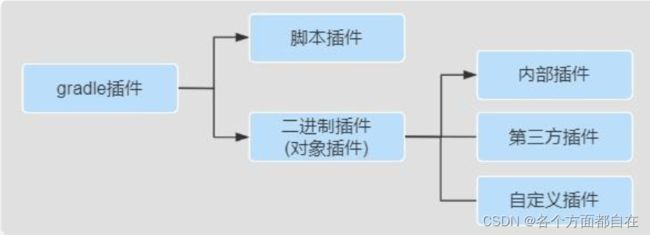
第一种:脚本插件
脚本插件的本质就是一个脚本文件,使用脚本插件时通过"apply from:"将脚本加载进来就可以了,后面的脚本文件可以是本地的,也可以是网络上的脚本文件,下面定义一段脚本,我们在 build.gradle 文件中使用它,具体名称我们定义为version.gradle(就放在ProjectA的gradle项目里面,与build.gradle文件同级别),内容如下:
ext {
company = "shangguigu"
cfgs = [
compileSdkVersion: JavaVersion.VERSION_1_8
]
spring = [
version: '5.0.0'
]
}
现在将在构建文件build.gradle中使用这个脚本文件,具体如下:
plugins {
id 'java'
id 'java-library'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'org.hibernate:hibernate-core:3.6.3.Final'
implementation 'org.slf4j:slf4j-api:+'
}
test {
useJUnitPlatform()
}
apply from: 'version.gradle'
task taskVersion {
doLast {
println "公司名称为:${company},JDK版本是${cfgs.compileSdkVersion},版本号是${spring.version}"
}
}
执行gradle taskVersion,我的打印是:公司名称为:shangguigu,JDK版本是1.8,版本号是5.0.0
这些是之前定义的文件的结果
意义:脚本文件模块化的基础,可按功能把我们的脚本进行拆分一个个公用、职责分明的文件,然后在主脚本文件引用, 比如:将很多共有的库版本号一起管理、应用构建版本一起管理等
第二种:对象插件
二进制插件(对象插件)就是实现了 org.gradle.api.Plugin 接口的插件
每个 Java Gradle 插件都有一个 plugin id(参照前面的id ‘java’)
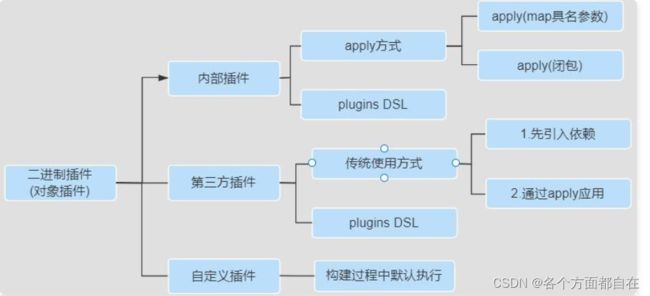
内部插件(核心插件):
如果子项目存在对应的插件,父项目会获得该插件,所以我们从ProjectC项目开始操作,首先先操作如下:
可通过如下方式使用一个 Java 插件(plugins DSL方式):
plugins {
id 'java'
}
去掉他,然后操作如下(apply方式):
map具名参数:
apply plugin : 'java'
闭包:
apply{
plugin 'java'
}
测试案例(上面的这也是groovy的处理,后面还有两种是map具名参数):
def f(int a,int b){
println(a)
println(b)
}
f(1,2)
f 1,3;
通过上述代码就将 Java 插件应用到我们的项目中了,对于 Gradle 自带的核心插件都有唯一的 plugin id,其中 java 是Java 插件的 plugin id,这个 plugin id 必须是唯一的,也可使用应用包名来保证 plugin id 的唯一性,这里的 java 对应的具体类型是 org.gradle.api.plugins.JavaPlugin,所以可以使用如下方式使用 Java 插件:
apply plugin: org.gradle.api.plugins.JavaPlugin
apply plugin:JavaPlugin
上面分别是全类名(全限定名),或者简类名(全限定名的类名)
可参考:https://docs.gradle.org/current/userguide/plugin_reference.html
第三方插件:
如果是使用第三方发布的二进制插件,一般需要配置对应的仓库和类路径
使用传统的应用方式(也放在ProjectC中):
使用先引入依赖方式来操作插件的处理:
当然,一般这个方式需要写在最前面,包括如下的前面:
plugins {
id 'java'
}
buildscript {
ext {
springBootVersion = "2.3.3.RELEASE"
}
repositories {
mavenLocal()
maven { name "Alibaba"; url 'https://maven.aliyun.com/repository/public' }
maven { name "Bstek"; url 'https://nexus.bsdn.org/content/groups/public/' }
maven { name "M2"; url 'https://plugins.gradle.org/m2/' }
jcenter()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}")
}
}
apply plugin: 'org.springframework.boot'
是否眼熟,我们回到之前配置的init.gradle:
allprojects {
repositories {
mavenLocal()
maven { name "Alibaba" ; url "https://maven.aliyun.com/repository/public" }
maven { name "Bstek" ; url "https://nexus.bsdn.org/content/groups/public/" }
mavenCentral()
}
buildscript {
repositories {
maven { name "Alibaba" ; url 'https://maven.aliyun.com/repository/public' }
maven { name "Bstek" ; url 'https://nexus.bsdn.org/content/groups/public/' }
maven { name "M2" ; url 'https://plugins.gradle.org/m2/' }
}
}
}
其中buildscript的repositories是一样的处理
但是如果是第三方插件已经被托管在 https://plugins.gradle.org/ 网站上,就可以不用在 buildscript 里配置 classpath
依赖了,直接使用新出的 plugins DSL 的方式引用,案例如下:
使 用 plugins DSL方式来操作插件的处理(这个位置,在前面说明了,也就是id 'java’的时候,他们是一样的处理(只是位置,而这里多一个版本,其实是从远程下载的,默认从https://plugins.gradle.org/中下载,当然,他也可能会从中央或者某些默认配置的地方进行下载,这主要看版本,具体可以百度,如果没有(对依赖来说,没有的话,自然报错,插件而不例外,当然,报错本质上只是一个提示而已,否则就是bug)),位置自然需要在前面,虽然没有上面的哪个前面):
plugins {
id 'org.springframework.boot' version '2.4.1'
}
插件和依赖是一样的会放在对应的仓库中(本质都是jar包,只是操作不同),当然,maven也存在插件,也是如此存放的
注意:
1:如果使用老式插件方式buildscript{}要放在build.gradle 文件的最前面,而新式plugins{}没有该限制(但是也基本要前面)
2:托管在网站gradle 插件官网的第三方插件有两种使用方式,一是传统的buildscript 方式(也就是先引入依赖),一种是 plugins DSL 方式
自定义插件(也放在ProjectC中):
interface GreetingPluginExtension {
Property<String> getMessage()
Property<String> getGreeter()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
def extension = project.extensions.create('greeting', GreetingPluginExtension)
project.task('hello') {
doLast {
println "${extension.message.get()} from ${extension.greeter.get()}"
}
}
}
}
apply plugin: GreetingPlugin
greeting {
message = 'Hi'
greeter = 'Gradle'
}
参考地址:https://docs.gradle.org/current/userguide/custom_plugins.html
我们直接执行 hello 任务,gradle hello 即可,这种方式实现的插件我们一般不使用,因为这种方式局限性太强,只能本Project,而其他的Project 不能使用
对应的打印:
Hi from Gradle
buildSrc 项目:
buildSrc 是Gradle 默认的插件目录,编译 Gradle 的时候会自动识别这个目录,将其中的代码编译为插件
1:首先先建立一个名为 buildSrc 的 java Module,将 buildSrc 从 included modules 移除,重新构建,然后只保留 build.gradle
和src/main 目录,其他全部删掉,注意名字一定是 buildSrc,不然会找不到插件
如图,在这之前,我们可以将ProjectA和ProjectB和ProjectC的build.gradle都设置成这样:
