第五周:深度学习知识点回顾
前言:
讲真,复习这块我是比较头大的,之前的线代、高数、概率论、西瓜书、樱花书、NG的系列课程、李宏毅李沐等等等等…那可是花了三年学习佳实践下来的,现在一想脑子里就剩下几个名词就觉得废柴一个了,朋友们有没有同感,高中的留给高中老师,大学的给大学老师,研究生的留给谁了呢~但是呢,想想我马上要成为风口上的众多马上飞起的(* ̄(oo) ̄),不说废话,撸起袖子开干!!!
tips:不做具体视频课程学习,基本会按照有PPT的看PPT,知识点忘得比较干净的上课程里面查漏补缺,也不能忘得一干二净不是,还是留了点的O(∩_∩)O哈哈~
学习资料
我的专栏笔记为主(基本涵盖了下面的资料):



- 《AI for everyone》:对AI的基础了解,时间久了忘差不多的建议先看
- 《DeepLearning.TV》视频:适合小白的短视频介绍,基本可以跨过
- 《吴恩达DeeplearningAI》:2023最新课程,主要以这个 课程笔记为主
- 《李宏毅深度学习》:2022最新的课程
- 李飞飞老师视觉《Stanford CS231N》:无论如何要过一遍的视觉基础
- 书籍 - Ian Goodfellow的《Deep Learning》
- 人工智能数学基础:https://www.showmeai.tech/tutorials/83
知识点串联
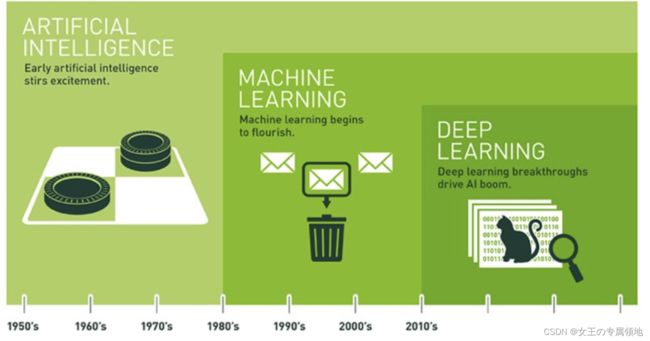

一、深度学习基础
深度神经网络目前的成功取决于三大推动因素:1. 数据;2. 算力;3. 算法。
1. 深度学习出现:深度学习是为了解决表示学习难题而被提出的,一般是指通过训练多层网络结构对未知数据进行分类或回归。
2. 深度学习思想:通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。
3. 深度学习分类:
> 有监督学习方法——深度前馈网络、卷积神经网络、循环神经网络等;
> 无监督学习方法——深度信念网、深度玻尔兹曼机,深度自编码器等。
4. 一些概念
- 表示学习(representation learning) 机器学习旨在自动地学到从数据的表示到数据的标记的映射。但是在某些领域(如图像、语音、文本等),如何从数据中提取合适的表示成为整个任务的瓶颈所在,而数据表示的好坏直接影响后续学习任务。与其依赖人类专家设计手工特征,表示学习希望能从数据中自动地学到从数据的原始形式到数据的表示之间的映射。
- 多层感知机(multi-layer perceptrons,MLP) 多层由全连接层组成的深度神经网络。多层感知机的最后一层全连接层实质上是一个线性分类器,而其他部分则是为这个线性分类器学习一个合适的数据表示,使倒数第二层的特征线性可分。
- 深度学习(deep learning,DL) 深度学习是把表示学习的任务划分成几个小目标,先从数据的原始形式中先学习比较低级的表示,再从低级表示学得比较高级的表示。这样,每个小目标比较容易达到,综合起来我们就完成表示学习的任务。
- 深度神经网络(deep neural networks,DNN) 很深的神经网络,利用网络中逐层对特征进行加工的特性,逐渐从低级特征提取高级特征。
二、神经网络发展与基础
1. 神经网络发展
阶段一:感知机

类比人类大脑运作原理抽象出来的最基础的模型,是神经网络和支持向量机的基础。
阶段二:多层感知机(Multi-Layer Perception ,MLP)
最典型的MLP包括包括三层:输入层、隐层和输出层,MLP神经网络不同层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。
