DevOps(11)
目录
66.在完全部署到所有用户之前,有哪些方法可以测试部署?
67.什么是持续测试?
68.如何做版本管理?
69.为什么要有监控系统?谈谈你对监控的理解?
70.监控体系监控哪些内容?
71.监控一般采用什么样的流程?
66.在完全部署到所有用户之前,有哪些方法可以测试部署?
由于必须回滚/撤销对所有用户的部署可能是一种代价高昂的情况(无论是技术上还是用户的感知),已经有许多技术允许"尝试"部署新功能并在发现问题时轻松“撤销”他们。这些包括:
蓝/绿测试/部署
在这种部署软件的方法中,维护了两个相同的主机环境-一个蓝色和一个绿色。(颜色并不重要,仅作为标识。)对应来说,其中一个是生产环境,另一个是预发布环境。
在这些实例的前面是调度系统,他们充当产品或者应用程序的客户网关。通过将调度系统指向蓝色或者绿色实例,可以将客户流量引流到期望的部署环境。通过这种方式,切换指向哪个部署实例(蓝色或者绿色)对用户来说是快速,简单和透明的。
当新版本准备好进行测试时,可以将其部署到非生产环境中。在经过测试和批准后,可以更改调度系统设置以将传入的线上流量指向他(因此他将成为新的站点)。现在,曾作为生产环境实例可供下一次候选发布使用。
同理,如果在最新部署中发现问题并且之前的生产实例仍然可用,则简单的更改可以将客户流量引流回到之前的生产实例-有效的将问题实例“下线”并且回滚到以前的版本。然后有问题的新实例可以在其他区域中修复。
金丝雀测试/部署
在某些情况下,通过蓝/绿发布切换整个部署可能不可行或者不是期望的那样。另一种方法是为金丝雀测试/部署。在这种模型中,一部分客户流量被重新引流到新的版本部署中。例如,新版本的搜索服务可以与当前服务的生产版本一起部署。然后,可以将10%的搜索查询引流到新版本,以在生产环境中对其进行测试。
如果服务那些流量的新版本没有问题,那么可能会有更多的流量会逐渐引流过去。如果仍然没有问题出现,那么随着时间的推移,可以对新版本增量部署,直到100%的流量都调度到新版本。这有效的“更替”了以前版本的服务,并让新版本对客户生效。
功能开关
对于可能需要轻松关掉的新功能(如果发现问题),开大人员可以添加功能开关。这是代码中的If-then软件功能开关,仅在设置数据值时才激活新代码。此数据值可以是全局可访问的位置,部署的应用程序将检查该位置是否执行新代码。如果设置了数据值,则执行代码;如果没有,则不执行。
这为开发人员提供了一个远程”终止开关“,以便在部署到生产环境后发现问题时关闭新功能。
暗箱发布
在暗箱发布中,代码被逐步测试/部署到生产环境中,但是用户不会看到更改(因此名称中有暗箱一词)。例如,在生产版本中,网页查询的某些部分可能会重定向到查询新数据源的服务。开发人员可收集此信息进行分析,而不会将有关接口,事务或结果的任何信息暴露给用户。
这个想法是想获取候选版本在生产环境负载下如何执行的真是信息,而不会影响用户或者改变他们的经验。随着时间的推移,可以调度更多负载,直到遇到问题或者认为新功能已经准备好供所有人使用。实际上功能开关标志可用于这种暗箱发布机制。
67.什么是持续测试?
持续测试是一个过程,他将自动化测试作为软件交付通道中内嵌的一部分,以尽快获得软件发布后业务风险的反馈。
持续测试与自动化测试的侧重点?
自动化测试旨在生成一组与用户故事或者应用程序要求先关的通过/失败的数据点。
持续测试侧重于业务风险,并提供有关软件是否可以发布的判断。要实现这一转变,我们需要停止询问“我们是否已经完成测试?”而是集中精力在“发布版本是否具有可接受的业务风险级别?”
为什么我们需要持续测试?
今天,整个行业的变化要求测试更多,同时自动化测试更难实现(至少使用传统工具和方法):
应用程序体系结构越来越分散和复杂,包含云,API,微服务等,并在单个业务事务中创建几乎无限的不同协议和技术组合。
由于Agile,DevOps和持续交付,许多应用程序现在两周发布一次,每天发布数千次。因此,可用于测试设计,维护和特别是执行的时间大大减少。
既然软件是业务的主要接口,那么应用程序故障就是业务失败,如果他影响用户体验,即使是看似微不足道的小故障也会产生严重后果。因此,与应用相关的风险已成为即使是非技术性商业领袖的主要关注点。
68.如何做版本管理?
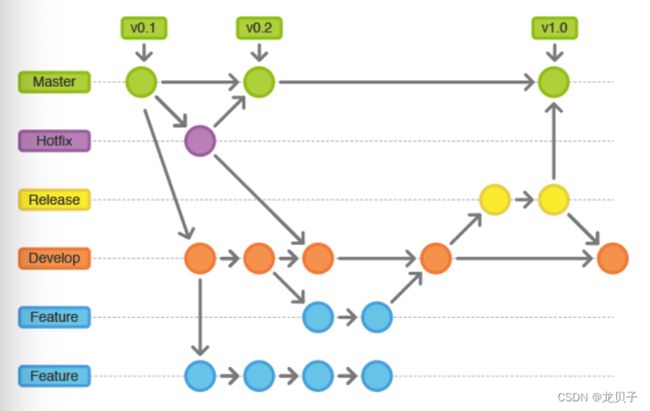 Master分支,主分支,这个分支最近发布到生产环境的代码,最近发布的Release,这个分支只能从其他分支合并,不能在这个分支直接修改。
Master分支,主分支,这个分支最近发布到生产环境的代码,最近发布的Release,这个分支只能从其他分支合并,不能在这个分支直接修改。
Develop分支,这个分支是我们的主开发分支,包括所有要发布到下一个Release的代码,这个主要合并与其他分支,比如Feature分支。
Feature分支,这个分支主要是用来开发一个新的功能,一旦开发完成,我们合并回Develop分支进入下一个Release。
Release分支,当你需要发布一个新Release的时候,我们基于Develop分支创建一个Release分支,完成Release后,我们合并到Master和Develop分支。
Hotfix分支,当我们在Production发现新的Bug时候,我们需要创建一个Hotfix,完成Hotfix后,我们合并回Master和Develop分支,所以Hotfix的改动会进入下一个Release。
69.为什么要有监控系统?谈谈你对监控的理解?
