多模态大模型MLLM 指令微调相关文章
文章目录
- LLM“家谱树”
- MLLM
- 使用指南--任务导向上手大模型
- 多模态大模型的发展
-
- 多模态数据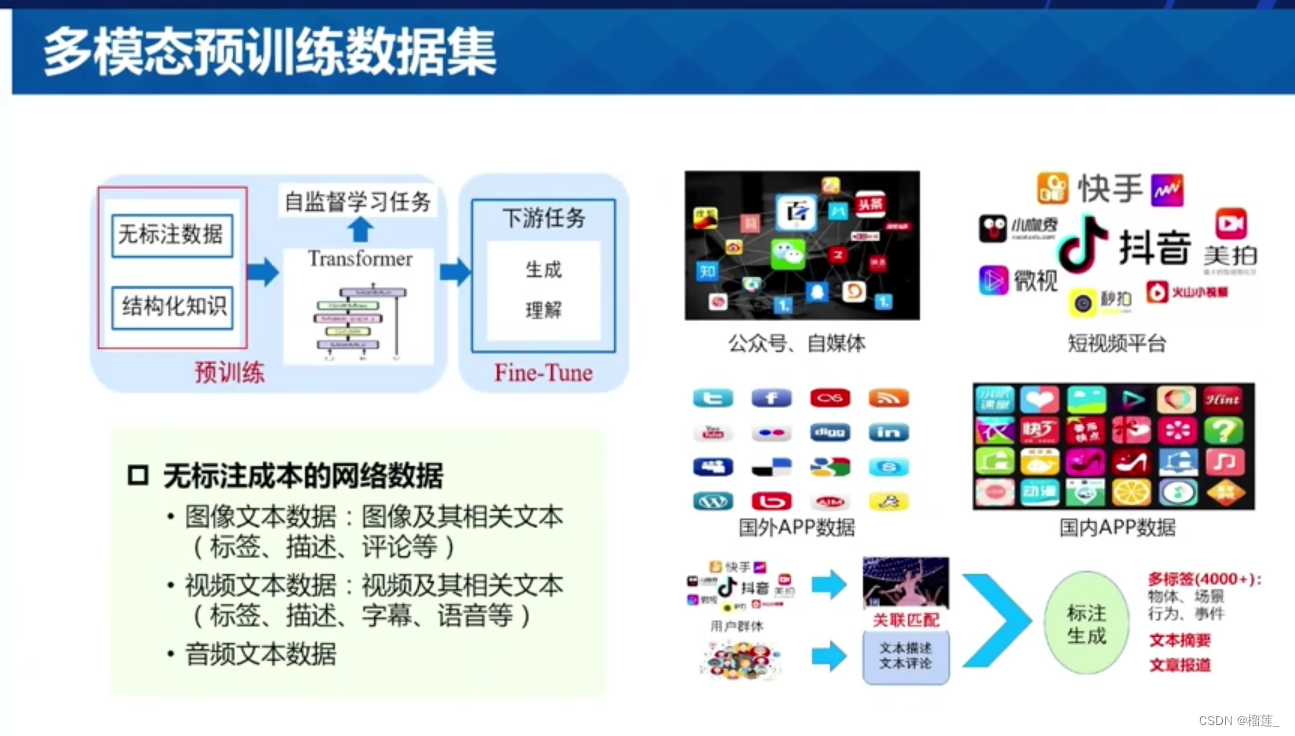
- 模型架构
- MLLM 指令微调相关文章
-
- BLIP-2
- 模型结构
- Q- Former
-
- 训练细节
- **InstructBLIP**
-
- 使用的模型
- 数据集构造
- 训练和评估协议 (**Training and Evaluation Protocols**)
- 数据采样方法- Balance Training Datasets
- Framework
- 推理方法
- miniGPT-4
-
- 数据构造
-
- 第一阶段数据集
- 第二阶段数据集
- framework
- 训练方式
-
- 第一阶段
- 第二阶段
- OpenFlamingo
-
- 数据集
- framework
- Otter: A Multi-Modal Model with In-Context Instruction Tuning
-
- 数据集
- Framework
- 训练
- LLAVA
-
- 数据集
- Framework
- 训练-next token prediction
- 实验分析
- mPLUG-owl
-
- framework
- 实验分析
- Frozen
- VisualGLM
- PICA
- Shikra
-
- framework
- 训练
- LAVIN
- OFA
-
- 图片的离散化
- 思考
- KOSMOS-2
- 一些开源库
- 一些榜单
- 其他相关链接
- 其他LLM文章
-
- LLAMA
- Vicuna(LLM)
- MOSS-moon(LLM)
- SAM-segment anything
-
- 数据引擎-Data engine
- Framework
-
- image encoder
- prompt encoder
- mask decoder
- 训练方式
- loss
- 指令生成相关文章
-
- self instruct
- Alpaca
- 相关链接
LLM“家谱树”
MLLM
近两年来基于LLM做vision-lanuage任务的一些工作,并将其划分为4个类别:
- 冻住LLM,训练视觉编码器等额外结构以适配LLM,例如mPLUG-Owl,LLaVA,Mini-GPT4,Frozen,BLIP2,Flamingo,PaLM-E[1]
- 将视觉转化为文本,作为LLM的输入,例如PICA(2022),PromptCap(2022)[2],ScienceQA(2022)[3]
- 利用视觉模态影响LLM的解码,例如ZeroCap[4],MAGIC
- 利用LLM作为理解中枢调用多模态模型,例如VisualChatGPT(2023), MM-REACT(2023)
本文我们主要关注的重点在于冻住LLM的指令微调相关方向的文章
使用指南–任务导向上手大模型
很多时候,“大模型很好!”这个断言后紧跟着的问题就是“大模型怎么用,什么时候用?”,面对一个具体任务时,我们是应该选择微调、还是不假思索的上手大模型?下图总结出了一个实用的“决策流”,根据“是否需要模仿人类”,“是否要求推理能力”,“是否是多任务”等一系列问题帮我们判断是否要去使用大模型。
多模态大模型的发展
通用AI
【中科院刘静:多模态预训练的进展回顾与展望(多模态大模型系列【一】)】 https://www.bilibili.com/video/BV13P411q7tH/?share_source=copy_web&vd_source=b4ac5c14fc9b2a8a8def938101b76302





多模态数据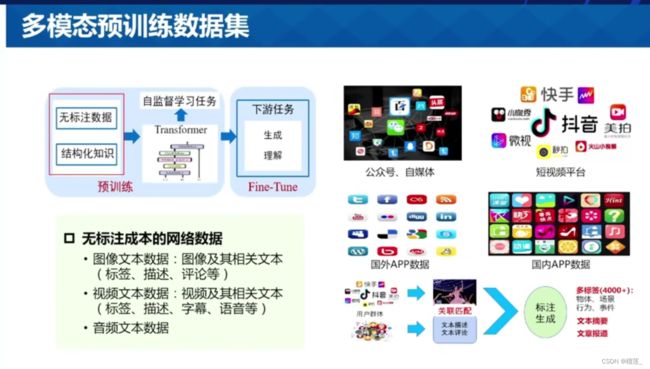
目前开源可获取的数据集-图像数据集和视频数据集

模型架构
encoder更适合做一些分析理解任务,以bert为主
decoder更适合做生成类任务

关键在于解决模态之间的关联,更好的建模图
MLLM 指令微调相关文章
BLIP-2
代码:https://github.com/salesforce/LAVIS(用于语言和视觉智能研究和应用的 Python 深度学习库,一个包含BLIP、BLIP2、IntructBLIP框架)
模态之间怎么配合就是个问题。BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂 (modality gap)。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。
Q-Former 能够从 image encoder 中提取出固定数量的输出特征(与输入图像的分辨率无关)
模型结构
如何两阶段训练 Q-Former:
-
第一阶段: vision-language representation learning stage with a frozen image encoder
能够强制让 Q-Former 学习更和文本相关的视觉表达信息 -
第二阶段: vision-to-language generative learning stage with a frozen LLM
通过将 Q-Former 的输出和 frozen LLM 连接起来实现 vision-to-language 生成式学习,所要实现的目标是能用 LLM 来解释 Q-Former 的输出视觉表达特征
上图的两个虚线框分别代表两个阶段,其中的关键部分在于q-former。

