本地部署清华大模型ChatGlm-6b、ChatGlm2-6b与ChatGlm3-6b(api接口、demo界面、流式非流式)(非常详细)
一、所具备的python环境和软硬件条件
1.python环境:直接安装Anaconda 3-2022
(1)百度网盘下载地址(下载文件中附了非常详细的安装教程):https://pan.baidu.com/s/1KQNOlYU-GMKbkPGcip1Hzw?pwd=5678
(2)直接网上百度下载和安装,非常多教程,这里直接略过
2.软件:安装Pycharm 2020.1 x64 软件
(1)百度网盘下载地址(下载文件中附了非常详细的安装教程):https://pan.baidu.com/s/1RaZJicGGUhBFCEh1Jy12lw 提取码:a66w
(2)直接网上百度下载和安装,非常多教程,这里直接略过
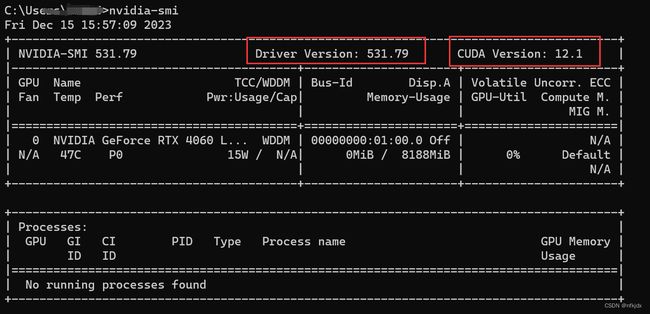
3.查看当前电脑的cuda版本,为后面安装pytorch做准备
打开cmd的shell,输入命令:nvidia-smi,cuda版本为12.1
二、下载chatglm的代码
下载地址:https://github.com/THUDM/ChatGLM2-6B

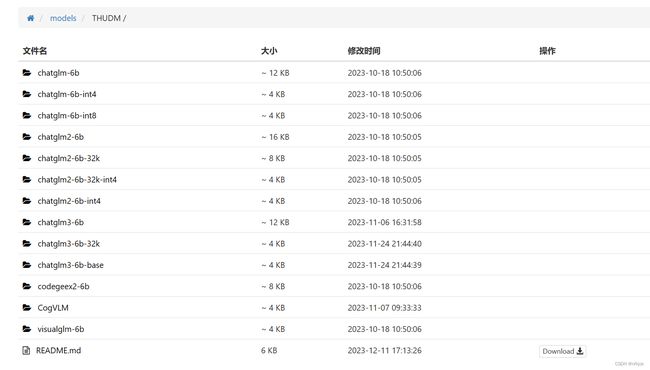
三、下载chatglm的模型
下载地址:https://aifasthub.com/models/THUDM
四、利用安装的pycharm打开下载的chatglm代码并设置环境
环境设置:File—Settings—Project:项目名—Python Interpret—接下来如下图所示:

点击上面的设置符号后会出现Add,点击Add,出现如下图:

选择存在的环境,点击浏览查找,如下图:
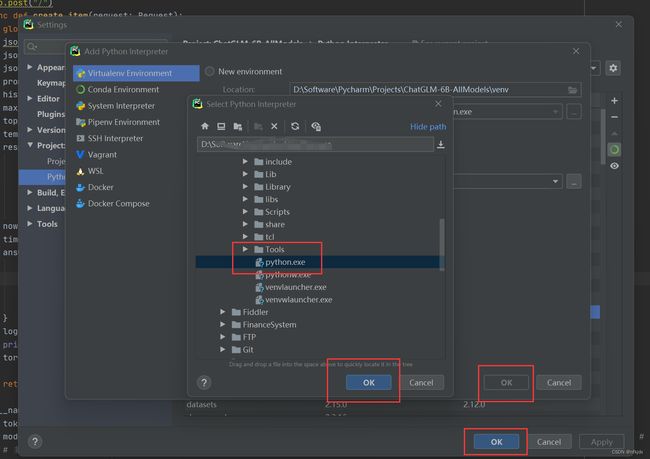
最后选择python.exe,点击每页ok就完成了!
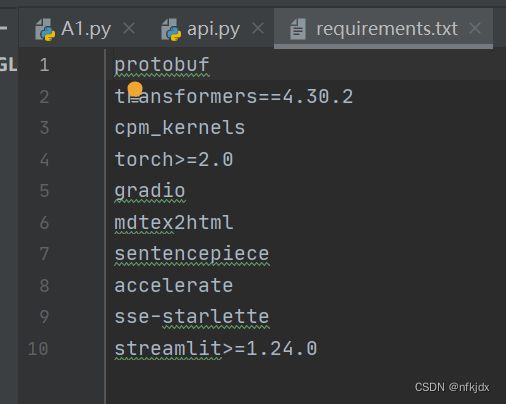
五、安装chatglm代码中所需要的包:找到代码项目中的requirements.txt文件,安装除torch之外的所有包(因为torch需要与cuda对应):可以使用清华、华为等源地址快速安装
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
比如:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ protobuf
六、安装torch:通过步骤一中的第3小点知道了本机cuda版本
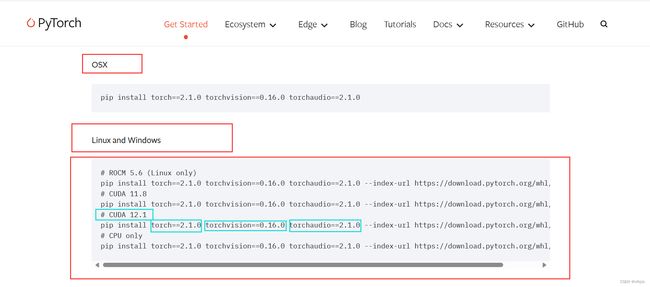
(1)方式一(在线安装):打开网址:https://pytorch.org/get-started/previous-versions/,查找本机对应的torch,并通过命令在线安装,如下图所示;
CUDA 11.8
pip install torch2.0.0+cu118 torchvision0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
(2)方式二(离线安装):打开网址:https://download.pytorch.org/whl/torch_stable.html
https://download.pytorch.org/whlversions/,查找到对应的torch、torchaudio、torchvision并下载下来,通过命令:pip install 下载地址+文件 进行安装

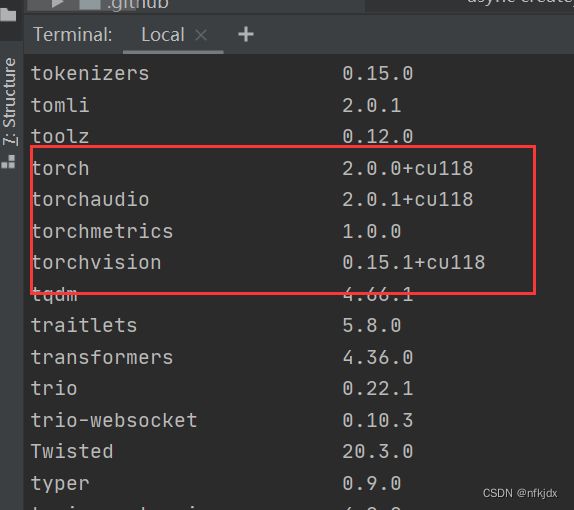
安装好之后,可以通过pip list 或者 conda list查看
七、首先进行api接口的改写(api中代码为非流式请求):
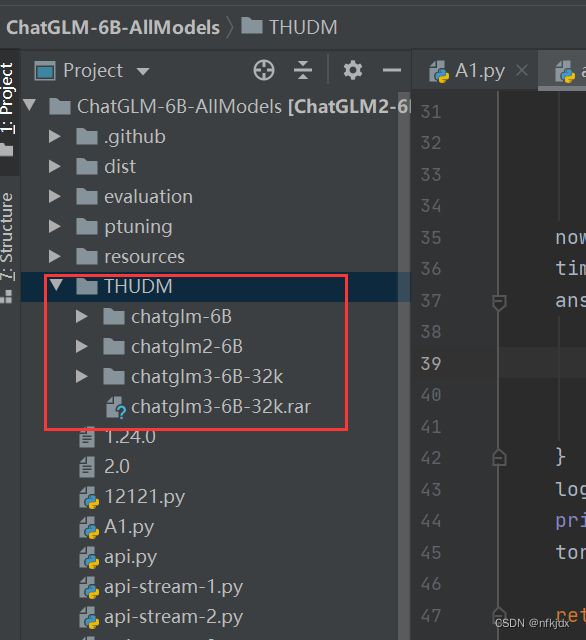
1、先在下载的chatglm代码项目里面新建THUDM文件夹,并将下载的chatglm模型放入其中
2、打开里面的api.py文件,进行简单改写:
第一步:主要改写模型的地址和url地址与端口号(模型的地址根据自己存放的地址,url地址可以是本机地址,也可以是1270.0.1,端口号可以随意写)
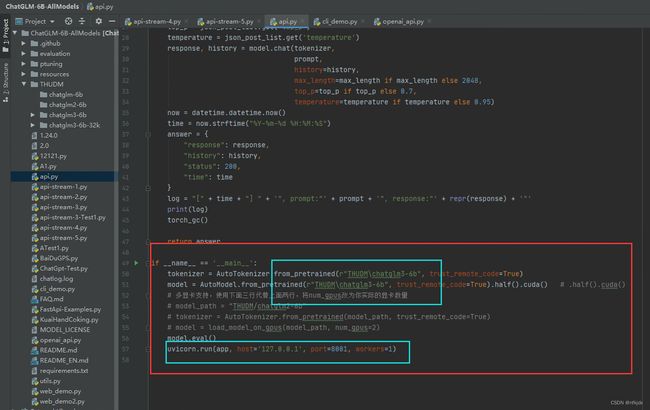
此时就可以运行api.py文件,如下图:

复制生成的地址,在网页中打开http://127.0.0.1:8001/docs,一个非常简单的post请求接口,没有任何请求参数,因此此时运行会报错,需要自己去进行改写:

3、对api.py进行大改:
(1)添加请求参数:
class Item(BaseModel):
prompt: str = None
history: list = None
max_length: int = None
top_p: float = None
temperature: float = None
(2)改写参数请求方式:
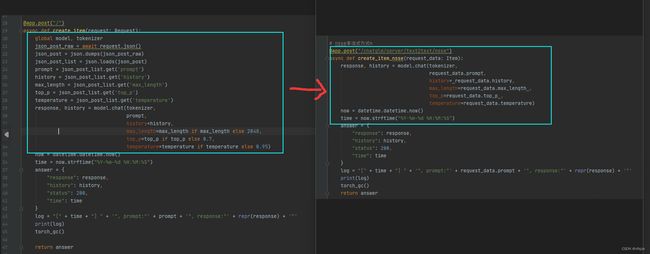
(3)改写完之后的全部代码(非流式):
#encoding:gbk
import platform
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch,os
from sse_starlette.sse import EventSourceResponse
from pydantic import BaseModel
from utils import load_model_on_gpus
class Item(BaseModel):
prompt: str = None
history: list = None
max_length: int = None
top_p: float = None
temperature: float = None
app = FastAPI()
os_name = platform.system()
clear_command = 'cls' if os_name == 'Windows' else 'clear'
stop_stream = False
# GC回收显存
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
# nsse非流式方式n
@app.post("/chatglm/server/text2text/nsse")
async def create_item_nsse(request_data: Item):
response, history = model.chat(tokenizer,
request_data.prompt,
history= request_data.history,
max_length=request_data.max_length ,
top_p=request_data.top_p ,
temperature=request_data.temperature)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + request_data.prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
# cpu/gpu推理,建议GPU,CPU实在是忒慢了
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
# 多显卡支持,使用下面三行代替上面两行,将num_gpus改为你实际的显卡数量
# model_path = "./THUDM/chatglm3-6B-32k"
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# model = load_model_on_gpus(model_path, num_gpus=2)
tokenizer = AutoTokenizer.from_pretrained("THUDM\chatglm3-6b-32k", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM\chatglm3-6b-32k", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='127.0.0.1', port=9000, workers=1)
(4)改写完之后的全部代码(流式和非流式):
#encoding:gbk
import platform
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch,os
from sse_starlette.sse import EventSourceResponse
from pydantic import BaseModel
from utils import load_model_on_gpus
class Item(BaseModel):
prompt: str = None
history: list = None
max_length: int = None
top_p: float = None
temperature: float = None
app = FastAPI()
os_name = platform.system()
clear_command = 'cls' if os_name == 'Windows' else 'clear'
stop_stream = False
# 流式推理
def predict_stream(tokenizer, prompt, history, max_length, top_p, temperature):
global stop_stream
print("欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
while True:
current_length = 0
for response, history in model.stream_chat(tokenizer, prompt, history=history,):
if stop_stream:
stop_stream = False
break
else:
yield json.dumps({
'response': response[current_length:],
'history': history,
'status': 200,
'sse_status': 1,
}, ensure_ascii=False)
return torch_gc()
# GC回收显存
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
# sse流式方式
@app.post("/chatglm/server/text2text/sse")
async def create_item_sse(request_data: Item):
res = predict_stream(tokenizer, request_data.prompt, request_data.history, request_data.max_length, request_data.top_p, request_data.temperature)
return EventSourceResponse(res)
# nsse非流式方式n
@app.post("/chatglm/server/text2text/nsse")
async def create_item_nsse(request_data: Item):
response, history = model.chat(tokenizer,
request_data.prompt,
history= request_data.history,
max_length=request_data.max_length ,
top_p=request_data.top_p ,
temperature=request_data.temperature)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + request_data.prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
# cpu/gpu推理,建议GPU,CPU实在是忒慢了
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
# 多显卡支持,使用下面三行代替上面两行,将num_gpus改为你实际的显卡数量
# model_path = "./THUDM/chatglm3-6B-32k"
# tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# model = load_model_on_gpus(model_path, num_gpus=2)
tokenizer = AutoTokenizer.from_pretrained("THUDM\chatglm3-6b-32k", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM\chatglm3-6b-32k", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='127.0.0.1', port=9000, workers=1)
(5)运行效果:
流式:
非流式:

八、对cli_demo.py进行改写(流式请求):
import os
import platform
import signal
from transformers import AutoTokenizer, AutoModel
import readline
tokenizer = AutoTokenizer.from_pretrained("THUDM\chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM\chatglm3-6b", trust_remote_code=True).half().cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
model = model.eval()
os_name = platform.system()
clear_command = 'cls' if os_name == 'Windows' else 'clear'
stop_stream = False
def build_prompt(history):
prompt = "欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
for query, response in history:
prompt += f"\n\n用户:{query}"
prompt += f"\n\nChatGLM2-6B:{response}"
return prompt
def signal_handler(signal, frame):
global stop_stream
stop_stream = True
def main():
past_key_values, history = None, []
global stop_stream
print("欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
while True:
query = input("\n用户:")
if query.strip() == "stop":
break
if query.strip() == "clear":
past_key_values, history = None, []
os.system(clear_command)
print("欢迎使用 ChatGLM2-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
continue
print("\nChatGLM:", end="")
current_length = 0
for response, history in model.stream_chat(tokenizer, query, history=history,): #past_key_values=past_key_values, #return_past_key_values=True):
if stop_stream:
stop_stream = False
break
else:
print(response[current_length:], end="", flush=True)
current_length = len(response)
print("")
if __name__ == "__main__":
main()
结果如下所示:

九、对web_demo.py进行改写(流式请求):
(1)首先安装:
pip install -U httpcore
pip install -U httpx==0.24.1
(2)将 gradio 版本降低至3.50.0
(3)改写代码
from transformers import AutoModel, AutoTokenizer
import gradio as gr
import mdtex2html
from utils import load_model_on_gpus
tokenizer = AutoTokenizer.from_pretrained("THUDM\chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM\chatglm3-6b", trust_remote_code=True).half().cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
model = model.eval()
"""Override Chatbot.postprocess"""
def postprocess(self, y):
if y is None:
return []
for i, (message, response) in enumerate(y):
y[i] = (
None if message is None else mdtex2html.convert((message)),
None if response is None else mdtex2html.convert(response),
)
return y
gr.Chatbot.postprocess = postprocess
def parse_text(text):
"""copy from https://github.com/GaiZhenbiao/ChuanhuChatGPT/"""
lines = text.split("\n")
lines = [line for line in lines if line != ""]
count = 0
for i, line in enumerate(lines):
if "```" in line:
count += 1
items = line.split('`')
if count % 2 == 1:
lines[i] = f'<pre><code class="language-{items[-1]}">'
else:
lines[i] = f'
"+line text = "".join(lines) return text def predict(input, chatbot, max_length, top_p, temperature, history, past_key_values): chatbot.append((parse_text(input), "")) for response, history in model.stream_chat(tokenizer, input, history, past_key_values=past_key_values, return_past_key_values=True, max_length=max_length, top_p=top_p, temperature=temperature): chatbot[-1] = (parse_text(input), parse_text(response)) yield chatbot, history, past_key_values def reset_user_input(): return gr.update(value='') def reset_state(): return [], [], None with gr.Blocks() as demo: gr.HTML("""
">ChatGLM3-6B
""") chatbot = gr.Chatbot() with gr.Row(): with gr.Column(scale=4): with gr.Column(scale=12): user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style( container=False) with gr.Column(min_width=32, scale=1): submitBtn = gr.Button("Submit", variant="primary") with gr.Column(scale=1): emptyBtn = gr.Button("Clear History") max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True) top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True) temperature = gr.Slider(0, 1, value=0.95, step=0.01, label="Temperature", interactive=True) history = gr.State([]) past_key_values = gr.State(None) submitBtn.click(predict, [user_input, chatbot, max_length, top_p, temperature, history, past_key_values], [chatbot, history, past_key_values], show_progress=True) submitBtn.click(reset_user_input, [], [user_input]) emptyBtn.click(reset_state, outputs=[chatbot, history, past_key_values], show_progress=True) demo.queue().launch(share=False, inbrowser=True)(4)运行代码,结果如下:
