Kubernetes
应该程序部署方式
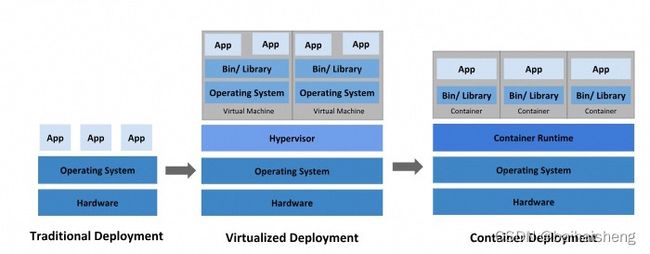
一、物理机 —传统方式
二、虚拟化部署,一台物理机运行多个虚拟机,多个操作系统
三、容器化部署,共享操作系统
容器管理-容器编排:
Swarm:docker自己的容器编排工具
kubernetes google开源的容器编排工具
kubernetes简介
是一个全新的基于容器技术的分布式架构方案,是google开源的容器编排工具,于2015年7月发布第一个正式版本
kubernetes本质是一组服务器集群,集群每个节点运行特定的程序,目的是实现资源管理自动化,主要提供的功能:
自我修复:容器崩溃,快速启动新的
弹性伸缩:自动对集群中运行的容器数据量进行调整
负载均衡:一个服务启动多个容器,自动实现请求的负载均衡
版本回退:发布版本有问题,可以回退到原来的版本
存储编排:根据自身自动创建存储卷
kubernetes核心组件
master(管理节点)和worker(工作节点)组成
master(管理节点):集群管理
Apiserver:资源操作的唯一入口,接受用户输入的命令,提供认证、授权、api注册和发现等机制
Scheduler:负责集群资源调度,按照预定的调度策略将POD调度到相应的worker节点上
controllerManager:负责维护集群的状态,例如程序部署安排,故障检测、自动扩展、滚动更新等
Etcd:负责存储集群中各种资源对象信息
worker(工作节点):容器运行环境
Kubelet:负责维护容器的生命周期、即通过控制docker、来创建、更新、销毁容器
Kubeproxy:负责提供集群内部的服务发现和负载均衡–程序对外服务
Docker:负责节点上容器的各种操作
组件调用关系:
程序安装请求–>master–>Apiserver–>Scheduler(计算安装节点)–>Etcd(Scheduler读取Etcd节点信息选择节点)-Apiserver-controllerManager-Kubelet-docker(启动一个pod)
Kubernetes组件社区:https://kubernetes.io/zh-cn/docs/concepts/overview/components/