如上图所示,Q-Former 由两个 transformer 子模型组成,且两个子模型共享 self-attention layers:
image transformer:和 frozen image encoder 进行交互,来抽取视觉特征
text transformer:同时有 text encoder 和 text decoder 的作用
Q-Former 如何工作: -
首先建立一组可学习的 query embedding 作为 image transformer 的输入
-
queries 之间会通过 self-attention layer 和 text 进行交互,也能通过 cross-attention 和 frozen image feature 进行交互
-
基于不同的预训练任务, 作者会使用不同的 self-attention mask 来控制 query-text 之间的交互
-
Q-Former 使用 BERT_base 进行初始化,cross-attention layers 的参数是随机初始化的
-
Q-Former 共包含 188M 参数
-
在实验中,作者使用了 32 queries,每个 query 有 768 维,使用 Z Z Z 来定义输出 query representation, Z Z Z ( 32 × 768 ) 的尺寸远远小于 frozen image feature 的尺寸(ViT-L/14 是 256x1024)
-
该结构能够和目标函数一起促进 query 来提取更和 text 相关的视觉信息
Q- Former
# 初始化
query_tokens = nn.Parameter(
torch.zeros(1, num_query_token, encoder_config.hidden_size)
)
query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range)
#使用
query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
query_output = self.Qformer.bert(
query_embeds=query_tokens,
encoder_hidden_states=image_embeds,
encoder_attention_mask=image_atts,
use_cache=True,
return_dict=True,
)
如何连接图像和文本两个模态
from lavis.models.blip2_models.Qformer import BertConfig, BertLMHeadModel
encoder_config = BertConfig.from_pretrained("bert-base-uncased")
encoder_config.encoder_width = vision_width
Qformer = BertLMHeadModel.from_pretrained(
"bert-base-uncased", config=encoder_config
)
相较于ALBEF,最大的不同,就是Learned Query的引入。可以看到这些Query通过Cross-Attention与图像的特征交互,通过Self-Attention与文本的特征交互。这样做的好处有两个:(1)这些Query是基于两种模态信息得到的;(2)无论多大的视觉Backbone,最后都是Query长度的特征输出,大大降低了计算量。比如在实际实验中,ViT-L/14的模型的输出的特征是257x1024的大小,最后也是32x768的Query特征。

图像 transformer 从图像编码器中提取固定数量的输出特征,这里特征的个数与输入图像分辨率无关。同时,图像 transformer 接收若干查询嵌入作为输入,这些查询嵌入是可训练的。这些查询还可以通过相同的自注意力层与文本进行交互 (这里的相同是指图像 transformer 和文本 transformer 对应的自注意力层是共享的)。
Q- Former如何工作(queries是Q-former中的一个可学习参数)
具体结合方式
该结构能够和目标函数一起促进 query 来提取更和 text 相关的视觉信息
首先,使用全连接层来对 output query embedding Z ZZ 进行线性映射,将其映射为何 LLM 的text embedding 相同的维度
映射后的 query embedding 放到 text embedding 的前面
将其作为 soft visual prompts 的功能,使用 Q-Former 提取出的视觉信息来过滤 LLM
Q-Former 分两个阶段进行预训练。
第一阶段
图像编码器被冻结,Q-Former 通过三个损失函数进行训练:
- 图文对比损失 (image-text contrastive loss): 每个查询的输出都与文本输出的 CLS 词元计算成对相似度,并从中选择相似度最高的一个最终计算对比损失。在该损失函数下,查询嵌入和文本不会 “看到” 彼此。
- 基于图像的文本生成损失: Query内部可以相互计算注意力但不计算文本词元对查询的注意力,同时文本内部的自注意力使用因果掩码且需计算所有Query对文本的注意力。
- 图文匹配损失 (image-text matching loss): 查询和文本可以看到彼此,最终获得一个几率 (logit) 用以表示文字与图像是否匹配。这里,使用hard negative mining来生成负样本。
实际上,这几个任务都是以Query特征和文本特征作为输入得到的,只不过有不同的Mask组合
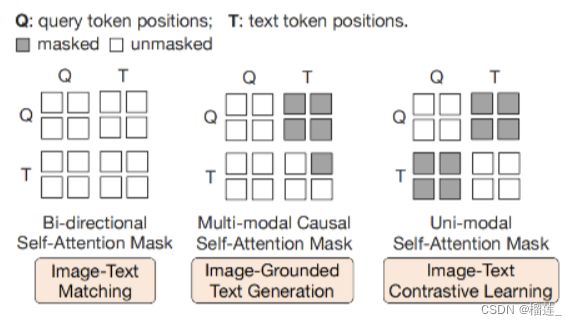
通过第一阶段的训练,Query已经浓缩了图片的精华,现在要做的,就是把Query变成LLM认识的样子。
**为什么不让LLM认识Query,而让Query变成LLM认识呢?**这里的原因有两:(1)LLM模型的训练代价有点大;(2)从 Prompt Learning 的观点来看,目前多模态的数据量不足以保证LLM训练的更好,反而可能会让其丧失泛化性。如果不能让模型适应任务,那就让任务来适应模型。
第二阶段
这里作者针对两类不同LLM设计了不同的任务:
- Decoder类型的LLM(如OPT):以Query做输入,文本做目标;
- Encoder-Decoder类型的LLM(如FlanT5):以Query和一句话的前半段做输入,以后半段做目标;
为了适合各模型不同的Embedding维度,作者引入了一个FC层做维度变换。
训练细节
作为图文预训练的工作,工程问题往往是关键。BLIP2的训练过程主要由以下几个值得关注的点:
- 训练数据方面:包含常见的 COCO,VG,SBU,CC3M,CC12M 以及 115M的LAION400M中的图片。采用了BLIP中的CapFilt方法来Bootstrapping训练数据。
- CV模型:选择了CLIP的ViT-L/14和ViT-G/14,特别的是,作者采用倒数第二层的特征作为输出。
- LLM模型:选择了OPT和FlanT5的一些不同规模的模型。
- 训练时,CV模型和LLM都是冻结的状态,并且参数都转为了FP16。这使得模型的计算量大幅度降低。主要训练的基于BERT-base初始化的Q-Former只有188M的参数量。
- 最大的模型,ViT-G/14和FlanT5-XXL,只需要16卡A100 40G,训练6+3天就可以完成。
- 所有的图片都被缩放到224x224的大小。
InstructBLIP
所有模型都使用16个Nvidia A100(40G)GPU进行训练,并在两天内完成训练。
论文:https://arxiv.org/pdf/2305.06500.pdf
代码:https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
数据集:https://opensource.salesforce.com/LAVIS//latest/benchmark
本文提出了InstructBLIP,一种视觉语言指导微调框架(vision-language instruction tuning framework),通过统一的自然语言界面使通用模型能够解决广泛的视觉任务。InstructBLIP从预训练的BLIP-2模型初始化,该模型包含图像编码器、LLM和Q-Former来连接两者。在指导微调过程中,我们微调Q-Former,同时保持图像编码器和LLM冻结。本文的主要贡献如下:
• 我们对视觉语言指导微调进行了全面系统的研究。我们将26个数据集转换为指导微调格式,并将其分为11个任务类别。其中,13个内部数据集用于指导微调,13个外部数据集用于零样本评估。此外,我们有意保留了四个任务类别用于任务级零样本评估。详尽的定量和定性结果证明了InstructBLIP在视觉语言零样本泛化上的有效性。
代码开源数据库:LAVIS 框架全方位支持 10+ 视觉语言任务,20+ 数据集,并提供 SOTA 模型性能和可复现预训练及微调实验配置。LAVIS 一大特点是统一和模块化的接口设计,极大降低训练、推理和开发的难度,致力于让研究和工程人员快速利用到近期多模态发展成果。