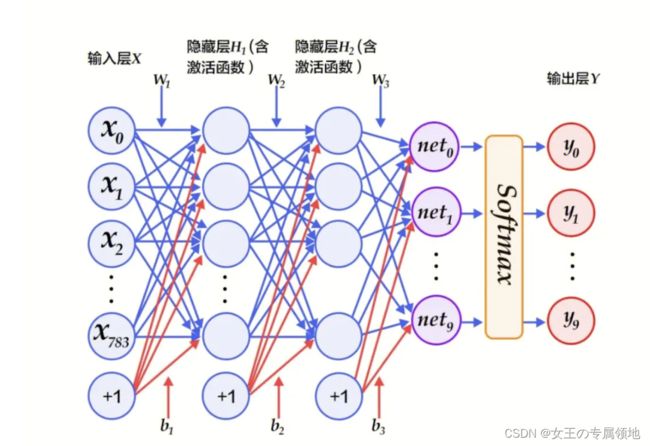
阶段三:深度神经网络
2. 神经网络基础
常用模型结构
前向传播和反向传播:重中之重!!!单独复习
激活函数:引入非线性因素增加神经网络模型的非线性。eg:Sigmoid、Softmax、Tanh、Relu、ELU等
超参数:寻找超参数最优值。eg:学习率(learning rate)、梯度下降法迭代的数量(iterations)、隐藏层数目(hidden layers)、隐藏层单元数目、激活函数( activation function)等
优化方法:采用优化方法使得模型在寻找最优参数的过程中朝着损失函数下降最快的方向更新;eg:基本梯度下降、Momentum 动量梯度下降、Adam 优化器等
损失函数:优化过程中减小输出与真实值间的差距;eg:分类损失函数(Logistic、交叉熵损失函数等)和回归损失函数(MSE、MAE、MSLE等);

常用的模型
三、深度神经网络模型
1. 卷积神经网络(Convolutional Neural Networks,CNN):
阅读资料:
- 强推:https://zhuanlan.zhihu.com/p/596559928
- https://paperswithcode.com/methods/category/convolutional-neural-networks
卷积神经网络(Convolutional Neural Networks,CNN)最早由Yann LeCun等人于1998年提出。CNN是一种专门用于处理具有网格结构数据(如图像、语音)的神经网络结构。
-
场景:图像分类、目标检测、图像生成等计算机视觉任务。
-
优点:对图像具有良好的特征提取能力,适用于处理大规模图像数据。
-
缺点:需要较大的计算资源和训练数据,不擅长处理位置不变的任务。
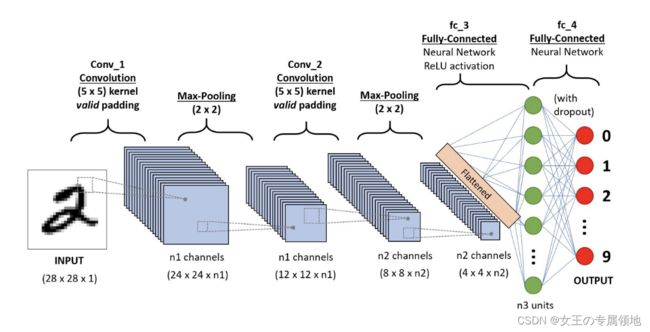
CNN的实现原理主要包括以下几个关键概念:
-
卷积层(Convolutional Layer):卷积层是CNN的核心组件。它通过在输入数据上应用滤波器(也称为卷积核)进行卷积操作,从而提取输入数据的特征。
-
滤波器(卷积核):滤波器是卷积操作的参数,它由一组可学习的权重组成。每个滤波器可以捕捉输入数据中的不同特征,如边缘、纹理等。
-
池化层(Pooling Layer):池化层用于减少特征图的空间维度,并保留关键特征。降维、防止过拟合。常用的池化操作包括最大池化和平均池化。
-
激活函数:激活函数引入非线性特性,使得CNN能够学习复杂的非线性关系。常见的激活函数包括ReLU、Sigmoid、Tanh等。
-
多层结构:CNN通常由多个卷积层、池化层和全连接层组成,通过逐渐提取抽象特征来学习和建模输入数据。
-
反向传播算法:CNN使用反向传播算法进行训练,通过最小化损失函数来更新网络的权重,使网络能够对输入数据进行准确分类或回归预测。
-
网络参数量与计算量:网络参数量来源卷积层卷积核的参数和偏置以及全连接层是基于连接权重和偏置等;计算量Flops。eg:卷积参数 = 卷积核长度x卷积核宽度x输入通道数x输出通道数+输出通道数(偏置)、卷积计算量 = 输出数据大小x卷积核的尺度x输入通道数
例:输入:224x224x3,输出:224x244x64,卷积核:3x3
参数量 = 3x3x3x64+64
计算量 = 224x224x64x3x3x3 # FLOPs的概念:Floating point operations,即浮点运算数量
