Flink状态容错savepoint与checkpoint
本文目录
Checkpoints
State Backends
Savepoints
Checkpoints 与 Savepoints区别
Flink可以保证exactly once,与其容错机制checkpoint和savepoint分不开的。本文主要讲解两者的机制与使用,同时会对比两者的区别。
Checkpoints
Checkpoint 使 Flink 的状态具有良好的容错性,通过 checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。Flink 中的每个方法或算子都能够是有状态的,状态化的方法在处理单个 元素/事件 的时候存储数据,让状态成为使各个类型的算子更加精细的重要部分。为了让状态容错,Flink 需要为状态添加 checkpoint(检查点)。Checkpoint 使得 Flink 能够恢复状态和在流中的位置,从而向应用提供和无故障执行时一样的语义。
Flink 的 checkpoint 机制会和持久化存储进行交互,读写流与状态。一般需要:
一个能够回放一段时间内数据的持久化数据源,例如持久化消息队列(例如 Apache Kafka、RabbitMQ、 Amazon Kinesis、 Google PubSub 等)或文件系统(例如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
存放状态的持久化存储,通常为分布式文件系统(比如 HDFS、 S3、 GFS、 NFS、 Ceph 等)。
1. 开启与配置 Checkpoint
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
// checkpoint间隔,这里配置为10s进行一次,单位是 ms
senv.enableCheckpointing(10 * 1000);Checkpoint 其他的属性包括:
精确一次(exactly-once)对比至少一次(at-least-once):你可以选择向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中传入一个模式来选择使用两种保证等级中的哪一种。对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用的关联较大。
checkpoint 超时:如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。
checkpoints 之间的最小时间:该属性定义在 checkpoint 之间需要多久的时间,以确保流应用在 checkpoint 之间有足够的进展。如果值设置为了 5000, 无论 checkpoint 持续时间与间隔是多久,在前一个 checkpoint 完成时的至少五秒后会才开始下一个 checkpoint。往往使用“checkpoints 之间的最小时间”来配置应用会比 checkpoint 间隔容易很多,因为“checkpoints 之间的最小时间”在 checkpoint 的执行时间超过平均值时不会受到影响(例如如果目标的存储系统忽然变得很慢)。注意这个值也意味着并发 checkpoint 的数目是一。
checkpoint 可容忍连续失败次数:该属性定义可容忍多少次连续的 checkpoint 失败。超过这个阈值之后会触发作业错误 fail over。默认次数为“0”,这意味着不容忍 checkpoint 失败,作业将在第一次 checkpoint 失败时fail over。可容忍的checkpoint失败仅适用于下列情形:Job Manager的IOException,TaskManager做checkpoint时异步部分的失败, checkpoint超时等。TaskManager做checkpoint时同步部分的失败会直接触发作业fail over。其它的checkpoint失败(如一个checkpoint被另一个checkpoint包含)会被忽略掉。
并发 checkpoint 的数目: 默认情况下,在上一个 checkpoint 未完成(失败或者成功)的情况下,系统不会触发另一个 checkpoint。这确保了拓扑不会在 checkpoint 上花费太多时间,从而影响正常的处理流程。不过允许多个 checkpoint 并行进行是可行的,对于有确定的处理延迟(例如某方法所调用比较耗时的外部服务),但是仍然想进行频繁的 checkpoint 去最小化故障后重跑的 pipelines 来说,是有意义的。该选项不能和 “checkpoints 间的最小时间"同时使用。
externalized checkpoints: 你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上并且在 job 失败的时候不会被自动删除。这种方式下,如果你的 job 失败,你将会有一个现有的 checkpoint 去恢复。更多的细节请看 Externalized checkpoints 的部署文档。
这些参数,通过senv.getCheckpointConfig() 都有对应的set方法:
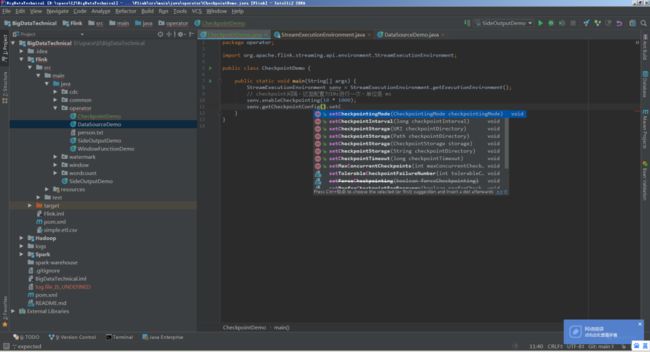
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 允许两个连续的 checkpoint 错误
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(2);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 使用 externalized checkpoints,这样 checkpoint 在作业取消后仍就会被保留
env.getCheckpointConfig().setExternalizedCheckpointCleanup(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 开启实验性的 unaligned checkpoints
env.getCheckpointConfig().enableUnalignedCheckpoints();比如通常可以这样配置:
 image-20231229154724919
image-20231229154724919
2. 保留 Checkpoint
Checkpoint 在默认的情况下仅用于恢复失败的作业,并不保留,当程序取消时 checkpoint 就会被删除。当然,你可以通过配置来保留 checkpoint,这些被保留的 checkpoint 在作业失败或取消时不会被清除。这样,你就可以使用该 checkpoint 来恢复失败的作业。
CheckpointConfig config = env.getCheckpointConfig();
config.setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);ExternalizedCheckpointCleanup 配置项定义了当作业取消时,对作业 checkpoint 的操作:
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:当作业取消时,保留作业的 checkpoint。注意,这种情况下,需要手动清除该作业保留的 checkpoint。
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业取消时,删除作业的 checkpoint。仅当作业失败时,作业的 checkpoint 才会被保留。
注意:通常我们应该选择保留checkpoint,失败的情况下都会被保留,如果我们要程序升级,这时候手动取消程序,如果设置为不保留,则会被删除,这样没法恢复程序。
本文代码地址:https://gitee.com/ddxygq/BigDataTechnical/blob/main/Flink/src/main/java/operator/CheckpointDemo.java
3. 目录结构
checkpoint 由元数据文件、数据文件(与 state backend 相关)组成。可通过配置文件中 “state.checkpoints.dir” 配置项来指定元数据文件和数据文件的存储路径,另外也可以在代码中针对单个作业特别指定该配置项。通常的 checkpoint 目录结构如下所示:
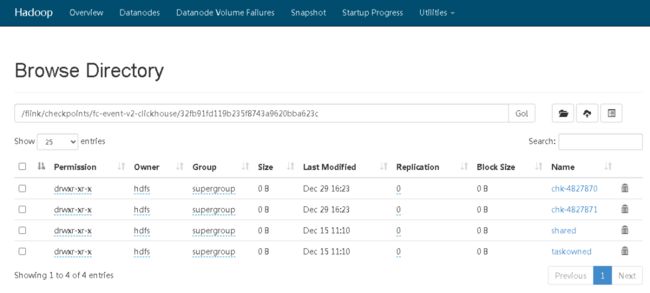 image-20231229162350639
image-20231229162350639
通过配置文件全局配置
state.checkpoints.dir: hdfs:///checkpoints/创建 state backend 对单个作业进行配置
env.setStateBackend(new RocksDBStateBackend("hdfs:///checkpoints-data/"));4. 从checkpoint 恢复状态
对于失败或者手动取消的Flink程序,通过以下命令恢复状态-s指定checkpoint路径即可:
bin/flink run -p 3 -n -s hdfs:///flink/checkpoints/jobName/jobId/chk-4582193 -c MainClass main.jarState Backends
在启动 CheckPoint 机制时,状态会随着 CheckPoint 而持久化,以防止数据丢失、保障恢复时的一致性。状态内部的存储格式、状态在 CheckPoint 时如何持久化以及持久化在哪里均取决于选择的 State Backend。
Flink 内置了以下这些开箱即用的 state backends :
HashMapStateBackend
EmbeddedRocksDBStateBackend
如果不设置,默认使用 HashMapStateBackend。
HashMapStateBackend
在 HashMapStateBackend 内部,数据以 Java 对象的形式存储在堆中。Key/value 形式的状态和窗口算子会持有一个 hash table,其中存储着状态值、触发器。
HashMapStateBackend 的适用场景:
有较大 state,较长 window 和较大 key/value 状态的 Job。
所有的高可用场景。
建议同时将 managed memory 设为0,以保证将最大限度的内存分配给 JVM 上的用户代码。
与 EmbeddedRocksDBStateBackend 不同的是,由于 HashMapStateBackend 将数据以对象形式存储在堆中,因此重用这些对象数据是不安全的。
EmbeddedRocksDBStateBackend
EmbeddedRocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。不同于 HashMapStateBackend 中的 java 对象,数据被以序列化字节数组的方式存储,这种方式由序列化器决定,因此 key 之间的比较是以字节序的形式进行而不是使用 Java 的 hashCode 或 equals() 方法。
EmbeddedRocksDBStateBackend 会使用异步的方式生成 snapshots。
EmbeddedRocksDBStateBackend 的局限:
由于 RocksDB 的 JNI API 构建在 byte[] 数据结构之上, 所以每个 key 和 value 最大支持 2^31 字节。RocksDB 合并操作的状态(例如:ListState)累积数据量大小可以超过 2^31 字节,但是会在下一次获取数据时失败。这是当前 RocksDB JNI 的限制。EmbeddedRocksDBStateBackend 的适用场景:
状态非常大、窗口非常长、key/value 状态非常大的 Job。
所有高可用的场景。
注意,你可以保留的状态大小仅受磁盘空间的限制。与状态存储在内存中的 HashMapStateBackend 相比,EmbeddedRocksDBStateBackend 允许存储非常大的状态。然而,这也意味着使用 EmbeddedRocksDBStateBackend 将会使应用程序的最大吞吐量降低。所有的读写都必须序列化、反序列化操作,这个比基于堆内存的 state backend 的效率要低很多。同时因为存在这些序列化、反序列化操作,重用放入 EmbeddedRocksDBStateBackend 的对象是安全的。
EmbeddedRocksDBStateBackend 是目前唯一支持增量 CheckPoint 的 State Backend 。
选择合适的 State Backend
在选择 HashMapStateBackend 和 RocksDB 的时候,其实就是在性能与可扩展性之间权衡。HashMapStateBackend 是非常快的,因为每个状态的读取和算子对于 objects 的更新都是在 Java 的 heap 上;但是状态的大小受限于集群中可用的内存。另一方面,RocksDB 可以根据可用的 disk 空间扩展,并且只有它支持增量 snapshot。然而,每个状态的读取和更新都需要(反)序列化,而且在 disk 上进行读操作的性能可能要比基于内存的 state backend 慢一个数量级。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());需要的maven依赖:
org.apache.flink
flink-statebackend-rocksdb
1.18.0
provided
设置默认的(全局的) State Backend
在 flink-conf.yaml 可以通过键 state.backend.type 设置默认的 State Backend。
可选值包括 jobmanager (HashMapStateBackend), rocksdb (EmbeddedRocksDBStateBackend), 或使用实现了 state backend 工厂 StateBackendFactory 的类的全限定类名, 例如:EmbeddedRocksDBStateBackend 对应为 org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackendFactory。
state.checkpoints.dir 选项指定了所有 State Backend 写 CheckPoint 数据和写元数据文件的目录。你能在 这里 找到关于 CheckPoint 目录结构的详细信息。
配置文件的部分示例如下所示:
# 用于存储 operator state 快照的 State Backend
state.backend: hashmap
# 存储快照的目录
state.checkpoints.dir: hdfs:///flink/checkpointsSavepoints
Savepoint 是依据 Flink checkpointing 机制所创建的流作业执行状态的一致镜像。你可以使用 Savepoint 进行 Flink 作业的停止与重启、fork 或者更新。Savepoint 由两部分组成:稳定存储(列入 HDFS,S3,…) 上包含二进制文件的目录(通常很大),和元数据文件(相对较小)。稳定存储上的文件表示作业执行状态的数据镜像。Savepoint 的元数据文件以(相对路径)的形式包含(主要)指向作为 Savepoint 一部分的稳定存储上的所有文件的指针。
1. 分配算子ID
强烈建议你按照本节所述调整你的程序,以便将来能够升级你的程序。主要通过 uid(String) 方法手动指定算子 ID 。这些 ID 将用于恢复每个算子的状态。
DataStream stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID 如果不手动指定 ID ,则会自动生成 ID 。只要这些 ID 不变,就可以从 Savepoint 自动恢复。生成的 ID 取决于程序的结构,并且对程序更改很敏感。因此,强烈建议手动分配这些 ID 。
2. 触发 Savepoint
当触发 Savepoint 时,将创建一个新的 Savepoint 目录,其中存储数据和元数据。
bin/flink savepoint :jobId [:targetDirectory]这里savepoint保存目录targetDirectory可以不用指定,如果配置了默认目录,配置文件flink-conf.yaml通过state.savepoints.dir参数配置。
# 默认 Savepoint 目标目录
state.savepoints.dir: hdfs:///flink/savepoints从 1.11.0 开始,你可以通过移动(拷贝)savepoint 目录到任意地方,然后再进行恢复。和 savepoint 不同,checkpoint 不支持任意移动文件,因为 checkpoint 可能包含一些文件的绝对路径。
使用 YARN 触发 Savepoint
bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId这将触发 ID 为 :jobId 和 YARN 应用程序 ID :yarnAppId 的作业的 Savepoint,并返回创建的 Savepoint 的路径。