编译原理 sql简易编译器
实验内容
利用yacc编写一个简易的sql编译器,使其能够使用sql查询语句
实验思路
词法分析
需要解析的单词其实并不是很多
tokens=('SELECT','FROM','WHERE',"DOT","MAX","MIN","LP","RP","EQUAL","AVERAGE",'AND','ORDER','OR','BIGGER','SMALLER','BY','DESC','NAME')
但是对一些细节还是需要注意。比如相同前缀的单词,要注意先后顺序,就如 O R D E R ORDER ORDER和 O R OR OR
语法分析
首先,对于每一个节点,我们用一个结构体 n o d e node node来记录其相关信息,包括其本身字段的内容,以及其子字段的信息等等
class node:
def __init__(self, data):
self._data = data
self._children = []
self._queryType = "NONE"
self._order = 0
def getdata(self):
return self._data
def getchildren(self):
return self._children
def getqueryType(self):
return self._queryType
def changeType(self,str):
self._queryType = str
def getorder(self):
return self._order
def rorder(self):
self._order = 1
def add(self, node):
self._children.append(node)
def print_node(self, prefix):
print (' '*prefix,'+',self._data)
for child in self._children:
child.print_node(prefix+1)
无条件查询
首先来实现最简单的无条件查询,并且只是查询最简单的字段信息
总结其基本的语法结构,得到如下格式
SELECT list FROM table
这里SELECT 和 FROM 都是我们在词法分析中会直接分析出来的单词,list表示的是需要查询的字段的列表,table就是我们需要查询的数据源
那么不难得到如下的基本语法
KaTeX parse error: No such environment: flalign at position 8: \begin{̲f̲l̲a̲l̲i̲g̲n̲}̲ &query\rightar…
这里DOT在词法分析中表示逗号,NAME就不是其余关键字的一个名称,一般就是字段名或者是某一个常数之类的
那么这样的话一个查询语句最后会归结成一个query节点,我们就能够对其进行操作了
以下是对应的文法实现
def p_query(t):
'''query : select'''
t[0]=t[1]
def p_select(t):
'''select : SELECT list FROM table '''
t[0]=node('QUERY')
t[0].add(node('[SELECT]'))
t[0].add(t[2])
t[0].add(node('[FROM]'))
t[0].add(t[4])
def p_table(t):
'''table : NAME'''
t[0]=node('[TABLE]')
t[0].add(node(t[1]))
def p_list(t):
''' list : '*'
| NAME'''
t[0]=node('[FIELD]')
t[0].add(node(t[1]))
def p_list_list_NAME(t):
''' list : list DOT NAME'''
t[0]=t[1]
t[0].add(node(t[3]))
举例,对于查询语句
SELECT Chinese FROM st
来说,其查询的结构就如下所示