kubernetes概念:
Pod:容器都是运行在pod中,一个pod可以有1个活多个容器
controller:
Service:pd对外服务的统一入口
Label:标签 用于对pod进行分类,同一类pod会拥有相同的标签
NameSpace:命名空间,用于隔离pod运行环境
Kubernetes集群部署规划:
一主多从:一台master节点和多台worker节点组成,一般测试环境使用
多主多从:多台master节点和多台worker节点组成,一般生产环境使用
一、资源管理方式:
kubectl–集群命令行工具,通过他能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
kubectl [command] [type] [name] [flags]
command:指定要对资源执行的操作
type:指定资源类型,例如pod、service
name:指定资源名称
flags:指定额外可选参数
命令式对象对象管理,直接使用命令去操作kubernetes资源 -操作对象
kubectl run nginxpd --image=nginx:1.xxx --port=80
命令式对象配置,通过命令配置和配置文件去操作kubernetes资源–操作对象目录文件
kubectl create(创建)/patch(更新) -f nginx-pod.yaml
声明式对象配置 通过apply命令和配置文件去操作kubernetes资源 --操作对象目录
kubectl apply -f nginx-pod.yaml --创建更新资源,有就更新,没有就创建
二、Ingress介绍
Service对集群之外暴露服务的主要方式有两种:nodeport和loadbalance
这两种方式缺点:
nodeport:占用集群节点端口
loadbalance:每个service需要一个loadbalance,浪费,麻烦。且需要集群之外的设备支持
kubernetes提供了Ingress资源对象,只需要一个nodeport或者一个loadbalance就可以满足暴露多个service的需求
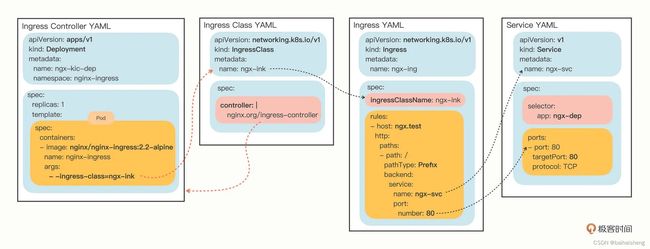
Ingress相对于一个7层的负载均衡,是kubernetes对反向代理的一个抽象,它的工作原理类型与Nginx,可以理解成Ingress里建立了多个映射规则,Ingress controller通过监听这些配置规则并转化成nginx的配置,然后对外提供服务,
Ingress:作用是定义请求如何转发到service的规则
Ingress controller:具体实现反向代理及负载均衡程序,对Ingress定义的规则进行解析,根据配置的规则来实现请求转发,实现的方式有很多,例如nginx haproxy等
工作原理(以ngix为例)原理:
1、编写Ingress规则,说明那个域名对应kubernetes集群中的那个service
2、Ingress控制器动态感知Ingress服务规则的变化,然后生成一段对应的nginx配置
3、Ingress控制器会将生成的nginx配置写入到一个运行着的nginx服务中,并动态更新
4、真正工作的就是nginx
yaml主要配置:
host:外部访问域名
paths:路径
servicename: service服务名
port:service的服务端口
https额外增加配置
tls:
Ingress 、Service、Ingress Class Ingress controller关系:
三、service详解
在kubernetes中,pod是应用程序的载体,可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的(可能会频繁的创建销毁),所以不方便采用pod的ip对外提供服务
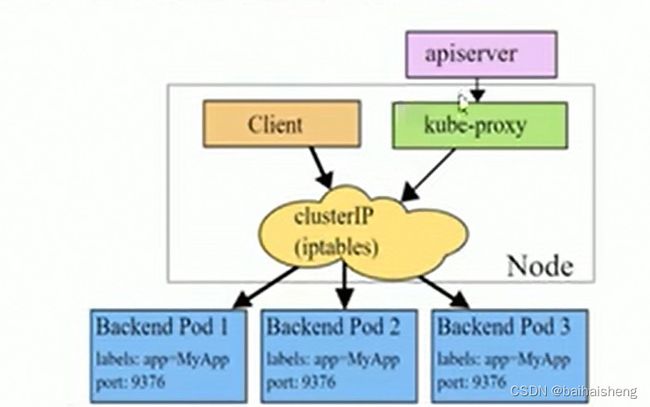
kubernetes提供了service资源,提供一个统一的入口地址,通过访问service的入口地址就能访问pod
service只是一个概念,实际起作用的是kube-proxy服务进程,每个节点上都运行着一个kube-proxy进程,当创建service的时候会通过api-server向etcd写入创建service的信息,而kube-proxy会基于监听的机制发现这种service的变动然后它会将最新的service信息转换成对应的访问规则
kube-proxy会基于rr(轮询)策略,转发请求到pod
kube-proxy支持三种工作模式:
userspace模式
userspace模式下,kube-proxy会为每一个service创建一个监听端口,发向cluster IP的请求被iptables规则重定向到kube-proxy
监听端口上,kube-proxy根据LB算法选择一个提供服务的pod并和其建立链接,以将请求转发到pod上
该模式下,kube-proxy充当一个四层负债均衡的角色,由于kube-proxy运行在userspace中,在进行转发处理时会增加内核和用户空间之间的数据拷贝,虽然稳定,但是效率比较低

iptables模式
iptables模式下,kube-proxy为service后端的每一个pod创建对应的iptables规则,直接将发向cluster ip的请求重定向到一个pod ip
该模式下kube-proxy不承担四层负载均衡器的角色,只负责创建iptables规则,该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端pod不可用时无法进行重试
ipvs
该模式和iptables类似,kube-proxy监控pod的变化并创建相应的ipvs规则
ipvs相对iptables转发效率更高,ipvs支持更多的LB算法

api-server接受创建service的请求,这个时候kube-proxy会生成一套ipvs规则策略,业务访问的时候基于策略转发
四、pod介绍
五、存储介绍–pv pvc
六、配置存储介绍–configmap
社区:https://kubernetes.io/zh-cn/docs/home/