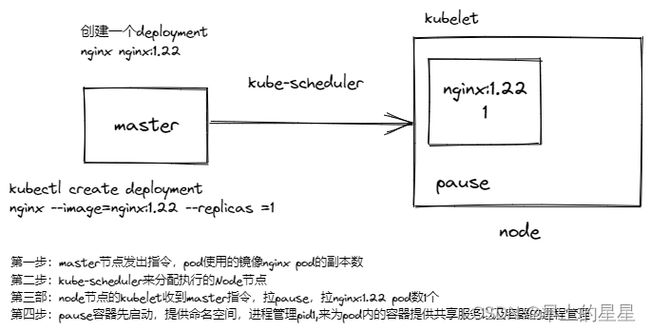
K8S POD
pod是k8s中最小的资源管理组件
pod也是最小运行容器化的应用的资源管理对象
pod是一个抽象的概念,可以理解为一个或者多个容器化应用的集合
在一个pod当中运行一个容器是最常用的方式。
在一个pod当中可以同时运行多个容器,在一个pod当中可以同时封装几个需要耦合的互相协作的容器
这些多个容器共享资源,也可以互相协作组成一个service单位
不论运行一个容器还是多个容器,K8S管理的都是pod而不是容器
一个pod内的容器,必须都运行在同一节点上。基于现代容器技术的要求,一个pod运行一个容器,一个容器只运行一个进程。
横向扩展,方便扩缩容
解耦,一个pod内运行多个容器,耦合度太高,一旦一个进程失败,整个pod将全部失败。实现解耦,基于pod可以创建多个副本,实现高可用,负载均衡
管理方便,简单直观
pod内的容器共享资源。共享机制:pause底层基础容器来提供共享资源的机制
pause是基础容器,也可以称为父容器。管理pod内容器的共享操作
pause还可以管理容器的生命周期
k8s提供了pause容器
1、为pod内的所有容器提供一个统一的命名空间
2、启动容器的pid命名空间,每个pod中都作为pid为1的进程(init进程),回收僵尸进程
3、创建pod时,先创建pause容器,然后拉取镜像,生成容器,最后形成pod
pod里面是容器,容器运行的是进程 pid
pause父进程 1 在pod内部管理容器进程
pause容器共享两种资源
网络:每个pod都会被分配一个集群内部的唯一ip地址,pod内的容器共享网络,POD在集群内部的ip地址和端口
pod内部的容器可以使用localhost互相通信,pod中的容器与外部通信时,从共享的资源当中进行分配。宿主机的端口映射
存储
pod可以指定多个共享的volume,pod内的容器共享这些vloume。
vloume可以实现数据的持久化
防止pod重新构建之后文件消失
总结:
每个pod都有一个基础容器pause容器
pause容器对应的镜像属于k8s集群的一部分。创建集群就会有pause这个基础镜像
pod里面包含了一个或者多个相关的容器(应用)
pod外再设置一个基础镜像:
pod内部有一组容器,挂了一个,就算这个pod失效了么?引入pause禁止,代表整个容器的组的状态
可以解决对pod内部容器整体状态的判断
pod内的容器共享IP,共享volume,解决了容器内网络通信的问题,解决了容器内部文件共享的问题
pod的分类:
自主式pod:pod不会自我修复,pod内容器的进程终止,被删除,缺少资源被驱逐,这个pod没有办法自愈
deployment daemanset
控制器管理pod:滚动升级,可以自愈(自动重启),可以管理pod的数量以及pod的扩缩容
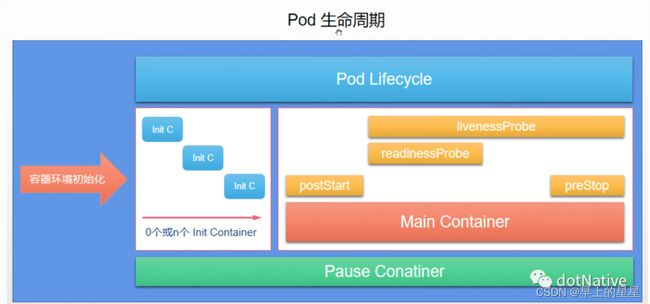
pod的生命周期:
1、pending 挂起状态
pod已被创建,但是尚未分配到运行他的node节点 (节点资源不够,需要等待其他pod的调度)
2、running 运行中 pod已经被分配到了运行节点 ,pod内部所有的容器都已经启动,运行状态正常,稳定
3、complete:容器内部的进程已经运行完毕,正常退出,未发生错误
successded:
4、faild:pod中的容器非正常退出。发生了错误,需要通过查看详情和日志来定位问题
5、UNkown:由于某些原因,k8s集群无法获取pod的状态,APIserver出了问题
6、terminating:终止中 正在被终止,还未终止 pod正在被删除,里面的容器正在终止,终止过程中,资源回收,垃圾清理,以及你终止过程中需要执行的一些命令
7、
存活探针和流量探针会伴随整个pod的生命周期,如果容器出了问题,pod将不再是ready状态
创建pod的容器分类:
1、基础容器:pause
2、init容器(初始化容器):init c
1和2这个过程中.pod的状态就叫init:0/3 1/3 2/3 3/3
3、业务容器
init容器的作用:
环境变量
可以在创建的过程中为业务容器定制好相关的代码和工具。
init容器独立与业务容器,他是单独构建的一个镜像,对业务容器不产生任何安全影响。
init容器能够以不同于pod内应用容器的文件系统视图运行。secrets 的权限 。应用容器无法访问secrets的权限
