分布式任务调度框架调研
分布式任务调度框架调研
-
-
-
- 需求:
-
- 当前方案
- 存在问题
- 调研:
-
- quartz:
-
- demo
- 整体架构:
- 关键实现:
- elastic-job:
-
- demo
- 整体架构:
- 关键实现:
- xxl-job:
-
- demo
- 整体架构:
- 关键实现:
-
-
需求:
在目前的实际业务中有大量的定时任务需要执行,例如大量缓存设置的保持数据一致性的兜底任务、课程开课前10分钟的考勤提醒、存在24小时未批改作业时提醒对应的老师等等。
当前方案
由于没有接入过分布式任务调度框架,所以在分布式环境中,这些任务是通过暴露一个HTTP接口来由外部调用触发的,只触发一次交给调用方来保证。调用方则是选择了Linux的crontab定时任务。
存在问题
由于任务量也不是很大,单机Linux crontab性能上倒也毫无压力,但是不代表没有其他问题
- 单机部署诸多任务,无备用节点,存在严重的单点问题。
- 任务失败无告警,无法第一时间做出应对。
- 任务执行无记录、无调度日志,出现问题难以排查。
- 无任务可视化列表,任务增删调整等容易误操作。
- ······
当前使用方案已经存在上述诸多问题,而且对于后续需要依赖分布式任务的业务场景豪无拓展空间。从另一方面也限制了当前业务实现的技术选型与设计。所以引入分布式任务调度框架显得非常重要。
调研:
当前系统对于分布式调度框架的使用场景是非常简单的,在可预见的未来其实也没有很复杂的需求是当前业界主流的分布式任务调度开源框架所不能满足的,所以自研就没太大的必要。那么技术选型就是在quartz、xxl-job以及elastic-job之间展开了。
本文参考的相关系统源码版本:
quartz:2.3.0
elastic-job:2.1.2
xxl-job:2.3.0
quartz:
git地址: https://github.com/quartz-scheduler/quartz
quartz是一个功能丰富的开源作业调度框架,完全由Java语言编写,几乎可以集成到任何Java程序中去。他集中解决任务的执行问题,缺乏数据统计。基于数据库来实现分布式环境下的任务调度。
demo
//job
@Component
public class TestJob extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
System.out.println("quartz----test");
}
}
@Configuration
public class QuartzConfig {
//jobdetail
@Bean
public JobDetail testJobDetail(){
return JobBuilder.newJob(TestJob.class)
.withIdentity("TestJob")
.usingJobData("msg", "Hello Quartz")
.storeDurably()
.build();
}
//trigger
@Bean
public Trigger testJobTrigger() {
CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule("0/1 * * * * ?");
return TriggerBuilder.newTrigger()
.forJob(testJobDetail())
.withIdentity("quartzTaskService")
.withSchedule(cronScheduleBuilder)
.build();
}
}
整体架构:
因为当前需求是在分布式环境下使用,所以这里以quartz的集群部署为例,部署视图如下
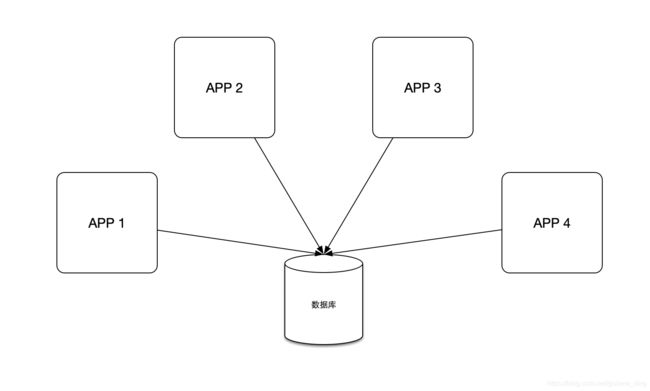
各实例相互之前无通信,通过数据库来感知对方并相互约束。
系统的逻辑视图如下:
如上图所示,quartz的主要组件有
- Job-简单的任务抽象,只提供了一个execute方法,没有job多余的属性。那在方法执行过程中是如何获取方法参数以及相关属性的呢?execute方法接受参数JobExecutionContext,该参数包含jobdetail、jobdatamap、trigger等对象,因此我们可以在execute方法中通过JobExecutionContext来获取job参数等内容。
- JobDetail-job相关属性的定义,包括name、group、jobclass以及jobdatamap等,是任务调度的基本元素。这里使用jobdetail而不是job来作为任务基本调度单元主要原因应该是为了复用job,同一个job可以定义多个jobdetail来并发执行。
- Triggger-触发器,用于定义触发规则。例如指定时间执行、间隔固定时间执行等,提供了多种实现,常用的有CronTrigger(cron表达式触发)、SimpleTrigger(固定次数)、DailyTimeIntervalTrigger(相隔固定时间间隔)以及CalendarIntervalTrigger(固定的日历时间-例如每周5)。
- Schedule-调度器,主要用于job-trigger的注册,维护了一个Triggger与JobDetail的注册表,完成任务的准时调度。quartz主要提供了RemoteScheduler(注册任务到远端服务)与StdScheduler。使用spring-boot-starter-quartz来引入quartz的话默认是通过StdSchedulerFactory初始化的StdScheduler。我们可以通过SchedulerFactoryBean来获取scheduler,从而动态得添加或移除任务。
关键实现:
这里以任务持久化到数据库为例来介绍quartz的一些关键实现。
关键数据库表:
- QRTZ_JOB_DETAILS:存储任务的基本信息,jobdatamap也序列化后存在该表中。
