【教学类-24-03】20230720《0-9数字描字帖+填空》(1页1份、1页2份)
作品展示:
0-9数字书写练习
(代码修改来源【教学类-24-02】20230306《数字火车-升序1-10取5条空3格》(中班《玩具总动员》))
 背景需求:
背景需求:
阿拉伯数字对幼儿日常生活非常重要——日常的“写学号”、插红牌子、放挂牌,都需要幼儿辨识或书写“数字”
因此我将“火车”的代码修改一下,直接变成了0-9的“数字描字帖”,在描字的同时,根据幼儿年龄段,不断增加难度,设置不等量的空格,让幼儿补全空缺数字(幼儿自己书写就会出现镜像字哦)
数字0-9排序的练习(年龄段规划)
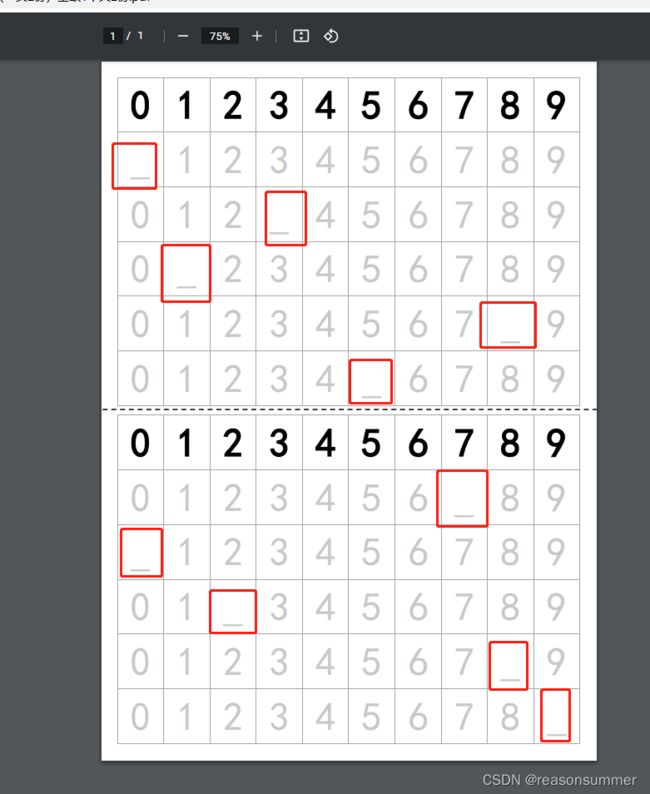
1、小班孩子:数字描字帖/或填写(缺失的1个空),实验后看看是不是要把字体变大(A4一页10*4行字)
2、中班孩子:数字描字帖、排序填空(缺3个空)、裁剪手环
3、大班孩子:数字描字帖、培训填空(5个空)、裁剪手环,抽签等。
因为是以描数字、写数字为目的,所以不设置整行空格让幼儿自己填写(空一行,小班、中班幼儿可能就空着不写了。),具体看教学后的反馈,再做调整
材料准备
第一种题型:WORD-A4一页1份(需要描11行数字,有点多)