总结:init容器提供了应用容器运行之前的先决条件。提供了一种阻塞机制或者延迟机制来控制应用容器的启动
只有前置条件满足,才会创建pod内的应用容器。
k8s的一种机制,相当于计算器一样,88+88+88 也可以88*3
1、在pod的启动过程中,容器时按照初始化容器先启动,每个容器必须在下一个容器启动之前,要成功退出。
2、如果运行失败,会按照容器的重启策略进行指定动作,restartPolicy Aways never onFailu(非正常退出才会重启)
3、所有的init容器没有成功之前,pod是不会进入ready状态的
init容器与service无关,不能提供对外访问
4、如果重启pod,所有的Init容器,一定会重新执行 ‘
5、如果修改init容器的spec(参数),只限于image,其他的修改字段都不生效基于deployment
6、每个容器的名称都要唯一,不能重复
总结:
pause容器: 底层容器/基础容器
提供pod内容器的网络和存储共享,以及pod内容退出之后资源回收
init容器: 人为设定的 业务容器启动之前的必要条件。
pod的生命周期:
1、pasue基础容器
2、init容器---全部成功退出---业务容器
3、poststart prestop 容器的钩子
启动时命令和退出时的命令
4、探针:探测容器时的健康状态。伴随pod的整个生命周期(除了启动探针)
总结:Pod就是用来封装容器的,业务是容器。服务也是容器。端口也是容器
K8S的pod重启策略:
Always deployment的yaml文件只能是Always pod的yaml三种模式都可以
OnFailure:只有状态非0才会重启。正常退出是不重启的
Never:正常退出和非正常退出都不重启
容器退出了,pod才会重启
pod可以有多个容器,只要有一个容器退出,整个pod都会重启,pod内的所有容器都会重启。
docker的重启策略:
docker默认策略是never
on-failure:非正常退出时才会重启容器
always:只要容器退出都会重启
unless-stopped:只要容器退出就会重启。docker的守护进程启动时已经停止的容器,不再重启
单机部署:docker足够了
集群化部署: K8S
yaml文件快速生成
kubectl create deployment nginx1 --image=nginx:1.22 --replicas=3 --dry-run=client
--dry-run=client :只是调用api的对象不执行命令 crashloopbackoff:pod当中的容器退出,kubelet正在重启
imagespullbackoff:正在重试拉取镜像
errimagepull:拉取镜像出现错误 (网速太慢,镜像名字写错了,镜像仓库挂了)
Evrcte:POD被驱赶 (node节点资源不足,不够部署POD,或者是资源不足,kubelet自动选择一个pod驱逐)
POD内的容器使用节点资源的限制:
1、request:需要的资源
2、limit:最高能占用系统多少资源
limit:需要多少,最多也只能占用这么多
两个限制:
cpu
cpu的限制格式:
1 2 0.5 0.2 0.3
1 可以占用1个cpu
2 可以占用两个
0.5 半个
0.2 一个cpu的五分之一
0.1 是最小单位
要么是整数要么是小数点后只能跟一位,最小单位是0.1
m来表示cpu
cpu分片时间原理:
cpu时间分片: 通过周期性的轮流分配cpu时间给各个进程,多个进程可以在cpu上交替执行
在k8s当中就是表示占用的cpu比率
m:milllicores 单位
1
1000m
500m
2000m
100m就是最小单位
内存:
ki
mi
gi
ti
K8S怎么设置拉取镜像的策略:
默认策略:
ifNotpresent:如果本地镜像有,就不在拉取,本地没有才会去镜像仓库拉取
Alway:不论镜像是否存在,创建时(重启)都会重新拉取镜像
Never:仅仅使用本地镜像,本地没有也不会主动拉取
pod的容器健康检查
探针
probe
k8s对容器执行的定期检查,诊断
探针有三种规则:
1、存活探针:
livenessProbe 探测容器是否正常运行,如果发现探测失败,会杀容器,容器会根据重启策略来决定是否重启 ,不是杀掉pod
2、流量/就绪探针:
探测容器是否进入ready状态,并且做好接受请求的准备