CNN的实现原理基于以下主要思想:
-
局部感受野(Local Receptive Field):卷积层中的每个神经元只连接输入数据的局部感受野,通过共享权重和局部连接的方式来减少模型参数量。

-
参数共享(Weight Sharing):在卷积层中,采用参数共享的策略,使得不同位置的特征可以共享同一个滤波器的权重。这样可以提高网络的泛化能力,并减少需要学习的参数数量。
-
空间上下文特性:CNN通过卷积、池化等操作,能够保留输入数据的空间结构和局部相关性,从而更好地捕获图像中的局部和全局特征。
卷积神经网络在计算机视觉领域取得了许多重要的突破,如图像分类、目标检测、图像生成等任务。其独特的网络结构和实现原理使得它能够高效地处理图像数据并从中提取关键特征。
2. 递归神经网络(Recurrent Neural Networks,RNN)
递归神经网络(Recurrent Neural Networks,RNN)最早由Alex Graves、Jürgen Schmidhuber等人于1986年提出。RNN是一种用于处理序列数据的神经网络结构。与传统的前馈神经网络不同,RNN具有循环连接,可以对先前的输出进行反馈,从而在模型中引入时间依赖关系。
-
场景:自然语言处理(如文本生成、机器翻译)、语音识别等需要处理时序数据的任务。
-
优点:能够建模时序关系,处理可变长度的输入序列。
-
缺点:难以捕捉长期依赖关系,并且在训练过程中容易出现梯度消失或梯度爆炸问题。

RNN的实现原理基于以下几个关键概念:
-
循环连接(Recurrent Connection):RNN的隐藏层节点之间具有循环连接,使得模型能够在处理序列数据时保留先前的信息状态。当前时间步的隐藏状态会根据前一个时间步的输出和当前输入进行更新。
-
状态传递:RNN通过对隐藏状态进行传递,将序列数据在时间维度上进行处理。隐藏状态的传递使得RNN能够利用之前的信息进行预测或分类。
-
隐藏状态(Hidden State):RNN中的隐藏状态是模型在处理序列数据时保留的内部信息表示。每个时间步的隐藏状态根据当前输入和前一个时间步的隐藏状态计算得到。
-
激活函数:与其他神经网络结构一样,RNN的隐藏层通常也会使用激活函数来引入非线性特性,如tanh、ReLU等。
-
反向传播算法:RNN使用反向传播算法进行训练,在时间维度上反向传播损失梯度,并更新模型的权重参数。
RNN的实现原理使得其能够有效地处理序列数据,并应用于自然语言处理(NLP)、语音识别、机器翻译等任务。然而,传统的RNN在处理长期依赖关系时容易面临梯度消失或梯度爆炸的问题,限制了其在一些复杂场景下的表现。
为了应对这个问题,研究人员提出了一些变种RNN结构,如长短期记忆网络(LSTM)和门控循环单元(GRU),它们通过引入门机制和记忆单元,可以更好地捕捉长期依赖关系。
3. 长短期记忆网络(Long Short-Term Memory,LSTM)
长短期记忆网络(Long Short-Term Memory,LSTM)是由Sepp Hochreiter和Jürgen Schmidhuber于1997年提出的。LSTM是一种递归神经网络(RNN)的变种,用于解决传统RNN在处理长期依赖关系时容易遇到的梯度消失或梯度爆炸问题。
-
场景:时序数据建模任务,如语音识别、情感分析等。
-
优点:相比传统RNN,能够更好地捕捉长期依赖关系,避免梯度消失和梯度爆炸问题。
-
缺点:需要更多的计算资源和训练数据。

LSTM的实现原理基于以下几个关键概念:
-
