PyTorch源码解读之torch.utils.data.DataLoader使用方法
目录
- 一、简介
- 二、参数
- 三、示例
一、简介
官网:https://pytorch.org/docs/stable/data.html?highlight=torch%20utils%20data%20dataloader#torch.utils.data.DataLoader
dataloader.py脚本的的github地址:https://github.com/pytorch/pytorch/blob/master/torch/utils/data/dataloader.py
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要。
torch.utils.data.DataLoader是数据加载器,结合了数据集dataset和取样器sampler,并且提供一个在dataset上的可迭代对象。DataLoader支持map样式和iterable样式的数据集,支持单进程或多进程加载、自定义加载顺序以及可选的自动批处理(排序)和内存固定。
在训练模型时使用到此函数,用来把训练数据分成多个小组,此函数每次抛出一组数据。直至把所有的数据都抛出。就是做一个数据的初始化。
CLASS torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
二、参数
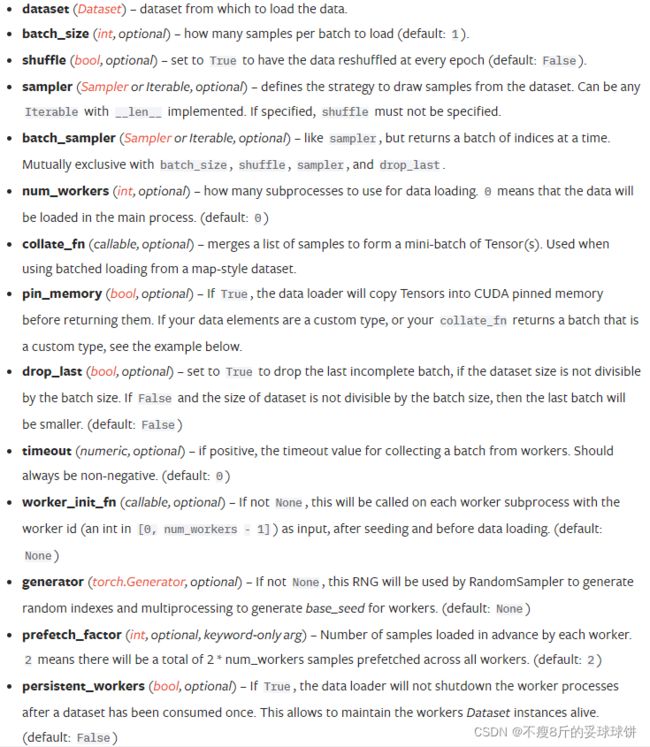
- dataset(Dataset)-从这个数据集里加载数据。这个就是PyTorch已有的数据读取接口(比如torchvision.datasets.ImageFolder)或者自定义的数据接口的输出,该输出要么是torch.utils.data.Dataset类的对象,要么是继承自torch.utils.data.Dataset类的自定义类的对象。
- batch_size(int, optional) -每个batch里面加载多少样本(default:1),根据具体情况设置即可。
- shuffle(bool, optional) -设置为True时,在每一个epoch都重新洗牌数据。一般在训练数据中会采用。
- sampler(Sampler or iterable, optional) -定义从数据集提取样本的策略,可以是任何带有__len__()实现的可迭代对象。如果sampler被指定了,那么shuffle一定不能被指定,二者是互斥的。一般默认即可。
- batch_sampler(Sampler or iterable, optional) -像sampler一样,但是一次返回一批索引。与batch_size、shuffle、sampler和drop_last互斥,一般采用默认。
- num_workers(int, optional) -使用多少子进程用于数据加载,0意味着使用主进程加载数据。(default:0)。从注释可以看出这个参数必须大于等于0,大于0的数表示通过多个进程来导入数据,可以加快数据导入速度。
- collate_fn(callable, optional) -合并样本列表形成一小批张量。是用来处理不同情况下的输入dataset的封装,一般采用默认即可,除非你自定义的数据读取输出非常少见。当从map-style数据集中加载批量数据时,使用这个参数。
- pin_memory(bool, optional) -如果设置为True,数据加载器将会在返回张量之前,将它们复制到CUDA的固定内存中,也就是一个数据拷贝的问题。
- drop_last(bool, optional) -若为True,当数据集大小不能被batch size整除时,丢掉最后不完整的batch;若为False,当数据集大小不能被batch size整除时,最后一个batch会小些。(default:false)
- timeout(numeric, optional) - if positive, the timeout value for collecting a batch from workers. Should always be non-negative.(default: 0)。是用来设置数据读取的超时时间的,超过这个时间还没读取到数据的话就会报错。
- worker_init_fn(callable, optional)If not None, this will be called on each worker subprocess with the worker id (an int in [0, num_workers - 1]) as input, after seeding and before data loading. (default: None)
- prefetch_factor(int, optional,keyword-only arg) - 1每个进程提前加载的样本数,2意味着在所有的进程中总共有2*num_workers个样本提前获得。
- persistent_workers(bool, optional) - If True, the data loader will not shutdown the worker processes after a dataset has been consumed once. This allows to maintain the workers Dataset instances alive.(default: False)
在__init__中,RandomSampler类表示随机采样且不重复,所以起到的就是shuffle的作用。BatchSampler类则是把batch size个RandomSampler类对象封装成一个,这样就实现了随机选取一个batch的目的。这两个采样类都是定义在sampler.py脚本中,地址:https://github.com/pytorch/pytorch/blob/master/torch/utils/data/sampler.py。以上这些都是初始化的时候进行的。当代码运行到要从torch.utils.data.DataLoader类生成的对象中取数据的时候,比如:
train_data=torch.utils.data.DataLoader(...)
for i, (input, target) in enumerate(train_data): …
就会调用DataLoader类的__iter__方法,__iter__方法就一行代码:return DataLoaderIter(self),输入正是DataLoader类的属性。因此当调用__iter__方法的时候就牵扯到另外一个类:DataLoaderIter(附学习链接),此处不做展开介绍。
三、示例
生成迭代数据非常方便,请看如下示例:
"""
批训练,把数据变成一小批一小批数据进行训练。
DataLoader就是用来包装所使用的数据,每次抛出一批数据
"""
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
# 把数据放在数据库中
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
# 从数据库中每次抽出batch size个样本
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
)
def show_batch():
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
# training
print("steop:{}, batch_x:{}, batch_y:{}".format(step, batch_x, batch_y))
if __name__ == '__main__':
show_batch()
结果:

变量类型:

参考链接:
https://blog.csdn.net/u014380165/article/details/79058479
https://www.cnblogs.com/demo-deng/p/10623334.html
https://blog.csdn.net/baidu_35120637/article/details/111378758