ROS高效进阶第四章 -- 机器视觉处理之ros集成yolov5实现目标检测
机器视觉处理之ros集成yolov5实现目标检测
- 1 资料
- 2 正文
-
- 2.1 深度学习框架和深度学习算法
- 2.2 yolov5_detector 样例
- 3 总结
1 资料
本文是机器视觉处理系列的第四篇,我们将使用当前比较流行的yolov5目标检测算法进行测试。所谓目标检测,就是识别出图像里的人和物。本文依然基于本系列第一篇 ROS高效进阶第四章 – 机器视觉处理之图像格式,usb_cam,摄像头标定,opencv和cv_bridge引入 的 robot_vision 进行扩充。
再次强调下本文样例的测试环境是:Thinkpad T14 i7 + Nvidia MX450,系统是ubuntu20.04,ros是noetic。
本文参考资料如下:
(1)12大深度学习开源框架(caffe,tf,pytorch,mxnet等)快速入门项目
(2)Nvidia tensorRT github
(3)ROS(noetic)+ubuntu20.04+virtualenv(python3.7.1)+YOLOV5实现目标检测
(4)yolov5 github
(5)解决yolov5 AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘
2 正文
2.1 深度学习框架和深度学习算法
(1)深度学习框架和算法的关系,就像厂房和产品的关系,框架生成算法。
深度学习框架为实现深度学习算法提供了一套完整的解决方案,可以简化复杂算法的编码过程,使得开发者可以更加集中精力在模型设计和优化上,而无需关心底层的计算细节。框架还会提供友好的API接口,方便进行模型训练、评估和优化。
当前比较流行的深度学习开源框架包括:TensorFlow,PyTorch等。前些年TensorFlow用的多,现在PyTorch更火一些,本文使用的yolov5算法就是基于PyTorch,用来实现实时目标检测,特点就是快。yolov5的github:yolov5 github ,具体细节暂不深究。
这里推荐一篇文章,其系统梳理了当前各种深度学习开源框架的特点:12大深度学习开源框架(caffe,tf,pytorch,mxnet等)快速入门项目
(2)ONNX:理论上任何深度学习算法,都可以使用不同的框架设计实现。更进一步,同一个深度学习算法,也应该能在不同的框架内跑起来,于是有了ONNX(Open Neural Network Exchange)。
ONNX定义了一个包含神经网络图结构和张量数据类型的通用模型格式,其使得模型可以跨越不同的框架进行共享,并且可以在各种硬件上高效地执行。有了它,开发人员可以选择最适合他们需求的工具进行模型的设计、训练、优化和部署,而无需担心模型格式的兼容性问题。
(3)TensorRT:在自动驾驶领域,实车运行了各种深度学习算法,他们统一使用ONNX模型,而模型的运行时环境普遍采用英伟达的TensorRT。
TensorRT是NVIDIA开发的深度学习推理(Inference)优化器和运行时库,其目标是加速深度学习模型的部署和推理过程,支持在嵌入式环境下,高效运行深度学习算法。这个是TensorRT的github:Nvidia tensorRT github
2.2 yolov5_detector 样例
(1)安装依赖:请把yolov5的依赖列表 requirements.txt 下载到本地,然后使用 pip3 安装依赖:
pip3 install -r requirements.txt
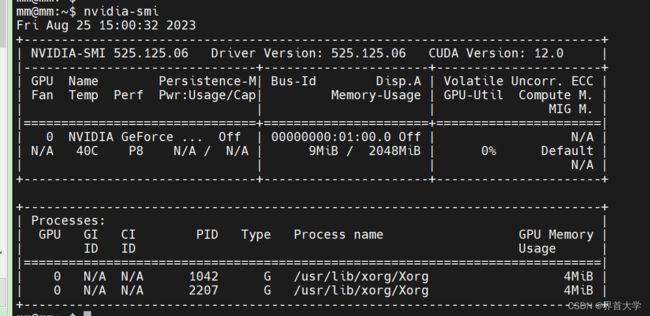
(2)安装cuda驱动:由于我的笔记本是ubuntu系统,安装系统时,其默认不支持Nvidia GPU的cuda驱动,而是使用英特尔的集成显卡驱动,因此需要给笔记本单独安装cuda。这里是thinkpad T14 Nvidia MX450的驱动链接:Nvidia MX450 cuda驱动 ,下载后执行,其在安装过程中会自动禁用掉intel集成显卡,然后继续安装cuda。cuda安装成功后,使用nvidia-smi命令校验:
(3)在 robot_vision 中创建yolov5_detector
cd ~/catkin_ws/src/robot_vision
mkdir scripts
touch scripts/yolov5_detector.py launch/yolov5_detector.launch
(4)yolov5_detector解析
yolov5_detector.py
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
import rospy
import cv2
import torch
import numpy as np
from functools import partial
from cv_bridge import CvBridge, CvBridgeError
from std_msgs.msg import Header
from geometry_msgs.msg import Twist
from sensor_msgs.msg import Image, RegionOfInterest
from robot_vision.msg import BoundingBox, BoundingBoxes
class Yolov5Param:
def __init__(self):
# load local repository(YoloV5:v6.0)
# 指定yolov5的源码路径,位于robot_vision/yolov5/
yolov5_path = rospy.get_param('/yolov5_path', '')