细胞状态(Cell State):LSTM引入了一个称为细胞状态的额外组件,用于存储和传递网络中的长期信息。这个细胞状态在整个序列数据中保持一致,通过门控机制来控制信息的添加和删除。
-
门结构(Gate Structure):LSTM通过门控单元(Gate Unit)来控制细胞状态的变化。主要的门结构包括遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate),其中每个门都有其对应的权重和激活函数。
-
遗忘门(Forget Gate):遗忘门决定是否将细胞状态中存储的信息丢弃。它通过将前一个时间步的隐藏状态和当前输入传递到Sigmoid激活函数中,生成一个0到1之间的值。该值乘以细胞状态,用于决定需要从细胞状态中删除多少信息。
-
输入门(Input Gate):输入门决定哪些新信息将被加入到细胞状态。类似于遗忘门,输入门计算一个0到1之间的值,该值表示要更新细胞状态的程度。它通过将前一个时间步的隐藏状态和当前输入传递到Sigmoid激活函数,并结合一个tanh激活函数的输出来计算。
-
更新细胞状态:通过遗忘门和输入门的运算,可以更新细胞状态。遗忘门确定要从细胞状态中删除多少信息,输入门确定要增加多少新信息。这两者相结合后,可以根据更新公式更新细胞状态。
-
输出门(Output Gate):输出门决定细胞状态的哪部分将作为当前时间步的输出。它通过将前一个时间步的隐藏状态和当前输入传递到Sigmoid激活函数,并结合当前细胞状态的tanh激活函数结果来计算。
LSTM通过门控机制和细胞状态来实现对序列数据的长期依赖关系建模。它能够保留和传递长期的信息,并根据当前输入和先前的隐藏状态来决定如何更新细胞状态。
LSTM网络在许多序列数据相关的任务中取得了很好的效果,例如语言建模、机器翻译、情感分析等。
4. 生成对抗网络(Generative Adversarial Networks,GAN)
生成对抗网络(Generative Adversarial Networks,GAN)是由Ian Goodfellow等人于2014年提出的。GAN是一种用于生成模型的深度学习架构。
-
场景:生成与真实样本相似的样本,如图像生成、视频生成等。
-
优点:能够生成具有高度真实性的样本,具有较好的生成能力。
-
缺点:训练过程不稳定,需要较长的训练时间和大量数据。

GAN的实现原理基于以下几个关键概念:
-
生成器(Generator):生成器是GAN中的一部分网络,其目标是生成与训练数据类似的新样本。生成器接收一个随机噪声向量作为输入,通过反向传播算法来学习如何从随机噪声中生成合成样本。
-
判别器(Discriminator):判别器是GAN中的另一部分网络,其目标是区分生成器生成的样本和真实训练数据。判别器通过判断输入样本是来自生成器还是真实数据,并输出一个概率值(0-1之间)来表示样本的真实性。
-
对抗过程(Adversarial Process):GAN的核心思想是通过生成器和判别器之间的对抗过程来推动两个网络的学习。生成器试图欺骗判别器,生成越来越逼真的样本,而判别器则试图正确判断样本的真实性。这种对抗过程鼓励生成器不断改进生成的样本,使其更接近真实数据分布。
-
损失函数(Loss Function):GAN使用交叉熵来定义生成器和判别器的损失函数。生成器的损失函数是判别器产生的误差,即生成器希望最小化生成样本被错误分类的概率。判别器的损失函数是真实样本被正确分类和生成样本被错误分类的概率之和。
