集群部署篇--Redis 集群动态伸缩
文章目录
- 前言
- 一、redis 节点的添加
-
- 1.1 redis 的实例部署:
- 1.2 redis 节点添加:
- 1.3 槽位分配:
- 1.4 添加从节点:
- 二、redis 节点的减少
-
- 2.1 移除主节点
-
- 2.1.1 迁移槽位
- 2.1.1 删除节点:
- 三、redis 删除节点的重新加入
-
- 3.1 加入节点:
- 四、redis 集群的故障转移:
-
- 4.1 某个主节点挂掉:
- 4.2 故障转移过程:
- 五、扩展:
-
- 5.1 redis 集群的cluster help命令:
- 5.2 redis 集群的cluster nodes命令:
- 5.3 `CLUSTER FORGET` 和 `del-node`:
- 总结
- 参考:
前言
在集群部署篇–Redis 集群分片模式 中我们知道了如果去部署redis 的分片集群,本文继续结束下集群节点的增加和删除。
一、redis 节点的添加
本文示例新添加3个节点,1主2从; redis 集群的一些操作指令可以参考 章节:五、扩展;
1.1 redis 的实例部署:
可以参考集群部署篇–Redis 集群分片模式 中 二、Redis 分片集群搭建:部署3个redis 实例;
1.2 redis 节点添加:
使用 --cluster add-node 进行节点添加:
docker exec -it fpredis-8379 redis-cli -p 8379 -a 123456 --cluster add-node 192.168.75.131:5379 192.168.75.131:8379
- docker exec -it fpredis-8379 redis-cli -p 8379 -a 123456 :用于连接某个redis 实例从而使用redis-cli 客户端
- –cluster add-node 添加节点命令
- 192.168.75.131:5379 新添加的节点信息 ip:端口
- 192.168.75.131:8379 已经存在于集群中的任意一个节点 ip:端口
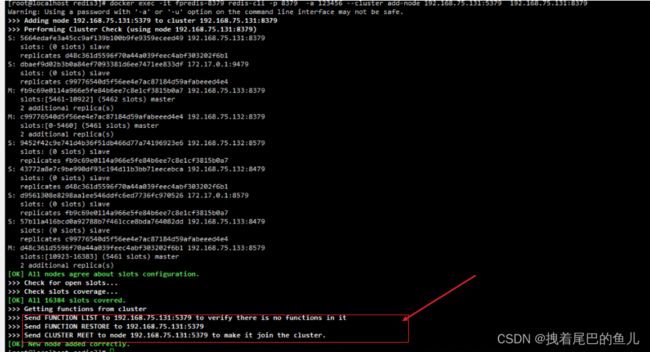
可以看到会将加入的节点信息 告知集群;
查看新加入的要成为主节点的 node id 信息:连接集群中任意一个节点 执行 cluster nodes 命令(cluster nodes命令 参考 章节: 5.2 redis 集群的cluster nodes命令)
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 -c cluster nodes

其中 第一列是node id,是改集群下节点的唯一id;
1.3 槽位分配:
使用 --cluster reshard 从已经存在的主节点中索取槽位:
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 --cluster reshard 192.168.75.131:8379
- docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 :用于连接某个redis 实例从而使用redis-cli 客户端
- –cluster reshard 交互式槽位分配命令
- 192.168.75.131:8379已经存在于集群中的任意一个节点 ip:端口

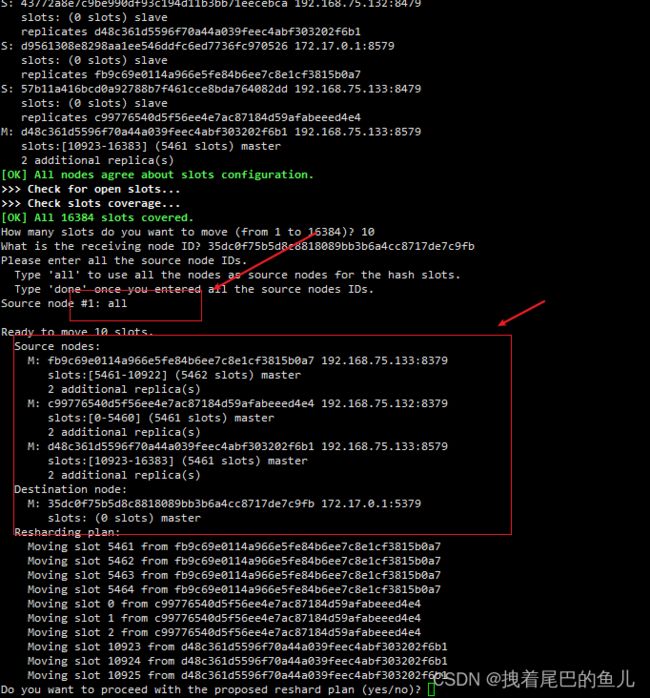
系统返回信息会提示我们要移动多少哈希槽,这里移动200个 输入200 然后回车;

