熔岩羊驼LLaVA:社区又一个多模态大模型,像GPT-4一样可以看图聊天
本文来源 机器之心 编辑:赵阳
尽管 LLaVA 是用一个小的多模态指令数据集训练的,但它在一些示例上展示了与多模态模型 GPT-4 非常相似的推理结果。

GPT-4 的识图能力什么时候能上线呢?这个问题目前依然没有答案。
但研究社区已经等不及了,纷纷自己上手 DIY,其中最火的是一个名为 MiniGPT-4 的项目。MiniGPT-4 展示了许多类似于 GPT-4 的能力,例如生成详细的图像描述并从手写草稿创建网站。此外,作者还观察到 MiniGPT-4 的其他新兴能力,包括根据给定的图像创作故事和诗歌,提供解决图像中显示的问题的解决方案,根据食品照片教用户如何烹饪等。该项目上线 3 天就拿到了近一万的 Star 量。
今天要介绍的项目 ——LLaVA(Large Language and Vision Assistant)与之类似,是一个由威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学研究者共同发布的多模态大模型。

论文链接:https://arxiv.org/pdf/2304.08485.pdf
项目链接:https://llava-vl.github.io/
该模型展示出了一些接近多模态 GPT-4 的图文理解能力:相对于 GPT-4 获得了 85.1% 的相对得分。当在科学问答(Science QA)上进行微调时,LLaVA 和 GPT-4 的协同作用实现了 92.53% 准确率的新 SoTA。

以下是机器之心的试用结果(更多结果见文末):

论文概览
人类通过视觉和语言等多种渠道与世界交互,因为不同的渠道在代表和传达某些概念时都有各自独特的优势,多渠道的方式有利于更好地理解世界。人工智能的核心愿望之一是开发一个通用的助手,能够有效地遵循多模态指令,例如视觉或语言的指令,满足人类的意图,在真实环境中完成各种任务。
为此,社区兴起了对开发基于语言增强的视觉模型的风潮。这类模型在开放世界视觉理解方面具有强大的能力,如分类、检测、分割和图文,以及视觉生成和视觉编辑能力。每个任务都由一个大型视觉模型独立解决,在模型设计中隐含地考虑了任务的需求。此外,语言仅用于描述图像内容。虽然这使得语言在将视觉信号映射到语言语义(人类交流的常见渠道)方面发挥了重要作用,但它导致模型通常具有固定的界面,在交互性和对用户指令的适应性上存在限制。
另一方面,大型语言模型(LLM)已经表明,语言可以发挥更广泛的作用:作为通用智能助理的通用交互接口。在通用接口中,各种任务指令可以用语言明确表示,并引导端到端训练的神经网络助理切换模式来完成任务。例如,ChatGPT 和 GPT-4 最近的成功证明了 LLM 在遵循人类指令完成任务方面的能量,并掀起了开发开源 LLM 的热潮。其中,LLaMA 是一种与 GPT-3 性能相近的开源 LLM。Alpaca、Vicuna、GPT-4-LLM 利用各种机器生成的高质量指令跟踪样本来提高 LLM 的对齐能力,与专有 LLM 相比,展示出了令人印象深刻的性能。但遗憾的是,这些模型的输入仅为文本。
在本文中,研究者提出了视觉 instruction-tuning 方法,首次尝试将 instruction-tuning 扩展到多模态空间,为构建通用视觉助理铺平了道路。
具体来说,本文做出了以下贡献:
多模态指令数据。当下关键的挑战之一是缺乏视觉与语言组成的指令数据。本文提出了一个数据重组方式,使用 ChatGPT/GPT-4 将图像 - 文本对转换为适当的指令格式;
大型多模态模型。研究者通过连接 CLIP 的开源视觉编码器和语言解码器 LLaMA,开发了一个大型多模态模型(LMM)—— LLaVA,并在生成的视觉 - 语言指令数据上进行端到端微调。实证研究验证了将生成的数据用于 LMM 进行 instruction-tuning 的有效性,并为构建遵循视觉 agent 的通用指令提供了较为实用的技巧。使用 GPT-4,本文在 Science QA 这个多模态推理数据集上实现了最先进的性能。
开源。研究者向公众发布了以下资产:生成的多模式指令数据、用于数据生成和模型训练的代码库、模型检查点和可视化聊天演示。
LLaVA 架构
本文的主要目标是有效利用预训练的 LLM 和视觉模型的功能。网络架构如图 1 所示。本文选择 LLaMA 模型作为 LLM fφ(・),因为它的有效性已经在几个开源的纯语言 instruction-tuning 工作中得到了证明。