现有的零样本图像到文本生成的方法(包括BLIP-2)都是不考虑指令的,即视觉输入与指令无关,这降低了模型在不同任务上的灵活性。为了解决这个问题,InstructBLIP提出了一种指令感知的视觉特征提取方法Q-Former。Q-Former利用BLIP-2模型中的Q-Former结构,从固定的图像编码器的输出中提取视觉特征。在预训练阶段,Q-Former学习提取与文本对齐的视觉特征。在InstructBLIP中,指令文本不仅被输入到LLM中,还被输入到Q-Former中,提取查询向量提取更符合指令的视觉特征,进而提高模型性能。作者在上表2中展示了指令感知的视觉特征提取在内部和外部评估中带来了明显的性能提升。
使用的模型
InstructBLIP 的 LLM 作者使用了 FlanT5-XL (3B), FlanT5-XXL (11B), Vicuna-7B 和 Vicuna-13B 这四种,视觉编码器使用的是 ViT-g/14。FlanT5[1] 是一个基于 Encoder-Decoder Transformer T5 的指令微调模型,Vicuna[2] 是一个基于 Decoder LLaMa 的微调模型。
数据集构造
InstructBLIP 这个工作介绍了如何把指令微调的范式做在 BLIP-2 模型上面。用指令微调方法的时候会额外有一条 instruction,如何借助这个 instruction 提取更有用的视觉特征是本文的亮点之一。对于每个任务,作者精心制作了10-15个自然语言指令模板,如下图2所示。这些模板阐明了任务并描述了目标。对于一些偏爱简短响应的数据集,作者刻意地在 instruction 中添加了 “short answer”, “as short as possible” 字样来减小模型过拟合的风险,防止其始终生成很短的输出。
最终收集了11个任务类别和28个数据集,包括图像字幕、图像字幕阅读理解、视觉推理、图像问答、知识驱动的图像问答、图像问答阅读理解、图像问答生成、视频问答、视觉对话问答、图像分类和 LLaVA-Instruct-150K 数据集等。
训练和评估协议 (Training and Evaluation Protocols)
为了在训练中涵盖广泛的任务,并同时保留足够的未见数据进行全面的零样本评估,我们将这26个数据集划分为13个内部数据集和13个外部数据集,分别用黄色和白色表示(见图2)。我们将内部数据集的训练集用于指导微调,并利用它们的验证集或测试集进行内部评估。
对于外部评估,我们的目标是了解指导微调如何改进模型在未见数据上的零样本泛化性能。在本文中,我们定义了两种类型的外部数据:1)在训练过程中模型没有接触到的数据集,但其任务存在于内部数据集群中;2)在训练过程中完全未见到的数据集及其相关任务。
由于内部和外部数据集之间存在图像分布差异,解决第一类型的外部评估是非常困难的。至于第二类型的外部评估,我们完全保留了一些任务,包括视觉推理、视频问答、视觉对话问答和图像分类。为了避免数据污染,我们精心选择数据集(不同数据集在内部训练集群中没有评估数据)。在指导微调过程中,我们混合了所有内部训练集,并针对每个数据集均匀采样指令模板。**模型使用标准的语言建模损失进行训练,以直接生成给定指令的响应。**此外,对于涉及场景文本的数据集,我们在指令中添加OCR标记作为补充信息。
数据采样方法- Balance Training Datasets


由于训练数据集数量众多,每个数据集的大小存在显着差异,均匀混合它们可能会导致模型过度拟合较小的数据集并欠拟合更大的数据集。为了缓解这个问题,我们建议对概率与其大小的平方根成正比的数据集进行采样,或者训练样本的数量。
Framework
InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。作者将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。

InstructBLIP中,指令文本不仅作为输入提供给LLM,也提供给Q-Former。指令通过Q-Former的自注意力层与查询进行交互,影响查询提取与指令所描述的任务更相关的图像特征。因此,LLM接收到更有用的视觉信息,以完成任务:和 BLIP-2 保持一致,依然由视觉编码器,Q-Former 和 LLM 组成。视觉编码器提取输入图片的特征,并喂入 Q-Former 中。此外,Q-Former 的输入还包括可学习的 Queries (BLIP-2 的做法) 和 Instruction。Q-Former 的内部结构如图3黄色部分所示,其中可学习的 Queries 通过 Self-Attention 和 Instruction 交互,可学习的 Queries 通过 Cross-Attention 和输入图片的特征交互,鼓励提取与任务相关的图像特征。
Q-Former 的输出通过一个 FC 层送入 LLM,Q-Former 的预训练过程遵循 BLIP-2 的两步:1) 不用 LLM,固定视觉编码器的参数预训练 Q-Former 的参数,训练目标是视觉语言建模。2) 固定 LLM 的参数,训练 Q-Former 的参数,训练目标是文本生成。
推理方法
在推理阶段,我们针对不同的数据集采用了略有不同的生成方法进行评估。对于大多数数据集,如图像描述和开放式VQA,指导微调模型直接生成响应,然后将其与参考答案进行比较以计算指标。另一方面,对于分类和多选VQA任务,我们采用了一个词汇排序方法。具体而言,我们仍然提示模型生成答案,但将其词汇限制在候选列表中。然后,我们计算每个候选项的对数似然,并选择具有最高值的候选项作为最终预测。此排名方法适用于ScienceQA、IconQA、A-OKVQA(多选)、HatefulMemes和Visual Dialog数据集。此外,对于二分类,将正类和负类标签扩展为更广泛的词汇集,以更有效地适应模型的语言建模概率质量(例如,正类的词汇集包括yes和true,负类的词汇集包括no和false)。
对于视频问答任务,我们每个视频样本均匀采样四个帧。每个帧分别由图像编码器和Q-Former进行处理,它们的查询嵌入结果在馈入LLM之前连接在一起。
miniGPT-4
MiniGPT-4 项目基于 *BLIP2*、*Lavis* 和 *Vicuna* 进行构建
论文链接:https://arxiv.org/abs/2304.10592
代码链接:https://github.com/Vision-CAIR/MiniGPT-4
数据构造
一共分为两个阶段
第一阶段数据集
传统图文对数据集Conceptual Caption, SBU和LAION(预训练)

img2dataset库可以直接下载数据集使用:https://zhuanlan.zhihu.com/p/627671257(微调)
cd ${MINIGPT4_DATASET}/cc_sbu
sh download_cc_sbu.sh
cd ${MINIGPT4_DATASET}/laion
sh download_laion.sh
第二阶段数据集
3500对高质量数据集
https://drive.google.com/file/d/1nJXhoEcy3KTExr17I7BXqY5Y9Lx_-n-9/view
虽然在自然语言处理领域,指令微调数据集和对话相关数据集很容易获得,但对于视觉语言领域来说,并不存在对应的数据集,所以为了让MiniGPT-4在生成文本时更自然、更有用,还需要设计一个高质量的、对齐的图像-文本数据集。
在初始阶段,使用预训练后得到的模型来生成对给定图像的描述,为了使模型能够生成更详细的图像描述,研究人员还设计了一个符合Vicuna语言模型的对话格式的提示符。
###Human: Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
其中表示线性投影层生成的视觉特征,如果生成的描述不足80个tokens,就添加额外的提示符「#Human:Continue#Assistant:」继续生成。
最后从Conceptual Caption中随机选择了5000幅图像,并生成对应的描述。
数据后处理
目前生成的图像描述仍然包含许多噪音和错误,如重复的单词、不连贯的句子等,研究人员使用ChatGPT来完善描述。
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
修正给定段落中的错误。删除重复的句子、无意义的字符、不是英语的句子等等。删除不必要的重复。重写不完整的句子。直接返回结果,无需解释。如果输入的段落已经正确,则直接返回,无需解释。
最后为了保证数据质量,手动验证每个图像描述的正确性,并得到了3500个图像-文本对
framework
MiniGPT-4 仅使用一个投影层将一个冻结的视觉编码器(BLIP-2)与一个冻结的 LLM(Vicuna)对齐。除此之外,此方法计算效率很高,因为它仅使用大约 500 万个对齐的图像-文本对和额外的 3,500 个经过精心策划的高质量图像-文本对来训练一个投影层。