代码展示:
# '''
# author:阿夏
# 原理:0-9升序,删除X个数字做填空.
# 结果:获得不重复题库,随机抽取11行10个数字的题型(一页1套,11行题目)
# 时间:2023-7-20 13:31
# '''
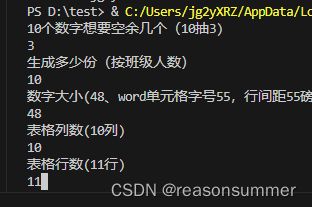
Number1=int(input('10个数字想要空余几个(10抽3)\n'))
num=int(input('生成多少份(按班级人数)\n'))
size=float(input('数字大小(48、word单元格字号55,行间距55磅)\n'))
weight=int(input('表格列数(10列)\n'))
height=int(input('表格行数(11行)\n'))
Number2=height
print('---------第1部分 制作题库(1-9之间升序排列的5个数字,其中有N个填空)----------')
import random
# 制作"数字+空格"
n1=[]
n2=[]
n3=[]
n4=[]
N1=[]
for x in range(1000):
for n in range(0,10):
a1=str(n)
n1.append(a1)
# print(n1) # ['0','1', '2', '3', '4', '5', '6', '7', '8', '9', ]
# 从n1里面随机抽取三个不重复的列表数字 可能会三个数字完全相连
a2 =random.sample(n1, Number1)
# print(a2) # ['10', '5', '8']现在是字符串格式
# 替换
for a3 in range(len(n1)): # 10个数字索引
for a4 in range(len(a2)): # 抽出来的3个数字的长度
if n1[a3] == a2[a4]:
# 如果原始列表n1的索引到的数字与3个数字a2的索引数字相同,就把这个数字改成“—”
n1[a3] = '_'
# 从n1提取数据,添加到新的列表n2
for a5 in n1:
n2.append(a5)
n1.clear() #要n1三个空的数据清除重新变成10个数字,便于再次提取3个
print(n2)
print(int(len(n2)/10))# 5条50个值['1', '2', '_', '4', '5', '6', '7', '_', '9', '_', '1', '2', '_', '_', '5', '6', '7', '_', '9', '10', '1', '2', '3', '_', '_', '6', '7', '8', '_', '10', '_', '2', '3', '4', '5', '6', '_', '8', '_', '10', '_', '_', '3', '4', '5', '_', '7', '8', '9', '10']
# 抽成10个一组
for a6 in range(int(len(n2)/10)):
print(a6)
a7=n2[a6*10:a6*10+10]
n3.append(a7)
print(n3)
# [['1', '2', '3', '_', '5', '_', '7', '8', '_', '10'], ['1', '2', '_', '_', '5', '6', '7', '8', '_', '10'], ['1', '2', '_', '4', '_', '6', '_', '8', '9', '10'], ['1', '_', '_', '4', '5', '6', '7', '8', '9', '_'], ['_', '_', '3', '4', '5', '_', '7', '8', '9', '10']]
# 遍历列表去重(保留所有不重复的
n4= []
for a8 in n3:
if a8 not in n4:
n4.append(a8)
print("缺失{}个空,1-10最大不重复组合数量:{} " .format(Number1,int(len(n4))))
# 缺失1个空,1-10最大不重复组合数量:10
# 缺失2个空,1-10最大不重复组合数量:45
# 缺失3个空,1-10最大不重复组合数量:120
# 缺失4个空,1-10最大不重复组合数量:210
# 缺失5个空,1-10最大不重复组合数量:252
# 缺失6个空,1-10最大不重复组合数量:210
# 缺失7个空,1-10最大不重复组合数量:120
# 缺失8个空,1-10最大不重复组合数量:45
# 缺失9个空,1-10最大不重复组合数量:10
# 缺失10个空,1-10最大不重复组合数量:1
# print('-----------第2部分,制作1-9倒叙---------------')
print('---------第2部分 word里面的表格----------')
# 表格位置
bg=[]
for x in range(1,height+1):
for y in range(0,weight):
ww='{}{}'.format('%02d'%x,'%02d'%y)
bg.append(ww)
print(bg)
print('---------第3部分 word单元格内写入随机抽取题目,批量N份word,并转为pdf----------')
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
# 新建一个”装N份word和PDF“的临时文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\0-9数字填空\零时Word')
list1=[]
for z in range(0,num): #多少份
# list1=[] # [[],[],[]]的样式
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\0-9数字填空\0-9数字填空(A4一页1份).docx')
# for b in range(0,5): # 共有5个表格
table = doc.tables[0] # 一共有1个表格
list2=random.sample(n4,Number2) # 10
print(list2)
# [['1', '_', '3', '4', '5', '6', '_', '_', '9', '10'], ['_', '_', '3', '4', '5', '6', '7', '8', '_', '10'], ['1', '2', '3', '4', '5', '_', '7', '_', '_', '10'], ['_', '2', '3', '4', '5', '_', '7', '_', '9', '10'], ['1', '_', '3', '_', '_', '6', '7', '8', '9', '10']]
list1.clear()
for xx in list2:
for yy in xx:
list1.append(yy)
print(list1)
for t in range(0,len(list1)): # 12组
pp=int(bg[t][0:2]) # 提取表格bg里面每个元素的第0个数字==单元格X坐标 t=索引数字
qq=int(bg[t][2:4])
k=list1[t] # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
run.font.size = Pt(size) #输入字体大小默认30号
run.font.color.rgb = RGBColor(200,200,200) #数字小,颜色深0-255
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\0-9数字填空\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/(打印合集)0-9数字填空(一页一份)空缺{}个共{}份.pdf".format(Number1,num))
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word') #递归删除文件夹,即:删除非空文件夹
终端输入:
第1行已有数字模板,所以只要11行数据