无条件查询数字特征
还是无条件查询,但是加入max,min或者average等操作
这种查询与上一种的区别在于,上一种查询返回的结果是一个集合,但是这一种返回的是一个数字。事实上在后面越发复杂的查询语句中,我们是很有必要对查询语句返回的结果进行判断的,所以这一点需要特别注意
并且不难发现,这种查询与上一种查询的语句结构是互斥的,其结构如下
SELECT MAX(NAME) FORM table
所以我们重新引入一个单词number用来表示需要对某一个字段进行取max或者取min或者取平均等一系列操作
这一点并不是十分困难,我们很快就能得到新增的文法如下
# 查询集合与查询满足条件的数字,这两种查询应该是互斥的
def p_select_num(t):
'''select : SELECT number FROM table '''
t[0] = node('QUERY')
t[0].changeType("NUMBER")
t[0].add(node('[SELECT]'))
t[0].add(t[2])
t[0].add(node('[FROM]'))
t[0].add(t[4])
def p_MAX_query(t):
''' max_num : MAX LP NAME RP '''
t[0] = node('[MAX]')
t[0].add(node(t[3]))
def p_MIN_query(t):
''' min_num : MIN LP NAME RP '''
t[0] = node('[MIN]')
t[0].add(node(t[3]))
def p_AVERAGE_query(t):
''' average_num : AVERAGE LP NAME RP '''
t[0] = node('[AVERAGE]')
t[0].add(node(t[3]))
def p_NUMBER(t):
''' number : max_num
| min_num
| average_num'''
t[0] = node('[NUMBER]')
t[0].add(t[1])
从而完成了该功能的分析
条件查询
条件查询的基本格式如下
SELECT ... FROM table WHERE ...
WHERE后面的格式还是比较复杂的,因为其能够嵌套许多AND以及OR关键字,这就让条件之间的交并关系难以处理。这里给出了简化,保证查询条件是一个主析取范式,也就是
A1 AND A2 AND A3
这样的形式,并且
Ai = a1 OR a2 OR a3
每一个ai就是一个基本的比较式子
如此我们就能得到WHERE后面的条件的格式了。
首先描述基本比较式子,可以是字段与常数之间的比较,也可以是字段与一个查询之间的比较
def p_compare_expresion(t):
''' compare : NAME BIGGER NAME
| NAME SMALLER NAME
| NAME EQUAL NAME'''
t[0]=node('[COMPARE]')
t[0].add(node(t[2]))
t[0].add(node(t[1]))
t[0].add(node(t[3]))
def p_compare_expresion_query(t):
''' compare : NAME BIGGER query
| NAME SMALLER query
| NAME EQUAL query'''
t[0]=node('[COMPARE]')
t[0].add(node(t[2]))
t[0].add(node(t[1]))
t[0].add(t[3])
然后描述析取范式,也就是一个个基本比较式之间进行合并
def p_compare_compare(t):
''' or : compare OR compare'''
t[0]=node('[or]')
t[0].add(t[1])
t[0].add(t[3])
def p_or_compare(t):
''' or : or OR compare'''
t[0]=t[1]
t[0].add(t[3])
def p_xiqu_or(t):
''' xiqu : or '''
t[0]=node('[OR]')
for x in t[1].getchildren():
t[0].add(x)
def p_xiqu_compare(t):
''' xiqu : compare '''
t[0]=node('[OR]')
t[0].add(t[1])
最后描述主合取范式,也就是析取范式之间进行合并
def p_heuq(t):
''' hequ : xiqu '''
t[0]=node('[AND]')
t[0].add(t[1])
def p_hequ_xiqu(t):
''' hequ : hequ AND xiqu'''
t[0]=t[1]
t[0].add(t[3])
def p_WHERE_condition(t):
''' condition : WHERE hequ '''
t[0] = node('[WHERE]')
t[0].add(t[2])
举例,对于查询语句
SELECT * FROM st WHERE Chinese < 100 OR Math<100 AND English>100 AND Total>100 OR Math >120
其结构如下
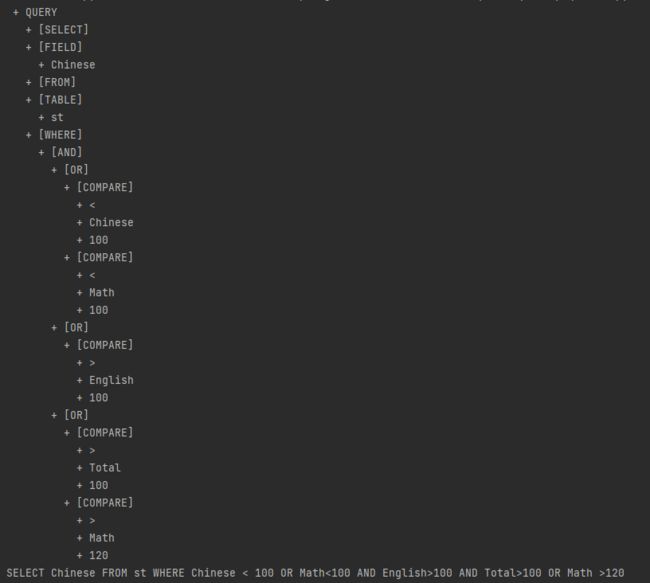
如此就完成了条件查询
嵌套查询
这一点其实比较好处理,因为对于每一个查询来说,它最终都会归结为一个节点。所以我们只要递归调用处理查询的函数,就能实现嵌套查询了
比如对于查询表达式
SELECT * FROM st WHERE Math=(SELECT MAX(Math) FROM st)
其结构如下所示