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
他是一个保留名称,通常设置的java插件,并不会让他生成src文件,所以我们需要给他创建这些文件
当然,我们也通常需要创建src\main\groovy,你也创建吧
并且也要注意:名字一定要是buildSrc,不然会找不到插件
2:然后修改Gradle 中的内容,也就是给他的build.gradle中加上如下:
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
apply plugin: 'groovy'
apply plugin: 'maven-publish'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
repositories {
google()
jcenter()
mavenCentral()
}
sourceSets {
main {
groovy {
srcDir 'src/main/groovy'
}
}
}
在groovy目录下创建com/Text文件(groovy的class):
package com
import org.gradle.api.Plugin
import org.gradle.api.Project
class Text implements Plugin<Project> {
@Override
void apply(Project project) {
project.task("atguigu") {
doLast {
println("自定义atguigu插件")
}
}
}
}
然后,在main/resources 目录下创建 META-INF 目录,在 META-INF 目录下创建gradle-plugins 目录,在gradle-plugins 目录下创建at.properties 文件(注意:这个at是插件id)
最后需要在该properties 文件中指明我们实现插件的全类名 implementation-class=com.Text
implementation-class=com.Text
到目前为止我们的插件项目已经写完了,很明显,我们通过一个文件来指向插件,而这个文件名称(除了properties)就是我们的插件id,那么在 ProjectA的module 引入我们写的插件 apply plugin:‘at’,然后执行插件的Task,也就是gradle atguigu
输出:自定义atguigu插件
当然,虽然我们前面基本都是操作任务的逻辑,其实,也可以操作其他逻辑,前面也有一些可能是操作对应里面的,只是我们都操作了任务而已,注意即可,就比如这里的apply方法中就可以不操作任务
这种形式的写法,在我们整个工程的module 都可以使用,但也只是限制在本工程(或者与该工程相关的子工程),其他工程不能使用(也包括他自己),或者说,他在哪个工程里面,那么他就是操作哪个工程的
上面的他只能在本工程中使用,而其他的项目工程不能使用,有时候我们需要一个插件在多个工程中使用, 这时候我们就需要把插件上传maven 中(类似于自己的第三方插件的说明,只是这个第三方是自己了,而不是第三方了)
第一步:首先将上述buildSrc 目录复制一份,修改文件夹名,可以设为buildSrcText,然后在settings.gradle 文件中使用include 引入(在ProjectA中的settings.gradle中加上include ‘buildSrcText’)
buildSrc是保留的名称,默认是该项目下面,所以你删除include的引入也没有什么作用,所以也规定必须删除了,当然,这会随着版本而改变,到那时百度即可
第二步:修改buildSrcText的build.gradle 文件,发布到maven 仓库中
具体内容如下:
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
apply plugin: 'groovy'
apply plugin: 'maven-publish'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
repositories {
google()
jcenter()
mavenCentral()
}
sourceSets {
main {
groovy {
srcDir 'src/main/groovy'
}
}
}
publishing {
publications {
myLibrary(MavenPublication) {
groupId = 'com.atguigu.plugin'
artifactId = 'library'
version = '1.1'
from components.java
}
}
repositories {
maven { url "$rootDir/lib/release" }
}
}
上面是想发布到当前根目录,也就是当前根项目(这里自然就是ProjectA)的lib的release目录下,如果没有这些目录,那么都会创建
第三步:执行publish 指令,发布到根 project 或者maven 私服仓库
这个命令,由apply plugin: 'maven-publish’提供,并且publishing {的操作也需要他(否则报错),在右边的这里:

我们进行执行他,那么就会出现这个了:

这些信息(如目录)都与我们的配置相关,当然,如果相关配置在项目中,会默认将buildSrc进行发布的,这也是为什么需要复制出来的原因,这是为了将复制出来的buildSrcText作为自身来处理,而不是父项目来处理
第四步:使用插件,在项目级 build.gradle 文件中将插件进行添加
比如我们在ProjectA中的该文件中添加如下:
buildscript {
repositories {
maven { url "$rootDir/lib/release" }
}
dependencies {
classpath "com.atguigu.plugin:library:1.1"
}
}
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
apply plugin: 'at'
执行gradle atguigu,打印:自定义atguigu插件
说明我们将这个插件下载好了,那么远程的呢,其实也不难,其中仓库地址基本都是一个规范,我们将具体的代码给目标地址即可,这里是maven,那么你可以到maven官网注册,然后添加你的仓库,和用户名和密码,即可,这里我们也可以进行测试:
修改buildSrcText的build.gradle文件:
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
apply plugin: 'groovy'
apply plugin: 'maven-publish'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
repositories {
google()
jcenter()
mavenCentral()
}
sourceSets {
main {
groovy {
srcDir 'src/main/groovy'
}
}
}
publishing {
publications {
myLibrary(MavenPublication) {
groupId = 'com.atguigu.plugin'
artifactId = 'library'
version = '1.1'
from components.java
}
}
repositories {
maven {
url = layout.buildDirectory.dir("repo")
println 1111
println url
}
}
}
继续前面的步骤,我们修改ProjectA的这个地方即可:
repositories {
maven { url "F:\\gradletest\\ProjectA\\buildSrcText\\build\\repo" }
}
最后看看gradle atguigu是否打印,打印了说明没有问题(记得刷新哦)
我们操作maven远程,写上你的仓库路径,给出你的用户名和密码,继续这样的处理(对应的上面的仓库地址url与对应的url是一样的),一般这样基本都会成功,首先进入一个maven仓库,其实,你可以购买一个服务器,定义也行,只需要可以拿取对应的文件夹里面的信息都可以作为仓库,这里自行测试吧
总结:
脚本插件:定义一个文件,在build.gradle引入并使用其内容(需要确定路径),路径确定,每个工程包括里面的项目都可以这样获取并使用
对象插件:
1:内部插件:自身存在的插件,有多种方式直接的引入,每个工程包括里面的项目都可以这样获取并使用
2:第三方插件:远程拿取插件,每个工程包括里面的项目都可以这样获取并使用
3:自定义插件:自己定义,只能本项目使用(注意是本项目,甚至还没有到工程)
buildSrc项目的插件:定义一个该工程和该工程里项目的公共插件(需要确定该项目是该工程的,也就是需要对应的工程配置,否则相当于不是该工程的,自然不能使用)
buildSrc项目的插件自己的插件:同第三方插件的说明(虽然他可能还包括自身仓库,但是第三方插件其实也包括)
插件的关注点(这在其他构建工具中,基本也都适用,包括maven):
第一点:插件的引用
apply plugin:‘插件名’
第二点:主要的功能(任务)
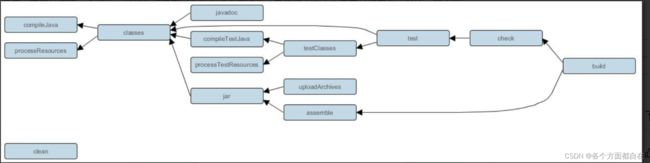