- CV 部分采用了 EVA、BEIT、timm 和 DeiT。其中,EVA 来自智源研究院,BEIT 来自微软,DeiT 则来自 Facebook,充分体现了开源世界合作的力量。
- NLP 部分采用了 LLaMA
训练方式
MiniGPT-4 的模型架构遵循 BLIP-2,因此,训练 MiniGPT-4 分两个阶段。
第一阶段
目标通过大量图文对数据学习视觉和语言的关系以及知识,采用CC+SBU+LAION数据集,冻住视觉编码器和文本解码器,只训练线性映射层;
第一个传统预训练阶段使用 4 张 A100 卡在 10 小时内使用大约 500 万个对齐的图像-文本对进行训练。 在第一阶段之后,Vicuna 虽然能够理解图像。 但是Vicuna的生成能力受到了很大的影响。
为了解决这个问题并提高可用性,MiniGPT-4 提出了一种通过模型本身和 ChatGPT 一起创建高质量图像文本对的新方法。 基于此,MiniGPT-4 随后创建了一个小规模(总共 3500 对)但高质量的数据集。
第二阶段
作者发现只有第一阶段的预训练并不能让模型生成流畅且丰富的符合用户需求的文本,为了缓解这个问题,本文也额外利用ChatGPT构建一个多模态微调数据集。具体来说,1)其首先用阶段1的模型对5k个CC的图片进行描述,如果长度小于80,通过prompt让模型继续描述,将多步生成的结果合并为一个描述;2)通过ChatGPT对于构建的长描述进行改写,移除重复等问题;3)人工验证以及优化描述质量。最后得到3.5k图文对,用于第二阶段的微调。第二阶段同样只训练线性映射层。
第二个微调阶段在对话模板中对该数据集进行训练,以显著提高其生成的可靠性和整体的可用性。
研究人员使用预定义的模板提示来优化预训练模型。
###Human: ###Assistant
其中表示从预定义指令集中随机抽样的指令,包含各种形式的指令,例如「详细描述此图像」或「您能为我描述此图像的内容吗」等。
需要注意的是,微调阶段没有计算特定文本-图像提示的回归损失,所以可以生成更自然、可靠的回复。
MiniGPT-4的微调过程非常高效,batch size为12的话,只需要400个训练步,使用单个A100 GPU训练7分钟即可。
OpenFlamingo
论文:https://arxiv.org/pdf/2204.14198.pdf
代码:https://github.com/mlfoundations/open_flamingo
OpenFlamingo 从根本上说是一个允许训练和评估大型多模态模型 (LMM) 的框架。 OpenFlamingo 建立在CLIP的ViT/L-14和 Meta AI 开发的 LLaMA 大型语言模型之上。
该实现与 Flamingo 的实现非常相似。 Flamingo 模型必须在具有交错文本和图形的大规模网络数据集上进行训练,以使它们具备上下文中的少样本学习技能。 在 OpenFlamingo 中实现了与原始 Flamingo 研究(感知器重采样器、交叉注意层)中建议的相同架构。 但是,由于 Flamingo 的训练数据无法向公众开放,因此开发人员使用开源数据集来训练模型。 新发布的 OpenFlamingo-9B 检查点专门针对来自 LAION-10B 的 2 万个样本和来自新的 Multimodal C5 数据集的 4 万个样本进行了训练。
数据集
使用多模式 C4 数据集的 500 万个样本和来自LAION-2B的 1000 万个样本上进行训练的。
Multimodal-C4 数据集是纯文本C4 数据集的扩展,用于训练 T5 模型。对于C4 en.clean数据集中的每个文档,我们从Common Crawl检索原始网页,然后收集可下载的图像。数据清理是通过重复数据删除和内容过滤进行的,旨在消除不安全的工作(NSFW)和不相关的图像,例如广告。此外,我们运行人脸检测并丢弃具有正面识别的图像。最后,图像和句子在文档中使用二分匹配交错:CLIP ViT/L-14 图像-文本相似性作为边缘权重。Multimodal-C4 包含大约 7500 万个文档,包括大约 4 亿张图像和 38B 个标记。
framework
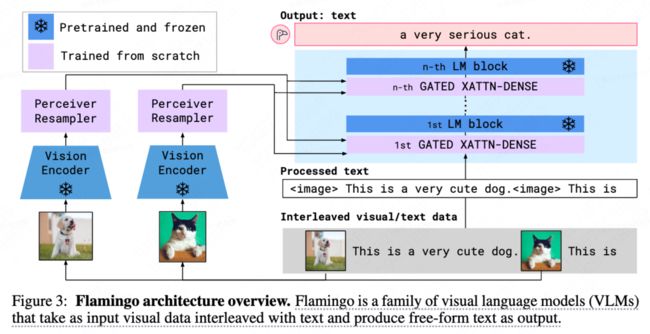
使用的是Flamingo的框架,只是训练数据有所不同。
Otter: A Multi-Modal Model with In-Context Instruction Tuning
论文:https://arxiv.org/abs/2305.03726
代码:https://github.com/Luodian/Otter
这篇文章主要关注 Multimodal LLMs 的 in-context learning 的研究。
in-context learning: 在LLMs 中,将 in-context leanring 的能力归结为是一种涌现能力。但是这种涌现能力也是在基于一定规模的参数量和数据量才能“涌现”出来的。
Multimodal LLMs: 目前已有的一些研究,如 miniGPT-4, LLAVA, mPLUG-owl 等这些均没有考虑 in-context learning 的能力。但是由于多模态的数据量远远抵不上训练LLMs时使用的数据量,所以完全靠涌现,并不太靠谱。
所以这篇文章就是希望在 Multimodal LLMs的训练过程中,人为的设计一些 in-context example, 将这种 in-context learning 的能力显式的学习到。
已有的工作
Flamingo 在预训练过程中考虑到 in-context learning 这回事了。具体地,其使用基于网页的数据,多个图片和多个文字 错落分布(interleaved ),基于这种数据学习,可以获得期望的 in-context learning 的能力。
本文的工作
但是,Flamingo 仅在预训练过程中考虑了这一点。对于 Multimodal LLMs, 还需要在第二阶段的 instruction tuning 时考虑到这种 in-context learning 能力的训练。那么这里就涉及到相应的数据和训练,即本文的贡献点:
- MultI-Modal In-Context Instruction Tuning (MIMIC-IT) dataset
- Otter, a multi-modal model with in-context instruction tuning based on OpenFlamingo
数据集
- MultI-Modal In-Context Instruction Tuning (MIMIC-IT) dataset
(1)image-instruction-answer triplets 的构建,这里使用了三类数据集:
- QA:VQAv2, GQA,
- visual instruction dataset: LLAVA dataset
- video scene graph dataset: PVSG
(2)in-context examples 的构建,本文设计了三种启发式的方式来构建这部分数据,如下图(b)所示:
Framework
- Otter, a multi-modal model with in-context instruction tuning based on OpenFlamingo

训练
加载openflamingo 的预训练参数,然后仅微调 the Perceiver resampler module, cross-attention layers inserted into the language encoder and input/output embeddings of the language encoder。

LLAVA
Visual Instruction Tuning Paper:https://arxiv.org/pdf/2304.08485.pdf
Code:https://github.com/haotian-liu/LLaVA
LLaVa 使用简单的投影矩阵连接预先训练好的 CLIP ViT-L/14 视觉编码器和大型语言模型 Vicuna,研究者们设计了一个两阶段的指令调整过程:
第 1 阶段:特征对齐的预训练。仅基于 CC3M 的子集更新投影矩阵。
第 2 阶段:端到端微调。投影矩阵和LLM都针对两种不同的用途进行了更新
可视化聊天:LLaVA根据研究者生成的多模态指令跟踪数据进行了微调,用于日常面向用户的应用程序。
科学QA:LLaVA对科学领域的多模态推理数据集进行了微调。
LLaVA最重要的部分是它如何构建高质量的多模式指示数据(multimodal instruction-following dataset),LLaVA的解决方案是采用GPT-4/ChatGPT来生成这样的数据集,这里并不是依赖GPT-4的多模态能力,而是只用GPT-4的文本理解和生成能力。
数据集
ScienceQA 包含 21k 个多模态多选问题,涉及 3 个主题、26 个话题、127 个类别和 379 种技能,具有丰富的领域多样性。基准数据集分为训练、验证和测试部分,分别有 12726、4241 和 4241 个样本。
自然语言处理领域的instruction tuning可以帮助LLM理解多样化的指令并生成比较详细的回答。LLaVA首次尝试构建图文相关的instruction tuning数据集来将LLM拓展到多模态领域。具体来说,基于MSCOCO数据集,每张图有5个较简短的ground truth描述和object bbox(包括类别和位置)序列,将这些作为text-only GPT4的输入,**通过prompt的形式让GPT4生成3种类型的文本:1)关于图像中对象的对话;2)针对图片的详细描述;3)和图片相关的复杂的推理过程。**注意,这三种类型都是GPT4在不看到图片的情况下根据输入的文本生成的,为了让GPT4理解这些意图,作者额外人工标注了一些样例用于in-context learning。
Framework

模型结构:采用CLIP的ViT-L/14作为视觉编码器,采用LLaMA作为文本解码器,通过一个简单的线性映射层将视觉编码器的输出映射到文本解码器的词嵌入空间,如图。
对于图文的融合,本文使用一个简单的线性层来将图像特征连接到单词嵌入空间中。具体而言,应用可训练投影矩阵 W 将 Z_v 转换为语言嵌入标记 H_q,H_q 具有与语言模型中的单词嵌入空间相同的维度:

结合GPT-4优异的文字能力,将原始数据构造成结构化的文本信息作为Context,同时通过prompt template请求GPT-4得到一些结果,来生成原始的instruction data。在训练时,则可加入visual token,以得到align后的instruction-tuned model
模型训练1/ 第一阶段:跨模态对齐预训练,从CC3M中通过限制caption中名词词组的最小频率过滤出595k图文数据,冻住视觉编码器和文本解码器,只训练线性映射层;2. 第二阶段:指令微调,一版针对多模态聊天机器人场景,采用自己构建的158k多模态指令数据集进行微调;另一版针对Science QA数据集进行微调。微调阶段,线性层和文本解码器(LLaMA)都会进行优化。
训练-next token prediction
模型训练1/ 第一阶段:跨模态对齐预训练,从CC3M中通过限制caption中名词词组的最小频率过滤出595k图文数据,冻住视觉编码器和文本解码器,只训练线性映射层;2. 第二阶段:指令微调,一版针对多模态聊天机器人场景,采用自己构建的158k多模态指令数据集进行微调;另一版针对Science QA数据集进行微调。微调阶段,线性层和文本解码器(LLaMA)都会进行优化。