- QRTZ_TRIGGERS:任务的触发规则信息,通过JOBKey(jobName,jobGroup)关联JOB_DETAILS中的一个任务。在添加任务的时候与QRTZ_JOB_DETAILS一起写入,每个任务在此表中可以配置多个触发器。每个触发器通过triggerKey(triggerName,triggerGroup)唯一区分。
- QRTZ_LOCKS:该表用于分布式环境下scheduler对于特定数据的并发访问控制,主要存储了TRIGGER_ACCESS与STATE_ACCESS两个字段,对job的暂停与恢复、新增与删除、trigger的暂停与恢复、任务触发等操作都需要拿到对应TRIGGER_ACCESS的行锁。STATE_ACCESS则用于集群状态判断,若部分集群(通过scheduler-name区分)检查失败则在集群恢复时会先对STATE_ACCESS加行锁,然后对TRIGGER_ACCESS加行锁,最后进行对应trigger状态修改。
- QRTZ_CRON_TRIGGERS:存储crontrigger的cron表达式,通过tiggerkey关联QRTZ_TRIGGERS中trigger。
- QRTZ_SIMPLE_TRIGGERS:简单触发器相关配置,通过tiggerkey关联QRTZ_TRIGGERS中trigger,关联主要用于触发执行固定次数的任务,业务上一般用于一次性任务。
- QRTZ_TRIGGERS:存储所有的trigger信息,
spring boot整合quartz后启动流程:
quartz自动配置时会初始化SchedulerFactoryBean实例,该实例初始化时通过SchedulerFactory创建scheduler实例,将应用中的配置的jobdetail实例与trigger实例进行注册,集群模式则还需要实例化到数据库。在scheduler实例化的同时初始化QuartzSchedulerThread线程不断拉取即将要触发的trigger,并利用线程池执行到期任务,更新trigger的下一次触发时间。
//启动sechduler-> 到主消费循环
org.springframework.boot.autoconfigure.quartz.QuartzAutoConfiguration#quartzScheduler
org.springframework.scheduling.quartz.SchedulerFactoryBean#afterPropertiesSet
org.springframework.scheduling.quartz.SchedulerFactoryBean#prepareScheduler
org.springframework.scheduling.quartz.SchedulerFactoryBean#createScheduler
org.quartz.impl.StdSchedulerFactory#getScheduler()
org.quartz.impl.StdSchedulerFactory#instantiate()
org.quartz.core.QuartzScheduler#QuartzScheduler
org.quartz.core.QuartzSchedulerThread#QuartzSchedulerThread(org.quartz.core.QuartzScheduler, org.quartz.core.QuartzSchedulerResources)
准时触发的实现:
Scheduler初始化时启动QuartzSchedulerThread线程来不断加载近30s内需要执行的任务到内存中,然后在任务指定的时间创建线程去执行任务。
org.quartz.core.QuartzSchedulerThread#run
避免重复执行的实现:
通过数据库行锁来控制不同线程对于trigger表的访问控制。保证同一时刻只有一个线程能操作trigger表以及jobdetail表。
//获取最近30s内需要触发的任务
org.quartz.impl.jdbcjobstore.JobStoreSupport#acquireNextTriggers
缺点:
- 无可视化界面来动态增删任务,无相关执行日志以及失败报警。
- 通过数据库行锁来保证分布式环境下的一致性,集群实例增多时带来的数据库压力大。
- 集群环境下没有任务调度,可能造成单节点压力。
- 无任务分片,无法拆分大任务。
- 调度器与任务执行耦合在一起,无法单独拓展,有短板效应。
quartz实际上只完成了一个分布式任务调度系统的最基本功能-正确执行。在完善性和拓展性方面都还不够。
elastic-job:
git地址:https://github.com/apache/shardingsphere-elasticjob
elastic-job是由当当网在15年开源的一个分布式任务调度框架,主要由elastic-job-lite与elastic-job-cloud两个子项目组成。esjob采用去中心化的方案、利用zk替换quartz的数据库依赖。elastic-job中的各个节点是对等关系,各节点之间通过注册中心进行分布式协调。elastic-job在quartz的基础上完善或优化了日志、监控报警、并行调度以及弹性扩缩容等功能。 在2020 年 5 月 28 日esjob成为 Apache ShardingSphere 的子项目。
demo
elastic-job-lite 示例
/**
* 注册中心
*/
@Configuration
public class ElasticJobRegistryCenterConfig {
private String ZOOKEEPER_CONNECTION_STRING = "10.177.47.4:2181" ;
private String JOB_NAMESPACE = "elastic-job-demo";
@Bean(initMethod = "init")
public CoordinatorRegistryCenter setUpRegistryCenter(){
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZOOKEEPER_CONNECTION_STRING, JOB_NAMESPACE);