探测失败 READY 0/1 没有进入ready状态。service会把这个资源对象的端点从当中剔除,service也不会把这个请求转发到这个pod
3、启动探针:
只是在容器启动之后开始检测,容器内的应用是否启动成功。在启动探测成功之前,所有的其他探针都会处于禁用状态
但是,一旦启动探针结束,后续的操作不再受启动探针的影响。
在一个容器当中的可以有多个探针。
启动探针:只在容器启动时探测
存活:
就绪
probe的检查方法:
1、exec探针:在容器内部执行命令,如果命令的返回码是0,表示成功
适用于需要在容器内自定义命令来检查容器的健康的情况
2、httpGet:
对指定ip加端口的容器发送一个httpGet的请求。响应状态码大于或者等于200,但是要小于400 ,在这区间的都是成功
200 正常 300 重定向 400客户端错误 500服务端错误
适用于检查容器能否响应http的请求,web容器(nginx,tomcat )
3、tcpsocket:
端口,对指定端口上的容器的ip地址进行tcp检查(三次握手),端口打开,任务探测成功
检查特定容器的端口监听状态
80
999
telnet 192.168.211.10:80
诊断结果:
1、成功,容器通过了,正常运行
2、失败,只有存活探针会重启,
3、未知状态:诊断失败
livenssprobe
存活探针:
杀死容器,重启
readinessProbe
就绪探针,pod的状态是runing ready状态是notready,容器不可以提供正常的访问
tcpSocket只是监听容器上的业务端口能否正常通信。8081没有,8080还在,也就是正常的端口还是可以访问。
如果更改了容器的启动端口
mysql 3306 33066
tcp--->33066
存活探针和就绪探针,会伴随整个pod的生命周期。
startupProbe:启动探针
如果探测失败,pod的状态是notReady
启动探针探测容器失败,会重启pod
启动探针没有成功之前,那么后续的探针都不会执行。
启动探针成功之后,在pod的生命周期内不会再检测探针
重启了pod之后相当于重新部署了一个初始版的新的容器。
总结:
1、在一个yaml当中可以有多个探针,启动,存活,就绪都针对一个容器
2、启动探针的优先级是最高的 只有启动探针“成功”,后续的探针才会执行
3、启动探针成功之后。后续除非重启pod,不会再触发启动探针了
4、在pod的生命周期当中,伴随pod,一直存在,一直探测的是存活探针,就绪探针
5、在pod的生命周期当中,后续的条件是满足哪个探针的条件,就触发哪个探针的条件
6、就绪探针,如果不影响容器运行,status:runing,这个时候不会重启,但是容器退出的话,就绪探针也会重启
容器启动和退出时的动作
poststart:容器启动钩子,容器启动之后触发的条件
prestop:容器退出钩子,容器退出之后触发的条件
volumeMounts:
- name: test1
mountPath: /opt
readOnly: false
声明容器内部的挂载目录
要给挂载卷取一个名字,不挂载卷的名字不能重复
readOnly: false
volumes:
- name: test1
hostPath:
Path: /opt/test
type: DirectoryOrCreate
声明的是Node节点上和容器的/opt的挂载目录
挂载卷的名称和要挂载的容器内挂载卷名称要一一对应
hostPath:指定和容器的挂载目录
type:DirectoryOrCreate:如果节点上的目录不存在,自动创建该目录
# pod会经常被重启,销毁,一旦容器和node节点做了挂载卷,数据就不会丢失
启动和退出的作用:
1、启动可以自定义配置容器内的环境
2、通知机制,告诉用户容器启动完毕
3、退出时,也可以执行自定义命令,删除或者生成一些必要的程序,自定义销毁方式,自定义资源回收的方式以及容器的退出等待时间在这个pod的生命周期事件当中,把启动探针,存活探针,就绪探针加入到yaml文件当中
pod的重启策略:
在k8s当中都是重启pod
Always:默认策略------>当pod内的容器退出,不论是一个还是两个容器退出,整个pod都会重启
never:当pod内的容器退出时,退出一个还是退出N个,pod都不重启
onFailure:当pod内的容器退出时,状态码0,整个pod都不会重启,只有一个或者N个容器非正常退出,状态码非0,整个pod才会重启