实验分析
消融实验: 在30个MSCOCO val的图片上,每张图片设计3个问题(对话、详细描述、推理),参考 Vicuna[8],用GPT4对LLaVA和text-only GPT4的回复进行对比打分,报告相对text-only GPT4的相对值
SOTA对比: 在Science QA上微调的版本实现了该评测集上的SOTA效果。
mPLUG-owl
该研究的代码、预训练模型、指令调整模型和评估集可以在https://github.com/X-PLUG/mPLUG-Owl上获得。在线演示可在https://www.modelscope.cn/studios/damo/mPLUG-Owl上获得。
mPLUG-Owl是阿里巴巴达摩院mPLUG系列的最新工作,继续延续mPLUG系列的模块化训练思想,将LLM迁移为一个多模态大模型。此外,Owl第一次针对视觉相关的指令评测提出一个全面的测试集OwlEval,通过人工评测对比了已有工作,包括LLaVA和MIniGPT4。该评测集以及人工打分的结果都进行了开源,助力后续多模态开放式回答的公平对比。
模型结构:采用CLIP ViT-L/14作为"视觉基础模块",采用LLaMA初始化的结构作为文本解码器,采用类似Flamingo的Perceiver Resampler结构对视觉特征进行重组(名为"视觉摘要模块"),如图。
模型训练
- 第一阶段: 主要目的也是先学习视觉和语言模态间的对齐。不同于前两个工作,Owl提出冻住视觉基础模块会限制模型关联视觉知识和文本知识的能力。因此Owl在第一阶段只冻住LLM的参数,采用LAION-400M,COYO-700M,CC以及MSCOCO训练视觉基础模块和视觉摘要模块。
- 第二阶段: 延续mPLUG和mPLUG-2中不同模态混合训练对彼此有收益的发现,Owl在第二阶段的指令微调训练中也同时采用了纯文本的指令数据(102k from Alpaca+90k from Vicuna+50k from Baize)和多模态的指令数据(150k from LLaVA)。作者通过详细的消融实验验证了引入纯文本指令微调在指令理解等方面带来的收益。第二阶段中视觉基础模块、视觉摘要模块和原始LLM的参数都被冻住,参考LoRA,只在LLM引入少量参数的adapter结构用于指令微调。
framework
多模态GPT一般都由两部分组成,视觉编码器和语言模型LLM,训练也分两阶段:预训练和instruction tuning。下图列举了mplug和之前模型在训练策略的一些区别,mplug会在第一阶段微调视觉编码器,第二阶段微调语言模型。之前的模型冻结了大部分模块,只微调少量参数,会导致有限的跨模态对齐能力。

本研究介绍了一种名为mPLUG-Owl的新型训练范式,主要在于训练数据的不同,而且两个阶段更新的参数不同。模型结构和训练策略如下。有三个模块组成:视觉编码器、语言模型和起到过渡作用的visual abstractor。视觉编码器提取视觉知识,由于patch序列长度导致后续LLM的高计算复杂度,所以引入abstractor,通过一些可学习的token序列提取得到视觉信息的高级语义信息。一方面序列长度变短,降低复杂度,另一方面相当于把视觉域的特征转换到语言域。然后把这些token和问题文本一起送入LLM。
实验分析
除了训练策略,mPLUG-Owl另一个重要的贡献在于通过构建OwlEval评测集,对比了目前将LLM用于多模态指令回答的SOTA模型的效果。和NLP领域一样,在指令理解场景中,模型的回答由于开放性很难进行评估。
SOTA对比:本文初次尝试构建了一个基于50张图片(21张来自MiniGPT-4, 13张来自MM-REACT, 9张来自BLIP-2, 3来自GPT-4以及4张自收集)的82个视觉相关的指令回答评测集OwlEval。由于目前并没有合适的自动化指标,本文参考Self-Intruct对模型的回复进行人工评测,打分规则为:A=“正确且令人满意”;B=“有一些不完美,但可以接受”;C=“理解了指令但是回复存在明显错误”;D=“完全不相关或不正确的回复”。实验证明Owl在视觉相关的指令回复任务上优于已有的OpenFlamingo、BLIP2、LLaVA、MiniGPT4以及集成了Microsoft 多个API的MM-REACT。作者对这些人工评测的打分同样进行了开源以方便其他研究人员检验人工评测的客观性。
多维度能力对比:多模态指令回复任务中牵扯到多种能力,例如指令理解、视觉理解、图片上文字理解以及推理等。为了细粒度地探究模型在不同能力上的水平,本文进一步定义了多模态场景中的6种主要的能力,并对OwlEval每个测试指令人工标注了相关的能力要求以及模型的回复中体现了哪些能力。在该部分实验,作者既进行了Owl的消融实验,验证了训练策略和多模态指令微调数据的有效性,也和上一个实验中表现最佳的baseline——MiniGPT4进行了对比,结果显示Owl在各个能力方面都优于MiniGPT4。
Frozen
Multimodal Few-Shot Learning with Frozen Language Models.
Frozen训练时将图片编码成2个vision token,作为LLM的前缀,目标为生成后续文本,采用Conceptual Caption作为训练语料。Frozen通过few-shot learning/in-context learning做下游VQA以及image classification的效果还没有很强,但是已经能观察到一些多模态in-context learning的能力。
VisualGLM
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisualGLM-6B 依靠来自于 CogView 数据集的30M高质量中文图文对,与300M经过筛选的英文图文对进行预训练,中英文权重相同。该训练方式较好地将视觉信息对齐到ChatGLM的语义空间;之后的微调阶段,模型在长视觉问答数据上训练,以生成符合人类偏好的答案。
PICA
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
以PICA为例,它的目标是充分利用LLM中的海量知识来做Knowledge-based QA。给定一张图和问题,以往的工作主要从外部来源,例如维基百科等来检索出相关的背景知识以辅助答案的生成。但PICA尝试将图片用文本的形式描述出来后,直接和问题拼在一起作为LLM的输入,让LLM通过in-context learning的方式直接生成回答,如图所示。
Shikra
论文:https://arxiv.org/pdf/2306.15195.pdf
代码:https://github.com/shikras/shikra
- Shikra 能够理解用户输入的 Point/Box,并支持 Point/Box 的输出,可以和人类无缝地进行参考对话;
- Shikra 设计简单统一,采用非拼接式设计,直接使用数字表示坐标,不需要额外的位置编码器、前/后目标检测器或外部插件模块,甚至不需要额外的词汇表。
framework

模型架构采用CLIP ViT-L/14 作为视觉主干,Vicuna-7/13B 作为语言基模型,使用一层线性映射连接CLIP和Vicuna的特征空间。
Shikra 直接使用自然语言中的数字来表示物体位置,使用[xmin, ymin, xmax, ymax] 表示边界框,使用[xcenter, ycenter]表示中心点,xy 坐标根据图像大小进行归一化,每个数字默认保留 3 位小数,这些坐标可以出现在模型的输入和输出序列中的任何位置,记录坐标的方括号也自然地出现在句子中。在论文中,本工作也尝试使用其他方式进行数值表示,并做了定量的对比实验。(不实用Vocab约束的形式而是直接使用数值)
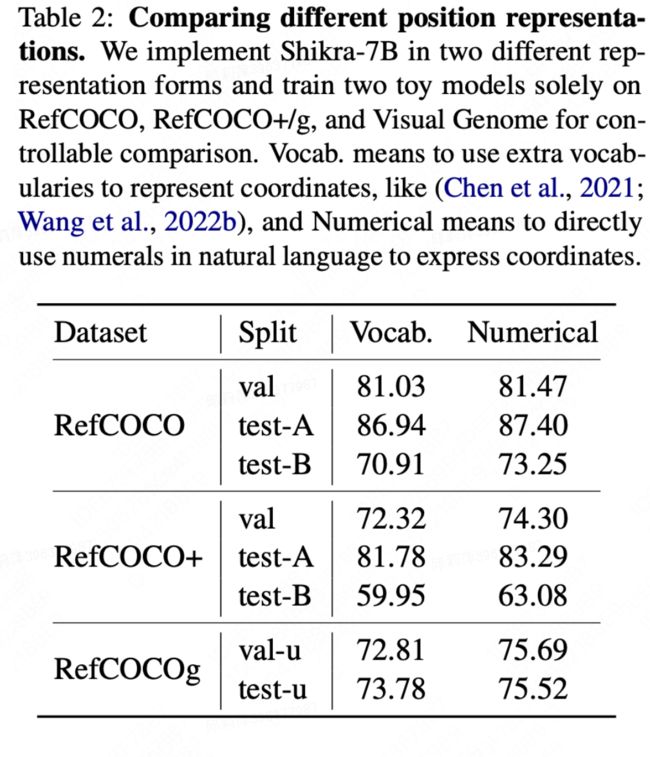
训练
思维链形式
思想链(CoT),旨在通过在最终答案前添加推理过程以帮助LLM回答复杂的QA问题。这一技术已被广泛应用到自然语言处理的各种任务中。目前的MLLM还存在严重的幻视问题,CoT也经常会产生幻觉,影响最终答案的正确性。通过在合成数据集CLEVR上的实验,本工作发现,使用带有位置信息的CoT时,可以提升模型回答的准确率。
LAVIN
如上图所示,LaVIN基于LLaMA来进行微调,整体结构非常简洁。
- 端到端联合优化架构。CLIP的backbone直接接到LLaMA,没有其它复杂的设计。整个CLIP和LLM是完全冻住的,通过加入adapter来进行训练。同时,通过在CLIP中插入了adapter,使得整个模型能够被端到端优化。相比于LLaVA,这种端到端优化节省了CLIP和LLM之间对齐的预训练过程。
- 多模态动态推理。在大语言模型中,本文设计了一个新的模块叫Mixture-of-modality adapter。这个模块能够根据输入指令的模态来切换adapter的推理路径。通过这种方式,能够实现两种模态训练时的解耦。简单来说,当输入文本指令时,模型会使用一组adapter路径来进行适配。当输入的是图像+文本指令时,模型会切换到另外一组adapter路径来进行推理。
- 多模态混合训练。在训练过程中,LaVIN直接将纯文本数据和图文数据混合,直接打包成batch进行训练。除此之外,没有额外的优化过程和其他复杂的设计。
OFA
https://www.gkwang.net/019_ofa/
https://github.com/OFA-Sys/OFA
图片的离散化