然后 需要指定把这些哈希槽转移到哪个节点上,这里选择我们新加入的5379 节点:
35dc0f75b5d8c8818089bb3b6a4cc8717de7c9fb

选择迁移槽位模式:
-
all all 表示从所有的主节点中随机转移,凑够200个哈希槽;
-
done模式:需要你手动的去收入你要迁移的主节点id ,可以为多个接着可以输入 你要迁移的主节点的 节点id:
最后输入 done 表示输入完成;
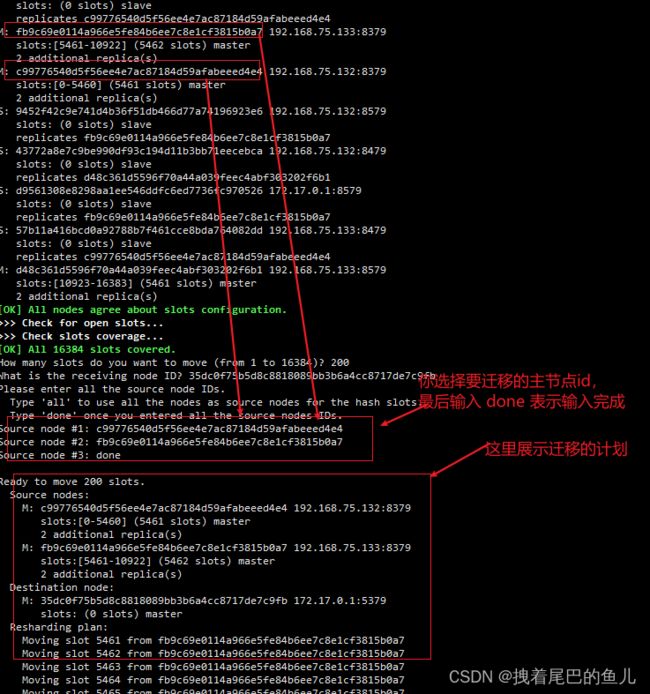
如果输入的不是主节点id 会有错误提示:

然后再输入yes,redis集群就开始分配哈希槽:
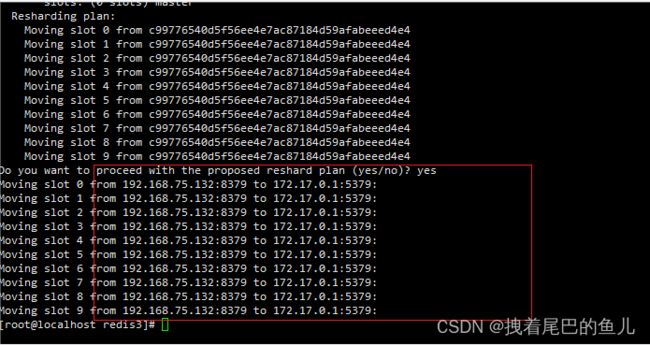
这样新加入的主节点就获取到了相应的槽位,以及随着迁移过来的数据;
1.4 添加从节点:
将已经存在的redis 实例添加到集群;
docker exec -it fpredis-8379 redis-cli -p 8379 -a 123456 --cluster add-node 192.168.75.131:5479 192.168.75.131:8379
其中192.168.75.131:5479 为新加入的节点ip 及端口,192.168.75.131:8379 为集群中任意节点ip 及端口
查看集群节点信息:
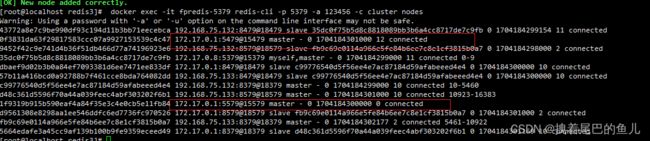
在对应的从节点上执行:
docker exec -it fpredis-5479 redis-cli -p 5479 -a 123456 CLUSTER REPLICATE 35dc0f75b5d8c8818089bb3b6a4cc8717de7c9fb
- docker exec -it fpredis-5479 redis-cli -p 5479 -a 123456 连接你要添加从节点的redis 实例 使用redis 客户端
- CLUSTER REPLICATE 添加从节点命令
- 35dc0f75b5d8c8818089bb3b6a4cc8717de7c9fb 要添加的主节点再集群中的唯一id
二、redis 节点的减少
集群中节点是由主从构成的,对于主从节点删除 也是不同的,对于注解点的删除,如果它拥有槽位需要先迁移槽位,在进行删除;对于从节点因为其只是同步主节点数据 可以直接将其从集群中删除;
2.1 移除主节点
2.1.1 迁移槽位
文中的例子是把拥有的全部槽位(10个),全部迁移到另外一台maser 节点上去
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 --cluster reshard 192.168.75.131:8379