zookeeperConfiguration.setSessionTimeoutMilliseconds(1000);
CoordinatorRegistryCenter zookeeperRegistryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
return zookeeperRegistryCenter;
}
}
/**
* job内容
*/
public class TestEsJobDemo implements SimpleJob {
@Override
public void execute(ShardingContext context) {
System.out.println(context.getShardingItem());
}
}
/**
* 注册job
*/
public class ElasticJobConfig {
@Autowired
CoordinatorRegistryCenter registryCenter;
/**
* 配置任务详细信息
* @param jobClass 任务执行类
* @param cron 执行策略
* @param shardingTotalCount 分片数量
* @param shardingItemParameters 分片个性化参数
* @return
*/
private LiteJobConfiguration createJobConfiguration(final Class<? extends SimpleJob> jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters){
JobCoreConfiguration.Builder JobCoreConfigurationBuilder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(!Strings.isEmpty(shardingItemParameters)){
JobCoreConfigurationBuilder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration jobCoreConfiguration = JobCoreConfigurationBuilder.build();
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration, jobClass.getCanonicalName());
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true)
.build();
return liteJobConfiguration;
}
@Bean(name = "job-Test",initMethod = "init")
public SpringJobScheduler initSimpleElasticJob() {
SpringJobScheduler springJobScheduler = new SpringJobScheduler(new TestEsJobDemo(),registryCenter,
createJobConfiguration(TestEsJobDemo.class, "0/5 * * * * ?", 4, "0=text,1=image,2=radio,3=vedio")
);
return springJobScheduler;
}
@Bean(name = "job-Test2",initMethod = "init")
public SpringJobScheduler initJobElasticJob() {
SpringJobScheduler springJobScheduler = new SpringJobScheduler(new TestEsJobDemo2(),registryCenter,
createJobConfiguration(TestEsJobDemo2.class, "0/10 * * * * ?", 2, "0=text,1=image,2=radio,3=vedio")
);
return springJobScheduler;
}
}
elastic-job-cloud demo,这里未经过实践,直接贴出官方文档
https://github.com/apache/shardingsphere-elasticjob/tree/master/examples/elasticjob-example-cloud/src
整体架构:
因为elastic-job的调度是基于quartz实现的,所以在作业与调度这一块只是做了些拓展。基本元素基本一一对应,这里以elastic-job-lite为例。
elastic-job关键元素:
ZookeeperRegistryCenter:作为注册中心用于与zk的数据交互,内部使用了curator的zk客户端。通过curator的TreeCache来监听节点数据变化。
JobNodeStorage:作业节点数据访问类,调度过程中都是通过该类来获取任务在zk节点的相关数据。
JobScheduler:作业调度器,底层基于quartz的Scheduler来实现调度,与quartz最大的不同在于quartz中所有关于job的操作都通过同一个scheduler来完成,从上面的简单demo我们也可以看出,在elastic-job每个任务都对应一个独立的JobScheduler。
JobLite:es的调度作业,实现了quartz的job接口。
JobCoreConfiguration:job的核心配置,类似于quartz中的jobdetail。es的job只能基于cron表达式配置触发规则,我们在JobCoreConfiguration中设置合法的cron表达式后,es会自动帮我们创建对应的CronTrigger。