# 指定yolov5的权重文件路径,位于robot_vision/data/weights/yolov5s.pt
weight_path = rospy.get_param('~weight_path', '')
# yolov5的某个参数,这里不深究了
conf = rospy.get_param('~conf', '0.5')
# 使用pytorch加载yolov5模型,torch.hub.load会从robot_vision/yolov5/中找名为hubconf.py的文件
# hubconf.py文件包含了模型的加载代码,负责指定加载哪个模型
self.model = torch.hub.load(yolov5_path, 'custom', path=weight_path, source='local')
# 一个参数,用来决定使用cpu还是gpu,这里我们使用gpu
if (rospy.get_param('/use_cpu', 'false')):
self.model.cpu()
else:
self.model.cuda()
self.model.conf = conf
# target publishers
# BoundingBoxes是本样例自定义的消息类型,用来记录识别到的目标
# 使用/yolov5/targets topic发布出去
self.target_pub = rospy.Publisher("/yolov5/targets", BoundingBoxes, queue_size=1)
def image_cb(msg, cv_bridge, yolov5_param, color_classes, image_pub):
# 使用cv_bridge将ROS的图像数据转换成OpenCV的图像格式
try:
# 将Opencv图像转换numpy数组形式,数据类型是uint8(0~255)
# numpy提供了大量的操作数组的函数,可以方便高效地进行图像处理
cv_image = cv_bridge.imgmsg_to_cv2(msg, "bgr8")
frame = np.array(cv_image, dtype=np.uint8)
except (CvBridgeError, e):
print(e)
# 实例化BoundingBoxes,存储本次识别到的所有目标信息
bounding_boxes = BoundingBoxes()
bounding_boxes.header = msg.header
# 将BGR图像转换为RGB图像, 给yolov5,其返回识别到的目标信息
rgb_image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = yolov5_param.model(rgb_image)
boxs = results.pandas().xyxy[0].values
for box in boxs:
bounding_box = BoundingBox()
# 置信度,因为是基于统计,因此每个目标都有一个置信度,标识可能性
bounding_box.probability =np.float64(box[4])
# (xmin, ymin)是目标的左上角,(xmax,ymax)是目标的右上角
bounding_box.xmin = np.int64(box[0])
bounding_box.ymin = np.int64(box[1])
bounding_box.xmax = np.int64(box[2])
bounding_box.ymax = np.int64(box[3])
# 本地识别到的目标个数
bounding_box.num = np.int16(len(boxs))
# box[-1]是目标的类型名,比如person
bounding_box.Class = box[-1]
# 放入box队列中
bounding_boxes.bounding_boxes.append(bounding_box)
# 同一类目标,用同一个颜色的线条画框
if box[-1] in color_classes.keys():
color = color_classes[box[-1]]
else:
color = np.random.randint(0, 183, 3)
color_classes[box[-1]] = color
# 用框把目标圈出来
cv2.rectangle(cv_image, (int(box[0]), int(box[1])),
(int(box[2]), int(box[3])), (int(color[0]),int(color[1]), int(color[2])), 2)
# 在框上, 打印物体类型信息Class
if box[1] < 20:
text_pos_y = box[1] + 30
else:
text_pos_y = box[1] - 10
cv2.putText(cv_image, box[-1],
(int(box[0]), int(text_pos_y)-10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 255, 255), 2, cv2.LINE_AA)
# 发布目标数据,topic为:/yolov5/targets
# 可以使用命令查看:rotopic echo /yolov5/targets
yolov5_param.target_pub.publish(bounding_boxes)
# 将标识了识别目标的图像转换成ROS消息并发布
image_pub.publish(cv_bridge.cv2_to_imgmsg(cv_image, "bgr8"))
def main():
rospy.init_node("yolov5_detector")
rospy.loginfo("starting yolov5_detector node")
