【CMU15445】Fall 2019, Project 2: Hash Table 实验记录
目录
-
- 实验准备
- 实验测试
- Task 1: PAGE LAYOUTS
-
- 类之间的关系
- block index、bucket index 和 slot index
- 1.1 Header Page 的实现
-
- 1)GetBlockPageId
- 2)AddBlockPageId
- 1.2 Block Page 的实现
- Task 2: HASH TABLE IMPLEMENTATION
-
- 2.1 构造函数
- 2.2 GetValue
- 2.3 Insert
- 2.4 Remove
- Task 3: TABLE RESIZING
- Task 4: CONCURRENCY CONTROL
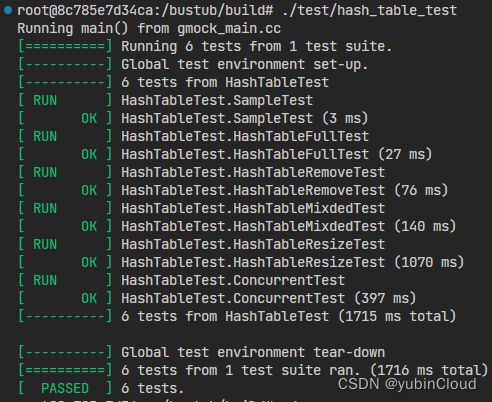
- 实验运行结果
这个实验需要实现一个构建在磁盘上的 Hash Table,由磁盘中的多个 page 组成,这些 page 分为两种类型:
- header page:用于存储整个 hash table 的元数据,只有一个 header page。
- block page:用于存储实际的 KV 数据
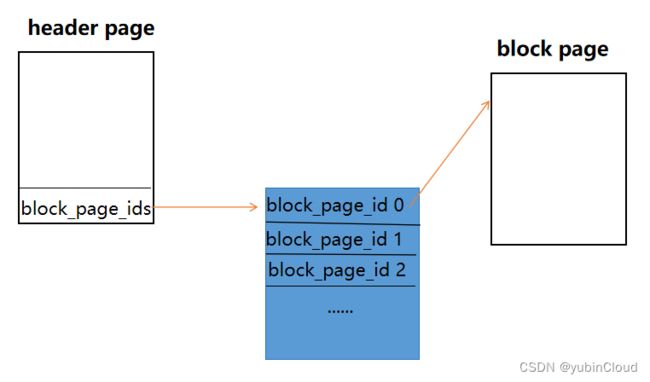
这些 page 通过 Project 1 中实现的 buffer pool manager 来创建、获取与删除。
实验准备
- 官方说明:https://15445.courses.cs.cmu.edu/fall2019/project2/
实验测试
Task 1:
mkdir build
cd build
make hash_table_page_test
./test/hash_table_page_test
Task 2~4:
make hash_table_test
./test/hash_table_test
不同的 Task 需要开启不同的测试用例(test/container/hash_table_test.cpp):
- Task 2:SampleTest、HashTableRemoveTest、HashTableMixdedTest
- Task 3:HashTableResizeTest
- Task 4:ConcurrentTest、HashTableFullTest
Task 1: PAGE LAYOUTS
这一个 task 需要实现出 header page 和 block page 两个类,后续的 Hash Table 将基于这两类 page 来构建。
每个 page 是固定大小 4096 bytes,header page 和 block page 的空间布局不同(可参考官网介绍)。因此这个 task 首先需要根据要求编写两个 Page 类的结构布局,即有哪些字段、每个字段的类型。
同时需要实现这两类 page 所应当实现的方法,比如 block page 应当能够在本 page 内实现 insert kv 等操作。
因此本 task 需要实现的是:
- 两个 page 类的结构布局(
HashTableHeaderPage和HashTableBlockPage) - 这两个类的相应接口方法
类之间的关系
page 的创建、获取与删除是通过 buffer pool manager 来实现的,而 buffer pool 管理的是 Page 类,当通过 buffer pool 拿到 Page * 的指针后,我们需要根据这个 page 的类型需要将 page 指针通过 reinterpret_cast 转换为 HashTableHeaderPage* 或 HashTableBlockPage* 的指针。
Page 类的字段结构主要如下:
/** The actual data that is stored within a page. */
char data_[PAGE_SIZE]{};
/** The ID of this page. */
page_id_t page_id_ = INVALID_PAGE_ID;
/** The pin count of this page. */
int pin_count_ = 0;
/** True if the page is dirty, i.e. it is different from its corresponding page on disk. */
bool is_dirty_ = false;
/** Page latch. */
ReaderWriterLatch rwlatch_;
其中 data_ 字段是一个大小为一个 PAGE_SIZE 的字节数组,它也就是一个磁盘页的实际数据,buffer pool 会做好这个字段与磁盘的 fsync。我们就是在通过 buffer pool 拿到 Page 类后,就是要将 data_ 字段的这个字节数组转化为 HashTableHeaderPage* 或 HashTableBlockPage* 指针,将其视为 header page 或 block page,然后在 header page 中存储元数据,在 block pages 存储实际的 KV 数据。
block index、bucket index 和 slot index
我们要区分好 block、bucket 和 slot 这三种概念。
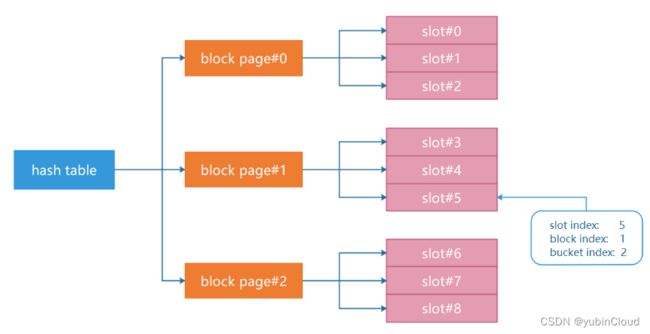
一个 Hash Table 由一个 header page 和多个 block page 组成,里面有 N 个 slots 来存储 N 个 KV pairs。每个 block page 由一个 bucket 数组组成,一个 bucket 也是一个 slot,用于存储一个 KV pair,只不过:
- bucket index 指的是在一个 block page 的 bucket 数组中的位移
- slot index 指的是在全局 Hash Table 中的逻辑上的位移
所以一个 KV pair 的 slot index 决定了 block index 和 bucket index,进而可以将其存储到 hash table 中。
slot index 是通过对 KV pair 的 key 调用 hash function 来计算得到:slot_index_t slot_index = this->hash_fn_.GetHash(key) % num_buckets_;。
1.1 Header Page 的实现
官网对 Header Page 的介绍如下:
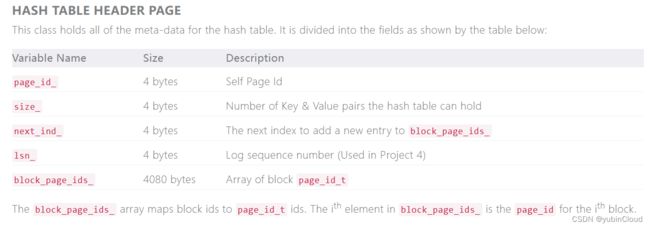
HashTableHeaderPage 的结构体如下:
lsn_t lsn_; // 暂时没用
size_t size_; // hash table 中有多少个 buckets,即多少个 slots