LiteJobConfiguration:持有JobCoreConfiguration配置,并进行job配置项拓展。
elastic-job-lite:
elastic-job-lite的定位是分布式无中心的轻量级分布式任务解决方案,通过jar包形式提供服务。适用于规模较小是的任务调度。如下架构图所示、App1,App2启动时通过注册中心把对应job注册到zk,并启动对应listener监听节点变化,选主完成后进入job调度阶段。任务调度分片由任一节点生成。同时提供了Console来动态地调度任务,以及日志收集系统。

elastic-job-cloud:
elastic-job-cloud基于mesos搭建任务处理云平台,整体分为调度模块和执行模块。从下面架构图中我们也可以看出该框架的基本处理流程。用户打包好任务镜像后将任务推送到镜像注册中心。然后在基于mesos搭建的调度平台上配置任务镜像、执行时间、资源占用、作业类型、是否缓存等相关信息后。调度平台就会根据用户配置进行调度。调度方式则还是采取了轮询的方式。对将要调度的作业加载进入待执行队列后,执行器根据调度信息来生成docker容器拉取任务镜像进行作业执行。如果是瞬时任务则在执行后释放对应资源。常驻任务则会有固定容器去执行。关于elastic-job-cloud的源码没有进行深入了解,就不对其实现进行展开了。

关键实现:
zk任务节点结构视图:
以TestEsJobDemo为例,config内部存储了任务相关配置LiteJobConfiguration。在instances中我们可以看到该任务共有多少个实例在运行。leader中主要存储了当前集群环境下该job选举出的leader,注意是以job为维度的。servers记录了注册服务的ip,sharding存储任务分片的逻辑,主要记录每个服务负责的任务分片。当节点down掉后leader会进行重新计算,重写分片逻辑。

准时触发的实现:
由于elastic-job内部是采用的quartz的调度器来调度任务的,在elastic-job初始化时会创建一个quartz的stdscheduler来进行job的注册,stdscheduler创建过程中会启动QuartzSchedulerThread线程来循环拉取30s内即将执行的job进行执行。这样保证了任务的准时触发。同时由于elastic-job是没一个scheduler对应一个job,所以每个任务实际上是有一个独享QuartzSchedulerThread线程去检测该任务是否需要执行的。所以准时性是要比quartz要更优秀的,当然带来的就是更多的资源占用。相关源码调用流程如下,就不一一展开了。
//任务调度关键调用链
com.dangdang.ddframe.job.lite.api.JobScheduler#init
com.dangdang.ddframe.job.lite.api.JobScheduler#createScheduler
org.quartz.impl.StdSchedulerFactory#getScheduler()
org.quartz.impl.StdSchedulerFactory#instantiate()
org.quartz.core.QuartzScheduler#QuartzScheduler
org.quartz.core.QuartzSchedulerThread#QuartzSchedulerThread(org.quartz.core.QuartzScheduler, org.quartz.core.QuartzSchedulerResources)
避免重复执行的实现:
由于elastic是基于zk来实现分布式环境下任务调用的准确性的,所以在QuartzSchedulerThread线程中拉取job通过quartz的RAMJobStore从内存中获取的,是放在本地缓存的,没法通过类似数据库锁这种方法来保证只有一个节点拉取任务执行,所以elastic-job的准确性是在执行期间保证的,这样其实也带来了一定的损耗,拉取任务分配好线程去执行时发现当前节点不需要执行后退出。任务执行的调用链如下所示,在AbstractElasticJobExecutor的execute方法中会先检查任务分片,也就是zknode中的sharing数据,如果当前服务没有分配对应的分片,则不会执行任务。源码调用主路径如下,也不一一展开了。
//任务调度避免重复实现关键调用链
org.quartz.core.QuartzSchedulerThread#run
org.quartz.core.JobRunShell#run
com.dangdang.ddframe.job.lite.internal.schedule.LiteJob#execute
com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#execute()
com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#execute(com.dangdang.ddframe.job.executor.ShardingContexts, com.dangdang.ddframe.job.event.type.JobExecutionEvent.ExecutionSource)
private void execute(final ShardingContexts shardingContexts, final JobExecutionEvent.ExecutionSource executionSource) {
//判断当前服务的分片
if (shardingContexts.getShardingItemParameters().isEmpty()) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format("Sharding item for job '%s' is empty.", jobName));
}
return;
}
......