监控的目标?
发现问题:当系统发生故障报警,我们会收到故障报警的信息。
定位问题:故障邮件一般都写在某某主机故障,具体故障的内容,我们需要对报警内容进行分析。比如一台服务器连不上,我们就需要考虑是网络问题,还是负载太高导致长时间无法连接,又或者某开发触发了防火墙禁止的相关策略等,我们就需要去分析故障具体原因。
解决问题:当然我们了解到故障的原因后,就需要通过故障解决的优先级去解决该故障。
总结问题:当我们解决完重大的故障后,需要对故障原因以及防范进行总结归纳,避免以后重复出现。
具体而言?
对系统不间断的实时监控:实际上是对系统不间断的实时监控(这就是监控);
实时反馈系统当前状态:我们监控某个硬件,或者某个系统,都是需要能实时看到当前系统的状态,是正常,异常,或者故障。
保证服务可靠性安全性:我们监控的目的就是要保证系统,服务,业务正常运行。
保证业务持续稳定运行:如果我们的监控做的很完善,即使出现故障,能第一时间接收到故障报警,在第一时间处理解决,从而保证业务持续性的稳定运行。
70.监控体系监控哪些内容?
1.硬件监控
通过SNMP来进行路由器交换机的监控(这些可以跟一些厂商沟通来了解如何做),服务器的温度以及其他,可以通过IPMI 来实现,当然如果没有硬件全是云,直接跳过这一步骤。
2.系统监控
如CPU的负载,上下文切换,内存使用率,磁盘读写,磁盘使用率,磁盘inode使用率。当然这些都是需要配置触发器,因为默认太低会频繁报警。
3.服务监控
比如公司用的LNMP架构,Nginx自带Status模块,PHP也有相关的Status,MySQL的话可以通过Percona官方工具来进行监控。Redis这些通过自身的info获取信息进行过滤等。方法都累死。要么服务自带。要么通过脚本本身实现想监控的内容,以及报警和图形功能。
4.网络监控
如果是云主机又不是跨机房,那么可以选择不监控网络。当然你说我们是跨机房以及如何如何,推荐使用smokeping来做网络相关的监控,或者直接交给你们的网络工程师来做,因为术业有专攻。
5.安全监控
如果是云主机可以考虑使用自带的安全防护。当然也可以使用iptables。如果是硬件,那么推荐使用硬件防火墙。使用云可以购买方DDOS,避免出现故障导致Down机一天。如果是系统,那么权限,密码,备份,恢复等基础方案要做好。Web同时也可以使用Nginx+Lua来实现一个Web层面的防火墙。当然也可以使用集成好的OpenResty。
6.Web监控
Web监控的话题其实还是很多。比如可以使用自带的Web监控来监控页面相关的延迟,js响应时间,下载时间,等等。这里我推荐使用专业的商业软件监控宝或者听云来实现。毕竟人家全国各地都有机房(如果本身是多机房那就另说了)。
7.日志监控
如果是Web的话可以使用监控Nginx的50X,40X的错误日志,PHP的ERROR日志。其实这些需求无非是,收集,存储,查询,展示,我们其实可以使用开源的ELKStack来实现。Logstash(收集),Elasticsearch(存储+索索),Kibara(展示)。
8.业务监控
上面做了那么多,其实最终还是保证业务的运行。这样我们做的监控才有意义。所以业务层面这块的监控需要和开发以及总监开会讨论,监控比较重要的业务指标,(需要开会确认)然后通过简单的脚本就可以实现,最后设置触发器即可。
9.流量分析
平时我们分析日志都是拿awl sed xxx一堆工具来实现。这样对我们统计IP,PV,UV不是很方便。那么可以使用百度统计,Google统计,商业,让开发嵌入代码即可。为了避免隐私也可以使用Piwik来做相关的流量的逆袭。
10.可视化
通过Screen以及引入一些第三方的库来美化界面,同事我们也需要直到,订单量突然增加,突然减少。或者说突然来了一大波流量,这流量从哪儿来,是不是推广了,还是被攻击了。可以结合监控平台来梳理各个系统之间的业务关系。
11.自动化监控
如上我们做了那么多的工作,当然不能是一台一台的来加key实现。可以通过Zabbix的主动模式以及被动模式来实现。当然最好还是通过API来实现。
71.监控一般采用什么样的流程?
采集
通过SNMP,Agent,ICMP,SSH,IPMI等对系统进行数据采集;
存储
各类数据库服务,MySQL,PostgreSQL,时序库等
分析
提供图形以及时间情况信息,方便我们定位故障所在
展示
指标信息,指标趋势展示
报警
电环,邮件,微信,短信,报警升级机制
处理
故障级别裁定,找响应人员进行快速处理