page_id_t page_id_; // header page 的 page_id
size_t next_ind_; // 表示当前有多少个 block pages,也是block_page_ids 下一个空位置的位移
page_id_t block_page_ids_[0]; // 长度为 0 的数组,是柔型数组
长度为 0 的数组的字段在结构体最后时,表示这块内存的剩余部分都是这个数组的了。因此称之为 柔型数组。
1)GetBlockPageId
用于获取指定 block_index 的 block page:
auto HashTableHeaderPage::GetBlockPageId(size_t index) -> page_id_t {
return block_page_ids_[index];
}
2)AddBlockPageId
增加一个 block page:
void HashTableHeaderPage::AddBlockPageId(page_id_t page_id) {
block_page_ids_[next_ind_] = page_id;
next_ind_++;
}
1.2 Block Page 的实现
官网对 block page 的结构布局介绍如下:

occupied_ 和 readable_ 的第 i 个 bit 表示这个 block page 的第 i 个 bucket 是否被占用或可读:
- occupied:一个 bucket 存有 KV 数据或已被删除并标有 timestone,则表示 occupied
- readable:一个 bucket 存有 KV 数据,表示 readble
array_ 字段是存有实际 KV 数据的数组。
Block Page 类实现 Insert、Remove 操作主要通过 occupied 和 readble 来完成:
- Remove 第 i 个 KV 就是将
readble_的第 i 个 bit 设为 0,但occupied_的第 i 个 bit 仍为 1 - 在第 i 个位置 Insert 一个 KV 就是将
occupied_和readable_的第 i 个 bit 都设置为 1
Task 2: HASH TABLE IMPLEMENTATION
这个 task 就是要实现开址法 Hash Table 的 Insert、GetValue 和 Remove 操作,对应代码中的 LinearProbeHashTable 类,其结构体如下:
page_id_t header_page_id_; // 哈希表的 header page 的 id
BufferPoolManager *buffer_pool_manager_;
KeyComparator comparator_; // 用于比较 key 的大小
size_t num_buckets_; // 哈希表 buckets 的数量
size_t num_pages_; // block page 的数量
// Readers includes inserts and removes, writer is only resize
ReaderWriterLatch table_latch_;
// Hash function
HashFunction<KeyType> hash_fn_;
2.1 构造函数
构造函数用来初始化各个成员变量,并创建出 header page 和各个 block pages:
template <typename KeyType, typename ValueType, typename KeyComparator>
HASH_TABLE_TYPE::LinearProbeHashTable(const std::string &name, BufferPoolManager *buffer_pool_manager,
const KeyComparator &comparator, size_t num_buckets,
HashFunction<KeyType> hash_fn)
: buffer_pool_manager_(buffer_pool_manager),
comparator_(comparator),
num_buckets_(num_buckets),
num_pages_((num_buckets - 1) / BLOCK_ARRAY_SIZE + 1),
hash_fn_(std::move(hash_fn)) {
table_latch_.WLock();
makeHeaderPage();
buffer_pool_manager->UnpinPage(header_page_id_, true);
table_latch_.WUnlock();
}
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::makeHeaderPage() -> HashTableHeaderPage* {
auto *header_page = reinterpret_cast<HashTableHeaderPage *>(
buffer_pool_manager_->NewPage(&this->header_page_id_)
);
header_page->SetSize(num_buckets_);
header_page->SetPageId(header_page_id_);
// 使用 buffer pool 创建出 num_pages 个 block page
page_id_t block_page_id;
for (size_t i = 0; i < num_pages_; i++) {
buffer_pool_manager_->NewPage(&block_page_id);
buffer_pool_manager_->UnpinPage(block_page_id, false);
header_page->AddBlockPageId(block_page_id);
}
return header_page;
}
注意 buffer pool manager 的 NewPage() 和 FetchPage() 方法会对 page 进行一次 pin,所以用完这个 page 后别忘了 unpin 一下。
2.2 GetValue
这个函数在 hash table 中找到指定 key 对应的所有 values:
- 哈希表存有 header_page_id,用这个 page id 从 buffer pool 中拿到 header page
- 对 key 调用 hash function 获取哈希值,计算出 slot index,再通过这个 slot index 计算出 block index 和 bucket index