结果展示:
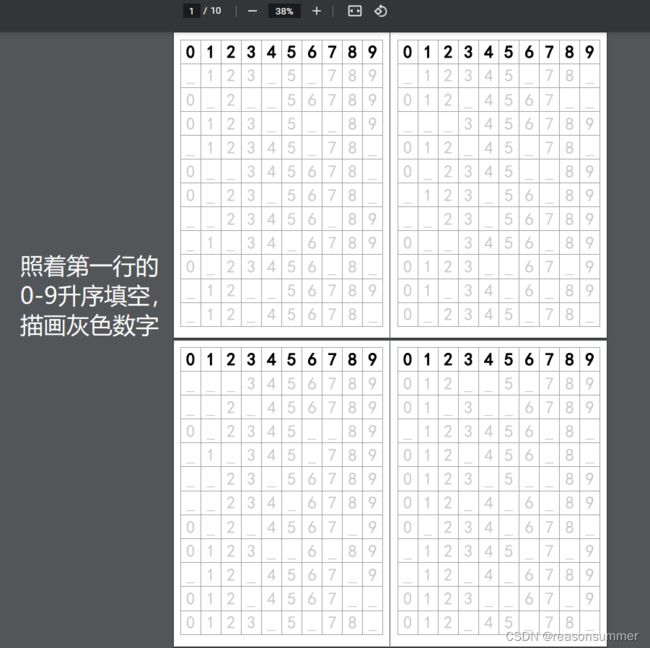
第二种题型:WORD-A4一页2份(需要描5行数字,题量适宜)

代码展示:
# '''
# author:阿夏
# 原理:0-9升序,删除X个数字做填空.
# 结果:获得不重复题库,随机抽取5行题型(一页2套)
# 时间:2023-7-20 13:31
# '''
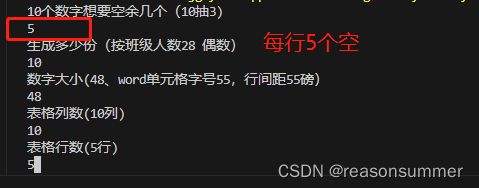
Number1=int(input('10个数字想要空余几个(10抽3)\n'))
num=int(input('生成多少份(按班级人数28 偶数)\n'))
size=float(input('数字大小(48、word单元格字号55,行间距55磅)\n'))
weight=int(input('表格列数(10列)\n'))
height=int(input('表格行数(5行)\n'))
Number2=height
print('---------第1部分 制作题库(1-9之间升序排列的5个数字,其中有N个填空)----------')
import random
# 制作"数字+空格"
n1=[]
n2=[]
n3=[]
n4=[]
N1=[]
for x in range(1000):
for n in range(0,10):
a1=str(n)
n1.append(a1)
# print(n1) # ['0','1', '2', '3', '4', '5', '6', '7', '8', '9', ]
# 从n1里面随机抽取三个不重复的列表数字 可能会三个数字完全相连
a2 =random.sample(n1, Number1)
# print(a2) # ['10', '5', '8']现在是字符串格式
# 替换
for a3 in range(len(n1)): # 10个数字索引
for a4 in range(len(a2)): # 抽出来的3个数字的长度
if n1[a3] == a2[a4]:
# 如果原始列表n1的索引到的数字与3个数字a2的索引数字相同,就把这个数字改成“—”
n1[a3] = '_'
# 从n1提取数据,添加到新的列表n2
for a5 in n1:
n2.append(a5)
n1.clear() #要n1三个空的数据清除重新变成10个数字,便于再次提取3个
print(n2)
print(int(len(n2)/10))# 5条50个值['1', '2', '_', '4', '5', '6', '7', '_', '9', '_', '1', '2', '_', '_', '5', '6', '7', '_', '9', '10', '1', '2', '3', '_', '_', '6', '7', '8', '_', '10', '_', '2', '3', '4', '5', '6', '_', '8', '_', '10', '_', '_', '3', '4', '5', '_', '7', '8', '9', '10']
# 抽成10个一组
for a6 in range(int(len(n2)/10)):
print(a6)
a7=n2[a6*10:a6*10+10]
n3.append(a7)
print(n3)
# [['1', '2', '3', '_', '5', '_', '7', '8', '_', '10'], ['1', '2', '_', '_', '5', '6', '7', '8', '_', '10'], ['1', '2', '_', '4', '_', '6', '_', '8', '9', '10'], ['1', '_', '_', '4', '5', '6', '7', '8', '9', '_'], ['_', '_', '3', '4', '5', '_', '7', '8', '9', '10']]
# 遍历列表去重(保留所有不重复的
n4= []
for a8 in n3:
if a8 not in n4:
n4.append(a8)
print("缺失{}个空,1-10最大不重复组合数量:{} " .format(Number1,int(len(n4))))
# 缺失1个空,1-10最大不重复组合数量:10
# 缺失2个空,1-10最大不重复组合数量:45
# 缺失3个空,1-10最大不重复组合数量:120
# 缺失4个空,1-10最大不重复组合数量:210
# 缺失5个空,1-10最大不重复组合数量:252
# 缺失6个空,1-10最大不重复组合数量:210
# 缺失7个空,1-10最大不重复组合数量:120
# 缺失8个空,1-10最大不重复组合数量:45
# 缺失9个空,1-10最大不重复组合数量:10
# 缺失10个空,1-10最大不重复组合数量:1
# print('-----------第2部分,制作1-9倒叙---------------')
print('---------第2部分 word里面的表格----------')
# 表格位置
bg=[]
for x in range(1,height+1):
for y in range(0,weight):
ww='{}{}'.format('%02d'%x,'%02d'%y)
bg.append(ww)
print(bg)
print('---------第3部分 word单元格内写入随机抽取题目,批量N份word,并转为pdf----------')
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
from docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColor
# 新建一个”装N份word和PDF“的临时文件夹
os.mkdir(r'C:\Users\jg2yXRZ\OneDrive\桌面\0-9数字填空\零时Word')
list1=[]
for z in range(0,int(num/2)): #多少份
# list1=[] # [[],[],[]]的样式
doc = Document(r'C:\Users\jg2yXRZ\OneDrive\桌面\0-9数字填空\0-9数字填空(A4一页2份).docx')
for b in range(0,2): # 共有2个表格
table = doc.tables[b] # 一共有2个表格
list2=random.sample(n4,Number2) # 随机抽取5个
print(list2)
list1.clear()
for xx in list2:
for yy in xx:
list1.append(yy)
print(list1)
for t in range(0,len(list1)): # 12组
pp=int(bg[t][0:2]) # 提取表格bg里面每个元素的第0个数字==单元格X坐标 t=索引数字
qq=int(bg[t][2:4])
k=list1[t] # 提取list图案列表里面每个图形 t=索引数字
print(pp,qq,k)
run=table.cell(pp,qq).paragraphs[0].add_run(k) # 在单元格0,0(第1行第1列)输入第0个图图案
run.font.name = '黑体'#输入时默认华文彩云字体
run.font.size = Pt(size) #输入字体大小默认30号
run.font.color.rgb = RGBColor(200,200,200) #数字小,颜色深0-255
# paragraph.paragraph_format.line_spacing = Pt(180) #数字段间距
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体')#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\0-9数字填空\零时Word\{}.docx'.format('%02d'%(z+1)))#保存为XX学号的电话号码word
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word/{}.docx".format('%02d'%(z+1))# 要转换的文件:已存在
outputFile = r"C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word/{}.pdf".format('%02d'%(z+1)) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile, 'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/(打印合集)0-9数字填空(一页2份)空缺{}个共{}份.pdf".format(Number1,num))
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/0-9数字填空/零时Word') #递归删除文件夹,即:删除非空文件夹
终端输入:
第1行已有数字模板,所以只要11行数据