当我们在工程中引入插件后,插件会自动的为我们的工程添加一些额外的任务来完成相应的功能,以Java 插件为例,当我们加入java 插件之后,就加入了很多功能,比如在右边就存在build等待,具体可以自行测试看看(这些是任务组,在前面我们操作插件时,是的确可以使用插件来完成自定义的处理的,简单来说插件只是一个已经在已有基础上定义好的东西,同样的idea中idea的插件的操作也基本类似,基本是java来处理的,那么中间的插件也是在其基础上的定义(所以大多数需要我们手动操作),当然,可能也会操作自动化(如热部署),所以功能多的语言中(如java),出现自动化的处理就越多,而这里的处理可能也会有,反正插件的上限由其语言决定,这种说明可以对所有插件进行统一说明的)
具体可通过gradle tasks查看一些任务或者插件的区别(可能可以看到,或者可能有这个功能)
说明:Gradle 中的任务依赖关系是很重要的,它们之间的依赖关系就形成了构建的基本流程
第三点:工程目录结构
一些插件对工程目结构有约定,所以我们一般遵循它的约定结构来创建工程,这也是 Gradle 的"约定优于配置"原则(是否眼熟与springboot,虽然我们基本都需要这样,包括maven,即约定这样,但并非一定这样,只是我们建议遵循约定,当我们都这样遵循,自然不会考虑其他兼容的问题,那么对整个项目来说(之所以说整个项目,是考虑部分代码处理可能优于当前的约定),也就会提高效率和审查代码的效率),例如java 插件规定的项目源集目录结构
如果要使用某个插件就应该按照它约定的目录结构设置,这样能大大提高我们的效率,当然各目录结构也可以自己定义
第四点:依赖管理
比如前面我们提到的依赖的类型(依赖管理)部分,不同的插件提供了不同的依赖管理
第五点:常用的属性
例如:Java 插件会为工程添加一些常用的属性,我们可以直接在编译脚本中直接使用,具体可以百度看看gradle的常用属性
Java 插件分析:
可以参考:https://docs.gradle.org/current/userguide/plugin_reference.html
第一点:我们要关注插件使用
plugins {
id 'java'
}
第二点:我们要关注插件的功能
最好查看官方文档,这是最权威的
第三点:项目布局
一般加入一个插件之后,插件也会提供相应的目录结构,例如:java 插件的目录结构
这个目录一般是如下:

当然这个默认的目录结构也是可以改动的例如:
在ProjectA中build.gradle加上如下:
plugins {
id 'java'
}
sourceSets {
main {
java {
srcDirs = ['src/ts/java']
}
resources {
srcDirs = ['src/ts/resources']
}
}
}
如图:

既然可以更改默认目录,其实生成的字节码也可以,具体可以去百度,这里就不多说了,但还是可以一些案例:
如:
test {
java {
srcDirs = ['src/ts/test/java']
}
resources {
srcDirs = ['src/ts/test/resources']
}
}
操作测试的,当然,我们也可以操作生成的,首先,无论你的main和test放在那里,生成的字节码都在build里面的classes/java/main里面,而资源文件则在build中的resources的main里面,因为是默认的,如果可以,那么可以这样(可以在https://docs.gradle.org/current/userguide/plugin_reference.html(前面的参考)里面找到java,点击进去,然后点击右边的Source sets,然后点击"output-(read-only)SourceSetOutput"可以找到这样的代码):
plugins {
id 'java'
}
sourceSets {
main {
output.resourcesDir = file('out/bin')
java.destinationDirectory.set(file('out/bin'))
}
}
我们使用他:
main {
java {
srcDirs = ['src/ts/main/java']
}
resources {
srcDirs = ['src/ts/main/resources']
}
output.resourcesDir = file('out/bin')
java.destinationDirectory.set(file('out/bin'))
}
这样,无论是字节码还是配置我呢见都会放在当前与build相同目录下的out/bin中,解释:
output.resourcesDir = file('out/bin')
java.destinationDirectory.set(file('out/bin'))
第四点:依赖管理:以java 插件为例,提供了很多依赖管理项,源集依赖关系配置
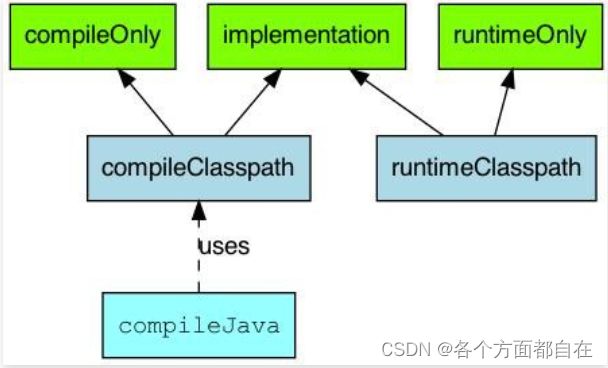
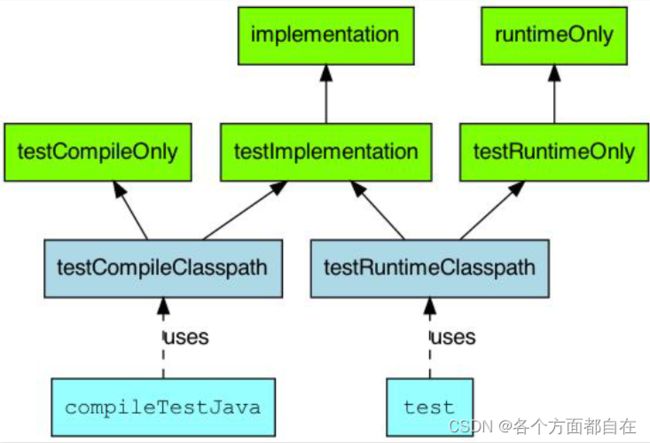
第五点:有其独特的属性和方法,比如:
plugins {
id 'java'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
}
}
build.gradle 文件:
其实插件我们通常使用的少,大多数情况下,我们只需要知道引入依赖和初始配置就行了,插件的编写是需要非常熟悉后才会涉及
build.gradle 是一个gradle 的构建脚本文件,支持java、groovy 等语言
每个project 都会有一个build.gradle 文件,该文件是项目构建的入口(对maven来说,xml则是入口,只不过他默认操作了一些处理,如类似的java插件的操作),可配置版本、插件、依赖库等信息
每个build 文件都有一个对应的 Project 实例(你在build.gradle里面操作下面的东西时,可以ctrl+左键进去就可以看到类了,比如进入repositories,可以看到Project 类),对build.gradle 文件配置,本质就是设置Project 实例的属性和方法
由于每个 project 都会有一个build 文件,那么Root Project 也不列外,Root Project 可以获取到所有 Child Project,所以在Root Project 的 build 文件中我们可以对Child Project 统一配置,比如应用的插件、依赖的maven 中心仓库等

所以说,其实插件配置,都是为了底层中的某个代码的处理而操作的,只是隐藏了这一个过程,用某些,如gradle或者xml来定义配置
常见属性代码(后面的可以在ProjectA中进行处理):
plugins {
id 'java'
}
sourceCompatibility = 1.8
targetCompatibility = 1.8
compileJava.options.encoding "UTF-8"
compileTestJava.options.encoding "UTF-8"
tasks.withType(JavaCompile) {
options.encoding = "UTF-8"
}
tasks.withType(Javadoc) {
options.encoding = "UTF-8"
}
group+name+version 类似于 maven 的group+artifactId+version
encoding(options.encoding = "UTF-8"的encoding )解决业务代码与测试代码中文乱码问题
Repositories:
plugins {
id 'java'
}
repositories {
maven { url 'file:///D:/repos/mavenrepos3.5.4' }
maven { url "$rootDir/lib/release" }
mavenLocal()
maven { name "Alibaba"; url "https://maven.aliyun.com/repository/public" }
maven { name "Bstek"; url "https://nexus.bsdn.org/content/groups/public/" }
mavenCentral()
google()
}
因为 Gradle 没有自己的远程仓库,而是使用 Maven、jcenter、jvy、google 这些远程仓库(当然,这些仓库通常是根据maven的坐标,但是gradle拿取会映射artifactId到name的,所以并不需要担心,虽然在对应的gradle中,我们并不能设置该name,但是在settings.gradle中的name就是这个name,在这里设置,当然,gradle不能设置,本质上还是底层代码的原因,因为gradle认为name默认为当前项目的即可,所以name的设置就不给出(在代码上,就不给出set方法了)),当然,我们其实也可以发现build.gradle+settings.gradle的结合,就是项目配置和代码坐标信息的结合,类似于maven将项目信息和坐标信息分开一样,或者部分分开,当然,他们都有各自的特点,具体为什么还是需要看底层是如何处理,为什么这样处理,那么可以百度查看原因,一般是为了更好的划分模块,也就是配置更加的进行分离
当然,父子关系的处理与maven是一样的,父编译,子也编译,父清除,子也清除,都与对应的项目信息有关,而gradle则是与settings.gradle有关,但是上面的说明只是依赖(是相对来说的父(api共享谁引入谁是子),而不是配置的父子关系),通常情况下,在项目的打包和编译和清除的过程中,gradle需要手动的在各个项目中进行处理,所以gradle的父子关系(一般没有像上面明显的说,基本都是配置的父子关系的说明)更多的是依赖之间的关系,而maven是依赖以及项目的都有,并且默认依赖父项目的所有,而不是gradle的手动依赖(但是可以父依赖子,这也是maven的不同,也就是说gradle灵活,只是比较麻烦,或者说复杂)