- 通过 header page 获取 block index 对应的 block page,然后从 bucket index 对应的 slot 开始查找,如果发生哈希冲突,则通过线性探测的方法向下继续查找,直到找到第一个空的 slot。
在线性探测向下查找的过程中:
- 如果查找到 block page 的底部,则要从下一个 block page 的开头继续查找。
- 如果查找到整个 hash table 的最后一个 slot,则要从第 0 个 slot 开始继续查找。
- 如果查找了一圈也没有查找到,则应当结束查找。
/*****************************************************************************
* SEARCH
*****************************************************************************/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::GetValue(Transaction *transaction, const KeyType &key, std::vector<ValueType> *result) -> bool {
table_latch_.RLock();
result->clear();
const size_t block_array_size = BLOCK_ARRAY_SIZE; // 一个 block page 中有多少个 buckets
// 计算出 key 的 slot index,以及对应的 block index 和 bucket index
auto *header_page = this->getHeaderPage();
auto [slot_index, block_index, bucket_index] = calculateIndex(key);
auto block_page_id = header_page->GetBlockPageId(block_index);
Page *block_page = buffer_pool_manager_->FetchPage(block_page_id);
block_page->RLatch();
auto *block = this->getBlock(block_page);
size_t cursor = slot_index; // 指向一个 slot,也就是某个 block_page 的某一个 bucket 上
// cycle 循环,从 slot index 开始循环遍历每一个 slot
do {
bucket_index = cursor % block_array_size;
if (!block->IsOccupied(bucket_index)) { // 发现空的 bucket,直接退出
break;
}
if (block->IsReadable(bucket_index)) { // 如果可读且 key 相当,则将 value 加入 result 中
if (compareKey(key, block->KeyAt(bucket_index))) {
result->push_back(block->ValueAt(bucket_index));
}
}
cursor = nextCursor(cursor, header_page, &block_index, &block_page_id, &block_page, &block);
} while (cursor != slot_index);
// 释放相关资源
block_page->RUnlatch();
buffer_pool_manager_->UnpinPage(block_page_id, false);
table_latch_.RUnlock();
buffer_pool_manager_->UnpinPage(header_page_id_, false);
return !result->empty();
}
/**
* cursor 是一个 block page 里面 slot 的位移,指向一个 slot
* 该函数获取一个 cursor 的下一个 cursor,同时处理好可能出现的跳转 block page、环形循环等情况
**/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::nextCursor(size_t cursor, HashTableHeaderPage *header_page, size_t *p_block_index,
page_id_t *p_block_page_id, Page **p_block_page,
HASH_TABLE_BLOCK_TYPE **p_block) const -> size_t {
cursor++;
if (cursor >= num_buckets_) {
cursor = 0;
}
const size_t block_offset = cursor / BLOCK_ARRAY_SIZE;
if (*p_block_index != block_offset) {
*p_block_index = block_offset;
auto *block_page = *p_block_page;
block_page->RUnlatch();
buffer_pool_manager_->UnpinPage(*p_block_page_id, false);
const auto block_page_id = header_page->GetBlockPageId(block_offset);
*p_block_page_id = block_page_id;
block_page = buffer_pool_manager_->FetchPage(block_page_id);
block_page->RLatch();
*p_block_page = block_page;
*p_block = getBlock(block_page);
}
return cursor;
}
/**
* 根据 key 计算出 slot index、block index 和 bucket index
**/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::calculateIndex(const KeyType key) -> std::tuple<slot_index_t, block_index_t, bucket_index_t> {
const slot_index_t slot_index = this->hash_fn_.GetHash(key) % num_buckets_; // 第一次 hash 是在哪个 slot 上
const auto block_array_size = BLOCK_ARRAY_SIZE;