}
任务分片的实现:
在APP启动时会初始化elastic-job,包括zknode的监听器启动以及主节点选主等。选主底层是通过curator的LeaderLatch来实现的,选主过程通过LeaderLatch.await方法阻塞,选主成功的节点会在leader/election下写入临时节点instance并存入当前实例ip。选主失败的节点则会监听上一节点(curator为避免羊群效应的设计),若上一临时节点失败则顺位第一选主为主节点。到此选主任务完成。随后shardingListenerManager中启动的listener监听到任务节点的数据变化后会在zk中写入leader/sharding/necessary节点,标示需要进行重分片。那么充分片的逻辑是什么时候执行的呢?其实我们在上面避免重复执行的实现中已经了解到了任务执行是会拉取分片信息进行判断当前节点需要执行的任务分片。其实在拉取分片的方法中会通过leader/sharding/necessary节点是否存在来判断是否需要重分片。需要重分时通过配置的重分片策略将分片结果写入zk并删除重分片标示节点leader/sharding/necessary。elastic-job提供了一些基本的重分片策略,我们也可以通过实现JobShardingStrategy接口来自定义分片策略。到此任务分片过程完成。源码调用主路径如下,也不一一展开了。
//启动->选主,并设置重分片标示
1.com.dangdang.ddframe.job.lite.api.JobScheduler#init
2.com.dangdang.ddframe.job.lite.internal.schedule.SchedulerFacade#registerStartUpInfo
public void registerStartUpInfo(final boolean enabled) {
//启动监听
listenerManager.startAllListeners();
//主节点选主
leaderService.electLeader();
serverService.persistOnline(enabled);
instanceService.persistOnline();
shardingService.setReshardingFlag();
monitorService.listen();
if (!reconcileService.isRunning()) {
reconcileService.startAsync();
}
}
//启动所有监听器
3.1com.dangdang.ddframe.job.lite.internal.listener.ListenerManager#startAllListeners
//选主
3.2com.dangdang.ddframe.job.lite.internal.election.LeaderService#electLeader
4.com.dangdang.ddframe.job.lite.internal.sharding.ShardingListenerManager.ListenServersChangedJobListener#dataChanged
//执行过程中重分片逻辑调用链
com.dangdang.ddframe.job.executor.AbstractElasticJobExecutor#execute()
com.dangdang.ddframe.job.lite.internal.schedule.LiteJobFacade#getShardingContexts
com.dangdang.ddframe.job.lite.internal.sharding.ShardingService#shardingIfNecessary
缺点:
- 部署复杂、资源占用高。
- 强依赖zk,zk的稳定性直接影响到任务调度的准确性。
elastic除了完成了一个分布式任务调度系统的最基本功能-正确执行之外。在日志、错误转移、动态分片、监控报警方面都做得不错,但是任务的触发还是基于轮询实现、资源利用效率不高。同时elastic-job学习成本高,且额外引入zk中间件,这一依赖的合理性是有待商榷的, 毕竟连kafka都正在努力移除对于其他中间级如zk的依赖。
xxl-job:
git地址
xxl-job:https://github.com/xuxueli/xxl-job
xxl-rpc:https://github.com/xuxueli/xxl-rpc
xxl-job由大宗点评员工许雪里开源,核心目标是打造一个简单、高效、易拓展的分布式任务调度框架,做到到开箱即用。他与quartz以及elastic-job-lite最大的区别是引入了中心化的调度中心。将调度中心与执行器分开部署。他和elastic-job提供的功能都比较全面,在技术选型中很难从基本功能上决出优劣。
demo
elastic-job-lite 示例
xxl-job在github上提供给了完整的示例,稍加改造即可使用docker容器快速部署。应该主要是数据库地址以及执行器的注册地址修改,需要注意的是本地容器起来后要配置调度中心容器ip到executor中的注册地址。
xxl-job-admin示例:https://github.com/xuxueli/xxl-job/tree/master/xxl-job-admin