我们可以以这样的说明,对gradle与maven的区别进一步进行区分:
执行效果:
gradle在配置好对应的基础环境后,使用这些环境自带的代码可以完成项目的编译打包处理,其中我们可以在对应的配置中加上一些关于依赖的操作,也就是build.gradle,他处理依赖的处理,也存在代码层面的直接处理,两个作用
而maven同理,对应的xml只有坐标的作用,所以maven简单,gradle复杂,但是gradle就快了(除了更加偏向底层外,也有很多原因,如灵活,我可以使用groovy更加的表达好的意思,编译语言的变化,对性能并不大,由于灵活存在,所以在其他方面容易对maven差的部分进行更好的处理,最终使得gradle中有其优势),当然,maven并不会停留,现在基本也会对maven补充gradle的优势,那么具体看他们最后的处理了吧
当然,最终都会导向一个:也就是maven简单(配置简单),而groovy灵活(存在代码处理,所以灵活,而不是单纯的依赖固定的配置),其他的都会随着时间来平衡,更加的区别就是,groovy以语言转换来完成,而maven则不是,所以有这两个主要区别
当然,gradle的灵活是非常多变的,这通常需要经历某些需求,才会更加的明白这方面的处理,所以单纯的用话语来说明,并不是非常好的,到以后使用时自然就会明白(比如:可以通过代码给所有项目设置相同的依赖等等,如allprojects)
Subprojects 与 Allprojects:
allprojects 是对所有project(包括Root Project+ child Project(当前工程和所有子工程))的进行统一配置,而subprojects是对所有Child Project 的进行统一配置(看名称也可以知道是这样)
plugins {
id 'java'
}
allprojects {
apply plugin: 'java'
tasks.create('hello') {
doLast {
task ->
println "project name is $task.project.name"
}
}
}
subprojects {
hello.doLast { task ->
println "here is subprojects $task.project.name"
}
}
在父项目中打印,如ProjectA中操作gradle hello等,打印如下:
通常父项目在执行一个任务时,会默认执行其子项目中与父项目执行的任务的相同名称的任务,所以如果子项目中存在一个名称,而父项目中没有,父项目中也可以操作"gradle 对应的任务名称"而不会报错
通常在 subprojects 和allprojects 中:
plugins {
id 'java'
}
allprojects {
apply plugin: 'java'
ext {
junitVersion = '4.10'
}
task allTask {
}
repositories {
}
dependencies {
}
}
subprojects {
}
插件只是简化构建以及补充一起处理的操作(虽然gradle的插件是写在gradle,maven则隐藏点)
如果是直接在根project 配置,repositories 和 dependencies 则只针对根工程有效,但是这也是会随着版本而改变的,通常都会有(父子项目都有对应的设置的依赖),所以请具体测试一下
拓展:我们也可以在对单个 Project 进行单独配置(这种一般只能在根项目或者父中处理,其实也就是父子的父,根项目是顶层父,当然了,可能以后只能在顶层父中进行处理,具体需要看当时的版本是否说明了)
plugins {
id 'java'
}
project('ProjectC') {
task ProjectC {
doLast {
println 'for ProjectC'
}
}
}
在子项目(是对应的子项目,否则报错)中或者父项目中操作gradle ProjectC吧
当然,因为gradle底层处理点,所以存在代码的一些处理,而不是单纯的配置(maven),所以存在这些代码操作
ext 用户自定义属性(如定义版本(前面操作过)):
Project 和 Task 都允许用户添加额外的自定义属性,要添加额外的属性,通过应用所属对象的ext 属性即可实现,添加之后可以通过 ext 属性对自定义属性读取和设置,如果要同时添加多个自定义属性,可以通过 ext 代码块:
plugins {
id 'java'
}
ext.age = 18
ext {
phone = 19292883833
address = "北京尚硅谷"
}
task extCustomProperty {
ext {
desc = "奥利给"
}
doLast {
println "年龄是:${age}"
println "电话是:${phone}"
println "地址是:${address}"
println "haha:${desc}"
}
}
执行gradle extCustomProperty看看吧
ext 配置的是用户自定义属性,而gradle.properties 中(前面说明的性能选项有提到)一般定义,系统属性、环境变量、项目属性、JVM 相关配置信息,例如我们在ProjectA项目中创建gradle.properties文件(自然与build.gradle同级别):
#加快构建速度的,gradle.properties 文件中的属性会自动在项目运行时加载
#设置此参数的原因,是考虑编译下载包会占用大量的内存,可能会内存溢出,而进行的调整(jvm内存溢出的情况)
org.gradle.jvmargs=-Xms4096m -Xmx8192m
# 开启gradle缓存
org.gradle.caching=true
#开启并行编译
org.gradle.parallel=true
#启用新的孵化模式
org.gradle.configureondemand=true
#开启守护进程
org.gradle.daemon=true
Buildscript:
buildscript 里是gradle 脚本执行所需依赖(一般底层都是操作单纯的repositories和dependencies,其他修饰只是补充,如这里的buildscript和allprojects,插件只是定义了一些属性,最后赋值,虽然他不是xml的定义),分别是对应的 maven 库和插件,案例如下:
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath group: 'commons-codec', name: 'commons-codec', version: '1.2'
}
}
plugins {
id 'java'
}
import org.apache.commons.codec.binary.Base64
tasks.register('encode') {
doLast {
def encodedString = new String(Base64.encodeBase64('hello world\n'.getBytes()))
println encodedString
}
}
一般他是引入的,只不过右边没有对应的组来显示而已,我的打印信息:aGVsbG8gd29ybGQK
需要注意的是:
1:buildscript{}必须在 build.gradle 文件的最前端
2:对于多项目构建,项目的 buildscript ()方法声明的依赖关系可用于其所有子项目的构建脚本(或者说classpath是传递的),其他的单纯的操作,通常需要配置是否传递的处理(虽然通常是子给父)
这里就需要考虑对应的情况了:
直接操作依赖给项目,那么就是项目的,如果操作了allprojects,那么相当于他都操作,这里的buildscript默认也是相当于都操作
构建脚本依赖可能是 Gradle 插件,案例如下所示:
apply plugin: 'java'
buildscript {
ext {
springBootVersion = "2.3.3.RELEASE"
}
repositories {
mavenLocal()
maven { name "Alibaba"; url 'https://maven.aliyun.com/repository/public' }
maven { name "Bstek"; url 'https://nexus.bsdn.org/content/groups/public/' }
maven { name "M2"; url 'https://plugins.gradle.org/m2/' }
jcenter()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}")
}
}
apply plugin: 'org.springframework.boot'
上面的案例或多或少都是在ProjectA中进行处理(除非有特别的说明,如也放在ProjectC中等等的说明)
publishing 项目发布:
这个在前面我们也处理过,这里深入说明一下:

引入maven 发布的插件(这里我们操作父项目的话(没有对应的properties文件是不会作为一个插件的,就会使用buildSrc项目作为发布插件,如果这个项目也没有处理插件,也通常不会报错(当然,这也需要看版本,可能也会报错),只是获取时获取不到,从而报错而已),那么就是处理buildSrc,这里我们可以试一下,都在ProjectA中处理):
plugins {
id 'java-library'
id 'maven-publish'
}
设置发布代码:
plugins {
id 'java-library'
id 'maven-publish'
}
javadoc.options.encoding = "UTF-8"
java {
withJavadocJar()