const block_index_t block_index = slot_index / block_array_size;
const auto bucket_index = slot_index % block_array_size;
return {slot_index, block_index, bucket_index};
}
/**
* 判断 key 是否相等,相等则返回 true
**/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::compareKey(const KeyType& expected, const KeyType& actual) -> bool {
return comparator_(expected, actual) == 0;
}
/**
* 判断 value 是否相等,相等则返回 true
**/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::compareValue(const ValueType& expected, const ValueType& actual) -> bool {
return expected == actual;
}
2.3 Insert
向 hash table 中插入一个 KV pair,注意规定不允许存在两个完全相同的 KV pairs(key 相同但 values 不同是可以的)。
/*****************************************************************************
* INSERTION
*****************************************************************************/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::Insert(Transaction *transaction, const KeyType &key, const ValueType &value) -> bool {
table_latch_.RLock();
bool success = this->insertImpl(transaction, key, value);
table_latch_.RUnlock();
return success;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::insertImpl(Transaction *transaction, const KeyType &key, const ValueType &value) -> bool {
// 计算 key 的 slot index,以及相应的 block index 和 bucket index
const auto block_array_size = BLOCK_ARRAY_SIZE;
auto *header_page = this->getHeaderPage();
auto [slot_index, block_index, bucket_index] = calculateIndex(key);
auto block_page_id = header_page->GetBlockPageId(block_index);
auto *block_page = buffer_pool_manager_->FetchPage(block_page_id);
block_page->RLatch();
auto *block = getBlock(block_page);
size_t cursor = slot_index;
// cycle 循环
bool success = false;
do {
bucket_index = cursor % block_array_size;
if (block->IsReadable(bucket_index)) { // 如果可读,则不允许插入,否则可以插入
if (compareKey(key, block->KeyAt(bucket_index)) && compareValue(value, block->ValueAt(bucket_index))) {
block_page->RUnlatch();
break; // 说明已存在完全一样的 KV,直接返回错误
}
cursor = nextCursor(cursor, header_page, &block_index, &block_page_id, &block_page, &block);
continue;
}
block_page->RUnlatch();
block_page->WLatch();
success = block->Insert(bucket_index, key, value);
block_page->WUnlatch();
buffer_pool_manager_->UnpinPage(block_page_id, success);
buffer_pool_manager_->UnpinPage(header_page_id_, false);
return success;
} while (cursor != slot_index);
buffer_pool_manager_->UnpinPage(block_page_id, success);
buffer_pool_manager_->UnpinPage(header_page_id_, false);
return false;
}
2.4 Remove
从 block page 中移除掉指定的 KV pair:
/*****************************************************************************
* REMOVE
*****************************************************************************/
template <typename KeyType, typename ValueType, typename KeyComparator>
auto HASH_TABLE_TYPE::Remove(Transaction *transaction, const KeyType &key, const ValueType &value) -> bool {
table_latch_.RLock();
const auto block_array_size = BLOCK_ARRAY_SIZE;
auto *header_page = this->getHeaderPage();