迁移的过程和 1.3 槽位分配 流程相同,在Redis集群中执行槽位(slot)的迁移时,涉及到槽位内的所有键值对数据也会一起迁移到目标节点。迁移完成,我们连接集群中任意一个节点在看下节点信息;
docker exec -it fpredis-5479 redis-cli -p 5479 -a 123456 -c cluster nodes

通过观察可以发现迁移完成后 ,之前的主节点现在已经变成了从节点;
2.1.1 删除节点:
通过del-node 命令删除节点:
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 --cluster del-node 192.168.75.131:8379 43772a8e7c9be990df93c194d11b3bb71eecebca
-
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 主要是为了进入某个redis 实例中从而使用redis 的客户端redis-cli
-
–cluster del-node 集群删除命令
-
192.168.75.132:8379 为集群中任意一个节点(可以连接你正在操作机器上 redis集群的一个实例)
-
43772a8e7c9be990df93c194d11b3bb71eecebca 为要删除的节点id

当然也可以将改主节点的从节点进行删除,只要将 节点id 换为从节点id 即可:
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 --cluster del-node 192.168.75.131:8379 1f9319b915b590eaf4a84f35e3c4e0cb5e11fb84
三、redis 删除节点的重新加入
通过 --cluster add-node 将需要的节点加入到集群中,新加入的节点是 master 主节点,并且没有被分配槽位,可以为其分配槽位使其成为一个新的主节点,也可以让其成为已经存在主节点的一个从节点,流程同 一、redis 节点的添加:本章节进行简单的概况
3.1 加入节点:
docker exec -it fpredis-8379 redis-cli -p 8379 -a 123456 --cluster add-node 192.168.75.131:5579 192.168.75.131:8379
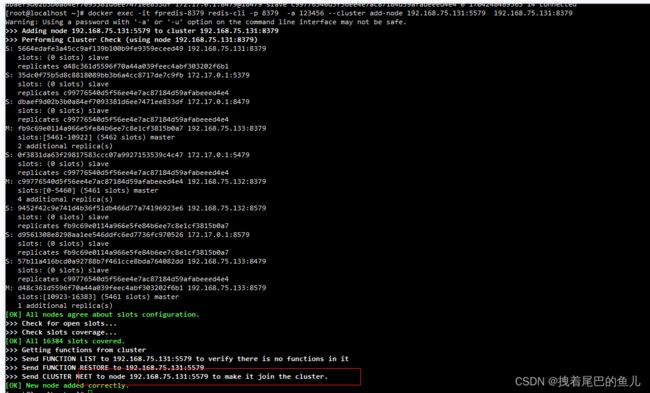
查看节点的情况:
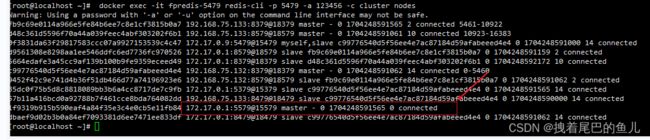
可以看到刚加入的节点是master 并且没有被分配槽位,重复 一、redis 节点的添加 可以为其分配槽位让其成为主节点,或者通过CLUSTER REPLICATE 命令让其成为某个主节点的从节点;
四、redis 集群的故障转移:
4.1 某个主节点挂掉:
查看集群节点的信息:
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 -c cluster nodes