xxl-job-sample-executor示例:https://github.com/xuxueli/xxl-job/tree/master/xxl-job-executor-samples
整体架构:
xxl-job中调度中心和执行器分开部署,执行器主要负责用户执行。调度中心则负责任务管理、任务调度、日志管理、告警、依赖等除执行外的所有功能。调度中心与执行器通过自研的rpc进行数据交互(采取netty实现)。执行器启动后将自己注册到调度中心,然后初始化执行线程之后开始监听配置的指定端口。调度中心则将配置的任务加载到秒级时间轮进行调度。调度过程是通过xxl-rpc发送run指令(其他还有kill、beat、log指令)到执行器,执行器根据指令参数找到对应的任务执行线程后(每个任务对应一个任务线程),将任务添加到任务线程的任务队列中,执行完后通过回调来告知调度器任务执行结果。

关键实现:
数据库表:
xxl_job_registry:执行器注册表。
xxl_job_group:执行器组,包含有注册表的所有已注册实例信息。
xxl_job_info:job的所有配置信息。
xxl_job_log:任务执行日志记录。
xxl_job_lock:用于调度器之间的并发控制。
xxl_job_logglue:glue配置的瞬时任务脚本详情。
xxl_job_log_report:每日的任务计数统计报表。
xxl_job_user:系统用户权限信息。
由于xxl-job任务的调度与实现是分离的,任务的正确执行都是靠调度器来保证的,调度器本身是可以多实例部署的。所以先重点来看一下调度服务启动时调度器的初始化方法,对相关组件有个整体的了解,相关注释已经标示于源码上。
public void init() throws Exception {
// init i18n
initI18n();
// 初始化触发任务线程池,分为fast与slow两个基本一样的线程池,slow的任务队列比fast稍长一些,用于执行在一分钟内超时10次以上的任务,所以普通任务的调度都是通过fast线程池调度。
JobTriggerPoolHelper.toStart();
// 初始化注册与移除事件的执行线程池以及注册监控线程,第一个线程池用于接收执行器的注册与移除消息,监控线程则用户定期监控注册列表是否有失效节点。
JobRegistryHelper.getInstance().start();
// 启动执行失败任务扫描线程,用户失败任务的重试与告警。
JobFailMonitorHelper.getInstance().start();
// 启动任务执行结果回调处理线程池,以及任务超时线程。由于任务执行结果是异步的回调通知的,所以需要线程来接受回调写入执行结果。监控线程用于轮询检查任务是否十分钟仍未接收到结果回调。
JobCompleteHelper.getInstance().start();
// 启动日志报告生成与日志清理线程
JobLogReportHelper.getInstance().start();
// 启动任务扫描线程与时间轮轮转线程从而实现任务调度。任务扫描线程负责加载即将执行任务到时间轮,然后由时间轮线程准时触发。
JobScheduleHelper.getInstance().start();
logger.info(">>>>>>>>> init xxl-job admin success.");
}
执行器注册列表维护实现:
执行器启动后会初始化注册线程来每隔30s不断地向调度器发送注册请求,调度器接受到请求后更新数据库表xxl_job_registry来保存注册信息或者更新updateTime。然后注册信息表的监控线程轮询xxl_job_registry表中更新时间未超时的注册实例更新至执行器组xxl_job_group表。这样保证了任务执行时从xxl_job_group中获取的执行实例都是在线的。相关源码调用路径如下:
//执行器启动注册线程流程
com.xxl.job.core.executor.XxlJobExecutor#start
com.xxl.job.core.executor.XxlJobExecutor#initEmbedServer
com.xxl.job.core.server.EmbedServer#start
com.xxl.job.core.server.EmbedServer#startRegistry
com.xxl.job.core.thread.ExecutorRegistryThread#start
//调度器动态刷新执行器组
com.xxl.job.admin.core.thread.JobRegistryHelper#start
准时触发的实现:
分布式环境下调度器启动是要先通过xxl_job_lock获取锁后才能读取任务配置,所以说实际上只有一台调度器在辛勤工作,其余调度器只是一个backup。获取到锁后的调度器拉取最近5s将要执行的任务,根据任务是否超时、是否超时时间大于5s、以及超时策略等来决定是直接执行任务还是加入时间轮。加入时间轮后的任务由时间轮线程ringThread来进行秒级任务调度。xxl_job的时间轮通过currentHashmap来实现,key是每一秒的时间戳,value则是这一秒需要触发的任务。每一秒的任务数以调度线程池大小*20为一个最高水位值,如果高于这个水位可能出现延迟或者不正确的调度行为。比如配置的fast线程池数量是300则建议每秒的任务应小于6000。20这个值则是由xxl-job官方测试后得出的单个任务调度的耗时为20ms。由于一秒的任务可能过多导致任务执行超过时间轮跳动间隔1s,所以时间轮滚动时会额外判断前两秒的任务是否已经执行,防止跳秒。这样就保证了任务的准时执行,代码入口如下,就不展开描述了。