对于输入图像 X_v,本文使用预训练的 CLIP 视觉编码器 ViT-L/14 进行处理,得到视觉特征 Z_v=g (X_v)。实验中使用的是最后一个 Transformer 层之前和之后的网格特征。本文使用一个简单的线性层来将图像特征连接到单词嵌入空间中。具体而言,应用可训练投影矩阵 W 将 Z_v 转换为语言嵌入标记 H_q,H_q 具有与语言模型中的单词嵌入空间相同的维度:
![]()
之后,得到一系列视觉标记 H_v。这种简单投影方案具有轻量级、成本低等特点,能够快速迭代以数据为中心的实验。也可以考虑连接图像和语言特征的更复杂(但昂贵)的方案,例如 Flamingo 中的门控交叉注意力机制和 BLIP-2 中的 Q-former,或者提供对象级特征的其他视觉编码器,如 SAM。
实验结果
多模态聊天机器人
研究者开发了一个聊天机器人示例产品,以展示 LLaVA 的图像理解和对话能力。为了进一步研究 LLaVA 如何处理视觉输入,展现其处理指令的能力,研究者首先使用 GPT-4 原始论文中的示例,如表 4 和表 5 所示。使用的 prompt 需要贴合图像内容。为了进行比较,本文引用了其论文中多模态模型 GPT-4 的 prompt 和结果。
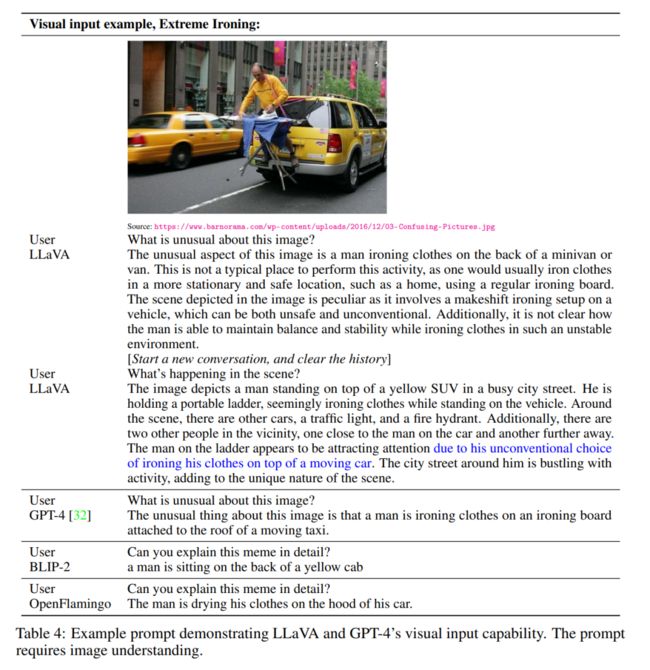

令人惊讶的是,尽管 LLaVA 是用一个小的多模态指令数据集(约 80K 的不重复图像)训练的,但它在以上这两个示例上展示了与多模态模型 GPT-4 非常相似的推理结果。请注意,这两张图像都不在 LLaVA 的数据集范围内,LLaVA 能够理解场景并按照问题说明进行回答。相比之下,BLIP-2 和 OpenFlamingo 专注于描述图像,而不是按照用户指令以适当的方式进行回答。更多示例如图 3、图 4 和图 5 所示。