withSourcesJar()
}
publishing {
publications {
myLibrary(MavenPublication) {
groupId = 'org.gradle.sample'
version = '1.1'
from components.java
}
}
repositories {
mavenLocal()
maven {
name = 'myRepo'
println 1
println layout.buildDirectory
println version
url = layout.buildDirectory.dir("repo")
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = version.endsWith('SNAPSHOT') ? snapshotsRepoUrl : releasesRepoUrl
}
}
}
远程的给出对应的地址即可
执行发布指令在前面我们也处理过了,当然还有其他的指令(在右边并不是只有其一个publish指令),这些指令名称,通常都会与版本有关(当然,其他的指令也是如此,版本通常指gradle版本,因为其他的可以指定,所以说的版本问题,通常指固定的版本的问题,如gradle,这里也适用与其他相关类似的知识),所以这里给出来并不是非常准确,就不给出了,具体作用可以百度
如果url没有指定,通常会到中央仓库(也是越来越多的原因),一般这些任务并不会直接操作环境变量
测试:点击ProjectA的右边的publish指令执行,修改ProjectA的build.gradle:
buildscript {
repositories {
maven { url "F:\\gradletest\\ProjectA\\build\\repos\\releases" }
}
dependencies {
classpath "org.gradle.sample:ProjectA:1.1"
}
}
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
apply plugin: 'at'
这种情况下,由于配置由项目来处理了,所以buildSrc的build.gradle什么都不写也行,并且还要注意一点:要发布的项目,在发布后,通过与对应的jar包进行了关联,也就是说,子项目发布或者项目发布(buildSrc),当你修改其对应的哪个方法里面的内容,如apply方法里面的内容,如任务的atguigu的打印,那么对应的jar里面的相应代码也会发生改变,所以当你刷新后,继续处理对应的,如gradle atguigu,那么就会打印你修改的东西
生命周期中Hook:
生命周期中的这些钩子函数都是由 gradle 自动回调完成的,利用这些钩子函数可以帮助我们实现一些我们想要的功能,其实钩子的意思,就是预留在已经写好的底层代码中的中间处理,这在vue中也存在,在java中一些拦截的操作也存在,如spring,这些都可以称为钩子函数或者称为(也可以说类似)钩子函数
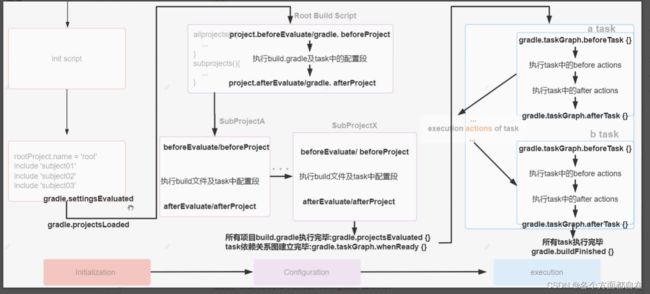
Gradle 在生命周期各个阶段都提供了用于回调的钩子函数:
Gradle 初始化阶段:
1:在 settings.gradle 执行完后,配置项目初始属性,会回调 Gradle 对象的 settingsEvaluated 方法
2:在构建所有工程 build.gradle 对应的Project 对象后(只是有实例),这个时候是识别生成的,也既初始化阶段完毕,会回调 Gradle 对象的projectsLoaded 方法
Gradle 配置阶段:
1:Gradle 会循环执行每个工程的 build.gradle 脚本文件,识别后,自然执行对应的代码
2:但在执行当前工程build.gradle 前,会回调Gradle 对象的 beforeProject 方法和当前Project 对象的 beforeEvaluate 方法,虽然 beforeEvalute 属于 project 的生命周期,但是此时 build script 尚未被加载,所以 beforeEvaluate 的设置依 然要在 init script 或 setting script 中进行,不要在 build script 中使用 project.beforeEvaluate 方法
3:在执行当前工程 build.gradle 后,会回调 Gradle 对象的afterProject 方法和当前Project 对象的 afterEvaluate 方法(可以在上一个阶段提取进行设置,即afterEvaluate ,他们会存在映射的或者复制(赋值 )的)
4:在所有工程的 build.gradle 执行完毕后,会回调 Gradle 对象的 projectsEvaluated 方法
5:在执行时,若已经构建 Task 依赖有向无环图后,也就是配置阶段这个时候基本完毕了(之前的完毕可以认为是代码完毕,构建没有,因为识别并不是代表执行,只是一种赋值,而由于这样,所以有时候配置节点会称为识别后的打印或者执行),会回调TaskExecutionGraph 对象的 whenReady 方法,但是build.gradle存在两个阶段,也就是配置阶段和执行阶段,配置阶段的代码已经操作完毕,这个时候开始操作执行阶段,配置阶段只是构建Task,而不是执行
Gradle 执行阶段:
1:Gradle 会循环执行Task 及其依赖的 Task
2:在当前 Task 执行之前,会回调 TaskExecutionGraph 对象的 beforeTask 方法
3:在当前 Task 执行之后,会回调 TaskExecutionGraph 对象的 afterTask 方法
4:当所有的 Task 执行完毕后,会回调 Gradle 对象的 buildFinish 方法
上面的对应的方法基本都是钩子,当然,这些钩子使用的并不多,在vue中,其实我们也使用的不多
提示:Gradle 执行脚本文件的时候会生成对应的实例,主要有如下几种对象:
1:Gradle 对象:在项目初始化时构建,全局单例存在,只有这一个对象
2:Project 对象:每一个build.gradle文件都会转换成一个 Project 对象,类似于maven中的pom.xml文件
3:Settings 对象:settings.gradle 会转变成一个 settings 对象,和整个项目是一对一的关系,一般只用到include方法
4:Task对象:从前面的有向无环图中,我们也可以看出,gradle最终是基于Task的(当然,这个基于是宏观上的,因为他是用来封装,我们只是使用他,否则我们还可以说是基于二进制的呢),一个项目可以有一个或者多个Task
钩子函数代码演示:
项目目录结构如下:
ProjectA,有两个子项目,ProjectB和ProjectC,他们三个的build.gradle都是:
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
在ProjectA的settings.gradle 文件中添加(要知道,他是gradle后缀):
rootProject.name = 'ProjectA'
include 'ProjectB'
include 'ProjectC'
gradle.settingsEvaluated {
println "settingsEvaluated"
}
gradle.projectsLoaded {
println "projectsLoaded"
}
def projectName = ""
gradle.addProjectEvaluationListener(new ProjectEvaluationListener() {
@Override
void beforeEvaluate(Project project) {
projectName = project.name
println "${project.name} Project beforeEvaluate"
}
@Override
void afterEvaluate(Project project, ProjectState projectState) {
println "${project.name} Project afterEvaluate"
}
});
gradle.beforeProject {
println "${projectName} beforeProject..."
}
gradle.afterProject {
println "${projectName} afterProject..."
}
def rootProjectName = rootProject.getName()
gradle.projectsEvaluated {
println "${rootProjectName} projectsEvaluated..."
}
gradle.taskGraph.whenReady {
println "${rootProjectName} taskGraph whenReady..."
}
gradle.taskGraph.beforeTask { task ->
println "this is the task ${task.name} of the project ${task.getProject().name} beforeTask.."
}
gradle.taskGraph.afterTask { task ->
println "this is the task ${task.name} of the project ${task.getProject().name} afterTask.."
}
gradle.buildFinished {
println "${rootProjectName} buildFinished..."
}
在ProjectA的build.gradle 文件中添加:
task A {
println "root taskA"
doFirst() {
println "root taskA doFirst"
}
doLast() {
println "root taskA doLast"
}
}
在ProjectB的build.gradle 文件中添加:
task B {
println "SubProject01 taskB"
doFirst(){
println "SubProject01 taskB doFirst"
}
doLast(){
println "SubProject01 taskB doLast"
}
}
在ProjectC的build.gradle 文件中添加:
task C {
dependsOn 'D'
println "SubProject02 taskC"
doFirst() {
println "SubProject02 taskC doFirst"
}
doLast() {
println "SubProject02 taskC doLast"
}
}
task D {
println "SubProject02 taskD"
doFirst() {
println "SubProject02 taskD doFirst"
}
doLast() {
println "SubProject02 taskD doLast"
}
}
测试:在ProjectA工程的根目录执行:gradle C,就能看到 gradle 生命周期的三个阶段,及每个阶段执行的钩子函数、还有在执行阶段有依赖关系的任务的执行顺序问题
打印如下:
PS F:\gradletest\ProjectA> gradle C
settingsEvaluated
projectsLoaded
> Configure project :
ProjectA Project beforeEvaluate
ProjectA beforeProject...
root taskA
ProjectA Project afterEvaluate
ProjectA afterProject...
> Configure project :ProjectB
ProjectB Project beforeEvaluate
ProjectB beforeProject...
SubProject01 taskB
ProjectB Project afterEvaluate
ProjectB afterProject...
> Configure project :ProjectC
ProjectC Project beforeEvaluate
ProjectC beforeProject...
SubProject02 taskC
SubProject02 taskD
ProjectC Project afterEvaluate
ProjectC afterProject...
ProjectA projectsEvaluated...
ProjectA taskGraph whenReady...
> Task :ProjectC:D
this is the task D of the project ProjectC beforeTask..
SubProject02 taskD doFirst
SubProject02 taskD doLast
this is the task D of the project ProjectC afterTask..
> Task :ProjectC:C
this is the task C of the project ProjectC beforeTask..
SubProject02 taskC doFirst
SubProject02 taskC doLast
this is the task C of the project ProjectC afterTask..
ProjectA buildFinished...
BUILD SUCCESSFUL in 1s
2 actionable tasks: 2 executed
PS F:\gradletest\ProjectA>
在settings.gradle 中添加监听器,查看task 有向无环图:
gradle.taskGraph.addTaskExecutionGraphListener(new TaskExecutionGraphListener() {
@Override
void graphPopulated(TaskExecutionGraph taskExecutionGraph) {
taskExecutionGraph.allTasks.forEach(task -> {
taskExecutionGraph.allTasks.forEach(releaseTask -> {
println "haha:" + releaseTask.getProject().name + ":" + releaseTask.name
})
})
}
})
在加上他之前,顺便也将在settings.gradle中的前面补充的代码注释掉,然后执行gradle C,打印如下:
PS F:\gradletest\ProjectA> gradle C
> Configure project :
root taskA
> Configure project :ProjectB
SubProject01 taskB
> Configure project :ProjectC
SubProject02 taskC
SubProject02 taskD
> Task :ProjectC:D
SubProject02 taskD doFirst
SubProject02 taskD doLast
> Task :ProjectC:C
SubProject02 taskC doFirst
SubProject02 taskC doLast
BUILD SUCCESSFUL in 1s
2 actionable tasks: 2 executed
PS F:\gradletest\ProjectA>
现在我们加上,然后执行gradle C,打印如下:
PS F:\gradletest\ProjectA> gradle C
> Configure project :
root taskA
> Configure project :ProjectB
SubProject01 taskB
> Configure project :ProjectC
SubProject02 taskC
SubProject02 taskD
haha:ProjectC:D
haha:ProjectC:C
haha:ProjectC:D
haha:ProjectC:C
> Task :ProjectC:D
SubProject02 taskD doFirst
SubProject02 taskD doLast
> Task :ProjectC:C
SubProject02 taskC doFirst
SubProject02 taskC doLast
BUILD SUCCESSFUL in 1s
2 actionable tasks: 2 executed
PS F:\gradletest\ProjectA>
计算 Gradle 构建过程中各个阶段的耗时:需要注意,这里只是计算了初始化阶段的 settings 文件,并没有计算init.gradle 初始化的时间,并且是利用钩子的,所以是非常准确的
我们还是在settings.gradle(一般只有在ProjectA也就是最根项目,或者说最父项目中存在)中加上:
def projectName = rootProject.getName()
long beginOfSetting = System.currentTimeMillis()
def beginOfConfig
def configHasBegin = false
def beginOfProjectConfig = new HashMap()
def beginOfTaskExecute
gradle.projectsLoaded {
println "${projectName}工程 初始化总耗时 " +
"${System.currentTimeMillis() - beginOfSetting} ms"
}
gradle.beforeProject { Project project ->
if (!configHasBegin) {
configHasBegin = true
beginOfConfig = System.currentTimeMillis()
}
beginOfProjectConfig.put(project, System.currentTimeMillis())
}
gradle.afterProject { Project project ->
def begin = beginOfProjectConfig.get(project)
if (project.name == projectName) {
println "根工程${projectName} 配置阶段耗时:${System.currentTimeMillis() - begin} ms"
} else {
println "子工程${project.name} 配置阶段耗时:${System.currentTimeMillis() - begin} ms"
}
}
gradle.taskGraph.whenReady {
println "整个${projectName}项目在配置阶段总耗时:${System.currentTimeMillis() - beginOfConfig} ms"
beginOfTaskExecute = System.currentTimeMillis()
}
gradle.taskGraph.beforeTask { Task task ->
task.doFirst {
task.ext.beginOfTask = System.currentTimeMillis()
}
task.doLast {
println "${task.name}在执行阶段耗时:${System.currentTimeMillis() - task.ext.beginOfTask} ms"
}
}
gradle.buildFinished {
println " 执行阶段总耗时:${System.currentTimeMillis() - beginOfTaskExecute} ms"
println " 整个构建过程耗时:${System.currentTimeMillis() - beginOfSetting} ms"
}
我们继续执行gradle C吧,看看打印,这里理解一下他们的逻辑就行了基本上是记录的,初始,配置,和执行的起始时间来得到后面的时间的,在内部中,配置阶段,记录了项目对应执行之前的起始,执行阶段,记录任务执行之前的起始,这样可以得到所有相关信息了
创建 Springboot 项目:
Spring Boot Gradle 插件在 Gradle 提供 Spring Boot 支持,它允许您打包可执行 jar 或 war 归档文件,然后进行运行Spring Boot 应用程序,并使用 Spring-Boot-dependencies 提供的依赖管理,当然了,SpringBoot是可执行jar包,有可直接运行的主类,否则一般的像单纯的jar包,或者class,需要手动的处理,而这些我们通常并不能作为项目,只能进行调用或者使用,通常他也可以与web进行处理,而这样的处理我们也会称为war包,所以分为可执行jar包,不可执行jar包,war包,依赖通常都是不可执行jar包
我们可以参考:https://docs.spring.io/spring-boot/docs/current/gradle-plugin/reference/htmlsingle/#running-your-application
引入springboot 插件:
该插件发布在 Gradle 的插件门户网站上,可以使用插件块来应用:
我们先将ProjectA的子项目关联在settings.gradle中都去掉,只要留下这个即可:rootProject.name = ‘ProjectA’,然后设置他的build.gradle:
plugins {
id 'org.springframework.boot' version '2.3.7.RELEASE'
id 'io.spring.dependency-management' version '1.0.10.RELEASE'
id 'java'
}
继续补充:引入所需要的依赖
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
test {
useJUnitPlatform()
}
在src的java资源文件下,创建com包,然后创建Test类:
package com;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Test {
public static void main(String[] args) {
SpringApplication.run(Test.class, args);
}
}
然后在com包下,创建controller包,在controller包下创建ActorController类:
package com.controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/actor")