bridge = CvBridge()
yolov5_param = Yolov5Param()
color_classes = {}
image_pub = rospy.Publisher("/yolov5/detection_image", Image, queue_size=1)
bind_image_cb = partial(image_cb, cv_bridge=bridge, yolov5_param=yolov5_param, color_classes=color_classes, image_pub=image_pub)
rospy.Subscriber("/usb_cam/image_raw", Image, bind_image_cb)
rospy.spin()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
yolov5_detector.launch
<launch>
<node name="usb_cam" pkg="usb_cam" type="usb_cam_node" output="screen" >
<param name="video_device" value="/dev/video0" />
<param name="image_width" value="640" />
<param name="image_height" value="480" />
<param name="pixel_format" value="yuyv" />
<param name="camera_frame_id" value="usb_cam" />
<param name="io_method" value="mmap"/>
node>
<param name="yolov5_path" value="$(find robot_vision)/yolov5"/>
<param name="use_cpu" value="false" />
<node pkg="robot_vision" name="yolov5_detector" type="yolov5_detector.py" output="screen" >
<param name="weight_path" value="$(find robot_vision)/data/weights/yolov5s.pt"/>
<param name="image_topic" value="/usb_cam/image_raw" />
<param name="pub_topic" value="/yolov5/targets" />
<param name="conf" value="0.3" />
node>
// 使用launch-prefix让rqt_image_view比yolov5_detector晚三秒启动,因为yolov5启动比较慢
<node
pkg="rqt_image_view"
type="rqt_image_view"
name="rqt_image_view"
launch-prefix="bash -c 'sleep 3; $0 $@'"
output="screen"
/>
launch>
BoundingBox.msg
float64 probability
int64 xmin
int64 ymin
int64 xmax
int64 ymax
int16 num
string Class
BoundingBoxes.msg
Header header
BoundingBox[] bounding_boxes
(5)编译和运行
整个robot_vison的cmake为:
cmake_minimum_required(VERSION 3.0.2)
project(robot_vision)
find_package(catkin REQUIRED COMPONENTS
cv_bridge
image_transport
roscpp
rospy
sensor_msgs
std_msgs
geometry_msgs
message_generation
)
add_message_files(
FILES
BoundingBox.msg
BoundingBoxes.msg
)
generate_messages(
DEPENDENCIES
std_msgs
)
catkin_package()
include_directories(
${catkin_INCLUDE_DIRS}
)
catkin_install_python(PROGRAMS
scripts/cv_bridge_test.py scripts/face_detector.py scripts/motion_detector.py
DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
)
cd ~/catkin_ws/
catkin_make --source src/robot_vision
source devel/setup.bash
roslaunch robot_vision face_detector.launch
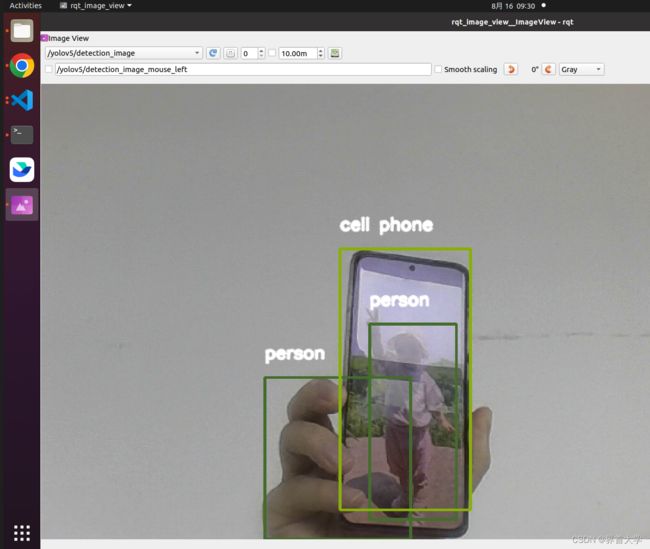
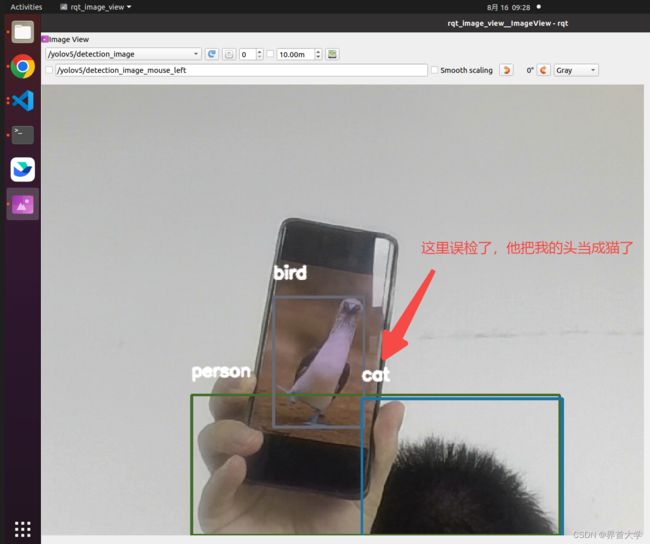
(6)踩坑记录
当我运行yolov5时,出现如下报错,参考了该博客修改了yolov5的源码后,问题解决:
解决yolov5 AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘
3 总结
机器视觉的四篇文章完成了,所有的样例包括本文的yolov5_detector,托管在本人的github上:robot_vision