Byte-Pair Encoding vocabulary
字节对编码(BPE, Byte Pair Encoder),又称 digram coding 双字母组合编码,是一种数据压缩 算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前它是最流行的方法。BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。
合并字符可以让你用最少的token来表示语料库,这也是 BPE 算法的主要目标,即数据的压缩。为了合并,BPE 寻找最常出现的字节对。在这里,我们将字符视为与字节等价。当然,这只是英语的用法,其他语言可能有所不同。现在我们将最常见的字节对合并成一个token,并将它们添加到token列表中,并重新计算每个token出现的频率。这意味着我们的频率计数将在每个合并步骤后发生变化。我们将继续执行此合并步骤,直到达到我们预先设置的token数限制或迭代限制。
CLIP使用的tokenizer:bpe_simple_vocab_16e6.txt.gz
LLAMA使用的也是:bytepair encoding (BPE)
dataset = FileDataset(file_path, self.cfg.selected_cols)
self.datasets[split] = RefcocoDataset(
split,
dataset,
self.bpe,
self.src_dict,
self.tgt_dict,
max_src_length=self.cfg.max_src_length,
max_tgt_length=self.cfg.max_tgt_length,
patch_image_size=self.cfg.patch_image_size,
imagenet_default_mean_and_std=self.cfg.imagenet_default_mean_and_std,
num_bins=self.cfg.num_bins,
max_image_size=self.cfg.max_image_size
)
可以看到这里使用的是float型的坐标
=========refcoco_dataset文件中的__getitem__========
OFADataset
init
self.bos_item = torch.LongTensor([self.bos])
self.eos_item = torch.LongTensor([self.eos])
def encode_text(self, text, length=None, append_bos=False, append_eos=False, use_bpe=True):
s = self.tgt_dict.encode_line(
line=self.bpe.encode(text) if use_bpe else text,
add_if_not_exist=False,
append_eos=False
).long()
if length is not None:
s = s[:length]
if append_bos:
s = torch.cat([self.bos_item, s])
if append_eos:
s = torch.cat([s, self.eos_item])
return s
class RefcocoDataset(OFADataset):
def __init__()
self.positioning_transform = T.Compose([
T.RandomResize([patch_image_size], max_size=patch_image_size),
T.ToTensor(),
T.Normalize(mean=mean, std=std, max_image_size=max_image_size)
])
def __getitem__(self, index):
uniq_id, base64_str, text, region_coord = self.dataset[index]
image = Image.open(BytesIO(base64.urlsafe_b64decode(base64_str))).convert("RGB")
w, h = image.size
boxes_target = {"boxes": [], "labels": [], "area": [], "size": torch.tensor([h, w])}
x0, y0, x1, y1 = region_coord.strip().split(',')
region = torch.tensor([float(x0), float(y0), float(x1), float(y1)])
boxes_target["boxes"] = torch.tensor([[float(x0), float(y0), float(x1), float(y1)]])
boxes_target["labels"] = np.array([0])
boxes_target["area"] = torch.tensor([(float(x1) - float(x0)) * (float(y1) - float(y0))])
patch_image, patch_boxes = self.positioning_transform(image, boxes_target)
resize_h, resize_w = patch_boxes["size"][0], patch_boxes["size"][1]
patch_mask = torch.tensor([True])
quant_x0 = "".format(int((patch_boxes["boxes"][0][0] * (self.num_bins - 1)).round()))
quant_y0 = "".format(int((patch_boxes["boxes"][0][1] * (self.num_bins - 1)).round()))
quant_x1 = "".format(int((patch_boxes["boxes"][0][2] * (self.num_bins - 1)).round()))
quant_y1 = "".format(int((patch_boxes["boxes"][0][3] * (self.num_bins - 1)).round()))
region_coord = "{} {} {} {}".format(quant_x0, quant_y0, quant_x1, quant_y1)
src_caption = self.pre_caption(text, self.max_src_length)
src_item = self.encode_text(self.prompt.format(src_caption))
tgt_item = self.encode_text(region_coord, use_bpe=False)
src_item = torch.cat([self.bos_item, src_item, self.eos_item])
target_item = torch.cat([tgt_item, self.eos_item])
prev_output_item = torch.cat([self.bos_item, tgt_item])
example = {
"id": uniq_id,
"source": src_item,
"patch_image": patch_image,
"patch_mask": patch_mask,
"target": target_item,
"prev_output_tokens": prev_output_item,
"w_resize_ratio": resize_w / w,
"h_resize_ratio": resize_h / h,
"region_coord": region
}
return example
输入输出
dict的数据是