public class ActorController {
@GetMapping("/ts")
public String ts() {
return "测试";
}
}
执行gradle bootRun 指令:
要想运行当前Springboot 项目,直接执行gradle bootRun 指令(在项目ProjectA路径下)或者idea 右侧按钮即可(也就是执行上面的Test文件),当然如果想让当前项目打成可执行jar 包而不是直接执行,只需执行: gradle bootJar 指令即可(默认的,一般会存放在build的libs目录中,如ProjectA.jar),当然,直接执行在某种程度上其实也会打包,前提是总结当前的项目信息,而非直接操作,所以jar包的生成过程和操作jar包的命令(通常是java提供的)是一个规范,大多数构建项目会遵循这个规范,使得可以生成可执行jar包
当然,无论是命令执行,还是右键执行,本质上是一样的,所以当其中一个执行时,另外一个可能由于端口原因而报错,即执行不了,其中命令执行通常会有一个时间来显示执行多少和一个整体到结束的进度(并不需要考虑,对执行影响不大),命令执行使用ctrl+c可以选择停止(这在多种命令框下都可以使用,如linux)
执行后,访问:http://localhost:8080/actor/ts,看看是否有对应的信息了
当然,Spring Boot是内置Tomcat的,所以我们可以看到,在操作Spring Boot时,通常并没有明显的设置Tomcat,但是却有端口
注意:Cloud 项目创建也可以借助于脚手架(在idea中的操作的快捷)创建,与Boot 项目类似,只是可能需要更多的处理,这些创建与前面的https://start.spring.io/的地方是类似的
拓展spring-boot-gradle-plugin 插件:
需要注意位置:
buildscript {
repositories {
maven { url 'https://maven.aliyun.com/repository/public' }
}
dependencies {
classpath 'org.springframework.boot:spring-boot-gradle-plugin:2.4.1'
}
}
plugins {
id 'org.springframework.boot' version '2.3.7.RELEASE'
id 'io.spring.dependency-management' version '1.0.10.RELEASE'
id 'java'
}
apply plugin: 'org.springframework.boot'
apply plugin: 'io.spring.dependency-management'
dependencies {
implementation 'org.springframework.boot:spring-boot-starter'
implementation 'org.springframework.boot:spring-boot-starter-web'
testImplementation('org.springframework.boot:spring-boot-starter-test') {
exclude group: 'org.junit.vintage', module: 'junit-vintage-engine'
}
}
test {
useJUnitPlatform()
}
所以插件存在多种:
直接使用,加版本号,那么操作下载,不操作版本号,可以使用内部,或者第三方,也可以手动指定
使用这些插件,可以使用定义的里面的东西,或者操作,如任务,依赖和插件并不相关,插件是补充的东西,依赖是补充的jar包
但是插件也可以在其内部完成依赖的导入,比如内部处理了相关implementation的处理,所以存在插件完成依赖的处理也是没有什么问题的,这里了解即可
基于 ssm 多模块项目案例:
我们重新创建项目:
首先创建父项目:project-parent(一般来说,创建文件夹通常都是小写,前面的是测试,并没有按照这样的规范来)
对应的build.gradle:
plugins {
id 'java'
}
group 'com.project'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
}
test {
useJUnitPlatform()
}
为什么文件夹按照小写,以及为什么要这样的规范:
其实大多数是为了操作系统中的文件系统来规定的,因为有些操作系统中(文件系统),可能并不会区分文件的大小写,比如在windows中,ProjectA和projecta是同一个文件,那么在中间的代码处理时,如io流中,对应路径大写是可以找到对应的小写的,也就是:
new FileWriter("d:/gGG/a.txt", true);
new FileWriter("d:/ggg/a.txt", true);
他们在windows中是等价的,但是在其他操作系统中可能就不是的,比如linux中,他们是两个文件,自然在这样的处理时,可能就会产生其他问题,因为对应的其他程序可能是从对应的ggg文件拿取文件的,但是你是gGG,由于是linux不同的,自然会出现某些问题甚至会报错,而windows则不会,但是虽然我们只能选择一个规范,但是为什么是全部小写,而不是大写呢,主要是观察:你是否可以发现,如果一个单词全部用大写,对比一下小写,哪个可读性大呢,自然是小写,因为并没有完全整齐,自然好观察
综上所述:文件夹中最好是使用小写(全部小写)
子工程为:
project-mobile-web
project-web
project-service
project-dao
project-bean
他们的build.gradle都是这个:
plugins {
id 'java'
}
group 'com.project'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
}
test {
useJUnitPlatform()
}
settings.gradle 文件中:
rootProject.name = 'project-parent'
include 'project-mobile-web'
include 'project-web'
include 'project-service'
include 'project-dao'
include 'project-bean'
一般创建子项目时,会自动补充的(在maven中也是如此)
在根工程 build.gradle 文件中抽取子模块的公共配置:
给project-parent项目的build.gradle中加上如下:
plugins {
id 'java'
id "io.franzbecker.gradle-lombok" version "5.0.0"
}
group 'com.project'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
}
test {
useJUnitPlatform()
}
subprojects {
apply plugin: 'java'
apply plugin: 'io.franzbecker.gradle-lombok'
targetCompatibility = 1.8
compileJava.options.encoding "UTF-8"
compileTestJava.options.encoding "UTF-8"
tasks.withType(JavaCompile) {
options.encoding = "UTF-8"
}
group 'com.project'
version '1.0-SNAPSHOT'
repositories {
mavenLocal()
maven { url "https://maven.aliyun.com/repository/public" }
maven { url "https://maven.aliyun.com/repository/central" }
maven { url "https://maven.aliyun.com/repository/google" }
maven { url "https://maven.aliyun.com/repository/spring" }
mavenCentral()
}
dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
implementation 'log4j:log4j:1.2.17'
}
test {
useJUnitPlatform()
}
}
这样,我们可以将子项目的build.gradle中的内容全部清除了(gradle很灵活吧,这是因为可以操作代码,所以灵活,比maven灵活)
现在在根工程的build.gradle 文件中配置各个模块的依赖信息,补充如下:
project("project-bean") {
apply plugin: 'java-library'
dependencies {
api 'org.projectlombok:lombok:1.18.24'
}
}
project("project-dao") {
apply plugin: 'java-library'
dependencies {
api project(':project-bean')
implementation 'org.mybatis:mybatis-spring:1.2.3'
implementation 'com.alibaba:druid:1.0.15'
implementation 'org.mybatis:mybatis:3.3.0'
implementation 'mysql:mysql-connector-java:5.1.36'
}
}
project("project-service") {
apply plugin: 'java-library'
dependencies {
api project(':project-dao')
implementation 'org.springframework:spring-web:4.1.7.RELEASE'
implementation 'org.springframework:spring-test:4.0.5.RELEASE'
implementation 'org.springframework:spring-jdbc:4.1.7.RELEASE'
implementation 'org.aspectj:aspectjweaver:1.8.6'
}
}
project("project-web") {
apply plugin: 'war'
dependencies {
implementation project(':project-service')
implementation 'org.springframework:spring-webmvc:4.1.7.RELEASE'
implementation "com.fasterxml.jackson.core:jackson-databind:2.2.3"
implementation "com.fasterxml.jackson.core:jackson-annotations:2.2.3"
implementation "com.fasterxml.jackson.core:jackson-core:2.2.3"
compileOnly 'javax.servlet:servlet-api:2.5'
implementation 'jstl:jstl:1.2'
}
}
project("project-mobile-web") {
apply plugin: 'war'
dependencies {
implementation project(':project-service')
implementation 'org.springframework:spring-webmvc:4.1.7.RELEASE'
implementation "com.fasterxml.jackson.core:jackson-databind:2.2.3"
implementation "com.fasterxml.jackson.core:jackson-annotations:2.2.3"
implementation "com.fasterxml.jackson.core:jackson-core:2.2.3"
compileOnly 'javax.servlet:servlet-api:2.5'
implementation 'jstl:jstl:1.2'
}
}
这样基本依赖都操作完毕,我们可以来进行测试:
首先创建数据库,具体的语句是:
CREATE DATABASE test CHARACTER SET utf8;
USE test;
CREATE TABLE USER(
id INT(11) PRIMARY KEY,
NAME VARCHAR(20)
);
INSERT INTO USER VALUES(1,'张三');
INSERT INTO USER VALUES(2,'李四');
然后在project-bean中的java资源文件夹中创建com.domain包,然后创建User类:
package com.domain;
import lombok.Data;