通过反复迭代生成器和判别器的训练过程,生成器学习生成逼真的样本,判别器学习更准确地区分真假样本。最终,生成器和判别器可达到一个动态平衡的状态,生成器能够生成与真实数据相似的样本。
GAN在图像生成、图像超分辨率、图像编辑和生成文本等领域取得了显著的成果。其对抗训练的思想和生成器与判别器的对抗过程使得GAN能够生成高质量的合成样本。
5. 注意力机制(Attention Mechanism)
注意力机制(Attention Mechanism)最早由Dzmitry Bahdanau等人在2014年的一篇论文中提出,并应用于机器翻译任务。注意力机制的思想在自然语言处理、计算机视觉等领域得到了广泛应用。
-
场景:用于处理具有不同重要性部分的任务,如机器翻译、图像描述等。
-
优点:能够根据任务的具体需求自动分配注意力到不同的部分,提升模型性能。
-
缺点:可能进行全局计算,计算复杂度较高,需要更多的计算资源。

注意力机制的实现原理如下:
-
上下文向量(Context Vector):在传统的序列到序列(Sequence-to-Sequence)模型中,通常只使用编码器-解码器架构,其中编码器将输入序列映射到固定长度的向量表示,解码器使用该向量生成输出序列。然而,这种固定长度的编码表示往往难以捕捉输入序列中的长距离依赖关系。注意力机制通过引入上下文向量,使解码器可以动态地对输入序列中的不同部分进行关注。
-
注意力权重(Attention Weights):注意力机制通过为输入序列中的每个位置分配一个权重,来决定在解码过程中需要关注的部分。这些注意力权重反映了输入序列中每个位置对当前解码器输出的重要性。常用的计算注意力权重的方法包括点积注意力、加性注意力和多头注意力等。
-
上下文向量计算:通过将注意力权重与输入序列中的对应位置进行加权相加,即可计算出上下文向量。上下文向量起到加权求和的作用,将输入序列中各个位置的信息编码为一个动态生成的向量。
-
注意力机制的使用:解码器可以使用上下文向量作为额外的输入,帮助生成更准确的输出。在每个时间步中,解码器根据上一时间步的隐藏状态和上下文向量来生成新的隐藏状态和输出。
通过注意力机制,模型可以根据输入序列中的不同部分的重要性动态地调整关注度,使得模型更加灵活地处理输入序列,并在生成过程中选择性地关注输入的不同部分。
注意力机制的应用范围非常广泛,包括机器翻译、文本摘要、问答系统、图像生成和语音识别等领域,代表性的如最近大火的transformer。注意力机制的引入提高了模型的性能,并使模型更具可解释性。
6. 强化学习模型(Reinforcement Learning,RL)
强化学习模型(Reinforcement Learning,RL)的提出可以追溯到上世纪50年代,由Richard Bellman等人在动态规划框架下首次提出。然而,后来的研究者如Arthur Samuel、Chris Watkins、Andrew Barto等人都对强化学习模型做出了重要贡献。
-
场景:通过与环境交互来学习决策策略的任务,如游戏智能体、自动驾驶等。
-
优点:能够在未知环境中进行学习和决策,并且能够自主探索和优化。
-
缺点:训练过程较长,对计算资源要求较高,对环境模型的识别能力较强。

强化学习模型的实现原理如下:
-
环境(Environment):强化学习模型的核心是一个与智能体进行交互的环境。该环境可以是真实世界的物理环境,也可以是虚拟环境或模拟器。环境会根据智能体的动作反馈相应的奖励信号和状态转换。
-
智能体(Agent):智能体是根据观察到的状态进行决策的实体。智能体根据当前的状态选择一个动作,并将其作用于环境中。智能体通过不断与环境的交互来学习,并试图通过优化累积奖励来达到长期的最优策略。