def add_symbol(self, word, n=1, overwrite=False):
"""Adds a word to the dictionary"""
if word in self.indices and not overwrite:
idx = self.indices[word]
self.count[idx] = self.count[idx] + n
return idx
else:
idx = len(self.symbols)
self.indices[word] = idx
self.symbols.append(word)
self.count.append(n)
return idx
def load_dictionary(cls, filename):
"""Load the dictionary from the filename
Args:
filename (str): the filename
"""
dictionary = Dictionary.load(filename)
dictionary.add_symbol("")
return dictionary
src_dict = cls.load_dictionary(
os.path.join(cfg.bpe_dir, "dict.txt")
)
tgt_dict = cls.load_dictionary(
os.path.join(cfg.bpe_dir, "dict.txt")
)
src_dict.add_symbol("")
tgt_dict.add_symbol("")
for i in range(cfg.code_dict_size):
src_dict.add_symbol("".format(i))
tgt_dict.add_symbol("".format(i))
# quantization
for i in range(cfg.num_bins):
src_dict.add_symbol("".format(i))
tgt_dict.add_symbol("".format(i))
from omegaconf import DictConfig
"gpt2_vocab_bpe": os.path.join(self.cfg.bpe_dir, "vocab.bpe")
bpe_dict = DictConfig(bpe_dict)
self.bpe = self.build_bpe(bpe_dict)
def encode_text(self, text, length=None, append_bos=False, append_eos=False, use_bpe=True):
s = self.tgt_dict.encode_line(
line=self.bpe.encode(text) if use_bpe else text,
add_if_not_exist=False,
append_eos=False
).long()
if length is not None:
s = s[:length]
if append_bos:
s = torch.cat([self.bos_item, s])
if append_eos:
s = torch.cat([s, self.eos_item])
return s
encoder_out = self.encoder(
src_tokens,
src_lengths=src_lengths,
patch_images=patch_images,
patch_masks=patch_masks,
patch_images_2=patch_images_2,
token_embeddings=token_embeddings,
return_all_hiddens=return_all_hiddens,
sample_patch_num=sample_patch_num
)
x, extra = self.decoder(
prev_output_tokens,
code_masks=code_masks,
encoder_out=encoder_out,
features_only=features_only,
alignment_layer=alignment_layer,
alignment_heads=alignment_heads,
src_lengths=src_lengths,
return_all_hiddens=return_all_hiddens,
)
pad = self.encoder.padding_idx
if classification_head_name is not None:
prev_lengths = prev_output_tokens.ne(pad).sum(1)
gather_index = prev_lengths[:, None, None].expand(x.size(0), 1, x.size(2)) - 1
sentence_representation = x.gather(1, gather_index).squeeze()
if self.classification_heads[classification_head_name].use_two_images:
hidden_size = sentence_representation.size(1)
sentence_representation = sentence_representation.view(-1, hidden_size * 2)
for k, head in self.classification_heads.items():
# for torch script only supports iteration
if k == classification_head_name:
x = head(sentence_representation)
break
class RefcocoConfig(OFAConfig):
def build_model(self, cfg):
model = super().build_model(cfg)
if self.cfg.eval_acc:
gen_args = json.loads(self.cfg.eval_args)
self.sequence_generator = self.build_generator(
[model], Namespace(**gen_args)
)
if self.cfg.scst:
scst_args = json.loads(self.cfg.scst_args)
self.scst_generator = self.build_generator(
[model], Namespace(**scst_args)
)
return model
model阶段–这里面对词表进行了nn.Embedding,如
encoder_embed_tokens = cls.build_embedding(
args, src_dict, args.encoder_embed_dim, args.encoder_embed_path
)
fairseq代码库
https://github.com/facebookresearch/fairseq
https://zhuanlan.zhihu.com/p/401911300
https://fairseq.readthedocs.io/en/latest/
def build_decoder(cls, args, tgt_dict, embed_tokens):
return TransformerDecoder(
args,
tgt_dict,
embed_tokens,
no_encoder_attn=getattr(args, "no_cross_attention", False),
)
@classmethod
def build_model(cls, args, task):
"""Build a new model instance."""
# make sure all arguments are present in older models
base_architecture(args)
if args.encoder_layers_to_keep:
args.encoder_layers = len(args.encoder_layers_to_keep.split(","))
if args.decoder_layers_to_keep:
args.decoder_layers = len(args.decoder_layers_to_keep.split(","))
if getattr(args, "max_source_positions", None) is None:
args.max_source_positions = DEFAULT_MAX_SOURCE_POSITIONS
if getattr(args, "max_target_positions", None) is None:
args.max_target_positions = DEFAULT_MAX_TARGET_POSITIONS
src_dict, tgt_dict = task.source_dictionary, task.target_dictionary
if args.share_all_embeddings:
if src_dict != tgt_dict:
raise ValueError(
"--share-all-embeddings requires a joined dictionary")
if args.encoder_embed_dim != args.decoder_embed_dim:
raise ValueError(
"--share-all-embeddings requires --encoder-embed-dim to match --decoder-embed-dim"
)
if args.decoder_embed_path and (
args.decoder_embed_path != args.encoder_embed_path
):
raise ValueError(
"--share-all-embeddings not compatible with --decoder-embed-path"
)
encoder_embed_tokens = cls.build_embedding(
args, src_dict, args.encoder_embed_dim, args.encoder_embed_path
)
decoder_embed_tokens = encoder_embed_tokens
args.share_decoder_input_output_embed = True
else:
encoder_embed_tokens = cls.build_embedding(
args, src_dict, args.encoder_embed_dim, args.encoder_embed_path
)
decoder_embed_tokens = cls.build_embedding(
args, tgt_dict, args.decoder_embed_dim, args.decoder_embed_path
)
if getattr(
args,
"freeze_encoder_embedding",
False) or getattr(
args,
"encoder_prompt",
False) or getattr(
args,
"decoder_prompt",
False) or getattr(
args,
"adapter",
False):
encoder_embed_tokens.weight.requires_grad = False
if getattr(
args,
"freeze_decoder_embedding",
False) or getattr(
args,
"encoder_prompt",
False) or getattr(
args,
"decoder_prompt",
False) or getattr(
args,
"adapter",
False):
decoder_embed_tokens.weight.requires_grad = False
if getattr(args, "offload_activations", False):
args.checkpoint_activations = True # offloading implies checkpointing
encoder = cls.build_encoder(args, src_dict, encoder_embed_tokens)
decoder = cls.build_decoder(args, tgt_dict, decoder_embed_tokens)
if getattr(args, "encoder_prompt", False) or getattr(
args, "decoder_prompt", False):
encoder.requires_grad_(False)
decoder.requires_grad_(False)
if getattr(args, "encoder_prompt", False):
encoder.encoder_prompt_encoder.requires_grad_(True)
if getattr(args, "decoder_prompt", False):
decoder.decoder_prompt_encoder.requires_grad_(True)
if getattr(args, "adapter", False):
for idx, layer in enumerate(encoder.layers):
layer.adapter.requires_grad_(True)
for idx, layer in enumerate(decoder.layers):
layer.adapter.requires_grad_(True)
if not args.share_all_embeddings:
min_params_to_wrap = getattr(
args, "min_params_to_wrap", DEFAULT_MIN_PARAMS_TO_WRAP
)
# fsdp_wrap is a no-op when --ddp-backend != fully_sharded
encoder = fsdp_wrap(encoder, min_num_params=min_params_to_wrap)
decoder = fsdp_wrap(decoder, min_num_params=min_params_to_wrap)
return cls(args, encoder, decoder)
搜索词表的方法
self.search = (
search.BeamSearch(tgt_dict) if search_strategy is None else search_strategy
)
https://www.cnblogs.com/miners/p/14950681.html#beam-search-%E8%A7%A3%E7%A0%81

https://zhuanlan.zhihu.com/p/424631681
loss
adjust_label_smoothed_cross_entropy
思考
扩充词表的方式
https://www.cnblogs.com/xiximayou/p/17500806.html
https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E8%8A%82#%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C%E8%AF%8D%E8%A1%A8%E6%89%A9%E5%85%85
KOSMOS-2

一些开源库
https://github.com/open-mmlab/mmdetection
模型和指令微调方法:https://blog.csdn.net/qq_35812205/article/details/130443994
一些榜单
https://opencompass.org.cn/leaderboard-multimodal
https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
其他相关链接
Pix2Seq:https://nicehuster.github.io/2022/07/18/pix2seq/(通过量化连续图像坐标,将box和cls转换为一系列离散token)
LLM解码生成文本: https://zhuanlan.zhihu.com/p/624845975
大模型与LLM语言分析:https://www.cnblogs.com/wujianming-110117/p/17462213.html
其他LLM文章
LLAMA
https://zhuanlan.zhihu.com/p/648365207
LLAMA2现在也出现了
Vicuna(LLM)
Vicuna 是通过使用从 ShareGPT.com 使用公共 API 收集的大约 7万 用户共享对话微调 LLaMA 基础模型创建的。为了确保数据质量,将 HTML 转换回 markdown 并过滤掉一些不合适或低质量的样本。此外,将冗长的对话分成更小的部分,以适应模型的最大上下文长度。
训练方法建立在斯坦福alpaca的基础上,并进行了以下改进。
- 内存优化:为了使 Vicuna 能够理解长上下文,将最大上下文长度从alpaca 中的 512 扩展到 2048。还通过gradient checkpointing和flash attentio来解决内存压力。
- 多轮对话:调整训练损失考虑多轮对话,并仅根据聊天机器人的输出进行微调。
- 通过 Spot 实例降低成本:使用 SkyPilot 托管点来降低成本。该解决方案将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元左右削减至 300 美元。
MOSS-moon(LLM)
MOSS是一个支持中英双语和多种插件的开源对话语言模型,moss-moon系列模型具有160亿参数,在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
SAM-segment anything
demo:https://segment-anything.com/demo#
代码:https://github.com/facebookresearch/segment-anything
分割的本质是:判断图像中的某个像素属于哪一个具体的对象。
作者:一个王二不小 https://www.bilibili.com/read/cv23131030/ 出处:bilibili
作者从NLP领域获得灵感,在NLP的任务中,预测下一个token用于基础模型的训练,并通过prompt engineering 解决不同的下游任务。为了建立这样一个分割的基础模型,作者的目标书建立一个具有类似能力的任务 ### Task promptable的分割任务是给定任何prompt都能返回有效的分割掩码。有效的mask意味着即使prompt是不准确的或者涉及到多个对象的也应该的能够输出正确的或者合理的掩码。
项目提出的新任务的名字叫做可提示的图像分割任务(the promptable segmentation task),即给定图片和一些提示词——点的位置、方框、mask、文字等等,返回图像分割结果。如下:
模型需要满足几个条件:
- 支持灵活的prompt
- 分割掩码的生成满足交互的实时性
- 能够处理歧义的情况(同一个位置不同粒度的分割)
为了满足上面三个条件,文章提出了如下模型:
- 一个基于ViT的图像编码器
- 一个prompt编码器
- 一个轻量级的掩码解码器
数据引擎-Data engine
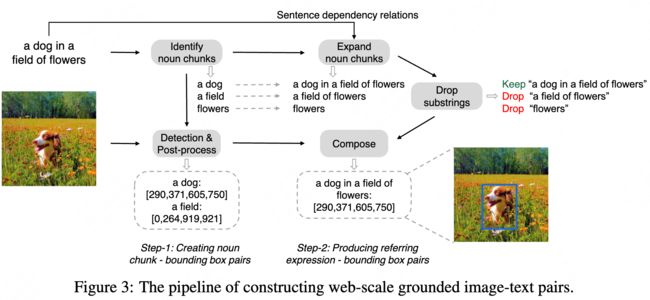
由于分割掩码在互联网上并不丰富,作者构建了一个数据引擎来实现1.1B 掩码数据集 SA-1B 的集合。
数据引擎分为三个阶段:(1)模型辅助手动注释阶段,(2)混合自动预测掩码和模型辅助注释的半自动阶段,以及(3)全自动阶段,
- 辅助人工标注
通过SAM基于浏览器的交互式分割工具,通过“brush”和"eraser"工具,进行标注。模型可以实时输出mask,建议标注者优先标记他们命名的对象,按图层顺序标记,如果一个mask标记超过30s,先处理下一张。
SAM先用公开数据集训练,然后再用新增的标注mask训练。随着数据越多,image-encoder的能力越强,retrained了6次。随着模型改进,每个mask平均标注时间从34s到14s,平均每张图像mask从22增加到44个。在这个过程中,从12万图像中,收集了430万个mask。
- 半自动
增加mask的多样性,首先检测出可信的mask,然后用预测mask填充图像,让标注者标注未标记的mask。为了检测可信的mask,先用第一步的mask训练了一个类别一样的box检测器。半自动过程中,从18万张图像中生成了590万个mask。用新收集的数据,重新训练模型,平均标注时间又回到了34s,因为新的mask都是比较有难度的。每张图像上mask从44增加到72。
- 全自动
利用前2步,得到的大量的和多样性的mask,结合模型可以根据不明确的输入也能输出有效的mask(参考mask encoder),对图像生成(32,32)个格网点,每个点预测一系列mask,如果一个点落在部分、子部分上,模型返回部分、子部分和整体的object。同时,通过预测的iou筛选 confident(可信的mask),选取一个stable的mask(稳定的mask,在相似的mask中,概率阈值在 0.5-δ和 0.5-δ之间);最后,通过nms过滤confident和stable中重复的mask。
全自动掩码生成应用于数据集中的所有 11M 图像,总共产生了 1.1B 的高质量掩码。
Framework
模型 SAM包括了三个部分 一个 image encoder, 一个 flexible prompt encoder, 和一个 fast mask decoder.