import java.io.Serializable;
@Data
public class User implements Serializable {
private Long id;
private String name;
}
我们在project-dao的java资源文件夹下创建com.dao包,然后创建UserDao接口:
package com.dao;
import com.domain.User;
public interface UserDao {
User select(User user);
}
我们继续在该子项目的资源(resources)文件夹下创建com目录,然后在该包下创建dao目录,然后创建UserDao.xml文件:
DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.dao.UserDao">
<select id="select" resultType="com.domain.User" parameterType="user">
select *
from user
where id = #{id}
and name = #{name}
select>
mapper>
我们继续在该资源文件夹下创建jdbc.properties文件:
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql:///test?characterEncoding=utf8&useSSL=false
jdbc.username=root
jdbc.password=123456
然后我们在project-service中创建com.service包,然后创建UserService接口和其实现类:
package com.service;
import com.domain.User;
public interface UserService {
User select(User user);
}
package com.service.impl;
import com.dao.UserDao;
import com.domain.User;
import com.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Override
public User select(User user) {
return userDao.select(user);
}
}
然后在资源文件夹下创建applicationContext.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.service">context:component-scan>
<context:property-placeholder location="classpath:jdbc.properties">context:property-placeholder>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.driver}">property>
<property name="url" value="${jdbc.url}">property>
<property name="username" value="${jdbc.username}">property>
<property name="password" value="${jdbc.password}">property>
bean>
<bean id="sessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource">property>
<property name="typeAliasesPackage" value="com.domain">property>
bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.dao">property>
bean>
beans>
到project-web项目,首先在main目录下创建webapp目录,然后创建WEB-INF目录,然后创建web.xml文件:
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee
http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<servlet>
<servlet-name>DispatcherServletservlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServletservlet-class>
<init-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:spring-mvc.xmlparam-value>
init-param>
<load-on-startup>2load-on-startup>
servlet>
<servlet-mapping>
<servlet-name>DispatcherServletservlet-name>
<url-pattern>/url-pattern>
servlet-mapping>
<filter>
<filter-name>CharacterEncodingFilterfilter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilterfilter-class>
<init-param>
<param-name>encodingparam-name>
<param-value>UTF-8param-value>
init-param>
filter>
<filter-mapping>
<filter-name>CharacterEncodingFilterfilter-name>
<url-pattern>/*url-pattern>
filter-mapping>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListenerlistener-class>
listener>
<context-param>
<param-name>contextConfigLocationparam-name>
<param-value>classpath:applicationContext.xmlparam-value>
context-param>
web-app>
然后再资源文件夹下创建spring-mvc.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.controller">context:component-scan>
<mvc:annotation-driven>mvc:annotation-driven>
beans>
然后再java资源文件夹下,创建com.controller包,然后创建UserController类:
package com.controller;
import com.domain.User;
import com.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@RequestMapping("/select")
public User select(
@RequestParam(required = false) Long id,
@RequestParam(required = false) String name,
User user1) {
System.out.println(id);
System.out.println(name);
User user = new User();
user.setId(id);
user.setName(name);
System.out.println(user1);
return userService.select(user);
}
}
操作好后,我们还需要进行修改一个地方,其实我们的api共享插件拿取的通常只是依赖,依赖我们的确有,但是在部署或者打包时,对应的只有web层的代码,那么为什么我们在项目中可以进行处理呢,或者可以使用到呢,因为上下文是共享的jar,实际上打包也会,而之所以idea可以认为我们可以直接使用,是idea的处理,具体在部署以及直接打包后,我需要看gradle的,这里再idea的maven中也是类似的
简单来说,我们在写代码时,看起来可以使用其他模块的代码(前面的api共享),但是在打包和部署时,却不是,因为前者是idea,后者是具体的处理,maven中也是如此,只不过maven的依赖和代码共同都给过去,而不是这里的gradle的依赖选择传递或者部分传递,且是手动,并且war的组成可能也需要手动,而且,由于gradle的版本不同,所造成的操作或者影响可能不同,如果出现什么问题,可以百度查看
我这里的api是部分的,所以选择后,还需要给对应选择的依赖项目中进行api的共享,只有api共享的依赖,才会传递
并且war可能是进行处理时,也需要这样的处理:
project("project-web") {
apply plugin: 'war'
war {
archiveName = 'project-web.war'
from project.configurations.runtimeClasspath
from project(':project-service').configurations.runtimeClasspath
from project(':project-dao').configurations.runtimeClasspath
from project(':project-bean').configurations.runtimeClasspath
}
dependencies {
implementation project(':project-service')
implementation 'org.springframework:spring-webmvc:4.1.7.RELEASE'
implementation "com.fasterxml.jackson.core:jackson-databind:2.2.3"
implementation "com.fasterxml.jackson.core:jackson-annotations:2.2.3"
implementation "com.fasterxml.jackson.core:jackson-core:2.2.3"
compileOnly 'javax.servlet:servlet-api:2.5'
implementation 'jstl:jstl:1.2'
}
}
当然,大多数版本下,对应的api操作也会给代码的(或者传递jar包),所以上面的可以选择不写,具体可以在打包后的war中可以看到对应项目的jar(在部署(idea的tomcat部署启动)和打包是拿取jar的,maven也是这样,而不是idea的直接使用)
一般情况下,build命令是编译和打包的意思(可以发现,在右边,并没有maven中的打包处理,那么build就是多个任务的处理的,这里也与maven中操作后面的,前面也会操作的,是同一样的)
注意:默认情况下,刷新是操作build的,但是操作之后,他就只是一种刷新处理(也是大多数刷新不会起作用的原因),这个时候执行clean,通常需要他来刷新一次来真正的执行了(虽然可能是看起来,就如前面说过的切换(切换回来就可以了,可以全局搜索切换)),并且对应的处理只能是当前项目的(一般并不是),他并没有maven中,父操作子都会操作的处理,父就是父,子就是子,当然,依赖的处理会这样的(因为共享依赖是更新的,当前,是相对来说的父(api共享谁引入谁是子))
引入后,可以手动将当前项目的build(包括子项目)都进行清除,然后执行右边的build,来进行打包,如果没反应,刷新一下,也可以在命令行中执行gradel build(一般子没有gradlew,我们使用配置好的全局gradle)来操作,然后我们部署tomcat,一般有两个关于project-web的,其中带有后缀exploded是解压没带后缀的,所以他们基本都可以选择,我们选择带后缀的(注意:大多数对应的依赖传递由于是更新的,那么当你部署其中一个时,相关的都会进行部署或者说编译,所以其实我们只需要编译project-web即可,其他的并不需要操作),然后我们访问http://localhost:8080/gradle/user/select?id=1&name=张三(其中gradle是命名的)
看看打印信息吧,若有打印,且返回了信息,并且正确,那么说明我们操作成功,还有,虽然前面可能提到了,对应的处理或者说是编译只能当前项目处理,其实大多数情况下,gradle也存在父子联动的,也就是操作根项目编译,会给起子项目进行编译(根据其配置来,settings.gradle),而不是没有maven的处理(具体看版本)
这里需要注意的情况:
api需要手动处理,手动编译project-web,然后部署启动即可
并且,每个任务或者实例中,都是有自身存在的处理,比如allprojects和subprojects可能存在不同的处理,比如subprojects有的,allprojects可能操作不了,具体可以看错误或者百度或者gradle文档(这里说明所有的属性也比较麻烦),也比如:
plugins {