-
状态(State):状态表示智能体与环境交互的某一时刻的特定情况。在强化学习中,状态可以是完全可观察的(如棋盘游戏中的棋盘状态)或部分可观察的(如自动驾驶中的传感器读数)。
-
动作(Action):动作是智能体从当前状态中选择的行为。动作可以是离散的(如向左、向右)或连续的(如油门踏板的位置)。智能体根据当前的策略选择一个动作,并将其作用于环境中。
-
奖励(Reward):奖励是环境根据智能体的动作和当前状态所提供的反馈信号。奖励可以是正向的(表示行为的好处),也可以是负向的(表示行为的代价)。智能体的目标是通过最大化累积奖励来选择最优的动作策略。
-
学习算法:强化学习通过学习算法来指导智能体的学习过程。常见的学习算法包括Q-Learning、深度Q网络(DQN)、策略梯度法(Policy Gradient)、蒙特卡洛树搜索(Monte Carlo Tree Search)等。这些算法根据智能体的经验数据来更新值函数或策略,并不断优化智能体的决策能力。
强化学习的目标是让智能体通过与环境的交互,不断学习并逐步改进自己的策略,以获得最大的累积奖励。强化学习在许多领域获得了重要的应用,例如机器人控制、游戏玩法、自动驾驶、资源调度等。
7. 变分自编码器(Variational Autoencoder, VAE)
变分自编码器(Variational Autoencoder, VAE)是由Diederik P. Kingma和Max Welling在2013年的一篇论文中提出的。VAE是一种生成模型,用于学习输入数据的潜在表示并生成与原始数据类似的新样本。
-场景:生成任务(图像生成、文本生成),缺失值填补,数据降维
-优点:能够生成新样本,能够学习数据的潜在分布,可解释性强
-缺点:生成质量有时不如GANs,训练过程不稳定,分布假设可能过于简单

VAE的实现原理如下:
-
自编码器(Autoencoder):VAE基于自编码器的思想,并在此基础上进行了改进。自编码器由编码器(Encoder)和解码器(Decoder)两部分组成。编码器将输入数据映射为一个潜在空间的低维表示,解码器则将这个低维表示转化回原始数据的重建。
-
潜在空间(Latent Space):VAE引入了一个概率化的潜在空间,而不是传统自编码器的确定性潜在空间。潜在空间中的每个点都表示一个潜在变量,它对应着数据的某种特征或属性。通过引入概率分布,VAE能够对这些变量进行建模,并利用潜在变量重新生成新的样本。
-
变分推断(Variational Inference):VAE使用变分推断的方法来训练模型并推断潜在变量的后验分布。变分推断通过将潜在变量的后验分布近似为一个参数化的分布,然后利用重参数化技巧来优化模型。这使得VAE能够通过最大化边缘似然性来学习数据分布的潜在表示,并生成新的样本。
-
损失函数(Loss Function):VAE的训练过程通过最小化一个重构损失与一个正则项损失的组合来进行。重构损失衡量重建的样本与原始样本之间的差异,而正则项损失则用于约束潜在变量的先验分布与近似后验分布之间的差异。
-
采样与解码:在训练过程中,VAE可以从先验分布中采样得到一个潜在向量,并通过解码器将其映射回原始数据空间,从而生成新的样本。这使得VAE能够生成具有多样性的样本,并在潜在空间中实现插值操作。
VAE具有许多应用,如图像生成、特征学习、数据压缩和图像重建等。通过引入概率建模和变分推断的方法,VAE能够学习数据的潜在结构和分布,并生成具有多样性的样本。
