关键字驱动类和Excel数据驱动
一、关键字驱动类
在自动化测试中,分为两种应用方式,第一种叫做线性代码的模式,是所有的学习者以及新手对于自动化的认知。第二种方式是基于框架的形态来完成。所谓框架其实就是一个完整的工程结构,具备有各类功能,满足企业实际各方功能需求的一个项目工程。
市场主流的自动化测试框架设计,分为POM和关键字驱动,主要是为了解决不同的需求而实现的不同设计模式。
测试框架在实际工作中是一种灵活的内容,会结合企业的实际需要来实现具体功能。
关键字驱动,最为传统的设计模式。最初就是基于工具的交互形态来实现的。冗余是非常常见的现象,关键字驱动的设计模式可以极大地降低代码的冗余。
测试框架基本原理:
代码与数据分离
逻辑代码与测试代码要分离
关键字驱动类就是Selenium的操作行为代码的封装。这是错误的。关键字驱动类,是行为的封装,重点在封装二字。关键字驱动类除去封装基本的操作行为之外,还可以实现流程的关键字封装,在整个框架设计上,封装的定义不是固定的。
对于代码来说不再是线性的,而是将逻辑代码和数据代码分开,将常用的操作封装起来,通过传入参数就可以调用:
常见的逻辑代码:
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
import class17.options as opt
# 关键字驱动类:逻辑代码实现
class WebKeys:
# 临时driver对象
# driver = webdriver.Chrome()
# 构造函数
def __init__(self, type_):
# 实例化driver对象
self.driver = open_browser(type_)
self.driver.implicitly_wait(5)
# 访问url
def open(self, url):
self.driver.get(url)
# 元素定位:要满足不同的定位需求将定位到的元素进行返回,以便后续操作
def locator(self, by, value):
return self.driver.find_element(by, value)
# 输入
def input(self, by, value, txt):
# self.driver.find_element(by, value).send_keys(txt) # 不要这样写
el = self.locator(by, value)
el.clear()
el.send_keys(txt)
# 点击
def click(self, by, value):
self.locator(by, value).click()
# 关闭
def quit(self):
self.driver.quit()
# 强制等待
def wait(self, time_):
time.sleep(time_)
# 显式等待:结合实际需要进行等待时长的变化
def driver_wait(self, by, value, time_=5):
WebDriverWait(self.driver, time_, 0.5). \
until(lambda el: self.locator(by, value), message="显式等待失败")
# 句柄切换
def window_switch(self):
handles = self.driver.window_handles
self.driver.close()
self.driver.switch_to.window(handles[1])测试代码管理:将所有需要执行的测试流程,放在此文件中,进行统一管理
测试代码文件是可以有多个的,根据业务需要,以及代码管理需要进行文件的批量化管理,测试代码脱离了逻辑代码之后,是没有任何价值的。
可以通过一次登录操作体会一下测试代码和逻辑代码的不同:
# 要实现一次登录操作:实现一个复杂的业务流程的自动化执行,是不是可以考虑把不同的子流程进行关键字的封装?实现一个流程关键字?
wk = WebKeys('chrome')
wk.open('http://hcc.fecmall.com/customer/account/login')
# 输入账号和密码
wk.input('id', 'email', '[email protected]')
wk.input('id', 'pass', 'hcc123456')
wk.click('id', 'js_registBtn')
wk.wait(20)
wk.quit()
# wk.login() # 是否可以意味着,login方法实现的操作行为是一个完整的登录业务流程二、Excel数据驱动
在自动化测试领域下,数据驱动是专门用于管理测试数据的核心技术。除了写代码,我们还要维护数据。
在自动化执行中,把所有测试相关联的测试数据全部都提取出来,单独用一个文件的形态进行保存和管理。需要用到什么数据,就读取对应的文件中数据内容,来实现数据的传入。这个技术就是数据驱动。
Excel:一般用于关键字驱动形态的实现
Excel文件的处理,在Python中有非常多的手段可以实现,XLRD,XLWT,pandas,Openpyxl等等等等,有很多。主体的技术实现都还是基于Openpyxl来进行。
环境部署指令:pip install openpyxl
准备步骤:
创建一个demo包->open in->finder->打开demo所在的路径->创建xlsx文件
不要直接右键通过file进行创建,否则容易识别不到xlsx里面的内容

我们可以尝试在excel文件中写入内容,excel文件下面可能会有很多的sheet,这里我们把内容写在sheet3中。如下图:

前面做了准备工作,接下来通过实际操作来学习如何,整体步骤如下:
Openpyxl库的基本应用
1. 获取excel文件
2. 获取指定的sheet页
3. 获取sheet页中的单元格内容
4. 单元格写入
5. 获取所有sheet页的内容
先通过代码看一下前三步的效果
import openpyxl
#1.获取execl文件
excel = openpyxl.load_workbook('./test.xlsx')
#2.获取sheet页
sheet = excel['Sheet3']
#3.获取单元格的内容,单元格有行和列,这里先获取第一行和第一列
print(sheet.cell(row=1, column=1).value)运行结果如下:
一般上面的操作不常用,我们也可以获取单元格里面的所有内容
#3.1获取所有单元格的内容
for values in sheet.values:
print(values)运行结果如下:所有的内容都是以行为单位进行返回,返回的数据都是元组的形态来进行的

单元格写入,写入保存的前提需要先把文件关闭,不然会报错
单元格写入方法一:
#单元格写入方法一
sheet['A2'] ='这是新加的内容'
#只要关联到写入的操作,excel就需要调用保存的方法,否则不会生效
excel.save('./text.xlsx')查看结果:

单元格写入方法二:就是通过先读再取的方式,进行赋值
#单元格写入方法二
sheet.cell(row=1, column=2).value = '这是写入方法二'查看结果:


那么我们如何获取sheet页中所有的内容,我们可以通过循环嵌套的方式进行获取
#2.1获取所有sheet页方法
names = excel.sheetnames
for name in names:
sheet = excel[name]
#获取sheet所有内容
for values in sheet.values:
print(values)运行结果如下:

三、关键字驱动+Excel数据驱动
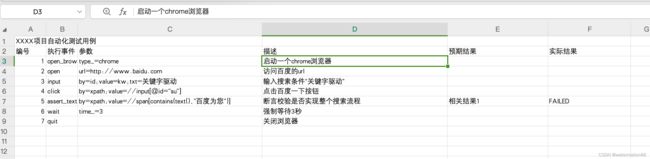
excel最好写成以下格式:
获取execl 文件中的内容
#获取excel文件
excel = openpyxl.load_workbook('./text.xlsx')
#获取sheet页
for name in excel.sheetnames:
sheet = excel[name]
for values in sheet.values:
#判断是否是用例正文
if type(values[0]) is int:
#print(values)
#参数处理
data = dict()
data['method'] = values[1]
data['value'] = values[2]
data['txt'] = values[3]
print(data)运行结果如下:

为了更好的和关键字驱动类结合起来:
参数的原本形态:by=id;value=kw;txt=关键字驱动
要实现的目标:
{
"by":"id",
"value":"kw",
"txt":关键字驱动"
}
因为我们要将原本形态转换成一个目标形态,所以要实现一个类:将str转换为字典形式
# 参数从str转换为dict的方法
def arguments(value):
# 定义返回对象
data = dict()
# 如果value有值,需要进行数据处理
if value:
str_temp = value.split(";")
for temp in str_temp:
# by = id
t = temp.split('=', 1)
# {"by":"id"}
data[t[0]] = t[1]
return data
执行事件的处理
open_browser表示实例化
其他操作则是实例化对象的常规方法调用而已。
断言校验因为关联到实际的excel写入结果,所以也是单独的一套处理因为断言是需要有结果反馈的,所以要根据断言成功或失败,对excel文件写入对应的pass或者failed,根据断言状态对用例结果进行写入。
所以要对特殊的方法进行处理:
# 实例化浏览器对象
if values[1] == 'open_browser':
wk = WebKeys(**data)
# 断言处理:因为断言的种类是多样化的,所以需要考虑用例写的什么断言方法,就调用对应的断言方法
elif "assert" in values[1]:
# 因为断言是需要有结果反馈的,所以要根据断言成功或失败,对excel文件写入对应的pass或者failed
status = getattr(wk, values[1])(expected=values[4], **data)
# 根据断言状态对用例结果进行写入
if status:#因为前面有两列综述信息,所以要加2
sheet.cell(row=values[0] + 2, column=6).value = 'PASS'
else:
sheet.cell(row=values[0] + 2, column=6).value = 'FAILED'
excel.save('./test.xlsx')
# 执行常规操作行为
else:
getattr(wk, values[1])(**data)
python传参,是字符串、数组、字典,所以整个关键是要将参数信息从字符串,转化成字典。