auto [slot_index, block_index, bucket_index] = calculateIndex(key);
auto block_page_id = header_page->GetBlockPageId(block_index);
auto *block_page = buffer_pool_manager_->FetchPage(block_page_id);
block_page->RLatch();
auto *block = this->getBlock(block_page);
size_t cursor = slot_index;
// cycle 循环
bool success = false;
do {
bucket_index = cursor % block_array_size;
if (!block->IsOccupied(bucket_index)) { // 发现空的 bucket,直接退出
break;
}
if (block->IsReadable(bucket_index)) {
if (compareKey(key, block->KeyAt(bucket_index)) && compareValue(value, block->ValueAt(bucket_index))) {
block_page->RUnlatch();
block_page->WLatch();
block->Remove(bucket_index);
block_page->WUnlatch();
success = true;
break;
}
}
cursor = nextCursor(cursor, header_page, &block_index, &block_page_id, &block_page, &block);
} while (cursor != slot_index);
if (!success) {
block_page->RUnlatch();
}
buffer_pool_manager_->UnpinPage(block_page_id, success);
buffer_pool_manager_->UnpinPage(header_page_id_, false);
table_latch_.RUnlock();
return success;
}
Task 3: TABLE RESIZING
前面的 Hash Table 是固定数量的 slots,这个 task 需要实现对 Hash Table 的扩容。
扩容需要对原来的所有 KV pairs 重新计算哈希并存放到相应的 slot 中,设定是内存无法存放所有的 KV pairs,所以我们无法复用已有的 block pages,只能重新创建新的 header page 和 block pages,并遍历旧的 block pages 的所有 KV pairs,然后重新哈希后插入到新的 block pages 中。
/*****************************************************************************
* RESIZE
*****************************************************************************/
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::Resize(size_t initial_size) {
table_latch_.WLock();
const size_t block_array_size = BLOCK_ARRAY_SIZE;
num_buckets_ = initial_size * 2;
num_pages_ = (num_buckets_ - 1) / block_array_size + 1;
// 删除旧的 header page
auto *old_header_page = this->getHeaderPage();
auto old_header_page_id = header_page_id_;
std::vector<page_id_t> old_page_ids = std::vector<page_id_t>(old_header_page->GetSize());
for (size_t i = 0; i < old_header_page->GetSize(); i++) {
old_page_ids[i] = old_header_page->GetBlockPageId(i);
}
buffer_pool_manager_->UnpinPage(old_header_page_id, false);
buffer_pool_manager_->DeletePage(old_header_page_id);
// 生成新的 header page
makeHeaderPage();
// copy kv from old to new
for (auto pid : old_page_ids) {
auto *block_page = buffer_pool_manager_->FetchPage(pid);
auto *block = getBlock(block_page);
for (size_t i = 0; i < block_array_size; i++) {
this->insertImpl(nullptr, block->KeyAt(i), block->ValueAt(i));
}
buffer_pool_manager_->UnpinPage(pid, false);
buffer_pool_manager_->DeletePage(pid);
}
buffer_pool_manager_->UnpinPage(header_page_id_, true);
table_latch_.WUnlock();
}
Task 4: CONCURRENCY CONTROL
前面的 task 是假设只有单个线程的访问操作,这个 task 需要实现多线程环境下的并发控制。
并发控制主要借助于读写锁,在两个地方有读写锁:
- 表锁:也就是整个 Hash Table 会有一个锁,位于
LinearProbeHashTable类中。当对 Hash Table 进行 resize 时,会涉及到哈希表的元数据的更改,因此需要获得这个表锁的 write lock;而其余的 search、insert、delete 等只读写 block page 来改动 KV 的操作,只需要获得 read lock。 - block page latch:每个 block page 都有一个属于自己的 latch,读 block page 时需获得它的 read lock,而写 block page 时需要获得它的 write lock。
相关的锁实现已经实现在上面的代码中了。
实验运行结果