【nn.Parameter】Pytorch特征融合自适应权重设置(可学习权重使用)
2021年11月17日11:32:14
今天我们来完成Pytorch自适应可学习权重系数,在进行特征融合时,给不同特征图分配可学习的权重!
原文:基于自适应特征融合与转换的小样本图像分类(2021)
期刊:计算机工程与应用(中文核心、CSCD扩展版)
实现这篇论文里面多特征融合的分支!
实现自适应特征处理模块如下图所示:
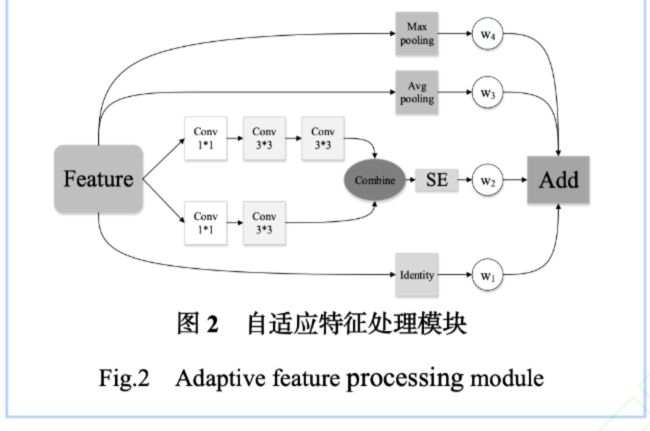
特征融合公式如下:
F
f
f
=
α
1
∗
F
i
d
+
α
2
∗
F
d
c
o
n
v
+
α
3
∗
F
max
+
α
4
∗
F
a
v
g
a
i
=
e
w
i
Σ
j
e
w
j
(
i
=
1
,
2
,
3
,
4
;
j
=
1
,
2
,
3
,
4
)
Fff=α1∗Fid+α2∗Fdconv+α3∗Fmax+α4∗Favgai=Σjewjewi(i=1,2,3,4;j=1,2,3,4)
其中,
α
i
\alpha_i
αi为归一化权重,
Σ
α
i
=
1
\Sigma\alpha_i=1
Σαi=1,
w
i
w_i
wi为初始化权重系数。
结构分析:
- 对于一个输入的特征图,有四个分支
- 从上往下,第一个分支用的是Maxpooling进行最大池化提取局部特征
- 第二个分支用的是Avgpooling进行平均池化提取全局特征
- 第三个分支,原文中讲的是“用两组1×1卷积将特征的通道减半压缩,一是为了减少参数量防止过拟合,二是方便后续进行卷积特征拼接进行加性融合;接着在第一组1×1卷积后加入两组3×3卷积来替代5×5卷积后按通道进行拼接(Combine按通道拼接)。”原文将这个分支称作双卷积分支DConv,卷积能提取丰富特征,在拼接后接入一个SE注意力模块。
- 第三个分支,是残差分支Identity,把输入直接跳跃连接加过去,保留原始特征
模型分析:
- 分析下模块结构,既然对于特征融合,最后的操作是Add,那么4个分支输出的特征图大小和维度是相同的!跳跃连接时原图的大小和维度都没有变,所以我们让四个分支的输出和原图大小保持一致
- 原文在3.2.2参数设置里面说:最大池化支路池化尺寸设为3,平均池化分支池化尺寸设为2
- 初始化各特征的权重全为1,使用nn.Parameter实现
- 输入图像的大小为3×84×84
AFP模块Pytorch实现
"""
Author: yida
Time is: 2021/11/17 15:45
this Code:
1.实现<基于自适应特征融合与转换的小样本图像分类>中的自适应特征处理模块AFP
2.演示: nn.Parameter的使用
"""
import torch
import torch.nn as nn
class AFP(nn.Module):
def init(self):
super(AFP, self).init()
self.branch1 = nn.Sequential(
nn.MaxPool2d(3, 1, padding=1), # 1.最大池化分支,原文设置的尺寸大小为3, 未说明stride以及padding, 为与原图大小保持一致, 使用(3, 1, 1)
)
self.branch2 = nn.Sequential(
nn.AvgPool2d(3, 1, padding=1), # 2.平均池化分支, 原文设置的池化尺寸为2, 未说明stride以及padding, 为与原图大小保持一致, 使用(3, 1, 1)
)
self.branch3_1 = nn.Sequential(
nn.Conv2d(3, 1, 1),
nn.Conv2d(1, 1, 3, padding=1), # 3_1分支, 先用1×1卷积压缩通道维数, 然后使用两个3×3卷积进行特征提取, 由于通道数为3//2, 此时输出维度设为1
nn.Conv2d(1, 1, 3, padding=1),
)
self.branch3_2 = nn.Sequential(
nn.Conv2d(3, 2, 1), # 3_2分支, 由于1×1卷积压缩通道维数减半, 但是这儿维度为3, 上面用的1, 所以这儿输出维度设为2
nn.Conv2d(2, 2, 3, padding=1)
)
# 注意力机制
self.branch_SE = SEblock(channel=3)
# 初始化可学习权重系数
# nn.Parameter 初始化的权重, 如果作用到网络中的话, 那么它会被添加到优化器更新的参数中, 优化器更新的时候会纠正Parameter的值, 使得向损失函数最小化的方向优化
self.w = nn.Parameter(torch.ones(4)) # 4个分支, 每个分支设置一个自适应学习权重, 初始化为1, nn.Parameter需放入Tensor类型的数据
# self.w = nn.Parameter(torch.Tensor([0.5, 0.25, 0.15, 0.1]), requires_grad=False) # 设置固定的权重系数, 不用归一化, 直接乘过去
def forward(self, x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3_1 = self.branch3_1(x)