还是比较简单的
关键字排序
如果前面的都已经做完了的话,这一步相对来说还是比较简单的,我们只要加上对ORDER,By关键字的识别即可
对应的文法也很好写
def p_selsect_ordet(t):
''' select : select order'''
t[0]=t[1]
t[0].add(t[2])
def p_order(t):
''' order : ORDER BY NAME'''
t[0]=node('[ORDER]')
t[0].add(node(t[3]))
def p_order_x(t):
''' order : ORDER BY paixu'''
t[0]=node('[ORDER]')
t[0].add(t[3])
def p_paixu(t):
''' paixu : NAME DESC '''
t[0] = node(t[1])
t[0].rorder()
def p_order_NAME(t):
''' order : order DOT NAME '''
t[0]=t[1]
t[0].add(node(t[3]))
def p_order_paixu(t):
''' order : order DOT paixu '''
t[0]=t[1]
t[0].add(t[3])
这里还涉及DESC带来的逆序排序的问题,我们只要在node结构体中添加一个描述是否为逆序排序的flag即可
具体实现
对查询节点的分析:
找出语句中对应的查询字段,数字特征,查询的表,查询的条件,查询的排序与否以及对应关键字即可
这里查询的条件我也做了简化处理,因为都是对字段值的限制,所以每一个条件都用一个三元组来表示,分别表示字段名称,字段值的左界以及右界
得到这些信息之后直接去表里面找对应的信息即可
def Query_sql_set(node):
st, dataset, condition = [], [], []
Flag = 0 # 是查询集合还是查询满足条件的数字
ordered = [0,"NONE"]
for ch in node.getchildren():
if ch.getdata() == "[FIELD]":
st=ch.getchildren()
if ch.getdata() == "[NUMBER]":
st = ch.getchildren()[0].getchildren()[0].getdata()
Flag, type = 1, ch.getchildren()[0].getdata()[1:-1]
if ch.getdata() == "[TABLE]":
dataset = ch.getchildren()[0].getdata()
if ch.getdata() == "[ORDER]":
ordered = [1,ch.getchildren()]
if ch.getdata() == "[WHERE]":
now=ch.getchildren()[0]
for Or in now.getchildren(): # 合取范式的每一个极小项
Insert=[] # 每一个元素是一个三元组,表示一个运算表达式,元素之间是或的关系
for compare in Or.getchildren():
ins, val = [], compare.getchildren()
name, val_to_compare = val[1].getdata(),get_val(val[2])
if val[0].getdata() == "=":
ins = [name,val_to_compare,val_to_compare]
elif val[0].getdata() == ">":
ins = [name,val_to_compare+EPS,INF]
else :
ins = [name,-INF,val_to_compare-EPS]
Insert.append(ins)
condition.append(Insert)
name = dataset + '.csv'
#
dtSet = pd.DataFrame(csv.reader(open(name, 'r')))
#
if Flag == 0:
return naive_find(st,dtSet,condition,ordered)
else :
return naive_find_num(st,dtSet,condition,type)
在表中对信息的查找与筛选
只要注意主析取范式中对条件的交并之间的细节处理,这一块并不是很难写的内容,这里不再过多展示
关键字排序
按需模拟即可
def Order(data,Key):
val = []
for key in Key:
# print(key.getdata(),key.getorder())
for i in range(0, len(data[0])):
if data[0][i] == key.getdata():
if key.getorder() == 0:
# 这里直接取负的话,0是保持不变的,所以需要整体平移一下
val.append(i+1)
else:
val.append(-(i+1))
break
def sort_key(item):
return tuple(int(item[k-1]) if k>=0 else -int(item[k+1]) for k in val)
data[1:] = sorted(data[1:], key=sort_key)
return data
如此我们就实现了一个简易的sql编译器
结果展示
SELECT AVERAGE(Math) FROM st

SELECT No FROM st WHERE Chinese=(SELECT MAX(Chinese) FROM st)

SELECT * FROM st ORDER BY Chinese , No DESC

SELECT * FROM st WHERE Chinese < 100 OR Math<100 AND English>100 AND Total>100 OR Math >120
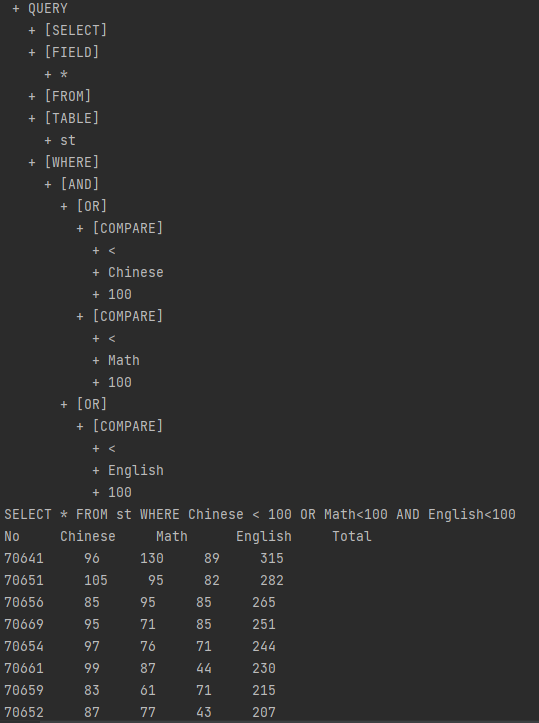
回顾
整体还是很有意思的,但是遗憾的是只实现了很少一部分的查询语句,并且写的还是太臭了…此外在已实现的功能中也有诸多限制,比如多条件查询时将条件格式限定在了主合取范式,无法处理更复杂的情况,诸如此类
不过总体来说,还是有点收获的,我也算真正会用yacc了(吧)