//时间轮调度入口
com.xxl.job.admin.core.thread.JobScheduleHelper#start
避免重复执行的实现:
通过上述准时触发的实现中其实我们可以发现调度器通过数据库锁来控制分布式环境下只有一个实例来加载任务。
conn = XxlJobAdminConfig.getAdminConfig().getDataSource().getConnection();
connAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
preparedStatement.execute();
任务调度实现:
时间轮调度触发任务后,调度器通过xxl-rpc框架发送任务执行请求到执行器,同步获取到执行器是否接受任务成功后方法退出。执行器执行任务后通过回调来通知调用器执行结果。一次任务调度完成。具体调用路径如下所示
//时间轮调度流程 xxl调度器
com.xxl.job.admin.core.thread.JobScheduleHelper#ringThread
com.xxl.job.admin.core.thread.JobTriggerPoolHelper#trigger
com.xxl.job.admin.core.thread.JobTriggerPoolHelper#addTrigger
com.xxl.job.admin.core.trigger.XxlJobTrigger#trigger
com.xxl.job.admin.core.trigger.XxlJobTrigger#processTrigger
//执行器启动->任务执行->结果回调 xxl执行器
com.xxl.job.core.executor.XxlJobExecutor#start
com.xxl.job.core.executor.XxlJobExecutor#initEmbedServer
com.xxl.job.core.server.EmbedServer#start
com.xxl.job.core.server.EmbedServer.EmbedHttpServerHandler#channelRead0
com.xxl.job.core.server.EmbedServer.EmbedHttpServerHandler#process
com.xxl.job.core.biz.impl.ExecutorBizImpl#run
com.xxl.job.core.thread.JobThread#pushTriggerQueue
com.xxl.job.core.thread.JobThread#run
com.xxl.job.core.thread.TriggerCallbackThread#pushCallBack
com.xxl.job.core.thread.TriggerCallbackThread#start
com.xxl.job.core.thread.TriggerCallbackThread#doCallback
com.xxl.job.core.biz.client.AdminBizClient#callback
//执行日志回调 xxl调度器
com.xxl.job.admin.controller.JobApiController#api
com.xxl.job.admin.service.impl.AdminBizImpl#callback
com.xxl.job.admin.core.thread.JobCompleteHelper#callback(java.util.List<com.xxl.job.core.biz.model.HandleCallbackParam>)
com.xxl.job.admin.core.thread.JobCompleteHelper#callback(com.xxl.job.core.biz.model.HandleCallbackParam)
调研结论:
由于当前需求都是基于http的curl调用,与任务调度中的瞬时任务想吻合。而elastic-job-cloud部署负责、学习成本高且需要额外引入zk的依赖。与他功能基本一致的xxl-job似乎是更好的选择,而且在可预见的未来每秒的qps也不会达到xxl-job的瓶颈。所以选择xxl-job完全没毛病。
总结:
本文从源码入手、详述了quartz、elastic-job和xxl-job三大任务调度框架的启动流程、任务调度的主链路以及关键实现。结合实践,深入浅出,对于自研分布式任务框架或者使用现有框架的人来说都很有帮助。
参考文档:
下面是对于elastic-job教全面的源码文档,注重单点,串联性不强。
https://www.iocoder.cn/categories/Elastic-Job-Cloud/