b3_2 = self.branch3_2(x)
b3_Combine = torch.cat((b3_1, b3_2), dim=1)
b3 = self.branch_SE(b3_Combine)
b4 = x
print("b1:", b1.shape)
print("b2:", b2.shape)
print("b3:", b3.shape)
print("b4:", b4.shape)
# 归一化权重
w1 = torch.exp(self.w[0]) / torch.sum(torch.exp(self.w))
w2 = torch.exp(self.w[1]) / torch.sum(torch.exp(self.w))
w3 = torch.exp(self.w[2]) / torch.sum(torch.exp(self.w))
w4 = torch.exp(self.w[3]) / torch.sum(torch.exp(self.w))
# 多特征融合
x_out = b1 * w1 + b2 * w2 + b3 * w3 + b4 * w4
print("特征融合结果:", x_out.shape)
return x_out
class SEblock(nn.Module): # 注意力机制模块
def init(self, channel, r=0.5): # channel为输入的维度, r为全连接层缩放比例->控制中间层个数
super(SEblock, self).init()
# 全局均值池化
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
# 全连接层
self.fc = nn.Sequential(
nn.Linear(channel, int(channel r)), # int(channel * r)取整数
nn.ReLU(),
nn.Linear(int(channel r), channel),
nn.Sigmoid(),
)
def forward(self, x):
# 对x进行分支计算权重, 进行全局均值池化
branch = self.global_avg_pool(x)
branch = branch.view(branch.size(0), -1)
# 全连接层得到权重
weight = self.fc(branch)
# 将维度为b, c的weight, reshape成b, c, 1, 1 与 输入x 相乘
h, w = weight.shape
weight = torch.reshape(weight, (h, w, 1, 1))
# 乘积获得结果
scale = weight * x
return scale
if name == ‘main’:
model = AFP()
print(model)
inputs = torch.randn(10, 3, 84, 84)
print("输入维度为: ", inputs.shape)
outputs = model(inputs)
print("输出维度为: ", outputs.shape)
# 查看nn.Parameter中值的变化, 训练网络时, 更新优化器之后, 可以循环输出, 查看权重变化
for name, p in model.named_parameters():
if name == 'w':
print("特征权重: ", name)
w0 = (torch.exp(p[0]) / torch.sum(torch.exp(p))).item()
w1 = (torch.exp(p[1]) / torch.sum(torch.exp(p))).item()
w2 = (torch.exp(p[2]) / torch.sum(torch.exp(p))).item()
w3 = (torch.exp(p[3]) / torch.sum(torch.exp(p))).item()
print(w0, w1, w2, w3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
nn.Parameter:上图特征融合中的权重系数
w
i
w_i
wi
nn.Parameter的使用:可学习权重设置
- 1

更新记录
- 2022年04月14日17:37:53
最近看有不少同学关注此博客,所以,我就找一个可以直接运行的手写数字识别代码,把可学习参数放进去,在训练时输出; 为了让大家能够对可学习参数的变化,有更好的理解。
手写数字识别代码
"""
Author: yida
Time is: 2022/3/6 09:30
this Code: 代码原文: https://www.cnblogs.com/wj-1314/p/9842719.html
- 代码: 手写数字识别, 源码参考上面的链接, 仅仅包含两个卷积层的手写数字识别 对每个卷积层设置一个权重系数w
- 可直接运行, torchvision会自动下载手写数字识别的数据集 存放在当前文件夹 ./mnist 模型保存为./model.pth
- 未实现测试功能 大家可以自行添加
- 为了便于大家更好的理解可学习参数
- 直接放到代码里面, 边训练边输出, 方便各位理解
"""
import os
import torch
import torch.nn as nn
import torchvision.datasets as normal_datasets
import torchvision.transforms as transforms
from torch.autograd import Variable
os.environ[“KMP_DUPLICATE_LIB_OK”] = “TRUE”
# 两层卷积
class CNN(nn.Module):
def init(self):
super(CNN, self).init()
# 使用序列工具快速构建
self.conv1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7 * 7 * 32, 10)
self.w = nn.Parameter(torch.ones(2)) # 初始化权重, 对2个卷积分别加一个权重
def forward(self, x):
# 归一化权重
w1 = torch.exp(self.w[0]) / torch.sum(torch.exp(self.w))
w2 = torch.exp(self.w[1]) / torch.sum(torch.exp(self.w))
out = self.conv1(x) * w1
out = self.conv2(out) * w2
out = out.view(out.size(0), -1) # reshape
out = self.fc(out)
return out
# 将数据处理成Variable, 如果有GPU, 可以转成cuda形式
def get_variable(x):
x = Variable(x)
return x.cuda() if torch.cuda.is_available() else x
if name == ‘main’:
num_epochs = 5
batch_size = 100
learning_rate = 0.001
# 从torchvision.datasets中加载一些常用数据集
train_dataset = normal_datasets.MNIST(
root='./mnist/', # 数据集保存路径
train=True, # 是否作为训练集
transform=transforms.ToTensor(), # 数据如何处理, 可以自己自定义
download=True) # 路径下没有的话, 可以下载
# 见数据加载器和batch
test_dataset = normal_datasets.MNIST(root='./mnist/',
train=False,
transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
model = CNN()
if torch.cuda.is_available():
model = model.cuda()
# 选择损失函数和优化方法
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = get_variable(images)
labels = get_variable(labels)
outputs = model(images)
loss = loss_func(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [%d/%d], Iter [%d/%d] Loss: %.4f'
% (epoch + 1, num_epochs, i + 1, len(train_dataset) // batch_size, loss.item()))
# 动态输出w权重变换
for name, p in model.named_parameters():
if name == 'w':
print("特征权重: ", name)
w0 = (torch.exp(p[0]) / torch.sum(torch.exp(p))).item()
w1 = (torch.exp(p[1]) / torch.sum(torch.exp(p))).item()
print("w0={} w1={}".format(w0, w1))
print("")
# Save the Trained Model
print("训练完成...")
torch.save(model.state_dict(), './model.pth')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
【推荐阅读】
Pytorch-GPU安装教程大合集(Perfect完美系列)