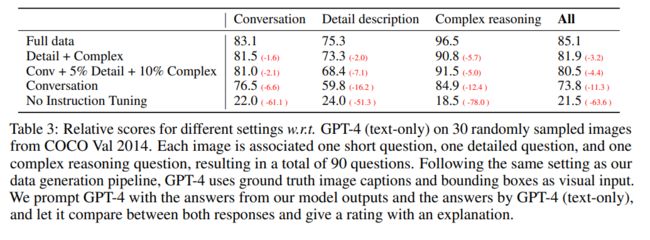
定量评估结果见表 3。
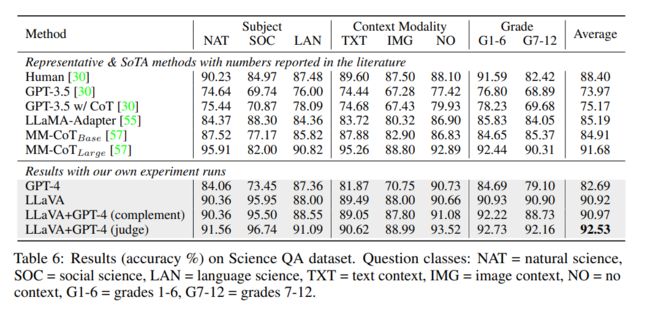
ScienceQA
ScienceQA 包含 21k 个多模态多选问题,涉及 3 个主题、26 个话题、127 个类别和 379 种技能,具有丰富的领域多样性。基准数据集分为训练、验证和测试部分,分别有 12726、4241 和 4241 个样本。本文对比了两种有代表性的方法,包括 GPT-3.5 模型(text-davinci-002)和没有思维链(CoT)版本的 GPT-3.5 模型,LLaMA-Adapter,以及多模态思维链(MM-CoT)[57],这是该数据集上当前的 SoTA 方法,结果如表 6 所示。
试用反馈
在论文给出的可视化使用页面上,机器之心也尝试着输入了一些图片和指令。首先是问答里常见的数人任务。测试表明,数人的时候较小的目标会被忽略,重叠的人也有识别误差,性别也有识别误差。


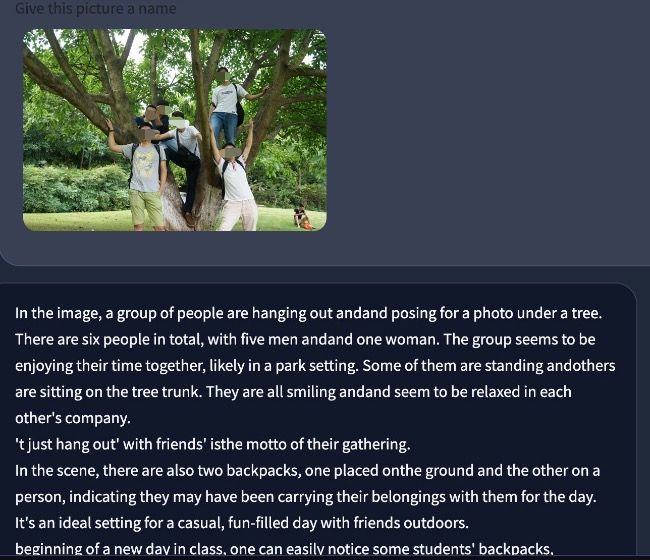
接着,我们尝试了一些生成任务,比如为图片起名字,或者根据图片讲一个故事。模型输出的结果还是偏向于图片内容理解,生成方面的能力还有待加强。

在这张照片中,即便人体有重合也依然能准确地识别出人数。从图片描述和理解能力的角度来看,本文的工作还是存在亮点,存在着二创的空间。
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
一顿午饭外卖,成为CV视觉的前沿弄潮儿!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!