image encoder
受可扩展性和强大的预训练方法的启发,作者使用了MAE预训练的视觉转换器(ViT),该转换器至少适用于处理高分辨率输入。图像编码器每个图像运行一次,并且在prompt运行之前运行。
输入(c,h,w)的图像,对图像进行缩放,按照长边缩放成1024,短边不够就pad,得到(c,1024,1024)的图像,经过image encoder,得到对图像16倍下采样的feature,大小为(256,64,64)。
prompt encoder
作者考虑了两组提示:稀疏(sparse)(点、框、文本)和密集(dense)(掩码)。MAE通过位置编码来表示点和框,这些位置编码与每个使用CLIP的现成文本编码器来编码过的prompt的学习嵌入相加。dense prompt(即掩码)使用卷积嵌入,并与图像嵌入逐元素求和。(ps:四种提示,point和box用坐标表示,进行位置编码。文本用CLIP进行编码,mask用像素表示,进行图像加权)
- point:映射到256维的向量,包含代表点位置的 positional encoding,加2个代表该点是前景/背景的可学习的embedding。
- box:用一个embedding对表示(1)可学习的embedding代表左上角(2)可学习的embedding代表右下角
- 文本:通过CLIP模型进行文本编码
- mask:用输入图像1/4分辨率的mask,然后用(2,2)卷积核,stride-2输出channel为4和16,再用(1,1)卷积核将channel升到256. mask 和iamge embedding通过element-wise相乘(逐元素相乘,可以理解成mask的feature对image的feature进行加权)
mask decoder
掩码解码器有效地将图像嵌入、提示嵌入和输出标记映射到掩码。这种设计受到的启发,对 Transformer decoder 进行了修改,然后是动态掩码预测头。修改后的解码器块在两个方向上使用提示自注意力和交叉注意力((prompt-to-image embedding,反之亦然)来更新所有嵌入。在运行两个块后,对图像嵌入进行上采样,MLP将输出标记映射到动态线性分类器,然后计算每个图像位置的mask foreground 概率。
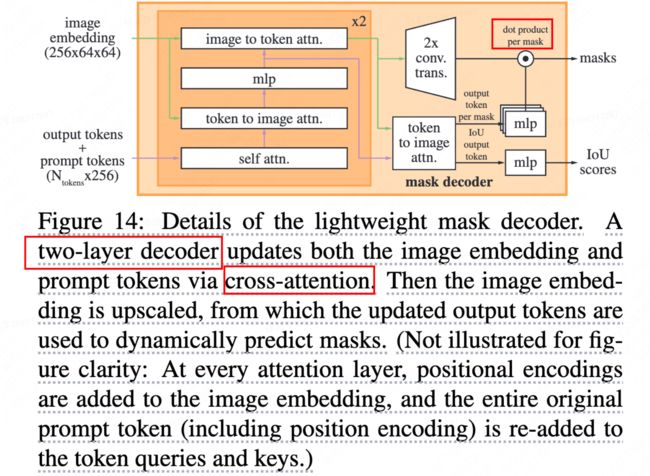
(1)prompt toekns+output tokens进行self attn,
(2)用得到的token和image embedding进行 cross attn(token作为Q)
(3)point-wise MLP 更新token
(4)用image embedding和(3)的token进行cross atten(image embedding作为Q)
重复上述步骤2次,再将attn再通过残差进行连接,最终输出masks和iou scores。
为了解决输出模糊性问题(一个提示可能生成多个mask,比如衣服上的一个点,既可以表示衣服,也表示穿衣服的人),预测输出多个masks(发现整体,部分,子部分已经足够描述mask),在训练过程中,只回传最小的loss,为了对mask进行排序,增加一个小的head预测mask和目标的iou。
当输入多个提示时,生成的mask会比较接近,为了减少loss退化和确保获取明确的mask,此时只预测一个mask(作为第4个预测mask,只有多个提示时才预测,当单个提示时不用)
训练方式
预训练
promptable segmentation task 提出了一种自然的预训练算法,该算法模拟每个训练样本的提示序列(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。作者将这种方法从交互式分割中改编出来,尽管与交互式分割不同,交互式分割的目的是在足够的用户输入后最终预测有效的掩码,但promptable segmentation task 的目的是始终预测任何提示的有效掩码,即使提示不明确的/错误的/荒谬的。
Zero-Shot推理实验
作者在这里讨论了五个任务,其中四个与训练数据完全不同。这也避免了模型训练过程中能够看到答案。这几个任务分别是 1. zero-shot单点有效掩码评估 2. 执行边缘检测 3. 分割所有内容,即对象提议生成 4. 分割检测到的对象,即实例分割, 5. 作为概念验证,从自由形式的文本中分割对象。
loss
mask 用focal loss和dice loss进行线性组合,系数(20:1),iou 用mse loss。
指令生成相关文章
self instruct
https://juejin.cn/post/7224652567053598778
本研究提出了一种半自动的self-instruction过程,用于使用来自模型本身的指示信号对预训练的LM进行指令调整。整个过程是一个迭代的自引导(iterative bootstrapping)算法(见图1),它从一个有限的人工编写的指令种子集开始,用于指导整个生成。在第一个阶段,提示模型为新任务生成指令。此步骤利用现有的指令集合来创建更广泛的指令,这些指令定义(通常是新的)任务。对于新生成的指令集,框架还为它们创建输入-输出实例,这些实例可在以后用于监督指令调优。最后,在将低质量和重复的指令添加到任务池之前,使用各种措施来修剪它们。这个过程可以在许多交互中重复,直到达到大量的任务。
通过在GPT3上运行该方法并微调,验证了其有效性。研究还发布了一个包含52K指令的数据集和一组手动编写的新任务,用于构建和评估未来的指令遵循模型。本文贡献如下:
- SELFINSTRUCT,一种用最少的人工标记数据诱导指令跟随能力的方法;
- 通过大量的指令调优实验证明了其有效性;
- 发布了一个包含52K指令的大型合成数据集和一组手动编写的新任务,用于构建和评估未来的指令遵循模型。
Alpaca
目前的 Alpaca 模型是由 7B LLaMA模型 [1] 对 Self-Instruct [2] 论文中的技术所产生的 52K 指令跟随(instruction-following)数据进行微调,并做了一些修改。在初步的人类评估中,作者发现 Alpaca 7B 模型在Self-Instruct 指令跟随评估套件 [2] 上的表现与 text-davinci-003 模型类似。
相关链接
通向AGI之路:大型语言模型(LLM)技术精要
BertModel一些方法