此时直接停掉主节点 5379 这个实例:
docker stop fpredis-5379
因为 fpredis-5379 实例已经被停到,此时使用它的一个从节点查看集群情况
docker exec -it fpredis-5479 redis-cli -p 5479 -a 123456 -c cluster nodes

可以看到 fpredis-5379 主节点已经 端口连接,并且已经选举出了新的主节点,接管了之前的槽位:此时我们恢复fpredis-5379 实例,它也知会成为集群的一个从节点:

4.2 故障转移过程:
在Redis集群中,当一个主节点宕机时,会触发故障转移(failover)过程。这个过程由Redis集群内的自动故障检测和转移机制控制。故障转移的主要目的是选举出一个新的主节点,以接替失效的主节点的角色,保证集群的高可用性。下面是主节点宕机后故障转移的大致流程:
-
故障检测
其他主节点会定期向集群中的所有其他节点发送PING消息。如果一个主节点在指定的时间内未能回应,其他节点就会怀疑该节点发生了故障。 -
选举流程
当足够数量的主节点(集群中大多数节点,至少 N/2 + 1,其中N为集群主节点总数)都认为一个主节点失效时,该主节点的从节点将开始选举流程。从节点会根据预设条件(例如复制偏移量、运行时间等)选举出一个从节点成为新的主节点。 -
晋升过程
选举出的从节点会将自己转变为主节点。这个过程涉及更新配置和发送通知给集群中的其他节点以获得它作为主节点的承认。 -
配置更新
新晋升的主节点负责接管原主节点负责管理的所有键槽(hash slots),并与集群中的其他节点通信以更新集群状态。 -
数据同步
一旦成为新的主节点,它将继续处理客户端请求,并开始与可能存在的其他从节点进行同步。这些从节点之前可能跟随的是旧的主节点,现在需要与新的主节点同步数据。 -
故障恢复
如果原来的主节点后来恢复了,它将被集群视为一个普通的从节点,并可能开始复制新的主节点的数据。它的所有键槽(hash slots)都已经移交给了新的主节点。
这个故障转移过程通常是自动进行的,但是Redis提供了手动干预的命令。例如,你可以使用CLUSTER FAILOVER命令来触发从节点的故障转移过程。
在分布式系统中,故障转移完整性非常重要,是评估集群健壮性的一个关键指标。因此,Redis集群的设计目标之一是确保在面临节点宕机等各种故障时,能够迅速且自动地进行恢复。
五、扩展:
5.1 redis 集群的cluster help命令:
通过 cluster help 查看指令:
docker exec -it fpredis-5379 redis-cli -p 5379 -a 123456 --cluster help
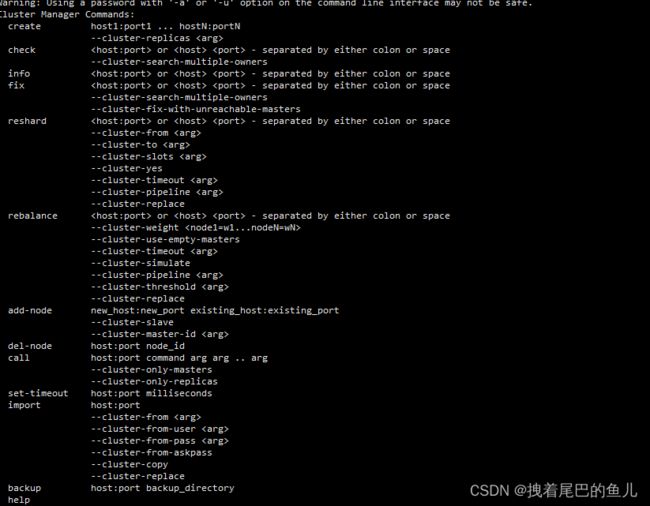
-
create:创建集群
-
check:检查集群
-
info:查看集群信息
-
fix:修复集群
-
reshard:在线迁移slot
-
rebalance:平衡集群节点slot数量
-
add-node:添加新节点
-
del-node:删除节点
-
set-timeout:设置节点的超时时间
-
call:在集群所有节点上执行命令
-
import:将外部redis数据导入集群
5.2 redis 集群的cluster nodes命令:
当你在命令行中执行 redis-cli CLUSTER NODES 命令时,Redis 会返回集群中所有节点的状态信息。这些信息按行分隔,每个节点的信息包括以下字段:
每个字段具体解释如下:
- node-id: 唯一标识每个节点的ID。
- ip:port: 节点的IP地址和端口号。
- flags: 节点的角色和状态信息,如:
master: 该节点是一个主节点。slave: 该节点是一个从节点。myself: 标识这是你当前与之交互的节点。fail?: 疑似失败状态(其他节点怀疑该节点失败)。fail: 失败状态(集群已经同意该节点失败)。handshake: 节点处于加入集群的握手过程中。noaddr: 没有有效的地址。
- master: 如果该节点是从节点,这里会显示它所属的主节点ID;如果该节点是主节点,则此字段为空。
- last-ping-sent: 上次发送
PING的时间戳(毫秒)。 - last-pong-received: 上次收到
PONG的时间戳(毫秒)。 - config-epoch: 节点的配置纪元,用于实现故障转移。
- link-state: 与此节点的连接状态,
connected表示已连接,disconnected表示断开连接。 - slots: 显示该节点负责的槽位。对于主节点,这会列出槽位范围和个别槽位;从节点则不显示此部分。
下面是一个简单的 CLUSTER NODES 输出示例:
07c37dfeb235213a872192d90877d0cd55635b91 127.0.0.1:7000@17000 master - 0 1407638882853 13 connected 0-5460
e7d1eecce10fd6bb5eb35b9f99a514335d9ba9ca 127.0.0.1:7001@17001 myself,master - 0 0 1 connected 5461-10922
在这个例子中,有两个主节点。第一个主节点 07c37dfeb235213a872192d90877d0cd55635b91 有槽位0到5460分配给它,并且目前状态是 connected。第二个节点 e7d1eecce10fd6bb5eb35b9f99a514335d9ba9ca 是你当前连接的节点(myself 标志),它掌管槽位5461到10922,状态也是 connected。
5.3 CLUSTER FORGET 和 del-node:
“del-node”是一个redis-trib 脚本的操作,该脚本用于管理Redis集群。redis-trib脚本中的"del-node"操作更像是一个集成操作,其实际上背后执行了如"CLUSTER FORGET"等一系列命令组合,来自动地移除一个节点。
-
CLUSTER FORGET:
- 这是一个Redis集群命令,用于让集群中的一个节点遗忘另一个节点。
- 执行
CLUSTER FORGET命令时,需要在集群中的每个节点上分别对要遗忘的节点执行该命令,除了被遗忘节点本身之外。 - 这是一种底层的操作,需要手动在每个节点上执行。
-
del-node:
- 这是
redis-trib(或者现在更常用的是redis-cli --cluster)工具的一个操作,用于从集群中移除节点。 redis-trib中的del-node命令会在内部自动地对集群中的所有其他节点执行CLUSTER FORGET命令,以移除目标节点。- 这可以被看作是一种更高层次的,自动化的操作,它简化了移除节点的复杂性,因为你只需运行一次命令,而不是手动到每个节点上去执行
CLUSTER FORGET。
- 这是
例如,使用 redis-cli 工具移除集群节点可以像这样操作:
redis-cli --cluster del-node <cluster-node-ip>:<port> <node-id>
这里
所以,CLUSTER FORGET是你需要手动在其他所有节点中对目标节点执行的底层命令,而del-node是redis-trib或redis-cli --cluster工具提供的一个自动化命令,它会帮你完成在集群中其他所有节点上执行CLUSTER FORGET的工作。
总结
Redis cluster 集群可以方便的通过集群命令进行节点的添加,槽位的分配,节点的下线操作。
参考:
深入学习Redis(四) Redis高可用之集群;