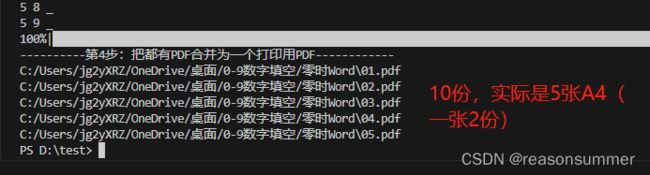
结果展示:
只有5页10份作业

每行随即5个空(中大班)

如果是小班的话,减少空格(空1-2)格,让幼儿熟悉题型
感悟:
1、练习绘画、书写(蜡笔、铅笔、记号笔),提升幼儿的手指肌肉灵活性。
2、联系数字书写,为学号书写做准备。
材料准备:

教学流程:
时间:2023年10月13日 下午14:20-14:45
班级:中3
人数:23人
目的:考虑到中班孩子写“学号字帖”速度一定比小班快多了,所以就拿了三套数字《0-9数字描字帖+填空》做补充材料(如果写完学号字帖,就拿一份0-9数字描字帖,练习写数字)





不少孩子很快就写完了0-9的数字,我鼓励他们做“手环”

















 感悟:
感悟:
1、每位孩子都尝试写了0-9字帖(3位孩子的书写手势不正确,描画速度缓慢)
2、10位孩子尝试剪了纸条,制作纸环
3、女孩喜欢做手镯、王冠。
4、一位男孩把纸条黏贴延长。
5、我示范了两个环的嵌套,2位女孩看了就模仿做了2个嵌套环,“可以继续套环哦!”我提示,两人都摇摇头,依旧做2环嵌套——没有实物演示,幼儿不理解最终效果,无法激发兴趣。
中班幼儿书写行为更自然。操作速度快。满地满桌的碎纸,收拾起来有点烦。