这些模型只是深度学习领域中的一部分,并且不同模型在不同任务和场景下都有各自的适用性和性能差异。通常在实践中,根据具体的问题和数据集选择适合的模型是更为关键的。此外,模型的性能还受到超参数调整、训练数据质量和量级、计算资源等因素的影响。
五、深度学习应用
图像处理领域主要应用
- 图像分类(物体识别):整幅图像的分类或识别
- 物体检测:检测图像中物体的位置进而识别物体
- 图像分割:对图像中的特定物体按边缘进行分割
- 图像回归:预测图像中物体组成部分的坐标
语音识别领域主要应用
- 语音识别:将语音识别为文字
- 声纹识别:识别是哪个人的声音
- 语音合成:根据文字合成特定人的语音
自然语言处理领域主要应用
- 语言模型:根据之前词预测下一个单词。
- 情感分析:分析文本体现的情感(正负向、正负中或多态度类型)。
- 神经机器翻译:基于统计语言模型的多语种互译。
- 神经自动摘要:根据文本自动生成摘要。
- 机器阅读理解:通过阅读文本回答问题、完成选择题或完型填空。
- 自然语言推理:根据一句话(前提)推理出另一句话(结论)。
综合应用
- 图像描述:根据图像给出图像的描述句子
- 可视问答:根据图像或视频回答问题
- 图像生成:根据文本描述生成图像
- 视频生成:根据故事自动生成视频
六、未来发展趋势
深度学习网络模型在取得了巨大成功的同时,仍然面临一些挑战和未解决的难点。以下是其中一些主要难点:
-
数据不足问题:深度学习网络通常需要大量的训练数据来获得良好的性能。然而,在某些领域和任务中,获取大规模标注数据是非常昂贵和困难的。因此,解决数据不足的问题仍然是一个重要挑战。
-
非凸优化问题:深度学习网络的训练通常涉及到解决一个高维非凸优化问题,存在局部最优和鞍点等问题。在许多情况下,找到全局最优解是非常困难的,需要更强大和有效的优化算法。
-
解释性和可解释性:深度学习网络通常被认为是黑盒模型,其内部的决策过程很难解释和理解。在一些应用领域,例如医疗诊断和金融风险预测,模型的解释性是至关重要的。因此,如何提高深度学习模型的可解释性仍然是一个挑战。
-
对抗攻击和鲁棒性:深度学习模型往往对输入数据的微小扰动非常敏感,使其容易受到对抗攻击。对抗攻击是指通过对输入数据进行精心设计的修改,导致模型错误的分类或预测。提高深度学习模型的鲁棒性和对抗攻击的能力仍然是一个重要的研究方向。
未来深度学习的发展趋势如下:
1. 模型的轻量化和移动部署:未来深度学习的发展将会更注重模型的轻量化和在移动设备上的快速、高效部署。这将有助于将深度学习技术应用于更多的嵌入式系统和移动应用。
2. 自动化模型设计:自动化模型设计将起到重要作用,自动化搜索和优化方法将能够自动生成高性能的网络结构和配置,减少人工设计的时间和成本。
3. 多任务学习和跨模态学习:深度学习将更多地涉及到多任务学习和跨模态学习的方法。多任务学习可以使模型同时学习多个相关任务,从而提高学习效率和泛化能力。跨模态学习将允许模型从多种不同的数据模态中学习,使其能够更好地理解和利用多模态信息。
4. 强化学习和深度学习的结合:强化学习和深度学习的结合将成为一个重要的研究方向。这将使模型能够在未标注的环境中进行学习,并具备更强大的决策能力和适应性。
七、案例
- 深度学习流程可视化:https://playground.tensorflow.org/
- 目标检测:
- 人脸识别:
- 文本分类:
- 自动驾驶:
八、参考资料
- 吴恩达老师深度学习课程完整笔记
- 深度学习知识点全面总结
- 深度学习网络模型
本文汇总的相对不够深入,对于产品来说绰绰有余了,如果各位产品同学有余力可以再进一步研究下各种模型的训练过程,研发同学就不要偷懒的,必须得实操一遍流程!